AI 如何助力企业数字化转型?五个行动建议_ai如何帮助数字化转型顾问
AI,特别是生成式AI在春节期间因为中国的DeepSeek引发关注之后,领导人的关注,投资人的热捧,媒体的火爆,让朋友见面,除了聊AI,貌似已经没有什么话题了,《哪吒2》都盖不住了。这也带来了很多人的焦虑。这波AI的热潮,普及了AI的热潮,也让很多企业家认识到,如果不拥抱AI,就不能顺应时代发展,被时代淘汰了。面对AI的快速发展和普及应用,对企业来讲,不应用就会被淘汰,为什么呢?因为AI赋能的是企
问题
基于 Llama 的模型都有哪些?有什么细微的差异?
Llama 生态
现在的模型架构基本都是 Llama 了。即使本来也有一些自己独创的结构,但是随着 Llama 生态环境的日趋统一,也都被迫向 Llama 低头了,不然没人适配你的特殊架构,自然就不带你玩了。比如 GLM 之前属于 Prefix LM,但是现在也变成 Llama 类似了。
虽然大家都长的很像,但是细微之处还是有些不太一样。今天就聊聊跟 Llama 很像的模型之间的细微差异。
Llama 目前有3代,先看一下 Llama 自己的变化,然后再以 Llama 为基准看一下其他模型与 Llama 的不同。
Llama 1 2 3
Llama 1
Llama 1 的架构是基于 GPT 来的,做了如下的升级:
- 采用了 Pre-RMSNorm
- 把 Gelu 改成了 SwiGLU
- 位置编码改成了 RoPE
需要注意的是,这些内容都不是 Meta 首创的,但是 Meta 的 Llama 团队将他们组合到了一起并且取得了开源的 SOTA 效果。至于闭源的,那肯定早都用了。
其结构如下所示(Llama 7B):
LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(32000, 4096, padding_idx=0)
(layers): ModuleList(
(0-31): 32 x LlamaDecoderLayer(
(self_attn): LlamaAttention(
(q_proj): Linear(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear(in_features=4096, out_features=4096, bias=False)
(v_proj): Linear(in_features=4096, out_features=4096, bias=False)
(o_proj): Linear(in_features=4096, out_features=4096, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP(
(gate_proj): Linear(in_features=4096, out_features=11008, bias=False)
(up_proj): Linear(in_features=4096, out_features=11008, bias=False)
(down_proj): Linear(in_features=11008, out_features=4096, bias=False)
(act_fn): SiLU()
)
(input_layernorm): LlamaRMSNorm((4096,), eps=1e-06)
(post_attention_layernorm): LlamaRMSNorm((4096,), eps=1e-06)
)
)
(norm): LlamaRMSNorm((4096,), eps=1e-06)
(rotary_emb): LlamaRotaryEmbedding()
)
(lm_head): Linear(in_features=4096, out_features=32000, bias=False)
)
Llama 2
Llama2 和 Llama1 结构基本相同,但是在更大的模型上(34B和70B) 采用了 grouped-query attention,主要是为了加速。
还有就是将上下文从 2048 扩展到了 4096.
Llama 3
Llama3 做了如下改变
- GQA 变成标配。
- 上下文 从 4096 扩展到了 8192
- 词表大小从 32k 变成了 128k。前两代都是基于 SentencePiece 的,Llama 3 直接采用了 Openai 的 tiktoken。因为 tiktoken 用 rust 进行了底层的深度优化,效率比其他家要好很多。
Baichuan 系列
Baichuan 1
Baichuan 1 可以说是完全复用了 Llama 1 的架构。把权重的名字改一改可以完全用 baichuan 的代码来加载 llama 的权重。具体怎么修改的代码放在付费内容了,感兴趣可以看看。
有如下的差异:
- llama 的 qkv 三个权重矩阵,在 baichuan 里变成了一个矩阵,相当于 qkv concat 起来了。
- 扩充了 llama 的词表,加入了中文,词表大小为 64k,llama 1 为 32k。
- 上下文为 4096, llama 1 为 2048.
