基于Ollama 和 Open WebUI 部署 DeepSeek-R1
DeepSeek是目前推理效率最高的模型,私有化部署模型有助于企业将私有化的数据与LLM结合。解决具体的企业问题,提效研发。关注“AI拉呱公众号”一起学习更多AI知识!
*大家好,我是AI拉呱,一个专注于人工智领域与网络安全方面的博主,现任资深算法研究员一职,热爱机器学习和深度学习算法应用,拥有丰富的AI项目经验,希望和你一起成长交流。关注AI拉呱一起学习更多AI知识。
基于Ollama 和 Open WebUI 部署 DeepSeek-R1
训练和推理算力计算
我们经常看到一个开源的大模型是7B,32B,671B,到底这些模型训练和推理需要多少的GPU算力?是否有一个明确的计算公式?本问一句实战验证测试发现了以下规律:Int8量化后的模型训练算力一般是4倍的模型参数,推理算力一般是一倍的模型参数。如果是float模型可能需要更多。
训练算力计算
一个LLaMA-6B的数据类型为Int8
模型参数 6B1bytes = 6GB
梯度 6B1bytes = 6GB
优化器参数 Adam 2倍模型参数:6GB*2 = 12GB
训练共24GB的显存
推理算力计算
LLaMA-6B的数据类型为Int8的模型参数 6B*1bytes = 6GB
推理共6GB的显存
可部署的模型
运行满血版 DeepSeek R1,但满血版 R1 模型参数高达 671B,仅模型文件就需要 404GB 存储空间,运行时更需要约 1300GB 显存。这是很多公司无法有条件做到的。注意,只要 GPU 等于或超过 VRAM 要求,模型仍然可以在规格较低的 GPU 上运行。但是设置不是最佳的,并且可能需要进行一些调整。因此本教程私有化部署的有:
- DeepSeek-R1-Distill-Llama-8B
- DeepSeek-R1-Distill-Qwen-14B
