DeepSeek_R1技术报告 超细致中文详解
仅使用强化学习(RL)激励推理能力,而不使用有监督的人工微调(SFT)→ 推理强,但存在可读性差、语言混淆的问题。则在RL之前加入了**多阶段训练(RL + 拒绝采样 + SFT)**和少量的冷启动数据最终效果可以达到OpenAI-o1-1217的推理效果。、基于Qwen2.5和Llama3从DeepSeek_R1 蒸馏 distillation出来的六个密度的模型**(1.5B, 7B, 8B,
概述:
- DeepSeek_R1_Zero 仅使用强化学习(RL)激励推理能力,而不使用有监督的人工微调(SFT)
→ 推理强,但存在可读性差、语言混淆的问题。 - DeepSeek_R1 则在RL之前加入了**多阶段训练(RL + 拒绝采样 + SFT)**和少量的冷启动数据
最终效果可以达到OpenAI-o1-1217的推理效果。 - 开源模型:DeepSeek_R1_Zero、DeepSeek_R1(671B)、基于 Qwen2.5 和 Llama3 从DeepSeek_R1 蒸馏 distillation 出来的六个密度的模型 (1.5B, 7B, 8B, 14B, 32B, 70B) 。
最终基座模型DeepSeek-V3一共经历了两次微调和两次强化学习。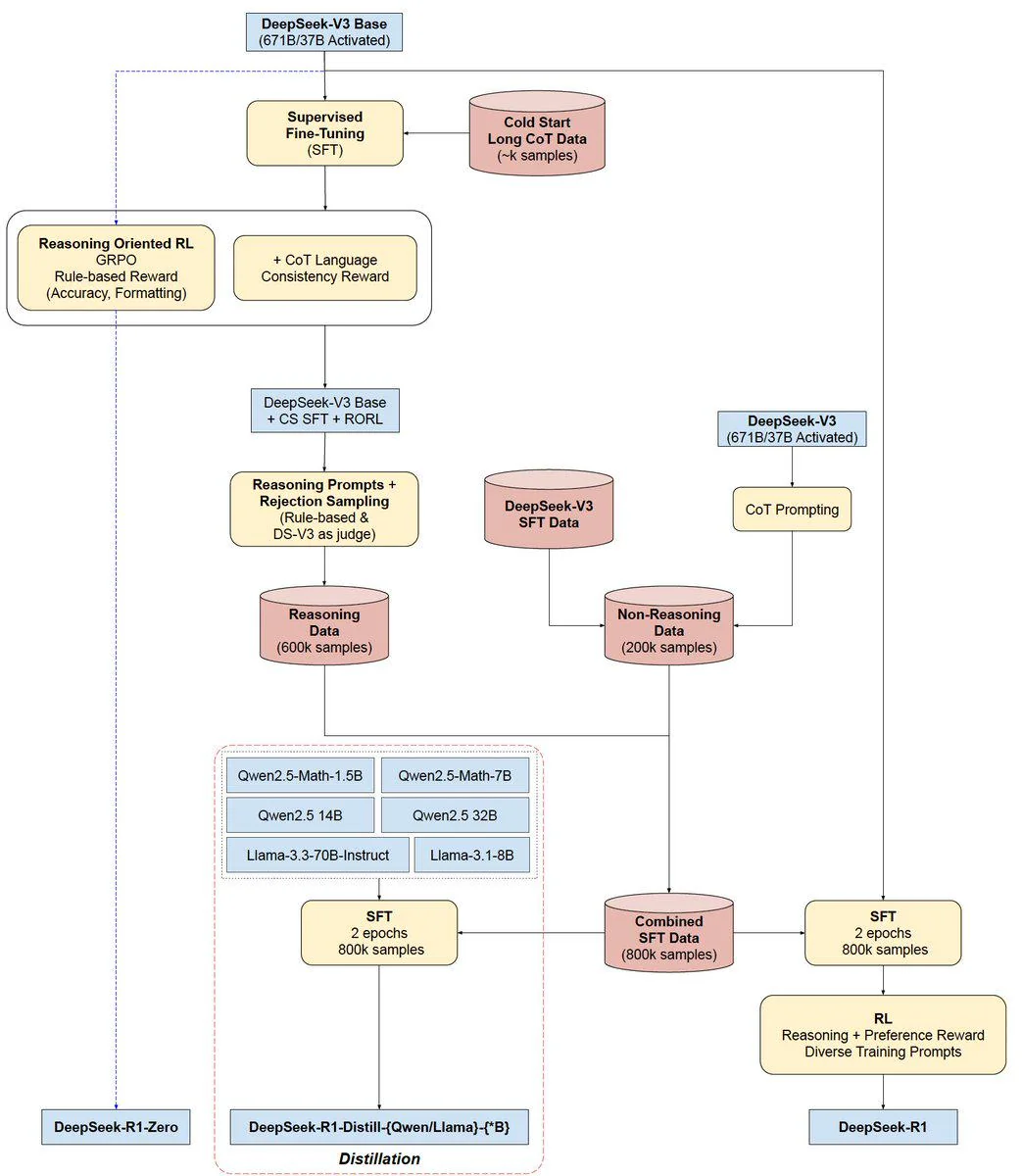
研究现状:
- LLMs快速发展: 大模型快速迭代,正在进一步接近通用人工智能。
- 后训练(Post-training)重要性: 对齐(与社会价值观对齐、无害性)、推理优化等后训练成为模型训练的关键环节,可以降低成本提升推理reasoning、对齐、适应用户偏好的效果
- 现有方法的局限性:
- OpenAI-o1系列首个提出通过增加思维链(Chain-of-Thought)推理过程的长度来缩放推理时间。但有效的测试阶段扩展 Test-Time-Scaling 仍是问题。
- 前期的研究通过过程奖励模型、强化学习 RL 和搜索算法 试图提升,但推理效果仍不能达到OpenAI-o1系列模型。
本文的应对策略:
- 纯强化学习 激励推理 (DeepSeek_R1_Zero):大规模推理导向强化学习。不使用SFT,以 DeepSeek-V3-Base 为基础模型,以 GRPO 为强化学习RL框架,经过数千个RL步骤。通过多数表决,性能进一步提升。
→RL过程中模型自发涌现了自我验证(Self-Verification)、反思(Reflection)、生成长CoT等复杂推理行为。 - 少量冷启动数据 + 多阶段训练:少量冷启动(Cold Start) → 推理导向强化学习(Reasoning-oriented RL) → 拒绝采样与监督微调(Rejection Sampling & SFT) → 全场景强化学习(RL for All Scenarios) → 蒸馏(Distillation)
- 蒸馏模型性能显著超越同类基于RL的小开源模型(如Qwen-32B-Preview),部分模型接近闭源商业模型(如o1-mini)。但超越智能的边界可能仍然需要更强大的基础模型和更大规模的强化学习。
具体方法:
一、DeepSeek-R1-Zero: Reinforcement Learning on the Base Model
-
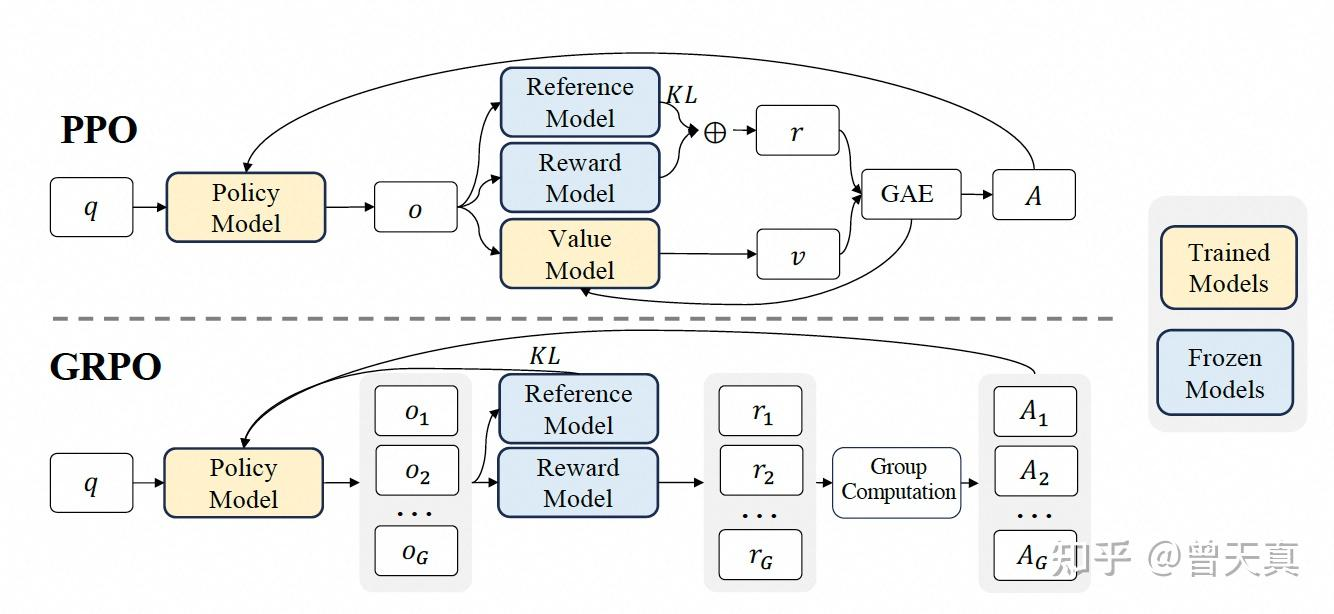