Baichuan 2
Baichuan 2 的架构在 Llama 2 的基础上做了一些创新。
- 在 lm_head 模块加了一个 norm,论文中说是可以提升效果
- 在 13B 的模型上采用了 Alibi 位置编码。
- 词表从 64k 扩充到了 125,696
Baichuan 3 & 4
没有开源。
Yi
yi 的架构和 llama2 一样。需要注意的是 llama2 只在更大的模型上使用了 GQA, 但是 Yi 在所有系列都用了。
在经历过一些开源协议的质疑之后,现在 yi 的模型可以用 LlamaForCausalLM 加载了。
Qwen
Qwen 1
Qwen 1 和 Llama 1 的区别如下:
- qkv 矩阵和 baichuan 类似,变成了一个 concat 后的大矩阵。
- 这个 qkv 的矩阵有 bias,这一点和大多数模型都不一样。这是因为苏剑林的一篇文章,认为加入 bias 可以提高模型的外推能力:https://spaces.ac.cn/archives/9577
- 词表大小为:151936
- 训练的长度是2048, 但是通过一些外推手段来扩展长度。
Qwen 1.5
其实 Qwen 1.5 开始,比起 Llama 就多了很多自己的东西,只不过 Qwen 1 仍然和 Llama 很相似,所以这里也一并写一下吧。
1.5 的版本更像是在 1 的基础上做了很多扩展,重点如下:
- 扩展长度到 32K
- sliding window attention 和 full attention 的混合
- 32B 的模型尝试了使用 GQA
- tokenizer 针对代码做了一些优化。
Qwen 2
Qwen 2 包含了 1.5 的所有改变。和 llama 2 的区别:
- qkv 矩阵有 bias
- 全尺寸使用了 GQA
- 上下文扩展为 32K
- 采用了 Dual Chunk Attention with YARN
- 还有一点就是在同等尺寸上,Qwen 2 相对于 1.5 和 1,将 MLP 模块的 hidden size 变大了,其他模块的 hidden size 变小了。以提高模型的表达的记忆能力。
- 词表又扩充了一点点。
ChatGLM
GLM 最开始的时候采用的是 Prefix LM,但是后来也都改成 Decoder Only LM 了。
所以虽然 GLM 要早于 Llama,但是最后还是和 Llama 变得很像。上面提到的其实最像 Qwen 1.
所以也说一下与 Llama 的区别:
- qkv 矩阵和 baichuan 类似,变成了一个 concat 后的大矩阵。
- 这个 qkv 的矩阵有 bias。
MiniCPM
目前已经转战 size 略小一点的模型,也取得了很不错的效果。
我粗看其架构应该和 llama 3 差不多,区别:
- 采用了 Weight Tying
- 整体框架采用了 deep and thin 的结构。
有个细节是,我看论文里写的词表大小为:122,753, 似乎有点非主流。因为一般都需要设置成 8 或者64 的倍数。
Gemma
我要说 Gemma 是基于 Llama 的,Google 肯定是不承认的。
Google 有不承认的底气,毕竟 Transformers 是人家搞出来的, GLU 也是人家的,MQA 和 GQA 也是人家搞出来的。
最终发现 Llama 中除了 Pre-RMSNorm 和 RoPE,其他都是 Google 的成果。只能说 Google 真的是 “斗宗强者,恐怖如斯”。
但是最后的架构和 Llama 其实还是很像。区别如下:
Gemma 1
- MLP 的激活采用了 GeGLU 而不是 SwiGLU
- 采用了 MHA。但是 2 代还是换成了 GQA
- 使用了 Weight Tying
Gemma 2
- MLP 的激活采用了 GeGLU 而不是 SwiGLU
- 融合了 Local and Global Attention
- 使用了 Weight Tying
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
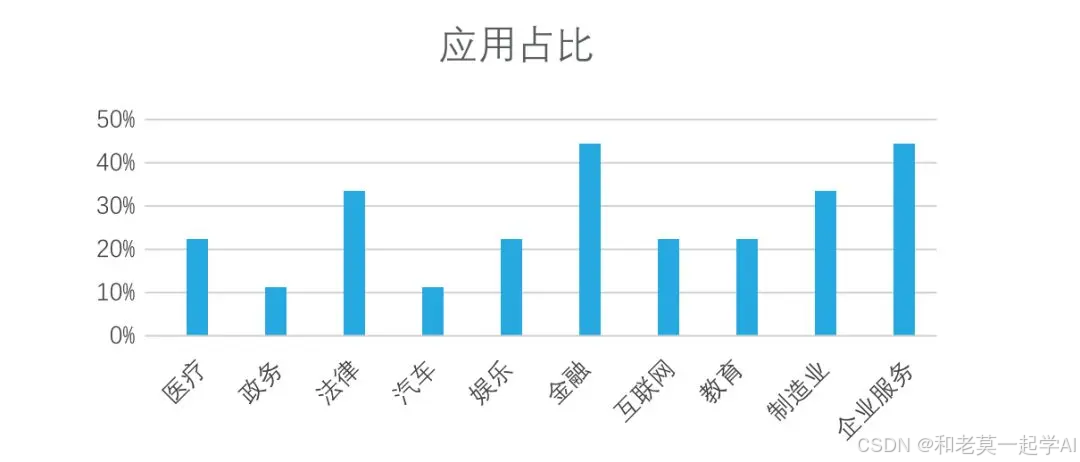
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
大模型目前在人工智能领域可以说正处于一种“炙手可热”的状态,吸引了很多人的关注和兴趣,也有很多新人小白想要学习入门大模型,那么,如何入门大模型呢?
