DeepSeek V3/R1 推理效率分析: 满血版逆向工程分解
之前的一些“意外地受到了挺多同学的关注,很多同学在评论区也提出了相关的疑问。尽管从“估计上限”这个目标来说,上次的分析完成了它的使命(避免了一些天方夜谭的数字上限,变成打工人的索命KPI),但是对于已经放出来timeline的DeepSeek R1性能估计来说还是太糙了。
1. 前言
之前的一些“不负责任”定性估计意外地受到了挺多同学的关注,很多同学在评论区也提出了相关的疑问。尽管从“估计上限”这个目标来说,上次的分析完成了它的使命(避免了一些天方夜谭的数字上限,变成打工人的索命KPI),但是对于已经放出来timeline的DeepSeek R1性能估计来说还是太糙了。方法论上存在以下几个问题:
a) 上界可达性:
联合考虑计算和通信两者,在不开启MTP的情况下,R1的 EP256 H800 FP8单卡吞吐的上限在3300(combine BF16)-5000(combine FP8) tokens/s,H20 的上限在1600 tokens/s 左右。
记单卡吞吐为 T ,之前用了一个naive 的吞吐估计方法—— 。尽管这样取出来的最小值一定是最终吞吐的上界,但不一定是一个“可达上界”: 是一个相对紧且实际的bound,但是用 不应该直接取峰值算力折合吞吐 ,它的实际取值往往和MFU及overlap设计有关:
-
• 对于H800, 如果网络通信无法完全掩盖计算(即 ),那么 是不可达的,此时可达上界取决于 。
-
• 对于H20, 尽管有 ,然而也需要考虑MFU的折损,实际可达的吞吐只能是 , MFU主要取决于非通信算子的实现效率。
b) Expert 饱和点的计算
上次饱和点估计时使用到了 ,这里取饱和点的时候用的是dense gemm估计的一个batch值(来源于我之前BF16 gemm的经验外推),有以下几个问题:
-
• 一方面是没有测过完整的FP8 gemm 测试曲线,对饱和点可能有较大偏差;
-
• 另一方面没有考虑group gemm对TFLOPS的提升——使用 假设的是单个expert gemm就能打满GPU 算力,显然忽略了当gemm尺寸较小时group gemm对SM利用率(从而对整体TFLOPS)表现的提升。这样算出来的结果会导致设备数 d 的估计偏大,无法实现很多同行最关心的问题——更少的卡数组EP是否能达到同样效果的讨论。
-
• 考虑Group Gemm, 应该是一个与 、 相关的值,与等式左边的 相关。