强化学习算法:Group Relative Policy Optimization(组相对策略优化)
放弃通常与 Policy模型 同等规模的 Critic模型,而是直接通过组内采样的平均奖励统计量计算个体优势函数(Advantage)作为Baseline。- 组采样(Group Sampling):对于某个问题p,从当前策略中采样提取出一组输出{o1,o2,…,oG}。通过组内多个输出的对比,动态计算出输出间的相对优势,避免依赖独立的基线baseline
→ 优势:省去训练额外Critic模型的成本,显著减少计算资源需求。 - 优势函数(Advantage)的组内计算:
Ai=ri−mean({r1,r2,…,rG})std({r1,r2,…,rG}) A_i=\frac{r_i-\mathrm{mean}(\{r_1,r_2,\ldots,r_G\})}{\mathrm{std}(\{r_1,r_2,\ldots,r_G\})} Ai=std({r1,r2,…,rG})ri−mean({r1,r2,…,rG})
优势值反映 oi 在组内的相对质量(优于组内平均水平的程度),而非绝对奖励值。-
策略优化目标函数:
IGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πθold(O∣q)]1G∑i=1G(min(πθ(oi∣q)πθold(oi∣q)Ai,iclip(πθ(oi∣q)πθold(oi∣q),1−ε,1+ε)Ai)−βDKL(πθ∣∣πref)),(1)DKL(πθ∣∣πref)=πref(oi∣q)πθ(oi∣q)−logπref(oi∣q)πθ(oi∣q)−1,(2) \begin{aligned}\mathcal{I}_{GRPO}(\theta) & =\operatorname{E}[q\sim P(Q),\{o_i\}_{i=1}^G\sim\pi_{\theta_{old}}(O|q)] \\ & \frac{1}{G}\sum_{i=1}^G\left(\min\left(\frac{\pi_\theta(o_i|q)}{\pi_{\theta_{old}}(o_i|q)}A_{i,i}\operatorname{clip}\left(\frac{\pi_\theta(o_i|q)}{\pi_{\theta_{old}}(o_i|q)},1-\varepsilon,1+\varepsilon\right)A_i\right)-\beta\operatorname{D}_{KL}\left(\pi_\theta||\pi_{ref}\right)\right), & (1) \\ & \mathrm{D}_{KL}\left(\pi_\theta||\pi_{ref}\right)=\frac{\pi_{ref}(o_i|q)}{\pi_\theta(o_i|q)}-\log\frac{\pi_{ref}(o_i|q)}{\pi_\theta(o_i|q)}-1, & (2)\end{aligned} IGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πθold(O∣q)]G1i=1∑G(min(πθold(oi∣q)πθ(oi∣q)Ai,iclip(πθold(oi∣q)πθ(oi∣q),1−ε,1+ε)Ai)−βDKL(πθ∣∣πref)),DKL(πθ∣∣πref)=πθ(oi∣q)πref(oi∣q)−logπθ(oi∣q)πref(oi∣q)−1,(1)(2)