下面给大家分享一份2025最新版的大模型学习路线,帮助新人小白更系统、更快速的学习大模型!
*有需要完整版学习路线*,可以微信扫描下方二维码,立即免费领取!

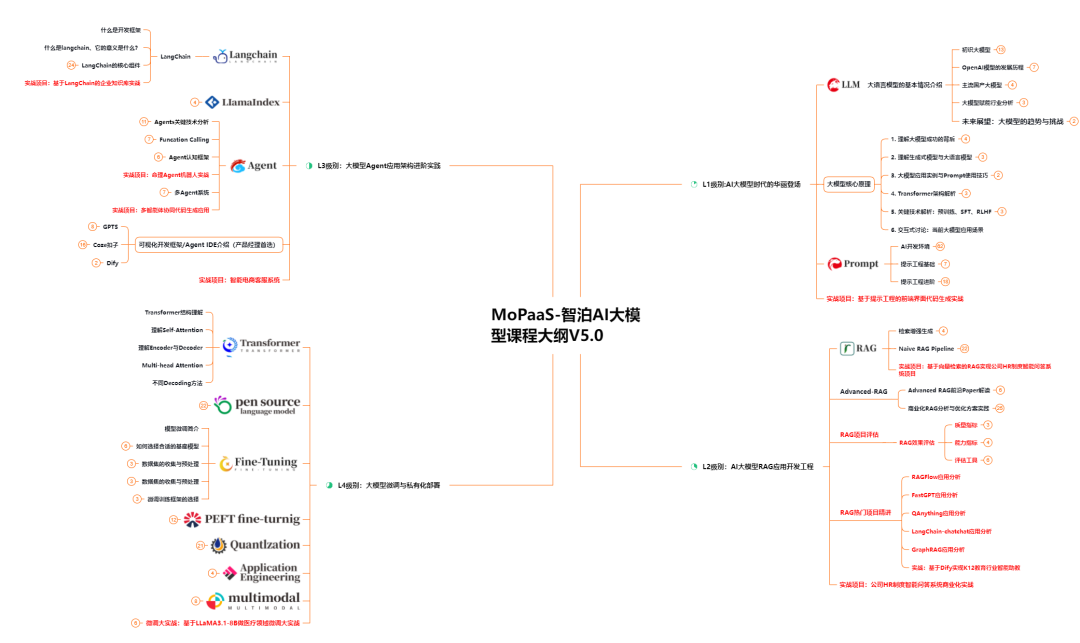
一、2025最新大模型学习路线
一个明确的学习路线可以帮助新人了解从哪里开始,按照什么顺序学习,以及需要掌握哪些知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。
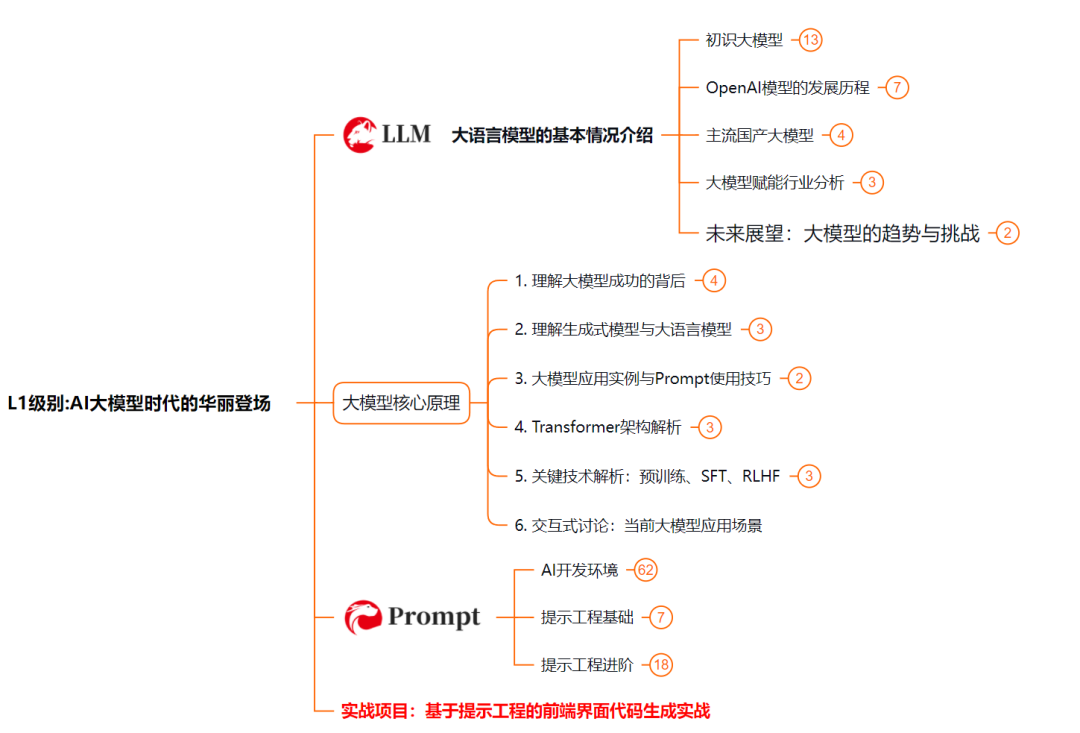
L1级别:AI大模型时代的华丽登场