针对上述问题,本着自己挖坑自己埋的操守,本文希望结合DeepSeek放出来的所有公开信息:FlashMLA[1]、DeepEP[2]、DeepGemm[3]、Profile-data[4],及DeepSeek V3/R1 推理系统概览,对DeepSeek EP144 做一个比较完备的逆向工程 :D。笔者水平有限,如有错漏欢迎指出。
注:这里不再区分V3和R1,而是使用DeepSeek V3/R1 推理系统概览里的平均分布来统称“满血版”。既然要对齐官方,这里相对之前做估计的时候的粗糙假设修正了两个地方:
1. 考虑shared expert 每个设备都存放副本,而不是EP320 一样shared expert 冗余分布在独立节点
2. 考虑专家冗余,prefill与decode 都为 256 个路由专家+32个冗余专家
2. DeepSeek 满血版逆向工程分析
DeepSeek 官方放出来的关键数据
-
• Prefill:路由专家 EP32、MLA 和共享专家 DP32,一个部署单元是 4 节点,32 个冗余路由专家,每张卡 9 个路由专家和 1 个共享专家
-
• Decode:路由专家 EP144、MLA 和共享专家 DP144,一个部署单元是 18 节点,32 个冗余路由专家,每张卡 2 个路由专家和 1 个共享专家
-
• 输入 token 总数为 608B,其中 342B tokens(56.3%)命中 KVCache 硬盘缓存。
-
• 输出 token 总数为 168B。平均输出速率为 20~22 tps,平均每输出一个 token 的 KVCache 长度是 4989。
-
• 平均每台 H800 的吞吐量为:对于 prefill 任务,输入吞吐约 73.7k tokens/s(含缓存命中);对于 decode 任务,输出吞吐约 14.8k tokens/s。
2.1 平均 P/D 长度
这里按 @天阿西吧 在之前评论区提到的算法:
假设P代表sequence的平均输入长度,D代表sequence的平均输出长度,那对于每一个输出token的平均KVcache的长度约等于P+D/2=4989; 再加上P/D=608B/168B;P的取值大概为4383,D的取值大概为1210。
因此 ,attention kvcache平均长度为 = 4989 \approx 5000
2.2 平均 P/D 实例数
为了达到P/D 的消费均衡,来看一下4节点的Prefill instance和18 节点的Decode instance配比:
设prefill node 为 组,decode node 为 组,平均意义上 = 226.75
-