- DeepSeek-R1-Distill-Qwen-32B
- DeepSeek-R1-Distill-Llama-70B
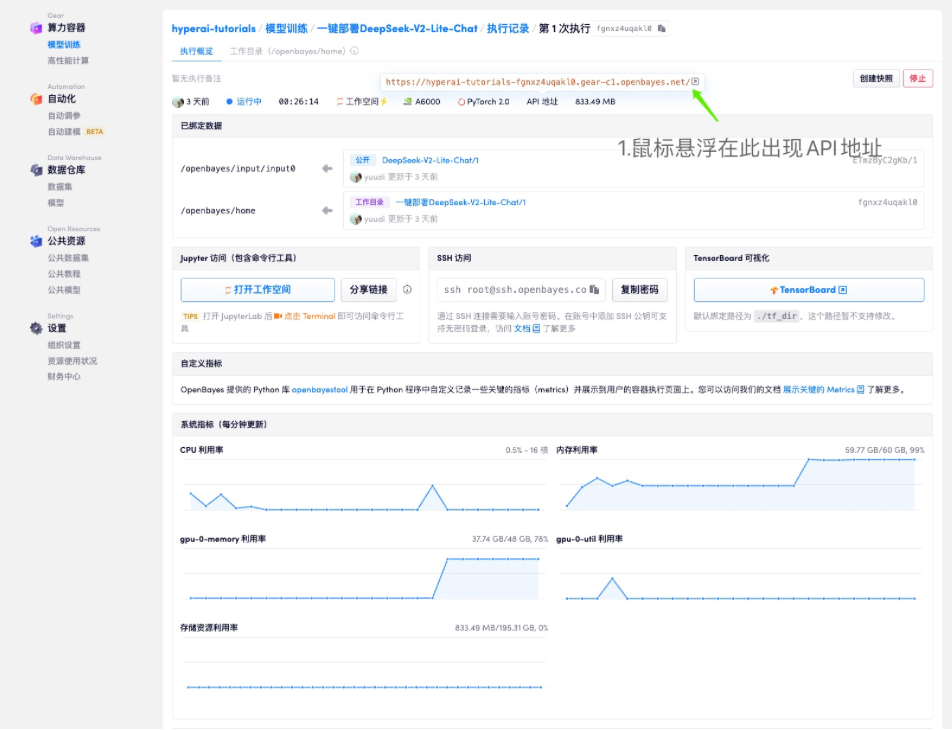
第一步:克隆启动容器
克隆启动容器成功后,看到该界面,稍等十几秒加载模型后复制右侧 API 地址到浏览器
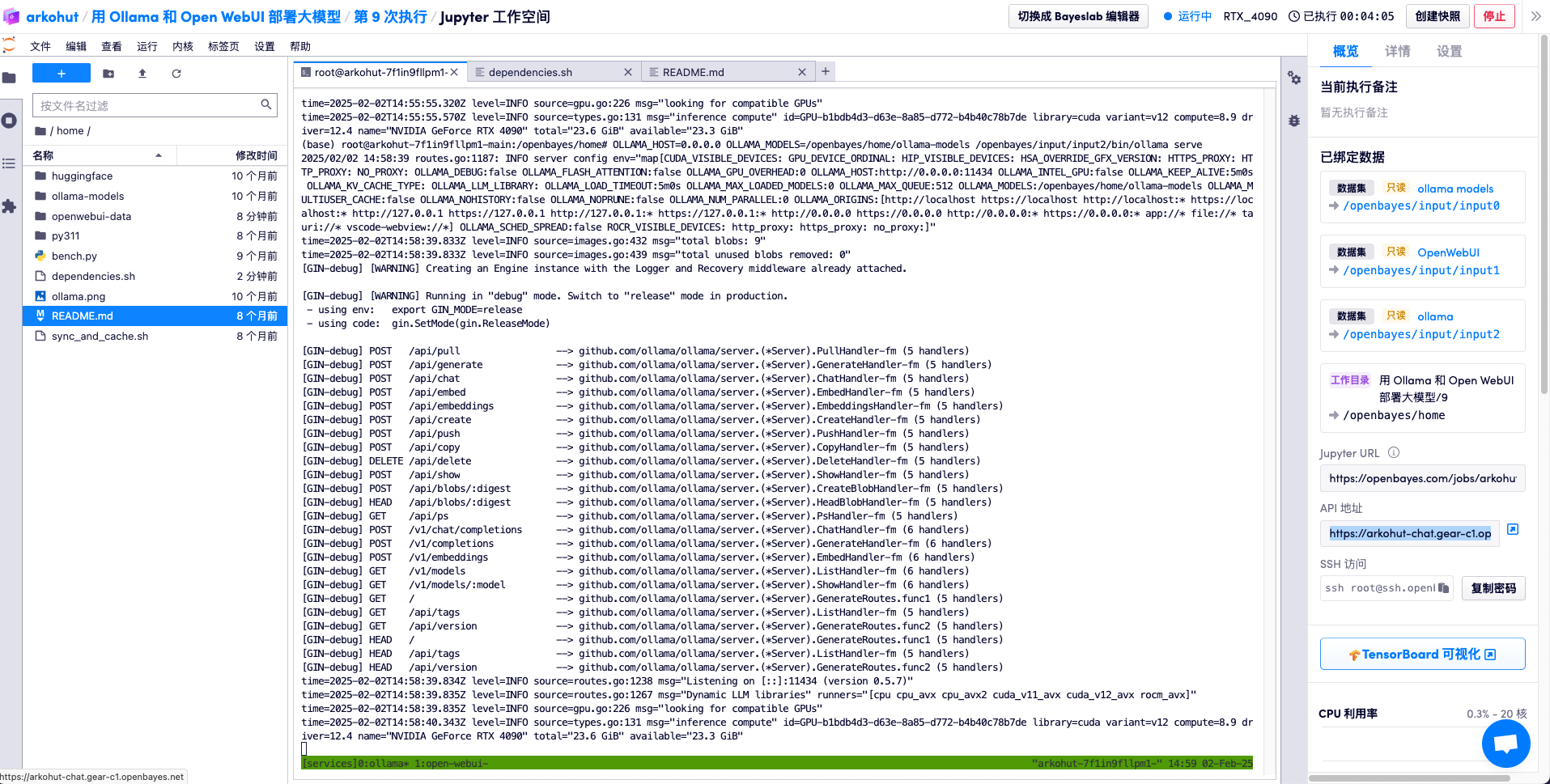
增加新的模型
在命令行通过命令 ollama pull 可以下载新的模型,新的模型会占用自己的空间。
-
下载安装ollama
-
下载模型
在终端中执行以下指令:
$ ollama run deepseek-r1:7b
配置好后运营模型

-
故障排除
访问链接时报错 “Bad Gateway”
可能原因
- 程序尚未完全启动:程序可能仍在初始化过程中,导致暂时无法访问。
- 程序启动失败:程序可能由于某些原因未能成功启动。
解决方案
- 等待一段时间:程序启动过程中,可能需要等待数分钟。请耐心等待,然后再次尝试访问链接。
- 检查程序状态:如果等待后仍无法访问,您可以在 JupyterLab 的终端中使用
tmux查看程序的运行状态和可能的错误信息。
import requests
query = "test"
url = f"http://html.duckduckgo.com/html/?q={query}"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=headers)
if response.status_code == 200 and "result" in response.text.lower():
print("DuckDuckGo search is working!")
else:
print("DuckDuckGo search may not be working.")
