DeepSeek核心论文全译本:DeepSeek-R1:通过强化学习提升大语言模型 (LLM) 的推理能力...
来源:硬科普引言1.1 贡献1.2 评估结果摘要方法2.1 概述2.2 DeepSeek-R1-Zero:基于基础模型的强化学习2.2.1 强化学习算法2.2.2 奖励建模2.2.3 训练模板2.2.4 DeepSeek-R1-Zero的性能、自进化过程与顿悟时刻2.3 DeepSeek-R1:基于冷启动的强化学习2.3.1 冷启动2.3.2 面向推理的强化学习2.3.3 拒绝采样与监督微调2.3

来源:硬科普
-
引言
1.1 贡献
1.2 评估结果摘要 -
方法
2.1 概述
2.2 DeepSeek-R1-Zero:基于基础模型的强化学习
2.2.1 强化学习算法
2.2.2 奖励建模
2.2.3 训练模板
2.2.4 DeepSeek-R1-Zero的性能、自进化过程与顿悟时刻
2.3 DeepSeek-R1:基于冷启动的强化学习
2.3.1 冷启动
2.3.2 面向推理的强化学习
2.3.3 拒绝采样与监督微调
2.3.4 全场景强化学习
2.4 蒸馏:为小模型赋能推理能力 -
实验
3.1 DeepSeek-R1评估
3.2 蒸馏模型评估 -
讨论
4.1 蒸馏 vs. 强化学习
4.2 失败的尝试 -
结论、局限性与未来工作
附录A 贡献与致谢
1. 引言 (Introduction)
近年来,大型语言模型 (Large Language Models, LLMs) 正经历着快速的迭代与演进 (Anthropic, 2024; Google, 2024; OpenAI, 2024a),逐步缩小与通用人工智能 (Artificial General Intelligence, AGI) 之间的差距。
最近,后训练 (post-training) 已成为完整训练流程中的重要组成部分。研究表明,这一阶段能够在推理任务上提升模型准确性,使其符合社会价值观并适应用户偏好,同时所需的计算资源相较于预训练 (pre-training) 较少。在推理能力的研究背景下,OpenAI 的 o1 系列 (OpenAI, 2024b) 模型率先通过扩展推理链 (Chain of Thought, CoT) 的长度引入了推断时 (inference-time) 扩展技术。这一方法在诸如数学、编程、科学推理等任务上取得了显著进展。然而,有效的测试时扩展 (test-time scaling) 依然是研究界尚未解决的开放性问题。
一些先前的研究探索了不同的解决方案,包括基于过程的奖励模型 (process-based reward models) (Lightman et al., 2023; Uesato et al., 2022; Wang et al., 2023)、强化学习 (Kumar et al., 2024) 以及搜索算法,如蒙特卡罗树搜索 (Monte Carlo Tree Search) 和束搜索 (Beam Search) (Feng et al., 2024; Trinh et al., 2024; Xin et al., 2024)。然而,这些方法都未能达到与 OpenAI 的 o1 系列模型在通用推理能力上的同等水平。
在本研究中,我们首次尝试使用纯强化学习 (Reinforcement Learning, RL) 来提升语言模型的推理能力。我们的目标是探索 LLM 在没有任何监督数据的情况下开发推理能力的潜力,重点关注其通过纯 RL 流程实现的自我演化 (self-evolution)。具体来说,我们使用 DeepSeek-V3-Base 作为基础模型,并采用 GRPO (Shao et al., 2024) 强化学习框架来提升模型在推理任务中的性能。
在训练过程中,DeepSeek-R1-Zero 自然地展现出许多强大而有趣的推理行为。经过数千步强化学习后,DeepSeek-R1-Zero 在推理基准测试中的表现大幅提升。例如,在 AIME 2024 基准测试中,其 pass@1 得分从 15.6% 提升至 71.0%,并在使用多数投票法后进一步提升至 86.7%,达到 OpenAI-o1-0912 的性能水平。