• 从输入总吞吐量来反推,并发度约为
-
• 从输出总吞吐反推, ,那么可以估计出平均意义上P/D组建的集群配置为
即平均 24组prefill实例与7组decode实例,能比较均衡地支持DeepSeek所需线上负载。
2.3 Prefill 分析
根据 prefill的timeline[5] setting,prefill 用的4k的prompt,每卡16k tokens做2 microbatch。因此可以推断单个microbatch的b=2, s=4096。因为prefill overlap的方式两个microbatch 负载均衡,这里先只考虑单个microbatch的。
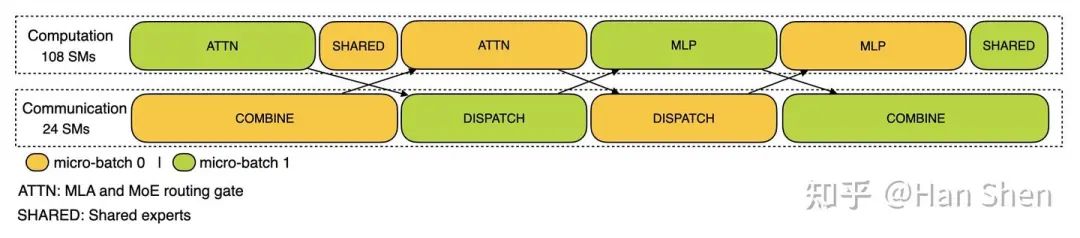
DP-32, EP-32 prefill 2-microbatch overlap timeline
2.3.1 prefill 单microbatch 单层profiling
核心计算部分
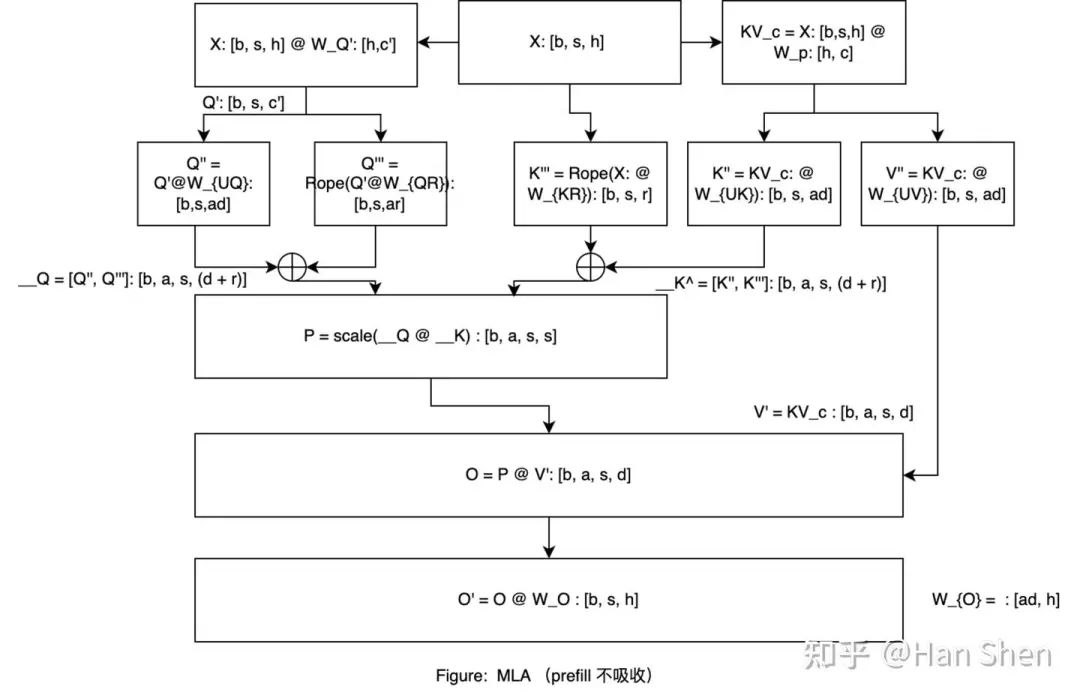
给一个之前画的比较糙的prefill MLA 示意图, 符号和这里定义的不太一样,有一点abuse大家能看明白就行:
,

网络通信部分
由于只有4台机器,网络上限的估计符合我们之前谈到的intra-device deduplication的传输方式,这里总共4个节点,所以最多每个token往外发3个副本,因此通信量:
Dispatch(单层)
Combine (单层)
得到计算量和通信量之后,我们对prefill.json 的timeline 时间进行分析:

prefill timeline overlap 真实情况
单层单microbatch 耗时与TFLOPS分布
这里为了overlap 计算普遍采用了108 个 SM core,通信采用24个SM core。Gemm计算相比独占牺牲了10%~20%的MFU。
|
浮点计算数(GFLOPs) |
Duration(us) |
TFLOPS |
|
|
Dense Gemm & MLA |
|||
|
X@(Concat(W_Q', W_p,W_{KR}))[7168,2112] |
248 |
268 |
925.5 |
|
Q' @Concat(W_{UQ}, W_{QR})[1536,24576] |
618.5 |
922 |
670.8 |
|
KV @ Concat(W_{UK}, W{UV}[512,32768] |
274 |
533 |
515.7 |
|
MHA Attention |
1392 |
