90%的DeepSeek一体机,都是拍脑袋交的“智商税”
单机版本的优势是简单上手快,短板也很明显,没有高可用能力,数据量增长到千万级,QPS 增长到几百以上,性能就会遇到瓶颈。而高可用和可扩展性,是 Milvus 集群版的天然能力,但是集群版依赖的 K8s环境,一体机几乎很难提供,很多套壳公司也不具备这个能力,所以,现实是,大部分一体机厂商仅仅满足于Docker单机版,不做容灾,只能“祈祷”机房不出故障、数据不暴涨。最过分的,是给客户甲的产品,改个名字


前言
避雷指南:本文并非要一杆子打死所有的一体机,而是指出行业鱼龙混杂背后的真相,并给出一些避坑小技巧。
这段时间,DeepSeek一体机的热度简直到了全民高潮的地步。媒体在蹭,厂商在炒,朋友圈里的“AI从业者”都在疯狂好物推荐。
打开知乎、小红书、视频号,到处都是“一体机开箱”“部署教程”“跑通指南”,好像买上一台DeepSeek一体机,业务就能一键起飞。营销话术也是一个比一个魔幻:“家用电源插上就能跑671B满血大模型”、“一机顶一座数据中心”。
甚至就连我们在做Milvus推广的时候,也有人一直询问,能不能一起捆绑销售
但越是全网吹爆的东西,越应该警惕。
这段时间密集地拜访了一些企业用户,甚至参与了几次真实的一体机部署过程之后,我的结论很简单:一体机90%是伪需求,特别对于DeepSeek这类MoE大模型,一体机不仅不是最优解,甚至是最差的解决方案之一。
01
一体机爆火,背后是DeepSeek模型的工程化创新
DeepSeek-R1的出现,确实解决了一个关键痛点:通过MoE架构,降低了高性能大模型部署的门槛。
这里我们科普下什么是 MoE 架构?MoE,全称 Mixture of Experts(专家混合)架构,是近年来在大模型训练和推理中逐渐兴起的一种结构设计思路。
你可以把一个普通的大模型想象成一个“万能工匠”,每次任务都靠它一个人完成,什么都得会、什么都得做。
而 MoE 更像一个“专家团队”,团队里有很多成员,每个成员擅长不同的领域。但神奇的地方在于,MoE 不会每次都动用全部专家,而是通过MLA 算法(Multi-Level Activation,多层激活算法),只调用与当前任务最相关的“少数几个专家”。这样MoE就可以:效果上能“像用大模型一样强”;计算资源上却只用了一小部分专家模块,极大减少了计算量需求,这就是 “稀疏激活”(Sparse Activation) 的核心理念。
相应的,MoE 的优势是:
-
节省推理计算量:只用部分专家就能完成任务;配合量化以及蒸馏甚至可以在消费显卡中使用。
-
同等算力消耗下,模型容量更大,可以堆很多专家进来;
-
便于扩展:多个专家模块可以独立部署,更适合大集群、分布式部署。(记住这里,后面会用得到)
优势很明显,官网很卡顿,两大因素叠加,所谓的“一体机”就这么在一夜之间火起来了:GPU服务器 + DeepSeek模型 + 操作系统 + 推理框架 + 简单UI界面组合,就成了一个“开箱即用”的产品。
当然,这对那些不具备技术团队的中小企业来说,不用搭环境、不用调驱动、不用写推理逻辑,看起来确实很省心。
但历史经验告诉我们,如果一个东西又好用又便宜,还能零门槛让普通人享受到,那大概率
是
杀
猪
盘
!
原因我们在下文详细解读。
02
猫腻一:满血是个筐啥都往里装
官宣的DeepSeek-R1,其实有满血版和“残血版”之分。
DeepSeek-R1的“满血版”,在宣传中泛指671B参数模型。
而残血蒸馏版,则指的是:
Qwen-7B(70亿参数):轻巧灵活,适合简单问答、日常文本生成,跑得快但跑得轻。
Llama-8B(80亿参数):基于Llama架构优化,通用性不错,胜任分类、情感分析等基础NLP任务。
Qwen-14B(140亿参数):推理能力更上一层楼,适合对输出质量有要求的应用,如复杂问答、内容生成。
Qwen-32B(320亿参数):蒸馏版本里的“高配”,能应对一些专业领域的文本分析和智能助手类任务。
Llama-70B(700亿参数):Llama蒸馏版中的天花板,性能强通用性高,适用于多语言翻译、摘要等重场景任务。
宣传说的天花乱坠,但实际部署之后,谁用谁知道,花了不少成本,结果幻觉多到崩溃。
我们的历史文章中,有做过DeepSeek私有化部署的教程,使用的就是7B版,然后作者就被后台吐槽效果翻车的读者排队问候了一遍。
(在此鞠躬道歉,但再次声明,蒸馏版并非一无是处,而是看具体需求,虽然需要满血的还是占多数)
但搞个满血版就解决问题了吗?满血版里猫腻也不少,同样是671B,但也分为:
-
原生(FP8)版:使用FP8数据精度,显存需求大概在750GB以上,是DeepSeek官方最推荐的配置。
-
转译版(BF16/FP16):由于硬件设备限制采用BF16/FP16精度,导致显存需求显著增加(1342GB左右)。
-
量化版本(INT8甚至INT4精度):显存虽然变小(335G即可),但模型表现却大打折扣。
其中,量化版会有性能损失不必说,而转译版的转译过程可能出现多少损耗,如何损耗,这就是个玄学,要看具体选择的芯片型号,还有部署水平了。
但毫无疑问,让我们再次复习前文知识点,如果一个东西又好用又便宜,还能零门槛让普通人享受到,那大概率
是
杀
猪
盘
!
市场上不是没有能把转译版做好的团队,但能被我们遇到的概率,和我的网恋对象是吴彦祖一样低。(如果有,或者您有认识的团队,欢迎在我们的后台留言)
03
猫腻二:单设备的一体机搞MoE,算不过来的成本账
我们部署私有大模型,需求核心无非三点:
-
算力效率最大化
-
模型性能最优解
-
私有数据保护
而MoE架构的精髓在于“只激活少数(256个里激活8个)专家”节省成本。
看起来是不是一拍即合?
但是,划重点,没激活的专家本身还得装在机器(显存)里。这意味着:没激活的专家,不会浪费算力,但是会蹲在显存里闲的抠脚。就像买了辆F1赛车,结果只能在小区绕圈。
毕竟,拿A100来说,显卡的显存,还是挺贵的。
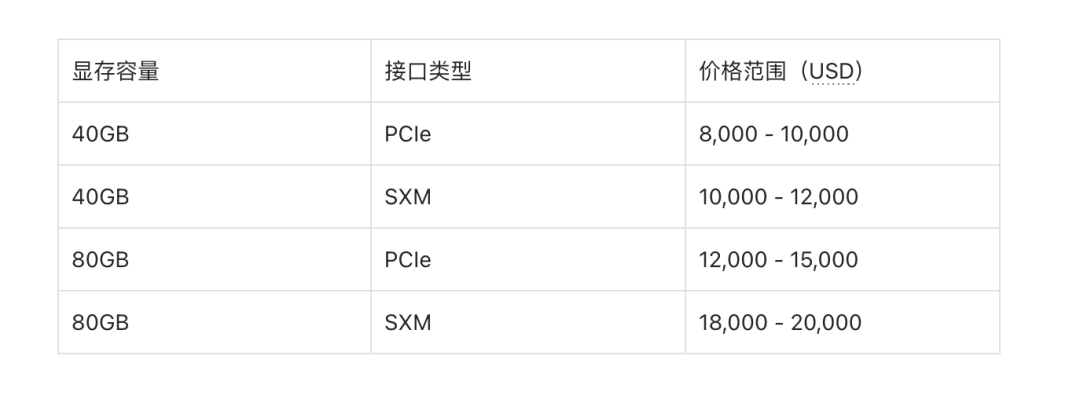
那既然一体机并不适合运行MoE模型,更适合全参数激活的稠密模型。那哪种硬件部署适合MoE模型呢?
DeepSeek官方其实已经说过很多次:要高吞吐、低延迟,就必须跨节点用专家并行(EP)思路,部署方案推荐22节点,176张H800显卡(不让任何一个专家闲着)。