展开的形式如下:
JGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πθold(O∣q)]1G∑i=1G1∣oi∣∑t=1∣oi∣{min[πθ(oi,t∣q,oi,<t)πθold(oi,t∣q,oi,<t)A^i,t,clip(πθ(oi,t∣q,oi,<t)πθold(oi,t∣q,oi,<t),1−ε,1+ε)A^i,t]−βlDKL[πθ∣∣πref]},(3)\begin{aligned} \mathcal{J}_{GRPO}(\theta) & =\mathbb{E}[q\sim P(Q),\{o_i\}_{i=1}^G\sim\pi_{\theta_{old}}(O|q)] \\ & \frac{1}{G}\sum_{i=1}^G\frac{1}{|o_i|}\sum_{t=1}^{|o_i|}\left\{\min\left[\frac{\pi_\theta(o_{i,t}|q,o_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q,o_{i,<t})}\hat{A}_{i,t},\operatorname{clip}\left(\frac{\pi_\theta(o_{i,t}|q,o_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q,o_{i,<t})},1-\varepsilon,1+\varepsilon\right)\hat{A}_{i,t}\right]-\beta l\mathbf{D}_{KL}\left[\pi_{\theta}||\pi_{ref}\right]\right\},\quad(3) \end{aligned}JGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πθold(O∣q)]G1i=1∑G∣oi∣1t=1∑∣oi∣{min[πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)A^i,t,clip(πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t),1−ε,1+ε)A^i,t]−βlDKL[πθ∣∣πref]},(3)- 重要性采样比 πθ /πθold:衡量新旧策略π 生成 oi 的概率差异。
- 优势裁剪(Clip):限制策略更新的幅度,防止剧烈波动(类似PPO)。
- KL散度惩罚项 DKL:使用上面的无偏估计来估计 KL 散度,约束新策略与参考策略 πref(如预训练模型)的偏离,避免灾难性遗忘。
-
GRPO 通过直接在损失函数中加入策略模型和参考模型之间的 KL 散度来正则化,而不是在奖励中加入 KL 惩罚项,从而简化了训练过程。
-
如果用的是过程监督(process supervision),即在推理过程中的每个关键步骤都打分,每个步骤都有一个局部奖励,就可以把它依时间序列累加或折算成与 token 对应的优势。
优势:
-
无需Critic模型,节省50%计算资源。
-
直接基于组内样本的统计特性,避免Critic模型的估计误差,提高训练效率和效果。
-
适合奖励密集且动态范围大的任务(如语言模型推理,单步奖励明确)。
-