2683 |
519 |
|
O Projection[16384,7168] |
1924 |
1652 |
1164.7 |
|
Expert Gemm |
|||
|
Shared Up&Gate[7168, 4096] |
481.04 |
439 |
1095 |
|
Shared Down[2048, 7168] |
240.5 |
306 |
786 |
|
Routed Up&Gate[7168, 4096] |
3848.3 |
3534 |
1089 |
|
Routed Down[2048, 7168] |
1924 |
2381 |
808 |
|
Communication |
|||
|
通信量(MegaBytes) |
Duration(us) |
Bandwidth(GB/s) |
|
|
Dispatch notify |
743 |
||
|
Dispatch Alltoall |
168 |
4326 |
38 |
|
Cache notify |
788 |
||
|
Combine Alltoall |
336 |
8845 |
37 |
|
Others:In total 3004 us |
|||
|
Attn part: add & LayerNorm & Rope |
549 |
||
|
Attn part: Attn BF16-to-FP8 to O projection |
232 |
||
|
Gate part: router gate & prepare shared gemm |
529 |
||
|
Expert part: prepare router gemm |
728 |
||
|
Expert part: Swiglu |
314 |
||
|
Expert part: Combine reduce |
594 |
主要计算耗时12.7ms
|
GFLOPs Duration(us) |
Model |
TFLOPS |
MFU |
|
Gemms + Attn (SM 108) |
10950 |
12718 |
861 |
|
Gemms + Attn + MemoryOps (SM 108) |
~10950 |
15722 |
696 |
2.3.2 prefill 单卡吞吐分析
prefill timeline 吞吐分析
从2.3.1 的 timeline 看,整个prefill 单次forward的总时长约为2118ms,对应单次forward 吞吐为 ,
而理论值
-
• 通信带宽按38GB/s来算,
