DeepSeek本地化部署架构和使用原理
更高的值,如0.8,会使输出更随机,而更低的值,会使其更加集中和确定。网上有非常多的关于DeepSeek的文章,都是其技术特点和优势以及如何提问让结果更准确的科普文章,对应用中的一些基本问题却很少提及,结合最近的一些学习内容,整理一篇DeepSeek的常见术语及私有化部署中常遇到的几个问题,供大家参考。对于政府和集团性企业来说,集约建设是首选模式,由一个单位或部门牵头先部署一套,其他单位和部门先共

DeepSeek最近大火,尤其在自然语言处理方面的能力,受到全世界各行各业的广泛关注。网上有非常多的关于DeepSeek的文章,都是其技术特点和优势以及如何提问让结果更准确的科普文章,对应用中的一些基本问题却很少提及,结合最近的一些学习内容,整理一篇DeepSeek的常见术语及私有化部署中常遇到的几个问题,供大家参考。
一、本地化部署架构
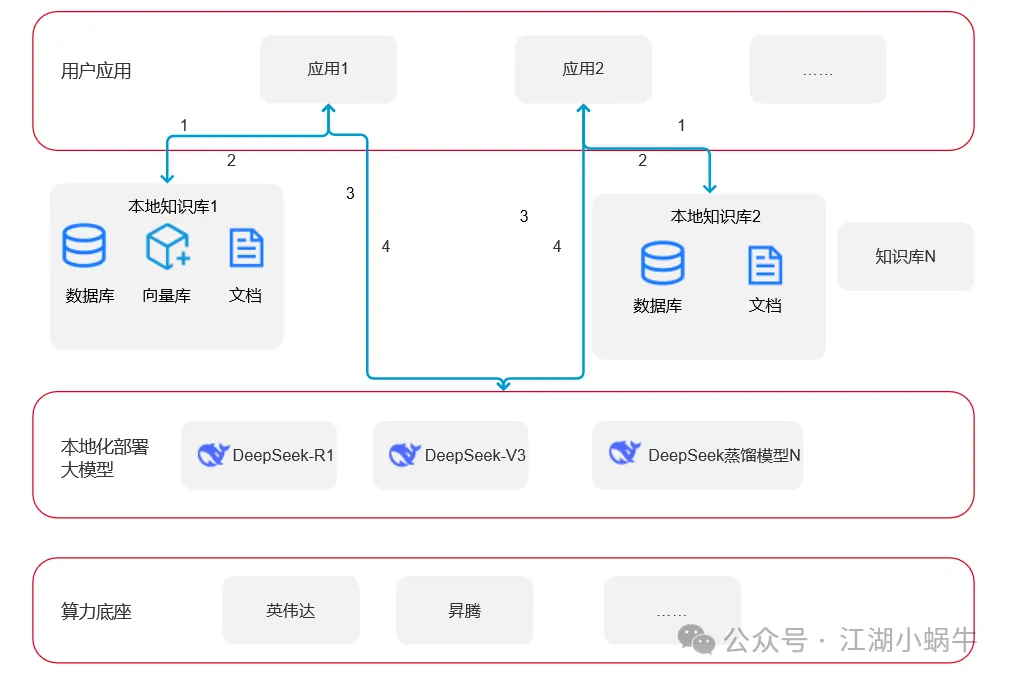
本地化私有部署的技术方案和使用的框架有很多,这里暂不涉及如何部署及涉及的技术原理,先说下主要的部署架构。
1、算力底座。我们假设是针对企业、政府等大型应用场景,对算力要求比较高,首先需要购买一定的算力资源,主流的主要有英伟达和国产的昇腾芯片,按需选择即可。如果个人实验的话,用个人电脑也能部署一套大模型。
2、本地化部署大模型。有了算力资源(其他服务器、网络等资源这里不做体现),可以部署DeepSeek-R1/V3 671B及各种蒸馏版本的模型,当然也可以部署其他的模型,这里以DeepSeek为例说明。本地化部署完成后,可以对外提供统一的API调用接口。
3、本地知识库。从应用的角度来看,本地知识库不是必须建设的,部署好DeepSeek后,上层应用就可以通过统一的API进行调用了。但是如果直接调用DeepSeek,由于他的知识只限于2024年7月份之前的信息,所以很多新的信息他是不掌握的。搭建本地知识库能够获得自己单位、部门相关性更高的知识,回答的内容更精准。本图中所示的知识库1、知识库2是物理隔离的。
4、用户应用。应用可以是网页、APP、小程序等各类应用,不限形式,需要研发人员支持对接知识库和大模型,提供更好的功能。
二、本地化部署+知识库的调用流程
图中步骤1、应用查询本地知识库。用户访问应用,提出问题;应用将问题向量化,然后先去本地知识库查询相关的内容。
图中步骤2、获取本地知识库的内容。根据用户的问题,检索本地知识库相关性更高的内容,将查询到的内容返回给应用。
图中步骤3、应用调用本地DeepSeek服务API。应用对2的结果做相应的转换和适配;拿结果作为输入调用DeepSeek的API。
图中步骤4、DeepSeek重新组合,返回结果。DeepSeek收到问题,结合已经学习的知识,加上本地知识库检索到的新知识,重新排列组合,生成全新的内容;把生成的内容返回给应用;应用将返回结果做呈现。
三、本地化部署的几个问题
1、为什么需要本地化?