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理,关键技术,以及大模型应用场景;通过理论原理结合多个项目实战,从提示工程基础到提示工程进阶,掌握Prompt提示工程。
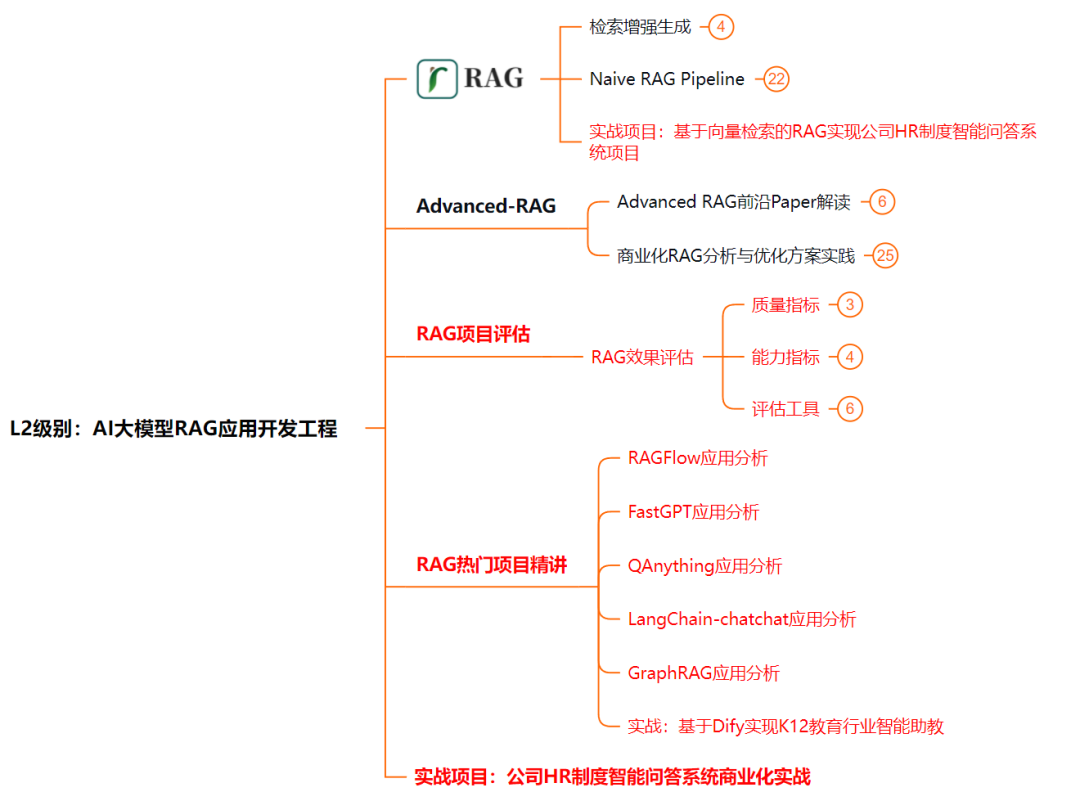
L2级别:AI大模型RAG应用开发工程
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。
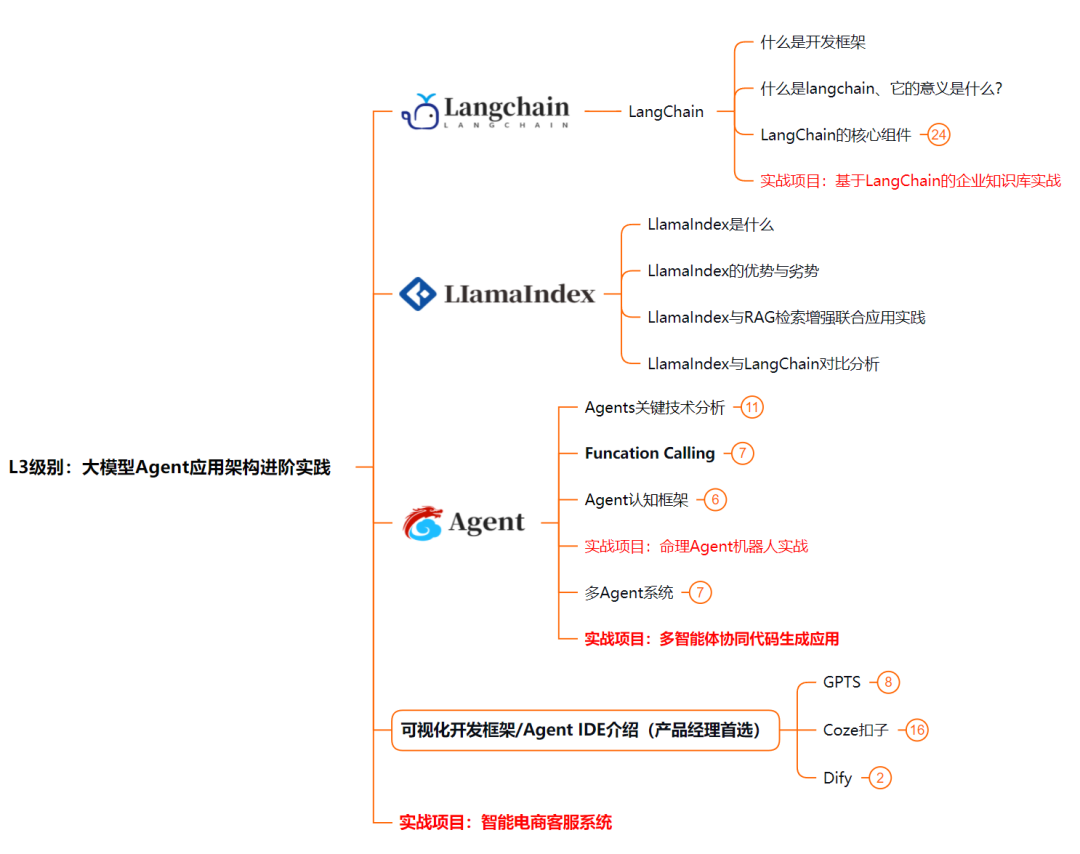
L3级别:大模型Agent应用架构进阶实践
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体;同时还可以学习到包括Coze、Dify在内的可视化工具的使用。
