深度探索AI 智算云平台与DeepSeek 的多元联动应用与模型微调全解析_deepseek知识库和微调
在数字浪潮汹涌澎湃的时代,程序开发宛如一座神秘而宏伟的魔法城堡,矗立在科技的浩瀚星空中。代码的字符,似那闪烁的星辰,按照特定的轨迹与节奏,组合、交织、碰撞,即将开启一场奇妙且充满无限可能的创造之旅。当空白的文档界面如同深邃的宇宙等待探索,程序员们则化身无畏的星辰开拓者,指尖在键盘上轻舞,准备用智慧与逻辑编织出足以改变世界运行规则的程序画卷,在 0 和 1 的二进制世界里,镌刻下属于人类创新与突破的
文章目录
- 前言
- 一、DeepSeek满血版使用
-
- 2.1 关于蓝耘
- 2.2 注册与登录
- 2.3 使用DeepSeek
- 二、DeepSeek 基础概念回顾
-
- 2.1 DeepSeek 模型架构概述
- 2.2 DeepSeek 的预训练优势
- 三、DeepSeek 在自然语言处理领域的联动应用
-
- 3.1 智能客服系统集成
-
- 3.1.1 应用场景与优势
- 3.1.2 实现流程与代码示例
- 3.2 机器翻译优化
-
- 3.2.1 翻译质量提升原理
- 3.2.2 训练与优化方法
- 四、DeepSeek 在计算机视觉领域的联动应用
-
- 4.1 工业缺陷检测
-