-
• 算力峰值来看,
,
实际达到
,
基本与实际情况匹配。
prefill 线上平均吞吐分析
根据线上数据,prefill 的单卡吞吐大约为 。
结论:可以看出,deepseek的峰值吞吐在负载均衡下能达到7735 tokens/s,之前平均数据得到的4k tokens/s是一个考虑到了全天波峰波谷没有打满/或者负载不均衡无法完全overlap的值。
2.4 Decode 分析
由于DeepSeek 官方尚未发布EP144 的decoding timeline,decoding部分的profiling数据来源于DeepGemm、FlashMLA的实测与少量估计:
让我们假设per GPU b_{mla} 约为profile_data 里的128。于是每个micro-batch 的 。
根据DP144-EP144,expert 部分的router expert 平均接收到 ,即 ,单卡 。
2.4.1 decode 单microbatch 单层profiling
考虑 MLA 吸收矩阵,稍微和prefill不太一样:
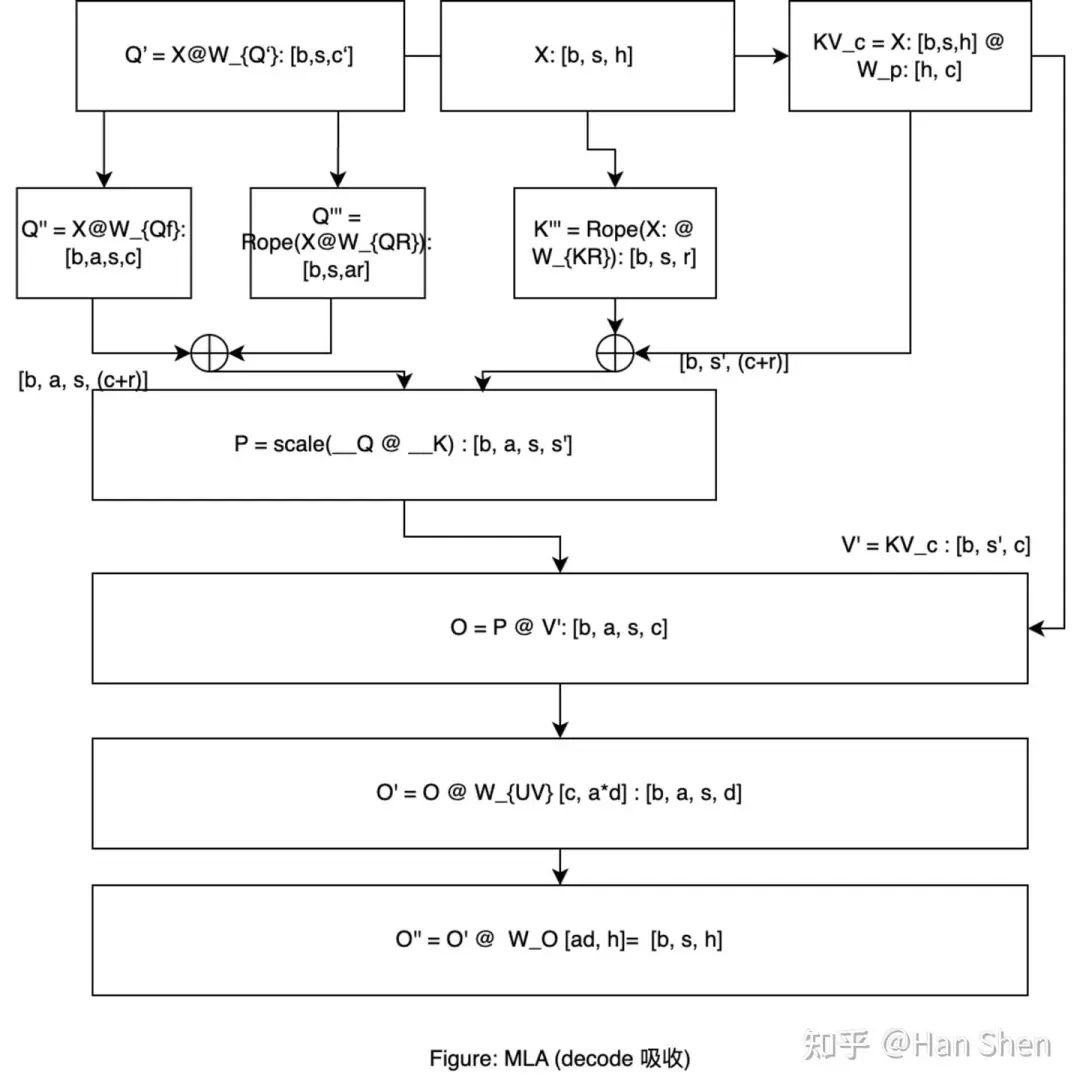
核心计算部分

网络通信部分
由于decode 节点数不会太小,我们先假设会有8台以上机器。网络上限的估计按通信最不友好的方式,往另外8个节点法,所以最多每个token往外发8个副本,因此通信量:
-
• Dispatch(单层
-
• Combine (单层)
访存密集算子的耗时根据2.3里prefill 的耗时按token数等比折算(在带宽bound下相对合理), 比如对于router gate & prepare shared gemm: ;
ContextLen 按DeepSeek 实际 带入
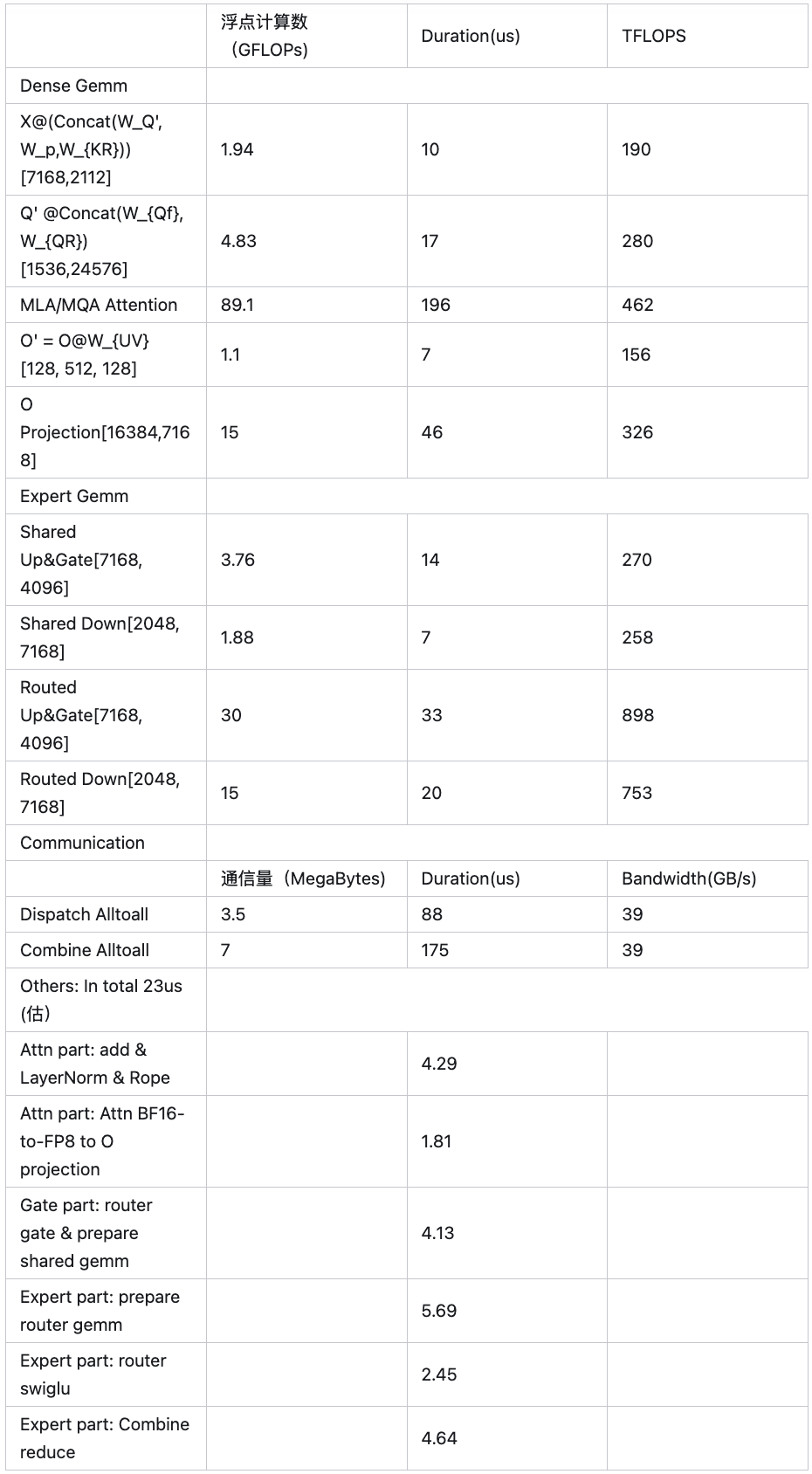
主要计算耗时350us
|
GFLOPs Duration(us) |
Model |
TFLOPS |
MFU |
|
Gemms + Attn (SM 132) |
163 |
350 |
464 |
|
Gemms + Attn + MemoryOps (SM 132) |
~163 |
373 |
437 |
2.4.2 decode 单卡吞吐分析
decode timeline 吞吐分析
由于没有完整的timeline,我们对decode 整个耗时进行一次拆解:
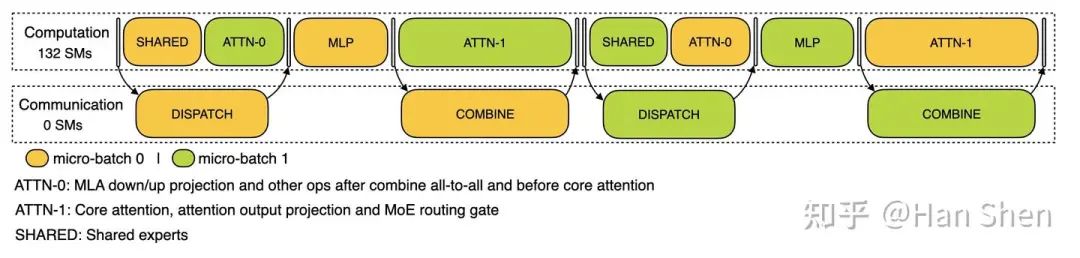