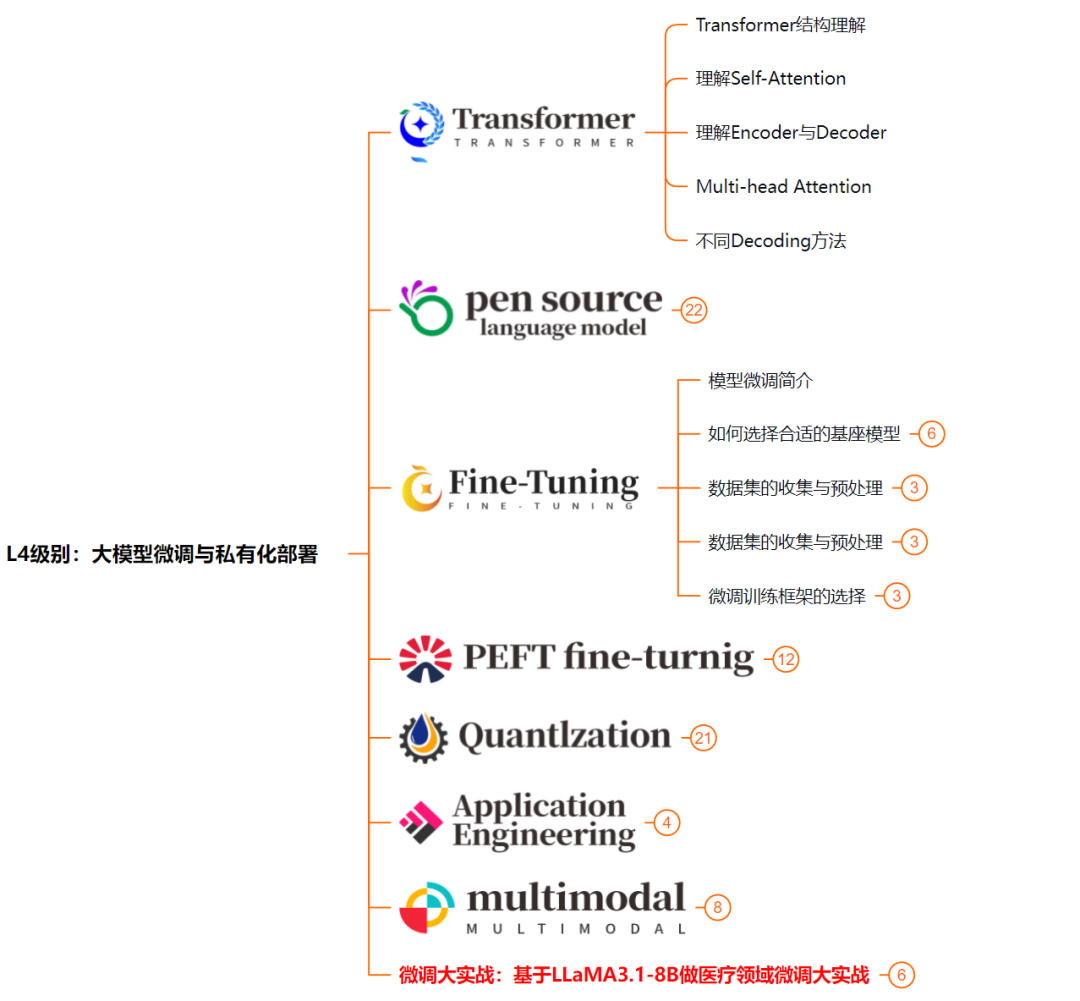
L4级别:大模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。
整个大模型学习路线L1主要是对大模型的理论基础、生态以及提示词他的一个学习掌握;而L3 L4更多的是通过项目实战来掌握大模型的应用开发,针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
二、大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

三、大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。
四、大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。
五、大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

****如果这篇文章对你有所帮助,还请花费2秒的时间**点个赞+收藏+分享,**让更多的人看到这篇文章,帮助他们走出误区。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 16
16 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)