使用效果
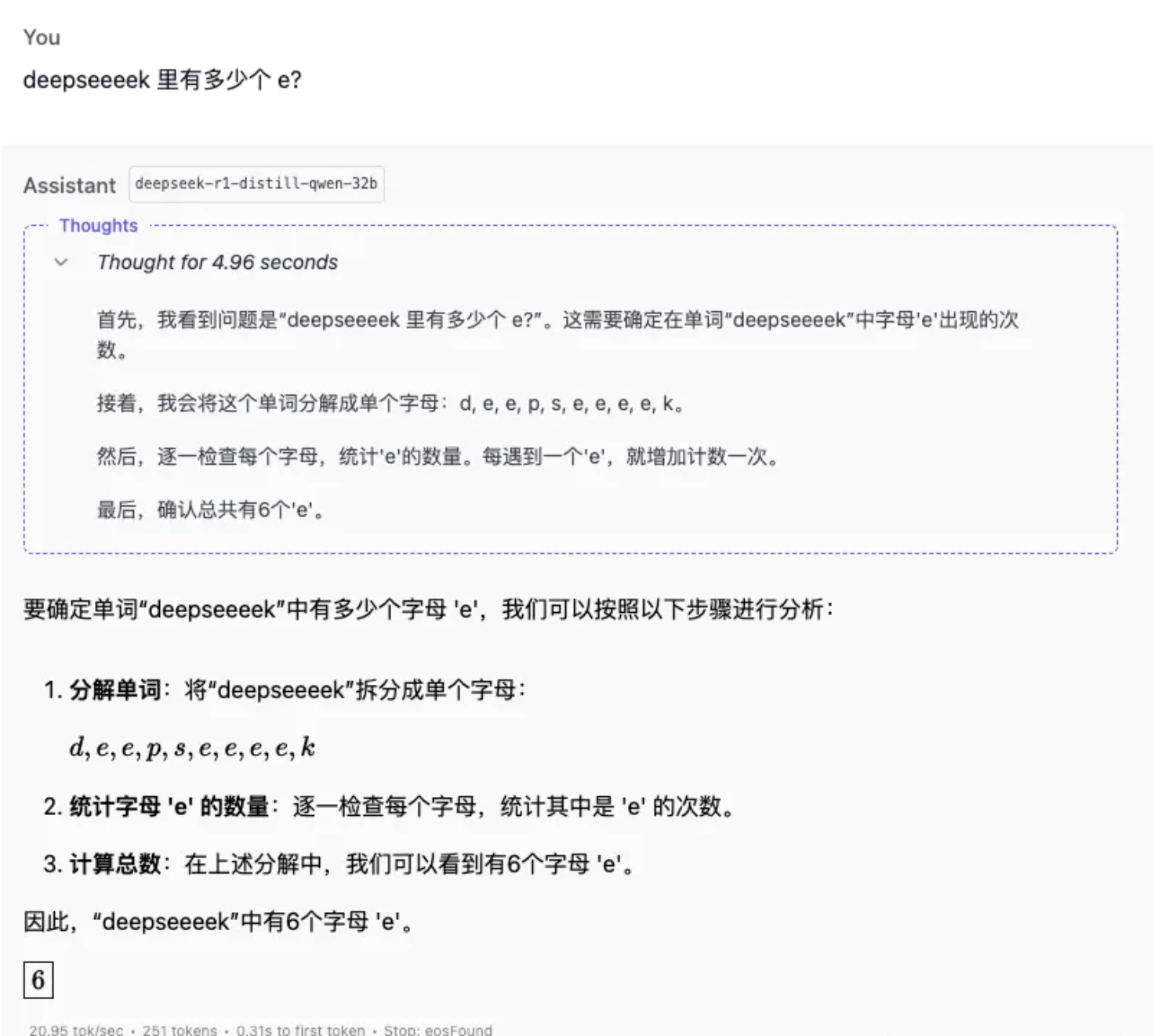
问题1:「deekseeeek 里有多少个 e?」
-
先看看8B的模型是如何回答的?

显然8B的模型将问题中的Deepseeeek当做了知识库中的“deepseek”,给出6个e的答案。
-
看看14B模型回答的答案

14B的模型也没有回答正确。测试只有32B的模型回答正确。可见模型越大,模型越聪明。
总结
DeepSeek是目前推理效率最高的模型,私有化部署模型有助于企业将私有化的数据与LLM结合。解决具体的企业问题,提效研发。
关注“AI拉呱公众号”一起学习更多AI知识!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)