DP-144, EP-144 decode 2-microbatch overlap timeline
-
• Shared + Attn0
Shared + MLA down/up gemm + AfterCombineReduce + BeforeCoreAttention, 10+17+14+7+4.1+4.6+4.29 = 61 us < 88us。这部分没有完全藏住通信,因此88us -
• MLP 部分
Prepare + Router Gemm + SwiGlu: 5.69 + 33 + 20 + 2.45 = 61 us -
• Attn1
Core attention + O projection + Routing gate: 196 + 7 + 46 + 1.81 + 4.13 = 254 us > 174us,盖住了combine,因此约254us
因此单层forward时间约为88+61+254 = 403, 前三层没有通信 373 us差不多,于是单iter forward 时间(包括2个microbatch)约为
这意味着TPOT 大约在50ms,也就是per user 平均 20-21 tokens/s 左右的延迟,同时单卡吞吐约为 。
decode 线上平均吞吐分析
根据线上数据,decode 的单卡吞吐大约为 14.8 * 1000 / 8 = 1850 tokens/s,实际单卡并发数为 per GPU
左右 。
结论:可以看出,deepseek的峰值吞吐在负载均衡下能达到2612 tokens/s,之前平均数据得到的1850 tokens/s是一个考虑到了全天波峰波谷没有打满的值。
2.5 Overlap 方式的选择
从官方的pipeline 示意图我们可以发现,prefill 和decode 用到了不一样的overlap策略,其中prefill 部分匀出了24个SM core 进行通信,而decode 部分并没有消耗SM。
我们先忽略为了追求延迟在decode 引入IBGDA实现上的差异,先看看如果想要讲通信与计算overlap,我们怎么设计:
笔者推测,引入IBGDA主要是在小传输量下达到更低的延迟,在DeepEP里体现为更高的等效带宽,不影响overlap分析。