然而,DeepSeek-R1-Zero 也面临着可读性差和语言混杂等问题。为了解决这些问题并进一步提升推理性能,我们引入了 DeepSeek-R1。该模型在强化学习之前加入了少量冷启动数据 (cold-start data) 和多阶段训练管道。具体而言,我们首先收集了数千条冷启动数据对 DeepSeek-V3-Base 模型进行微调,随后与 DeepSeek-R1-Zero 类似,执行以推理为导向的强化学习。在强化学习过程接近收敛时,我们通过在 RL 检查点 (checkpoint) 上进行拒绝采样 (rejection sampling),结合 DeepSeek-V3 的监督数据(包括写作、事实问答、以及自我认知等领域),生成新的监督微调 (SFT) 数据并重新训练模型。在微调完成后,该检查点继续进行强化学习,以涵盖所有场景的提示 (prompt)。经过这些步骤后,我们得到了名为 DeepSeek-R1 的检查点,其在推理任务上的表现与 OpenAI-o1-1217 相当。
我们进一步探索了将 DeepSeek-R1 的能力蒸馏 (distillation) 到小型密集模型 (dense models) 的可能性。以 Qwen2.5-32B (Qwen, 2024b) 作为基础模型,直接从 DeepSeek-R1 进行蒸馏的效果优于在该模型上应用强化学习的结果。这表明,大型基础模型中发现的推理模式对于提升推理能力至关重要。我们开源了蒸馏后的 Qwen 和 Llama (Dubey et al., 2024) 系列模型。值得注意的是,我们蒸馏的 14B 模型在推理基准测试中远超现有的开源模型 QwQ-32B-Preview (Qwen, 2024a),而蒸馏的 32B 和 70B 模型在密集模型的推理基准测试中创下了新的纪录。
1.1 贡献 (Contributions)
后训练:在基础模型上进行大规模强化学习 (Post-Training: Large-Scale Reinforcement Learning on the Base Model)
-
我们直接在基础模型上应用强化学习 (RL),不依赖于监督微调 (Supervised Fine-Tuning, SFT) 作为初始步骤。这一方法使模型能够通过链式推理 (Chain-of-Thought, CoT) 探索复杂问题的解决方案,从而开发出 DeepSeek-R1-Zero。
DeepSeek-R1-Zero 展示了诸如自我验证 (self-verification)、反思 (reflection) 以及生成长推理链等能力,标志着推理模型研究领域的重要里程碑。值得注意的是,这是首次公开研究验证了通过纯强化学习即可激励大型语言模型 (LLM) 的推理能力,而无需依赖 SFT。这一突破为未来的发展铺平了道路。 -
我们引入了开发 DeepSeek-R1 的训练管道,该管道包括两个强化学习阶段,旨在发现改进的推理模式并与人类偏好对齐。此外,该管道还包含两个监督微调阶段,为模型的推理和非推理能力提供基础种子。我们相信,这一管道将有助于行业开发更优质的模型。
蒸馏:小型模型也能具备强大能力 (Distillation: Smaller Models Can Be Powerful Too)
-
我们证明了可以将大型模型的推理模式蒸馏到小型模型中,从而使小型模型的性能优于直接在小模型上通过强化学习获得的推理模式。开源的 DeepSeek-R1 及其 API 将为研究社区提供支持,帮助开发出性能更佳的小型模型。
-
基于 DeepSeek-R1 生成的推理数据,我们对多个在研究界广泛使用的密集模型进行了微调。评估结果表明,蒸馏后的小型密集模型在基准测试中表现出色。例如,DeepSeek-R1-Distill-Qwen-7B 在 AIME 2024 上取得了 55.5% 的成绩,超越了 QwQ-32B-Preview。此外,DeepSeek-R1-Distill-Qwen-32B 在 AIME 2024 上得分为 72.6%,在 MATH-500 上为 94.3%,在 LiveCodeBench 上为 57.2%。这些结果显著优于之前的开源模型,并且与 o1-mini 性能相当。
我们向社区开源了基于 Qwen2.5 和 Llama3 系列的 1.5B、7B、8B、14B、32B 和 70B 蒸馏模型检查点 (checkpoints)。