组内对比天然稳定,适合大规模并行训练。
动机:
-
PPO 中的值函数Critic模型通常是一个与策略模型大小相当的模型**,这带来了显著的内存和计算负担。此外,在 LLMs 的上下文中,值函数在训练过程中被用作优势计算中的Baseline,但通常只有最后一个 token 会被奖励模型赋予奖励分数,这可能使得值函数的训练变得复杂。
在许多实际应用中,奖励只有在序列末端才给一个分数(称之为 Result/Oucome Supervision),或在每一步给一些局部分数(Process Supervision)。不管怎么样,这个奖励本身往往是离散且比较稀疏的,要让价值网络去学习每个token的价值,可能并不划算。
在这里插入图片描述 - 组采样(Group Sampling):对于某个问题p,从当前策略中采样提取出一组输出{o1,o2,…,oG}。通过组内多个输出的对比,动态计算出输出间的相对优势,避免依赖独立的基线baseline
-
奖励模型 Reward Modeling:基于规则的奖励系统(rule-based reward system)
- 准确度奖励 Accuracy Rewards:检查回答是否正确
- 有确定回答的数学问题:需要以特定格式输出,以验证正确性
- 编程类问题:自动化评估。系统自动调用编译器,运行题目提供的预定义的测试用例,根据测试用例的通过率(Pass@k)计算奖励值。
- 格式奖励 Format Rewards:强制模型将思考过程放在‘’ 和 ‘’之间。
- 在DeepSeek-R1-Zero中没有使用结果或过程神经奖励模型(Neural Reward Model)
原因:- 奖励攻击(Reward Hacking)风险:模型通过利用奖励规则的漏洞而非真正提升能力来最大化奖励,导致行为偏离预期目标。e.g. 表面合规性欺骗、语义规避、过度优化。
- **训练资源与流程复杂度:**神经奖励模型需要独立训练(通常需千亿级参数);若发现奖励模型存在缺陷(如偏好偏差),需重新收集数据并训练。
- 准确度奖励 Accuracy Rewards:检查回答是否正确
-
训练模板 Training Template:
- 结构化输出约束:强制分步推理与格式规范
reasoning process here
answer here . - 作用:
- 确保模型生成完整的推理链,而非直接输出答案,从而提升可解释性;
- 便于后续基于规则的奖励计算。
- 结构化输出约束:强制分步推理与格式规范
-
性能 Performance:
average pass@1 score on AIME 2024:15.6% → 71.0%,与 OpenAI-o1-0912 效果相当
多数表决(Majority Voting):cons@64 score on AIME 2024 71.0% → 86.7%,超过了 OpenAI-o1-0912基准benchmark 任务类型 评估重点 DeepSeek-R1表现 对比模型(OpenAI-O1-1217) AIME 2024 数学竞赛 多步证明与精确计算 79.8% (pass@1) 79.2% MATH-500 高中数学题 结构化推理稳定性 97.3% 96.4% GPQA Diamond 跨学科科学问题 专业知识与逻辑整合 71.5% 75.7% LiveCode Bench 代码生成 功能正确性与算法效率 65.9% 63.4% (O1-0912) CodeForces 算法竞赛 时间复杂度与内存优化 2029 Elo评分 2061 Elo评分 -