对于prefill来说,Gemm计算密集型的算子占据主导,因此可以基本忽略memory-bound的算子开销。可以先画出蓝色部分的单microbatch 时序依赖图。剩下的工作时如何将 dispatch (dispatch notify + alltoall ~ 5ms) 与combine(cache notify + alltoall ~ 9.6ms)带来的bubble填满。我们很容易的发现,QKV + Core Attention.+ O projection的计算时间约为6ms,而MLP 计算时间约为5.9ms,两者正好与dispatch 的耗时相近且依赖错开。于是很自然地构造出下面双batch overlap方式:为了尽量填满combine,将shared expert计算挪到了与combine overlap的位置。
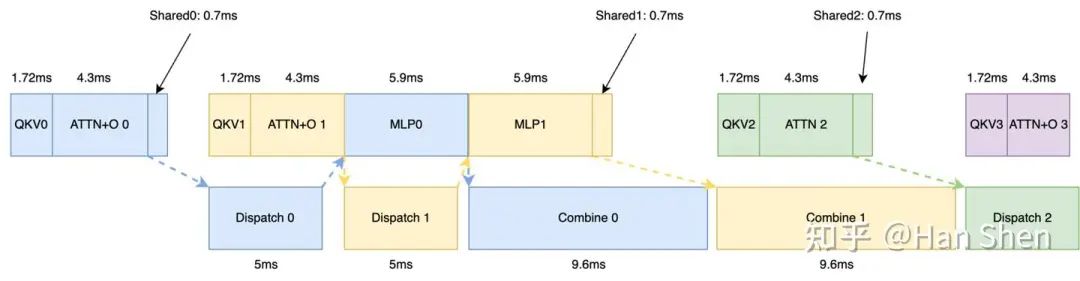
Prefill overlap 示意
由于decode gemm算子都相对较小,这里无法忽略memory bound的算子开销,
我们用以下符号来表示:
QKV(QKV Attn part: add & LayerNorm & Rope + QKV gemm) = 10 + 17 + 4.29 = 31.3us
ATTN + O + Gate(Core MLA Attention + O projection + Routing gate): 196 + 7 + 46 = 249us
Shared(Prepare + Shared expert gemms): 4.13 + 14 + 7 = 25.1 us
注:因为Gate耗时较小,这里还是加到Shared里了
MLP( Prepare + Router Gemms + SwiGlu): 5.69 + 33 + 20 +2.45 = 61us
对于decode来说,也是先画出单microbatch的时序依赖,如下图蓝色模块。
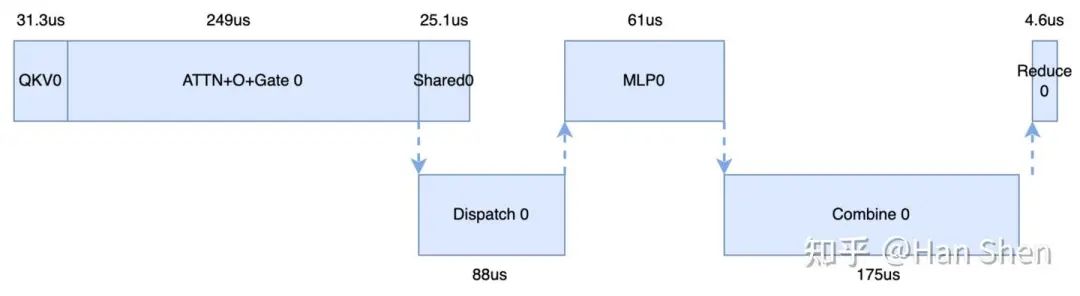
我们发现由于MLA Core Attention 的计算在decode部分占据了主导部分,不能再继续把MLA Core Attention 与Dispatch overlap了,而是应该尽量让Core Attention 与Combine 进行overlap。于是易得下面的overlap方式,与官方给出的overlap 方式一致。

3. 结论
至此,我们对DeepSeek 放出来的信息做了一个相对完备的拆解。本来寄希望于在本文里完成更多泛化性讨论的,但是工作量实在是有点大,阅读起来也会相对困难,如有关心的朋友,请等等下一篇 TAT。

如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 23
23 0
0- 0



 已为社区贡献127条内容
已为社区贡献127条内容

所有评论(0)