DeepSeek对MoE架构做了哪些改进?大模型面试真题!
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
随着DeepSeek爆火,面试中也越来越高频出现,因此训练营也更新了DeepSeek系列技术的深入拆解。包括MLA、MTP、专家负载均衡、FP8混合精度训练,Dual-Pipe等关键技术,力求做到全网最硬核的解析~
DeepSeek 对 MoE 架构做了哪些改进?跟 Mixtral 的 MoE 有什么不同?这个是我的学员最近面试某个大模型独角兽遇到的一道面试题。
01面试官心理分析
这篇文章,我们就从面试官的角度来分析一下,如果你在面试现场被问到这个题目,应该如何作答?
面试官问这个问题,它其实是想考你什么?
- 第一,Mixtral 大模型采用的 MoE 架构长什么样?
- 第二,就是 DeepSeek 的 MoE 做了哪些改进,这样改进的动机是什么?
02面试题解析
要回答 DeepSeek 的 MoE 改进,我们先来看看,最原始的 MoE 网络长什么样子?以及它是怎么工作的?
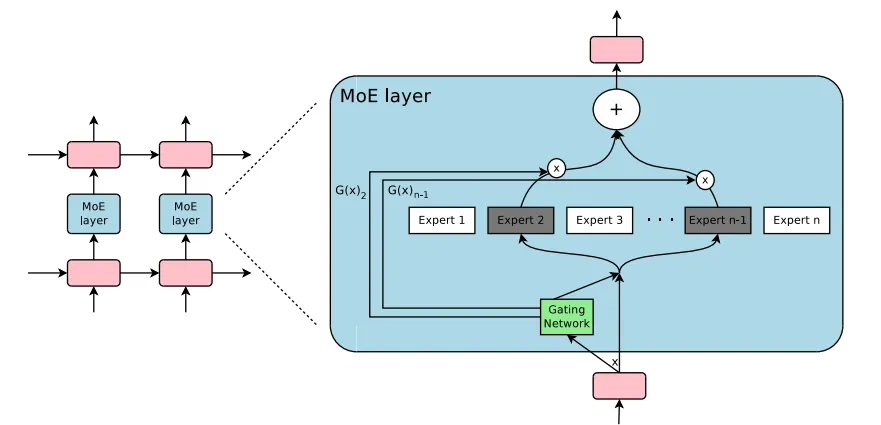
这张图是 Mixtral 8x7B 的 MoE 架构:
其核心思想很直观,它实际上用了 8 个7B的“专家”模型,当 MoE 与Transformer 相结合时,会用稀疏 MoE 层替换掉某些前馈层。
MoE 层包含了一个路由网络,用于选择将输入 token 分派给哪些专家处理,Mixtral 模型为每个词元选择 top-K 个专家,那在图中是选择两个。
因为每次只激活部分的专家,所以其解码速度能做到与 14B 模型相当,也就极大的提高了模型的推理效率。
好,了解了最原始的 MoE 架构,我们再来看看,DeepSeek 是怎么改进的?
看这张图,其实 DeepSeek 的主要改动点,就是把专家分成了两拨,分别是 Shared Expert 和 Routed Expert。
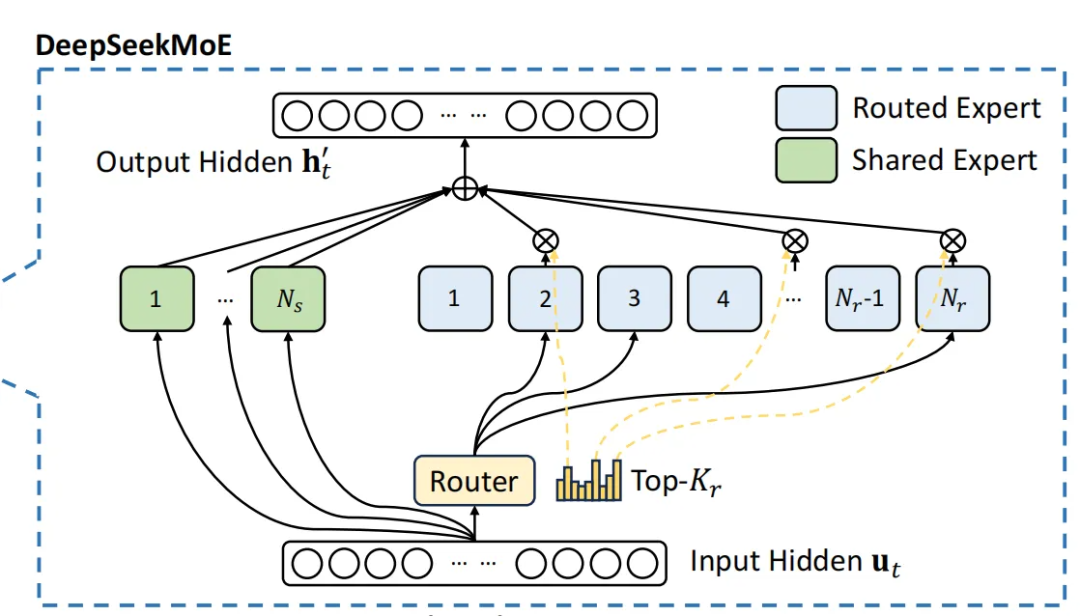
通俗来讲,就好比学校的常驻教授和客座教授,常驻教授是一直在的,而客座教授则经常会变,不同的教学主题,有不同的客座教授。
在 DeepSeek 的 MoE 中,Shared Expert 是一直激活的,也就是输入的 token 会被 Shared Expert 计算,Routed Expert 和普通的 MoE 一样,要先计算相似度,也就是专家的得分,再选择 top-k 进行推理。
但是我们分析 DeepSeek 的源码可以发现,代码实际在计算 top-k 时,会先将 N 个 Expert 进行分组 n_groups,将每个组中 top-2 个专家的相似度得分加起来,算出得分最高的那些 top_k_group 组,然后在这些组里选择 top-k 个专家。
最后将所有的 Shared Expert 输出和 Routed Expert 输出做加权相加,得到 MoE 层的最终输出。
这里 Deepseek-v3 和 Deepseek-R1 采用了 256 个 Routed Expert 和 1个 Shared Expert,并在 Router 中选出 8 个来,参数量是 671B,而实际激活的参数量只有 37B。
好,现在我们答出了 DeepSeek 对 MoE 架构的改进点,面试官可能会继续追问:那它为什么要这样改进呢?这样改进有什么好处?
实际上这种设计主要是基于以下两点考虑:
第一,原始的 MoE 会产生较多的冗余,一个想法就是抽取一个 Shared Expert 出来处理通用知识,其他的 Routed Expert 来处理差异性的知识。
通过隔离 Shared Expert,以减轻 Routed Expert 所需要学习的知识量,从而减少路由专家之间的冗余。
第二个考虑是高效计算的层面,MoE 模型在训练的时候,会花费大量的时候来做通讯,因为 expert 会分散到不同的设备上,从而降低巨大的总参数量带来的显存消耗。
一种解决思路是:在通讯流处在工作状态的时候,同时用计算流进行后续的运算,从而隐藏掉部分通讯时间。
Shared Expert 的计算与 Routed Expert 通讯是不依赖的,因此可以使用通讯隐藏,从而比普通的 MoE 结构计算更高效。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
这里我整理了一份AI大模型入门到进阶全套学习包,包含学习路线+实战案例+视频+书籍PDF+面试题+DeepSeek部署包和技巧,需要的小伙伴文在下方免费领取哦,真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 15
15 0
0- 0



 已为社区贡献50条内容
已为社区贡献50条内容

所有评论(0)