你看,前文专家模块独立部署的知识点,这不就用上了。
顺便补充一句,单服务器的一体机和EP思路的差距有多大呢?我们测了一下,也就是节省20倍显存,输入输出吞吐量提升区区20倍。
当然有人说,我不在意性价比,不差钱。
那问题来了,以后否能够平滑扩容也不在意了吗?
单机部署和多机部署的难度,不是1+1=2,而是10000个单机接在一起,一通专业操作,结果发现结果等于5500。
这不是瞎编的,而是来自字节跳动与北大联合发表的论文《MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs》,论文里表示,在12288个GPU上训练大模型时,MegaScale实现了55.2%的模型FLOPs利用率(MFU)。
而字节对55.2%的数据评价是——远超传统方案。
所以,潜在含义就是,很多人的万卡集群,可能只有一半在干活,另一半在看热闹。
当然,从单机到集群扩展,通信延迟与带宽限制、分布式协调与一致性开销、数据复制与任务拆分成本都会带来性能损失。
但如果一开始就直接用单机架构部署,那后续水平扩容,带来的性能浪费,更是灾难级。
毕竟,单机架构和分布式架构往往天差地别。
比如Milvus的单机版和 k8s集群版,都做语义检索,但其实从索引算法到基础的架构,都会有区别,基于此实现的功能必然也大不相同。
04
猫腻三:落地不等于大模型+硬件
首先,别把所有一体机都想成一样的“铁盒子”,DeepSeek 一体机其实分为三种不同“段位”:
A类:纯硬件型
-
就是一堆 AI 卡 + 服务器,啥都不带,裸铁一台
-
适合有强大工程能力的技术团队做深度定制
B类:平台型
-
在 A 类基础上预装 DeepSeek 模型 + 基础开发平台
-
比如集成 dify、langchain、Milvus,适合企业快速部署、开发对话或者RAG产品
C类:应用型
-
进一步在 B 类上进一步包装变成企业知识库、智能办公SaaS、AI客服等
-
更偏产品化,买回去就能用,适合非技术型团队
整体来看,BC类型居多,而且这两种类型大部分是小白客户,小白客户有多好骗呢?
开源产品简单部署就交付已经是良心供应商;
更有甚者,套壳dify和Milvus,然后乱改UI假装自研,我们在最近两个月收到的反馈已经数不胜数。