自我进化 Self-evolution Process :DeepSeek-R1-Zero通过增加 **测试时间计算(Test-Time Computation, TTC)**自然获得解决日益复杂的推理任务的能力。自发产生反思、探索问题的替代方法。
"Aha moment”:模型通过强化学习自主发展出复杂推理能力的突破性瞬间
在模型的中间版本中,DeepSeek-R1-Zero通过重新评估自己初始的回答,自主学习分配更多的思考时间。 -
DeepSeek-R1-Zero 的缺点:
- Poor Readability(可读性差): 指生成的推理过程结构混乱、缺乏格式规范,导致用户难以快速理解逻辑。
- Language Mixing(语言混合): 指在生成内容中混杂使用多种语言(如中英文交替),破坏内容一致性。
二、DeepSeek-R1: Reinforcement Learning with Cold Start
- 冷启动 Cold Start:收集数千条少量长 CoT 数据,自动化生成与人工修正的协同。注重推理
-
少样本提示引导长思维链生成(Few-Shot Prompting with Long CoT): 提供少量包含详细推理步骤的示例,作为模板引导模型生成结构化输出。
-
直接提示生成带反思与验证的答案(Direct Prompting with Reflection):要求模型在生成答案时主动反思中间步骤的正确性。
-
收集并格式化R1-Zero的输出(Gathering R1-Zero Outputs):从纯强化学习模型DeepSeek-R1-Zero的生成结果中提取有效推理片段,并强制转换为可读结构。
-
人工后处理优化(Human Post-Processing): 由标注员对自动生成的内容进行修正。
优势:
-
可读性:设计在每个响应的末尾包含一个总结,定义输出格式为
|special_token|<reasoning_process>|special_token|;过滤掉用户不友好的回答。
-
- 面向推理的强化学习 Reasoning-oriented Reinforcement Learning:
- 在RL训练期间引入语言一致性奖励,计算目标语言单词在CoT中的比例。
- 将推理任务的准确性和语言一致性的奖励直接相加形成最终的奖励。
- 拒绝采样与监督性微调 Rejection Sampling and Supervised Fine-Tuning:800k
当强化学习接近收敛时,在RL结果检查点 resulting checkpoint 上进行拒绝采样,结合DeepSeek-V3的通用监督数据,生成下一轮SFT数据,将推理数据和非推理数据合并。生成-筛选闭环替代人工标注。- 推理数据:使用拒绝采样 **Rejection Sampling(代替人工标注)**管理推理提示并生成推理轨迹。600k
- 利用强化学习模型 DeepSeek-R1-Zero 批量生成候选响应。使用基于规则的奖励进行评估。
- 引入生成式奖励模型(Generative Reward Model):将事实真相和模型预测输入DeepSeek-V3进行判断。
- **可读性过滤:**将混合语言、长段和代码块过滤掉。
- 非推理数据:采用DeepSeek-V3流程并重新使用DeepSeek-V3的部分SFT数据集。200k