- 4.1.1 检测原理与流程
- 4.1.2 模型训练与部署
- 4.2 智能安防监控
-
- 4.2.1 异常行为识别
- 4.2.2 多模态数据融合应用
- 五、DeepSeek 模型微调基础
-
- 5.1 微调的重要性与意义
- 5.2 微调的基本流程
-
- 5.2.1 数据准备
- 5.2.2 模型加载与初始化
- 5.2.3 训练与优化
- 六、DeepSeek 模型微调的具体方向
-
- 6.1 基于领域知识的微调
-
- 6.1.1 医疗领域微调示例
- 6.1.2 法律领域微调要点
- 6.2 个性化定制微调
-
- 6.2.1 用户偏好学习
- 6.2.2 特定场景适配
- 七、总结
深度探索AI | 智算云平台与DeepSeek 的多元联动应用与模型微调全解析,DeepSeek 作为一款在人工智能领域具有显著影响力的模型,其应用场景不断拓展,与其他领域的联动日益紧密。同时,模型微调作为提升模型性能、适配特定任务的重要手段,对于 DeepSeek 的广泛应用至关重要。本文将深入探讨 DeepSeek 的各种衍生联动应用以及模型微调方向,为相关从业者和爱好者提供全面且深入的指导。
前言
在数字浪潮汹涌澎湃的时代,程序开发宛如一座神秘而宏伟的魔法城堡,矗立在科技的浩瀚星空中。代码的字符,似那闪烁的星辰,按照特定的轨迹与节奏,组合、交织、碰撞,即将开启一场奇妙且充满无限可能的创造之旅。当空白的文档界面如同深邃的宇宙等待探索,程序员们则化身无畏的星辰开拓者,指尖在键盘上轻舞,准备用智慧与逻辑编织出足以改变世界运行规则的程序画卷,在 0 和 1 的二进制世界里,镌刻下属于人类创新与突破的不朽印记。
在人工智能飞速发展的今天,强大的语言模型为我们解决各类问题提供了极大的便利。蓝耘元生代智算云的 Deepseek-R1 满血版便是一款性能卓越的人工智能模型,它能够处理复杂的自然语言任务,帮助用户在科研、工作、学习等多个领域提升效率。本教程将详细介绍如何使用蓝耘元生代智算云的 Deepseek-R1 满血版,无论你是初次接触人工智能模型的新手,还是希望深入了解并高效运用该模型的专业人士,都能从本教程中获取到实用的信息。
蓝耘的Deepseek-R1/V3满血版
一、DeepSeek满血版使用
2.1 关于蓝耘
蓝耘元生代智算云是一个基于 Kubernetes 构建的现代化云平台,专为大规模 GPU 加速工作负载而设计。它具备以下优势:
`高性能`:速度可比传统云服务提供商快 35 倍,这意味着在运行 Deepseek-R1 这样的大型模型时,能够快速地给出结果,大大节省用户等待时间。
`低成本`:成本降低 30%,对于需要长期使用智算服务的企业和个人来说,能够有效控制开支。