最过分的,是给客户甲的产品,改个名字,换个logo(是的,毕竟是私有部署,所以连UI都不用换)就卖给客户乙,美其名曰定制化,然后额外收费几十万。
但乱收费,其实只是最温柔的杀猪盘,其高级精髓在于收费之前先让你觉得自己捡到了金猪,交付之后,发现这是个根本控制不住的野猪。
落地大模型应用的时候,选择一个专业的开发平台与向量数据库已经成为共识。但就拿Milvus 来说,我们目前有 3 种主流的部署形式:
-
基于 docker 的单机部署
-
基于 k8s 的集群部署
-
基于公有云的 SaaS (Zilliz Cloud)
一般做一体机的企业,刚开始都会使用 docker 部署 Milvus 单机版,对于数据规模在千万以内,且业务 QPS 在 100 以内的场景基本是够用的。单机版本的优势是简单上手快,短板也很明显,没有高可用能力,数据量增长到千万级,QPS 增长到几百以上,性能就会遇到瓶颈。
而高可用和可扩展性,是 Milvus 集群版的天然能力,但是集群版依赖的 K8s环境,一体机几乎很难提供,很多套壳公司也不具备这个能力,所以,现实是,大部分一体机厂商仅仅满足于Docker单机版,不做容灾,只能“祈祷”机房不出故障、数据不暴涨。
顺便,在这里打个小广告:如果一体机中允许联网,那么使用 Milvus 的 SaaS 服务 Zilliz Cloud 可以完美地解决前面的所有问题,数据库的稳定性,性能,扩展性都交给 Milvus 的原厂团队去保障。
05
一些小tips
当然,前面说了这么多,并不是要一杆子打死所有的一体机。毕竟在保证数据合规、以及企业资产核算方面,相比“看不见、摸不着”的软件,硬件有着无可比拟的优势。
问题的核心,不是一体机本身有没有价值,而是:
你选的那台,
值不值这个价!!!
最近 Zilliz 也接触了不少类似的一体机部署项目,甚至参与了一些从“看方案”到“实际上线”的全过程。在这个过程中,我们也总结出一些经验,供大家参考。
(1)首先是硬件选型。
别只看纸面参数,更要关注“实际调度能力”与“模型适配情况”。建议优先选择主流厂商在生态内有明确适配支持的硬件平台,比如支持 CUDA 的 NVIDIA GPU,或已经对特定大模型做过深度优化的一体化解决方案(对多数人来说,H20可能是当前的最优解之一)。
选择一些国产芯片的话,需要尤其关注对FP8格式的支持,目前国产AI芯片支持这一数据格式的,大约在三家。
长期来看,能否支持FP4数据格式,也需要纳入考量。微软已经跑通了FP4的完整模型训练,英伟达也将在Blackwell一代GPU中以硬件级别支持FP4,低精度训练会是大势所趋。
(2)其次是如何避免被各种量化、转译、阉割版模型忽悠?
很简单——选择一些比如逻辑推理、多轮问答或者行业知识的场景,和官网的回答做个对比,差距一眼可见,当然,这是一个后验视角,但在签合同之前,强烈建议你“先试后买”。
(3)关于如何识别被各种“套壳中间件”收智商税?
我们看到有些方案,看似提供了全链路的模型管理、数据处理、权限控制,结果实际就是套了几个开源组件、加了个前端壳,就敢开价几十万。这时候就得看:有没有核心调度能力?能不能灵活接入主流模型?有没有完善的权限体系和审计机制? 如果只是套了个 Chat UI,连模型都换不了,那就是在拿 PPT 收服务费了,毕竟DeepSeek不会是所有场景的最优解。
尾声
为什么我劝你不慎选DeepSeek一体机
前面说了那么多,总结起来就是三点:
第一,考虑性能和成本,单服务器版本的一体机其实并不划算。因此,如果数据不敏感,用公有云其实就够了。
第二,一体机部署意味着软硬件锁死,不方便扩容,也不方便换模型。DeepSeek不会是所有场景的最优解,而不同模型的最佳适配硬件是不一样的。
第三,草台班子太多,鱼龙混杂。既有量化版、阉割版让效果大打折扣,也有三流团队对dify、langchain、Milvus套壳失败,导致效果扑街。
总之,别迷信一体机,更别高估它的边界,集群版+Zilliz Cloud 部署性能更佳、扩展性更好!
当然,如果您面临的场景是,并发少、数据少、且只能本地部署,
或者上面大手一挥,单机部署、板上钉钉。那么,以上内容,全不作数。
作者介绍

推荐阅读




欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)