简单来说就是调用官方的模型,效率和稳定性上无法满足政府、企业商用的需求,调用官网或其他厂家推出的大模型,一般按照使用量进行收费,后期成本不可控。本地部署,优点是:专门供本单位使用,稳定性、效率都能保证,并且没有调用次数的限制。缺点:前期投入大,对人员技术水平要求较高,安全方面需要投入更多资源。
对于政府和集团性企业来说,集约建设是首选模式,由一个单位或部门牵头先部署一套,其他单位和部门先共用一套模型的能力,降低前期的投入,当后续使用量逐步增大以后,可以考虑架构的优化和演进。
2、为什么需要知识库?
一句话总结:调用大模型时需要建设本地知识库的主要原因是为了解决大模型的幻觉问题并提升其在特定领域的应用效果。
大模型如GPT、千问、DeepSeek等通用大模型在特定场景下容易产生幻觉问题。幻觉问题指的是大模型生成的内容看似合理,但实际上包含错误、虚构或矛盾的信息,这严重影响了其可靠性和应用落地。幻觉问题的原因包括数据缺陷、参数知识偏置、对齐不足、解码策略缺陷以及多模态局限等。
通过构建本地知识库,可以显著缓解大模型的幻觉问题。本地知识库是一个存储特定领域知识的数据集,可以是结构化的数据库、文档集合或其他形式的信息源。与通用知识库不同,本地知识库专注于特定的业务需求或领域,提供更为精确的信息和上下文。本地知识库的主要作用包括:减少幻觉,通过动态检索外部知识库(如文档、数据库等),弥补通用大模型在知识时效性、专业领域覆盖等方面的缺陷,生成更可信的答案;动态数据支持,整合最新或专有数据,无需重新训练模型,提高生成内容的实时性和准确性;透明度高,提供检索来源作为依据,增强用户信任;多模态处理,支持文本、图像、音频等数据类型,扩展应用场景。
3、本地不同知识库的内容会不会被DeepSeek内容拿来学习和训练,以上图为例,应用2在调用DeepSeek时会不会得到知识库1的内容?
私有化部署的DeepSeek模型在本地部署后,其参数和知识范围已固化,模型本身不会通过用户调用动态学习或使用本地知识库的内容。并且提供的接口已经标明了用途,每次调用均为独立的检索过程,不会拿知识库的内容进行微调或训练,本质上仍是检索式增强,而非学习式增强。
大模型的微调和训练是需要专门的程序和训练框架,涉及数据集准备、模型选择和初始化、参数调优与训练、验证部署等,是一个复杂的系统工程。
在本图的例子中,应用1和应用2在调用DeepSeek模型时,只能分别使用各自对应知识库的内容。
注:以上回答是基于对API文档及网上搜索答案理解内容,不是DeepSeek官方回答,仅作为参考,实际使用时,务必注意信息安全,以免关键信息泄露。
4、私有化部署模式下,为什么两个人问同样的问题,得到的回答却不一样。
API调用文档里写了,其中一个参数“temperature”:采样温度,介于0和2之间。更高的值,如0.8,会使输出更随机,而更低的值,会使其更加集中和确定。如下表中是官方给出的不同场景的建议值,代码生成和数学解题需要精确的结果,不能不同的人问的结果不一样,所以值设置为0。在对话和创意写作等场景下,设置更高的值,可以保持回答结果的多样性,不会千篇一律。使用时要根据场景不同进行动态调整,设置更恰当的数值。
|
场景 |
温度 |
|---|---|
|
代码生成/数学解题 |
0.0 |
|
数据抽取/分析 |
1.0 |
|
通用对话 |
1.3 |
|
翻译 |
1.3 |
|
创意类写作/诗歌创作 |
1.5 |

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)