`低时延`:时延减少 50%,保证了模型响应的及时性,让交互更加流畅。
2.2 注册与登录
`访问官网`:打开你常用的浏览器,在地址栏输入蓝耘元生代智算云的官方网址(请确保从官方渠道获取准确网址)。
注册界面
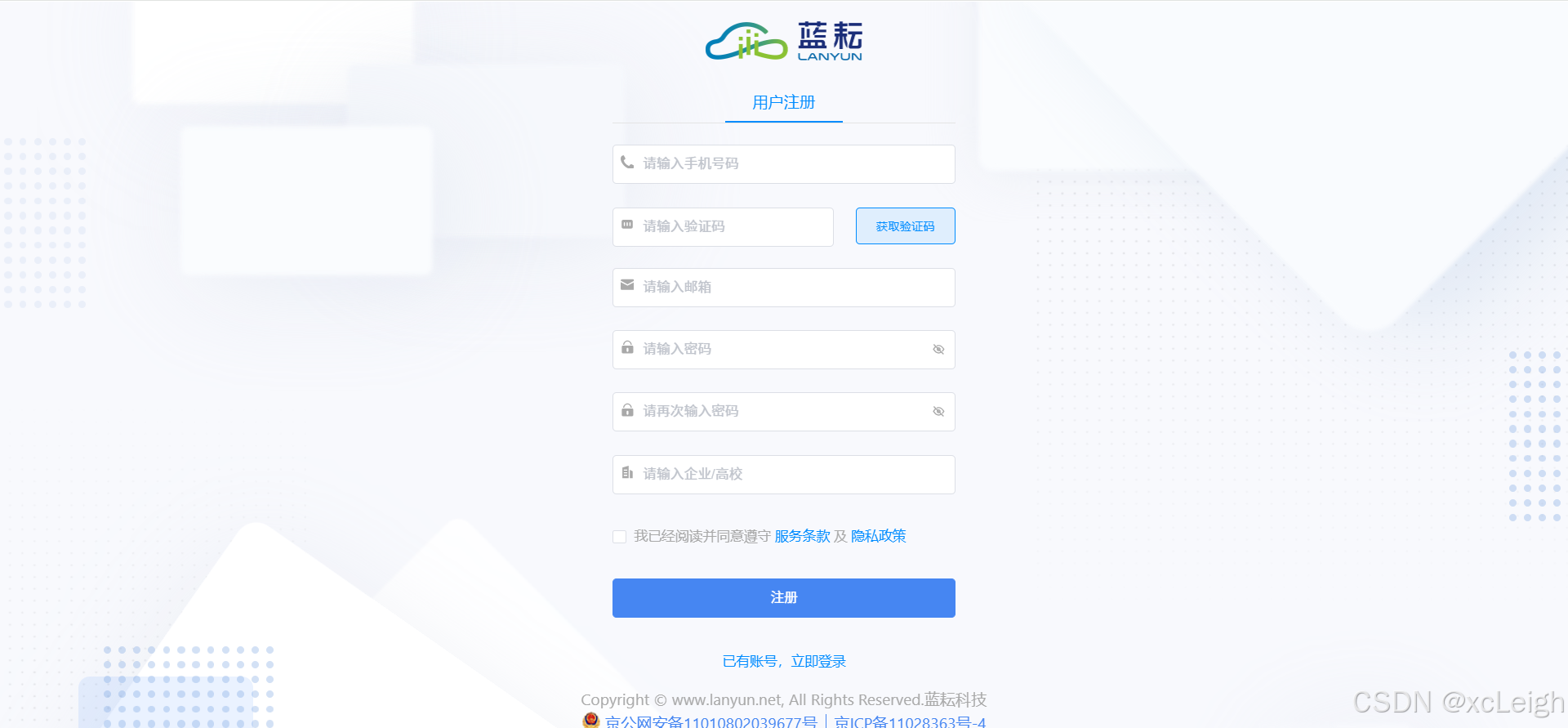
`注册账号`:如果您是新用户,点击页面上的 “注册” 按钮。在注册页面,填写必要的信息,通常包括用户名、邮箱地址、密码等。用户名应简洁易记,且符合平台规定的命名规则;邮箱地址用于接收平台的重要通知和验证信息;密码需设置为强度较高的组合,包含字母、数字和特殊字符,以确保账号安全。填写完成后,点击 “注册” 按钮完成注册流程。

`登录账号`:注册成功后,返回官网首页,点击 “登录” 按钮。在登录页面输入您刚刚注册的用户名和密码,点击 “登录” 即可进入蓝耘元生代智算云平台。
登录成功的控制台效果
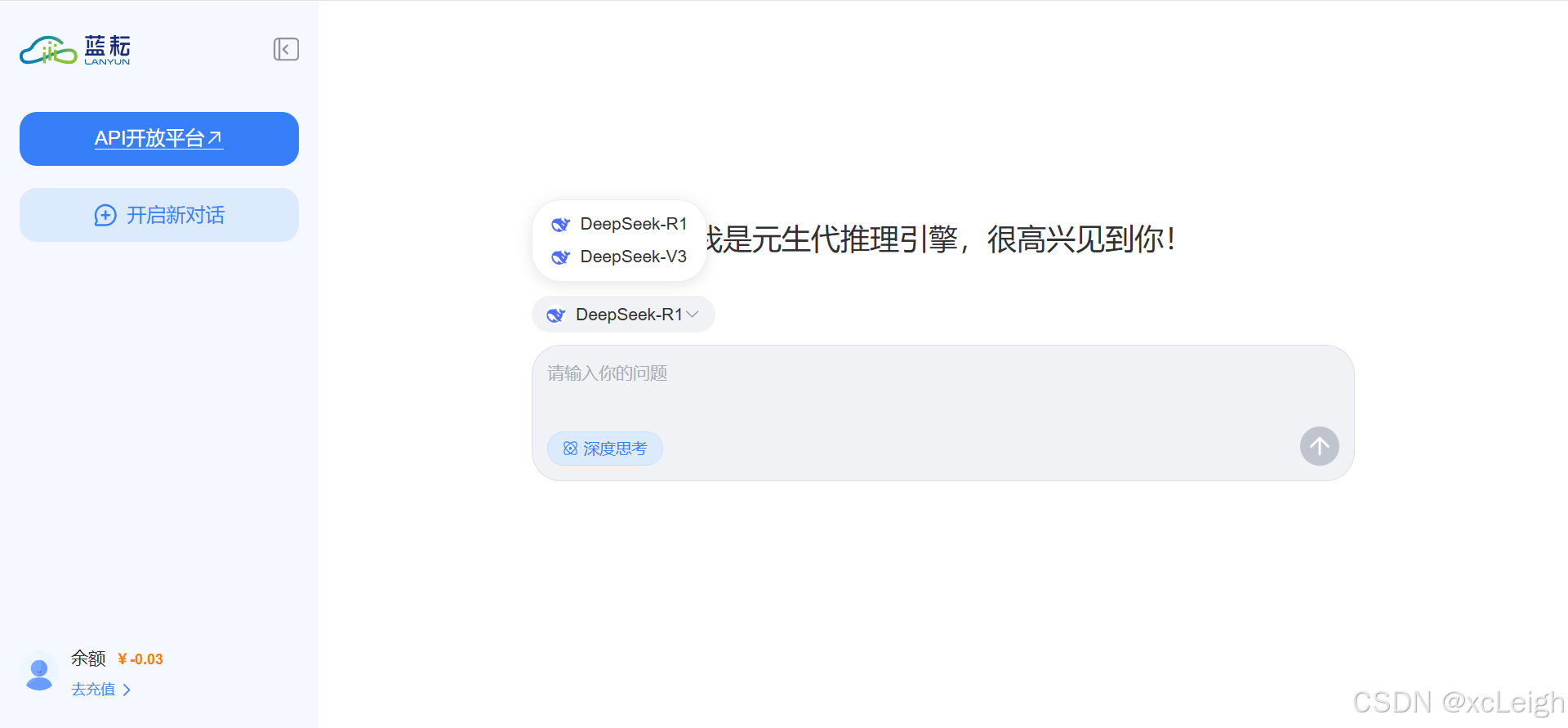
2.3 使用DeepSeek
- 点击MaaS平台
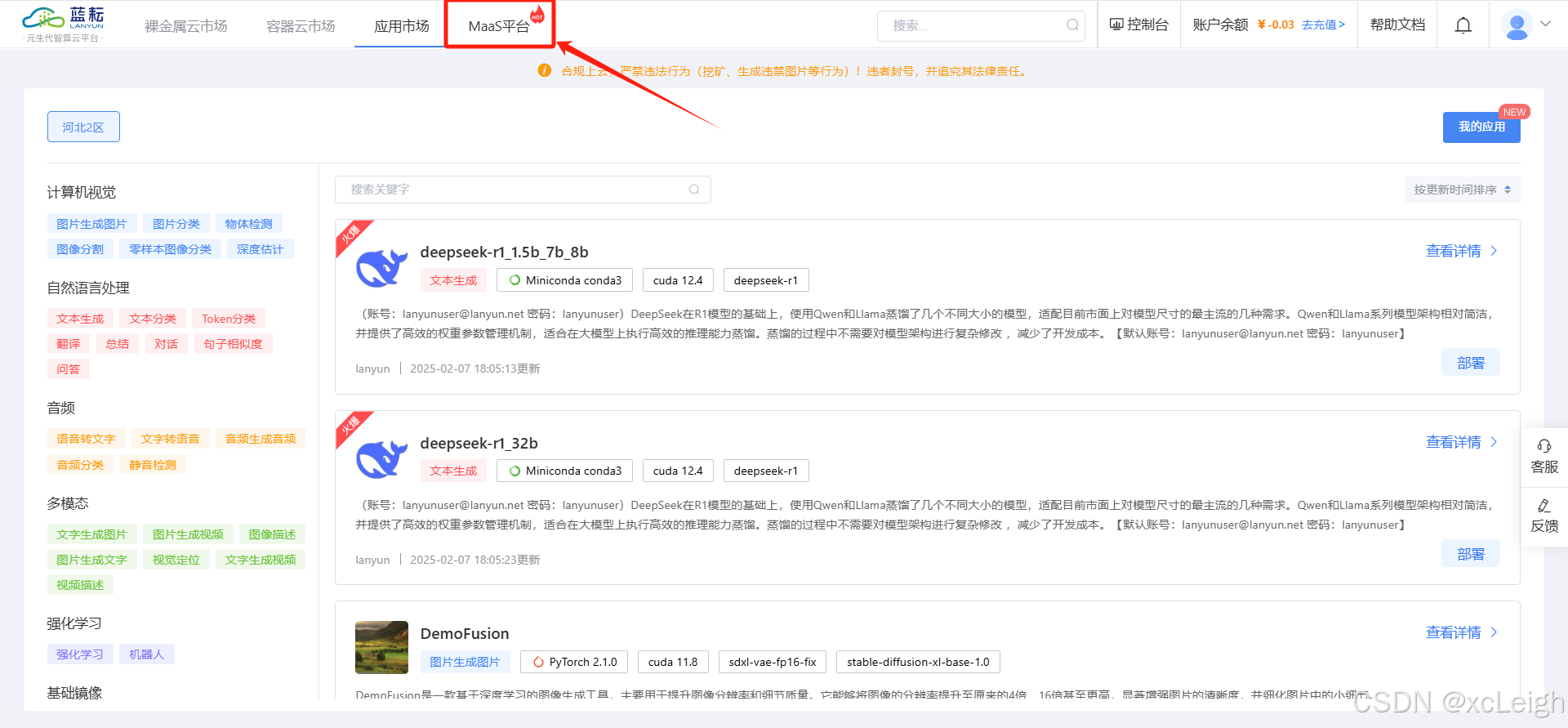
- 直接跟DeepSeek对话
- 问DeepSeek:xcLeigh博主咋样?