对于一些复杂的非推理问题,调用DeepSeek-V3在回答之前生成潜在的思维链;对于简单的问题则不生成思维链。
- 推理数据:使用拒绝采样 **Rejection Sampling(代替人工标注)**管理推理提示并生成推理轨迹。600k
- 全场景的强化学习 Reinforcement Learning for all Scenarios:二级强化学习,为了与人类偏好通用对齐(RLHF)
- 奖励信号设计:
- 推理数据:沿用 DeepSeek-R1-Zero 的规则化奖励 rule-based rewards。
- 通用数据:采用奖励模型 reward model 评估,在复杂场景中捕捉人类偏好。
- 实用性:只评估summary,确保优化不损害推理逻辑。
- 有害性:评估summary和推理过程,提升整体安全性。
- 多样化提示分布 diverse prompt distributions:
收集涵盖推理任务(数学、代码、逻辑)和通用任务(开放问答、写作、角色扮演)的提示数据,构建综合训练集。
- 奖励信号设计:
三、蒸馏 Distillation: Empower Small Models with Reasoning Capability
使用DeepSeek-R1生成的800k样本直接微调了 Qwen(Qwen,2024b) 和 Llama(AI@Meta,2024) 等开源模型。
仅使用SFT数据微调,而不使用强化学习。
实验
- 温度采样(Temperature Sampling):通过温度采样生成多组候选答案
通过调节温度参数(Temperature=0.6,top-p=0.95)控制生成多样性,避免**贪婪解码(Greedy Decoding)**导致的答案重复率高、不同模型检查点性能波动大的问题。- 温度与top-p的作用:
- 温度=0.6:平衡生成多样性与确定性(>1更随机,<1更保守)。
- top-p=0.95:从累计概率前95%的候选词中采样,避免低概率词干扰。
- 为何选择非零温度:完全贪婪(温度=0)会导致模型路径依赖,而适度随机性可探索更多潜在正确解法。
- 温度与top-p的作用:
- 基于统计方法(Pass@k、Consensus)评估模型性能:
- Pass@k 评估方法
- 定义:实际有两个参数:n,k。让模型为每个问题生成 n(n>k)份代码,再从中随机选择 k 份代码,k 份代码中至少有一份代码通过单元测试即通过测试,c 代表能通过单元测试的总数。则Pass@1意味着让模型为每个问题生成 n(n>k)份代码,再从中随机选择 1 份代码,计算正确率。
pass@k:=EProblems[1−(n−ck)(nk)]pass@k:=E_{Problems}\left[1-\frac{\binom{n-c}{k}}{\binom{n}{k}}\right]pass@k:=EProblems[1−(kn)(kn−c)] - 实现步骤:
- 采样参数:温度(Temperature)=0.6,top-p=0.95(控制生成多样性,避免过于随机或保守)。
- 生成n个响应:n值根据测试集规模调整(通常4~64次)。
- 计算Pass@1:对每个问题的n个答案统计正确率,再求平均(公式中的
pass@1 = (Σp_i)/n,其中p_i表示第i个答案是否正确)。
- 优势:通过多次采样降低随机性影响,更真实反映模型能力。