二、DeepSeek 基础概念回顾
2.1 DeepSeek 模型架构概述
DeepSeek 基于 Transformer 架构构建,这种架构以其强大的并行计算能力和对长序列数据的有效处理而闻名。Transformer 架构主要由多头注意力机制(Multi - Head Attention)和前馈神经网络(Feed - Forward Neural Network)组成。多头注意力机制允许模型同时关注输入序列的不同部分,从而捕捉到更丰富的语义信息。例如,在文本处理中,它可以同时关注一个句子中的不同单词之间的关系,而不仅仅是相邻单词。
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
def __init__(self, embed_dim, num_heads):
super(MultiHeadAttention, self).__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
self.W_q = nn.Linear(embed_dim, embed_dim)
self.W_k = nn.Linear(embed_dim, embed_dim)
self.W_v = nn.Linear(embed_dim, embed_dim)
self.W_o = nn.Linear(embed_dim, embed_dim)
def forward(self, Q, K, V):
batch_size = Q.size(0)
Q = self.W_q(Q).view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
K = self.W_k(K).view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
V = self.W_v(V).view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.head_dim ** 0.5)
attention = F.softmax(scores, dim=-1)
output = torch.matmul(attention, V).transpose(1, 2).contiguous().view(batch_size, -1, self.embed_dim)
output = self.W_o(output)
return output
前馈神经网络则对注意力机制输出的结果进行进一步的特征变换和非线性处理,以增强模型的表达能力。
2.2 DeepSeek 的预训练优势
DeepSeek 在大规模数据集上进行了预训练,这些数据集涵盖了丰富的文本、图像等信息。通过预训练,模型学习到了通用的语言和视觉模式,例如在自然语言处理中,它掌握了单词的语义、语法规则以及文本的结构等知识。这使得在进行特定任务的微调时,模型能够更快地收敛到较好的性能,因为它已经具备了一些基础的知识和特征表示,无需从头开始学习。
三、DeepSeek 在自然语言处理领域的联动应用
3.1 智能客服系统集成
3.1.1 应用场景与优势
在现代商业环境中,智能客服系统是企业与客户沟通的重要桥梁。将 DeepSeek 集成到智能客服系统中,可以显著提升客服的效率和质量。DeepSeek 能够理解客户的自然语言问题,无论是简单的产品咨询还是复杂的技术问题,都能给出准确且有针对性的回答。
例如,当客户询问 _“你们最新款手机的电池续航如何?”_ DeepSeek 可以快速从产品知识库中提取相关信息,并组织语言进行回答。与传统基于规则的客服系统相比,基于 DeepSeek 的智能客服具有更强的语言理解能力,能够处理模糊、多变的用户提问。
3.1.2 实现流程与代码示例
首先,需要将 DeepSeek 模型加载到客服系统中。在 Python 中,可以使用相应的深度学习框架(如 PyTorch)来实现。假设已经下载了 DeepSeek 的预训练模型权重文件deepseek\_model.pth,加载模型的代码如下:
import torch
from deepseek_model import DeepSeekModel # 假设已经定义了DeepSeekModel类
model = DeepSeekModel()
model.load_state_dict(torch.load('deepseek_model.pth'))
model.eval()
接下来,对用户输入的问题进行处理和预测。需要对输入文本进行编码,将其转换为模型能够接受的格式。例如,使用分词器将文本拆分为单词或子词,并将其转换为对应的数字编码。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('deepseek - tokenizer')
user_question = "你们最新款手机的电池续航如何?"
input_ids = tokenizer(user_question, return_tensors='pt').input_ids
with torch.no_grad():
output = model(input_ids)
predicted_answer = tokenizer.decode(output.argmax(dim=-1)[0], skip_special_tokens=True)
print(predicted_answer)
3.2 机器翻译优化
3.2.1 翻译质量提升原理
DeepSeek 在机器翻译领域的应用主要通过其对不同语言之间语义和语法结构的理解。它能够将源语言句子准确地解析为语义表示,然后再根据目标语言的语法规则和词汇进行重新生成。例如,在将中文句子 “我喜欢阅读书籍” 翻译成英文时,DeepSeek 能够理解 “喜欢” 对应的英文词汇 “like”,以及句子的主谓宾结构,从而生成准确的翻译 “I like reading books”。与传统机器翻译模型相比,DeepSeek 能够更好地处理长难句、习语等复杂语言现象,提高翻译的准确性和流畅性。
3.2.2 训练与优化方法
为了进一步优化 DeepSeek 在机器翻译任务上的性能,可以使用大规模的平行语料库进行微调。平行语料库包含了大量的源语言和目标语言的对齐句子对。在微调过程中,以源语言句子作为输入,目标语言句子作为标签,通过反向传播算法调整模型的参数,使得模型能够更好地完成翻译任务。
from torch.utils.data import Dataset, DataLoader
import torch.optim as optim
class TranslationDataset(Dataset):
def __init__(self, source_texts, target_texts, tokenizer):
self.source_texts = source_texts
self.target_texts = target_texts
self.tokenizer = tokenizer
def __len__(self):
return len(self.source_texts)
def __getitem__(self, idx):
source_input = self.tokenizer(self.source_texts[idx], return_tensors='pt').input_ids
target_input = self.tokenizer(self.target_texts[idx], return_tensors='pt').input_ids
return source_input.squeeze(0), target_input.squeeze(0)
source_texts = ["我喜欢阅读书籍", "他正在跑步"]
target_texts = ["I like reading books", "He is running"]
tokenizer = AutoTokenizer.from_pretrained('deepseek - tokenizer')
dataset = TranslationDataset(source_texts, target_texts, tokenizer)
dataloader = DataLoader(dataset, batch_size = 2, shuffle=True)
optimizer = optim.Adam(model.parameters(), lr = 0.001)
criterion = nn.CrossEntropyLoss()
for epoch in range(10):
for source_input, target_input in dataloader:
optimizer.zero_grad()
output = model(source_input)
loss = criterion(output.view(-1, output.size(-1)), target_input.view(-1))
loss.backward()
optimizer.step()
四、DeepSeek 在计算机视觉领域的联动应用
4.1 工业缺陷检测
4.1.1 检测原理与流程
在工业生产中,产品的质量检测至关重要。DeepSeek 可以通过对大量正常产品和缺陷产品图像的学习,建立起能够准确识别产品是否存在缺陷以及缺陷类型的模型。首先,将产品图像输入到 DeepSeek 模型中,模型通过卷积神经网络(CNN)层对图像进行特征提取,这些特征能够反映图像中物体的形状、纹理等信息。然后,经过一系列的池化层和全连接层,模型对提取的特征进行分类,判断图像中的产品是否为正常产品。如果是缺陷产品,还可以进一步判断缺陷的类型,如划痕、裂纹等。
4.1.2 模型训练与部署
收集大量的工业产品图像数据,包括正常产品和各种缺陷类型的产品图像。对图像进行标注,标记出缺陷的位置和类型。使用这些标注数据对 DeepSeek 进行训练,在训练过程中,调整模型的参数,使得模型能够准确地对图像进行分类。
import torchvision
from torchvision import datasets, transforms
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
train_dataset = datasets.ImageFolder('path/to/train_data', transform=transform)
train_dataloader = DataLoader(train_dataset, batch_size = 32, shuffle=True)
model = torchvision.models.resnet18(pretrained=False)
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, num_classes) # num_classes为类别数,包括正常和各种缺陷类型
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr = 0.001, momentum = 0.9)
for epoch in range(20):
running_loss = 0.0
for i, data in enumerate(train_dataloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch {epoch + 1}, Loss: {running_loss / len(train_dataloader)}')