- 定义:实际有两个参数:n,k。让模型为每个问题生成 n(n>k)份代码,再从中随机选择 k 份代码,k 份代码中至少有一份代码通过单元测试即通过测试,c 代表能通过单元测试的总数。则Pass@1意味着让模型为每个问题生成 n(n>k)份代码,再从中随机选择 1 份代码,计算正确率。
- Cons@64(共识评估)
- 定义:对同一问题生成64个答案,通过**多数投票(Majority Vote)**选择高频正确答案作为最终结果。
- 例:若64个答案中正确答案出现40次,则采纳该答案,正确率计为1(否则为0)。
- Pass@k 评估方法
失败的尝试方法
-
Process Reward Model(过程奖励模型) :
是一种用于提升大语言模型在复杂推理任务(如数学解题、代码生成)中性能的技术。其核心思想是对推理过程中的每个步骤进行细粒度奖励反馈,引导模型逐步生成更合理的解决方案。- 优势:
- 提升生成结果的逻辑严谨性(如避免数学推导中的跳步错误);
- 减少无效尝试,加速收敛到正确解(如代码生成中快速定位错误)。
- 局限性:
- 步骤定义困难:开放式推理任务难以明确定义“正确步骤”(如哲学问题可能有多种合理路径);
- 验证成本高:确定当前步骤是否正确很困难。自动验证依赖模型自身判断(可能引入误差),人工标注则难以扩展;
- 奖励黑客风险:模型可能通过“刷分”提高步骤得分(如冗余步骤),而非真正优化答案质量。
- 优势:
-
蒙特卡罗树搜索(MCTS):
- 选择
基于2.2中的选择算法,从根节点开始,我们选择采用UCB计算得到的最大的值的孩子节点,如此向下搜索,直到我们来到树的底部的叶子节点(没有孩子节点的节点),等待下一步操作。 - 扩展
到达叶子节点后,如果还没有到达终止状态(比如五子棋的五子连星),那么我们就要对这个节点进行扩展,扩展出一个或多个节点(也就是进行一个可能的action然后进入下一个状态)。 - 模拟
之后,我们基于目前的这个状态,根据某一种策略(例如random policy)进行模拟,直到游戏结束为止,产生结果,比如胜利或者失败。 - 反向传播
根据模拟的结果,我们要自底向上,反向更新所有节点的信息。
未来的工作
-
通用能力不足:
- 在多轮对话、复杂角色扮演、JSON格式输出等场景中,性能仍落后于DeepSeek-V3。
- 改进计划:通过扩展训练数据与优化对齐目标提升通用性。
-
语言混合问题:
- 当前模型对中英文混合输入敏感,非中/英文查询时可能错误切换语言(如用英文推理中文问题)。
- 改进计划:优化多语言支持,减少语言切换干扰。
-
提示工程敏感:
- 模型对提示词(prompt)设计敏感,少样本示例(few-shot)会降低性能。
- 建议:直接使用零样本(zero-shot)描述问题并明确输出格式。
例子:请解方程 x2−5x+6=0x^2 - 5x + 6 = 0x2−5x+6=0,并按照以下要求输出:
(1)分步解释推导过程;
(2)最终答案用 “\boxed{}” 包裹。 -
软件工程任务优化:
- 在代码生成等软件工程任务中,性能未显著超越DeepSeek-V3。
- 改进计划:
- 引入软件工程数据拒绝采样(rejection sampling)。
- 在强化学习过程中加入异步评估,提升效率与代码质量。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 44
44 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)