训练完成后,将模型部署到工业生产线上的检测设备中,实时对生产的产品进行检测。
4.2 智能安防监控
4.2.1 异常行为识别
在智能安防监控中,DeepSeek 可以对监控视频中的人员行为进行分析,识别出异常行为,如打架、奔跑、摔倒等。模型通过对视频帧序列的分析,提取人员的动作特征,利用循环神经网络(RNN)或其变体(如 LSTM、GRU)来处理时间序列信息,从而判断行为是否异常。例如,当检测到视频中多个人物的动作突然变得激烈,且身体姿态呈现出对抗性时,模型可以判断可能发生了打架行为,并及时发出警报。
4.2.2 多模态数据融合应用
为了提高安防监控的准确性,DeepSeek 还可以融合多种模态的数据,如视频图像和音频数据。例如,在监控场景中,当视频图像中检测到人员行为异常时,同时分析音频数据,如果音频中出现了争吵声或异常的呼喊声,那么可以进一步确认异常事件的发生。这种多模态数据融合的方式能够充分利用不同数据源的信息,提高模型的判断准确性。
五、DeepSeek 模型微调基础
5.1 微调的重要性与意义
微调是指在预训练模型的基础上,针对特定任务对模型的参数进行进一步调整。对于 DeepSeek 来说,预训练模型虽然在通用任务上表现良好,但在面对具体的应用场景时,可能无法达到最佳性能。通过微调,可以使模型更好地适应特定任务的数据分布和需求,提高模型在该任务上的准确性和效率。例如,在医疗影像诊断任务中,通过使用医疗影像数据对 DeepSeek 进行微调,可以使模型更好地识别医学图像中的病变特征,为医生提供更准确的辅助诊断信息。
5.2 微调的基本流程
5.2.1 数据准备
收集与特定任务相关的数据集,并对数据进行预处理。例如,在自然语言处理任务中,对文本数据进行清洗、分词、编码等操作;在计算机视觉任务中,对图像数据进行裁剪、缩放、归一化等处理。确保数据的质量和格式符合模型的输入要求。
5.2.2 模型加载与初始化
加载预训练的 DeepSeek 模型,并根据任务需求对模型的部分层进行调整或初始化。例如,如果是一个文本分类任务,可以将模型的最后一层全连接层替换为适合分类任务的输出层,其神经元数量等于类别数。
model = DeepSeekModel.from_pretrained('deepseek - base - model')
num_classes = 5 # 假设分类任务有5个类别
model.fc = nn.Linear(model.fc.in_features, num_classes)
5.2.3 训练与优化
使用准备好的特定任务数据集对模型进行训练。在训练过程中,选择合适的损失函数和优化器。例如,在分类任务中常用交叉熵损失函数,优化器可以选择 Adam、SGD 等。通过反向传播算法计算损失函数对模型参数的梯度,并根据梯度更新模型的参数,使得模型在特定任务上的性能不断提升。
六、DeepSeek 模型微调的具体方向
6.1 基于领域知识的微调
6.1.1 医疗领域微调示例
在医疗领域,DeepSeek 可以通过微调来更好地处理医学文本和图像。例如,对于医学影像诊断,收集大量的医学影像数据,包括 X 光、CT、MRI 等图像,并标注出图像中的病变区域和类型。使用这些数据对 DeepSeek 进行微调,使得模型能够准确地识别医学图像中的疾病特征。在医学文本处理方面,收集医学文献、病历等文本数据,对模型进行微调,使其能够理解医学术语、诊断描述等信息,例如准确提取病历中的症状、诊断结果等关键信息。
6.1.2 法律领域微调要点
在法律领域,将 DeepSeek 应用于法律文本分析时,需要收集大量的法律法规文本、案例判决书等数据。对模型进行微调,使其能够理解法律条文的语义、逻辑关系,以及案例中的法律事实和判决依据。例如,在法律文书分类任务中,通过微调让模型能够准确将不同类型的法律文书(如起诉状、答辩状、判决书等)进行分类,或者在法律问题回答任务中,根据法律法规和案例对用户的法律问题进行准确回答。
6.2 个性化定制微调
6.2.1 用户偏好学习
在一些个性化推荐系统中,DeepSeek 可以通过对用户行为数据的学习进行个性化定制微调。例如,在电商平台中,收集用户的浏览历史、购买记录等数据,将这些数据转换为适合模型输入的格式。通过微调,使模型能够学习到每个用户的偏好,从而为用户提供个性化的商品推荐。例如,对于经常购买运动装备的用户,推荐更多相关的运动产品;对于喜欢阅读科幻小说的用户,推荐最新的科幻书籍。
6.2.2 特定场景适配
对于一些特定的应用场景,如智能家居环境中的语音控制。通过收集用户在智能家居环境中的语音指令数据,对 DeepSeek 进行微调,使其能够更好地理解用户在该场景下的语音指令,如 “打开客厅灯”“调整卧室空调温度” 等。这样可以提高智能家居系统对用户指令的识别准确率和响应效率,为用户提供更好的使用体验。
七、总结
DeepSeek 在自然语言处理和计算机视觉等领域展现出了强大的应用潜力,通过与不同领域的联动,为各个行业带来了创新的解决方案。同时,模型微调作为提升 DeepSeek 性能、适配特定任务的关键手段,具有丰富的方向和广阔的发展空间。无论是基于领域知识的微调,还是个性化定制微调,都能够进一步挖掘 DeepSeek 的优势,使其更好地服务于实际应用。随着技术的不断发展和数据的不断积累,相信 DeepSeek 在未来会在更多领域发挥重要作用,推动人工智能技术的广泛应用和发展。
如果你对文章中的某个部分,比如某个概念的解释、代码示例等,还有更具体的要求,欢迎告诉我,我会进一步完善。
今天就介绍到这里了,更多功能快去尝试吧……
如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。
2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 28
28 0
0- 0



 已为社区贡献46条内容
已为社区贡献46条内容

所有评论(0)