1.2 评估结果概述 (Summary of Evaluation Results)
-
推理任务 (Reasoning tasks)
-
DeepSeek-R1 在 AIME 2024 基准测试中取得了 79.8% 的 pass@1 得分,略微超过了 OpenAI-o1-1217。在 MATH-500 测试中,该模型取得了 97.3% 的出色成绩,与 OpenAI-o1-1217 的表现相当,且远超其他模型。
-
在编程相关任务中,DeepSeek-R1 在代码竞赛任务中展现了专家级水平,Elo 评分在 Codeforces 平台上达到了 2029,超越了 96.3% 的人类参赛者。对于工程相关任务,DeepSeek-R1 的表现略优于 DeepSeek-V3,这对开发人员在实际任务中有潜在帮助。
知识类任务 (Knowledge)
在 MMLU、MMLU-Pro 和 GPQA Diamond 等基准测试中,DeepSeek-R1 表现出色,其成绩显著优于 DeepSeek-V3:
虽然在这些基准测试中其成绩略低于 OpenAI-o1-1217,但 DeepSeek-R1 超越了其他闭源模型,展示出在教育类任务中的竞争优势。在事实问答基准测试 SimpleQA 上,DeepSeek-R1 的表现优于 DeepSeek-V3,显示出其在处理基于事实的查询方面的能力。类似趋势也在 OpenAI-o1 超越 GPT-4o 的测试中有所体现。
-
MMLU:90.8%
-
MMLU-Pro:84.0%
-
GPQA Diamond:71.5%
其他任务表现 (Others)
DeepSeek-R1 在广泛的任务中也表现优异,包括创意写作、通用问答、编辑、摘要等。在 AlpacaEval 2.0 上,其长度控制 (length-controlled) 胜率达到了 87.6%,在 ArenaHard 上的胜率达到了 92.3%,展示出其在非考试类查询中智能处理的强大能力。此外,DeepSeek-R1 在需要长上下文理解的任务中表现突出,远超 DeepSeek-V3 在长上下文基准测试中的表现。
2. 方法 (Approach)
2.1 概述 (Overview)
以往的研究通常依赖大量监督数据来提升模型性能。在本研究中,我们证明了即使不使用监督微调 (Supervised Fine-Tuning, SFT) 作为冷启动,通过大规模强化学习 (Reinforcement Learning, RL) 依然可以显著提升模型的推理能力。此外,适量冷启动数据的引入可以进一步提高性能。在接下来的章节中,我们将介绍:
-
DeepSeek-R1-Zero:直接在基础模型上应用 RL,而无需任何 SFT 数据。
-
DeepSeek-R1:从经过数千条长推理链 (Chain-of-Thought, CoT) 样本微调的检查点开始进行 RL。
-
推理能力蒸馏 (Distillation):将 DeepSeek-R1 的推理能力转移到小型密集模型中。
2.2 DeepSeek-R1-Zero:在基础模型上的强化学习
强化学习在推理任务中表现出了显著的效果,这在我们之前的研究 (Shao et al., 2024;Wang et al., 2023) 中得到了验证。然而,这些研究依赖于监督数据,而这些数据的收集通常耗时费力。在本节中,我们探索大型语言模型 (LLM) 在没有任何监督数据的情况下发展推理能力的潜力,重点关注其通过纯强化学习过程实现的自我演化 (self-evolution)。我们首先简要概述了我们的 RL 算法,然后展示了一些令人兴奋的结果,希望这些内容能为研究社区提供有价值的见解。
2.2.1 强化学习算法 (Reinforcement Learning Algorithm)
群相对策略优化 (Group Relative Policy Optimization, GRPO)
为了降低强化学习的训练成本,我们采用了群相对策略优化 (GRPO) (Shao et al., 2024)。这种方法放弃了通常与策略模型 (policy model) 大小相同的评价模型 (critic model),而是通过群体得分来估计基线。具体而言,对于每个问题 ,GRPO 从旧策略 中采样一组输出 ,然后通过最大化以下目标来优化策略模型 :
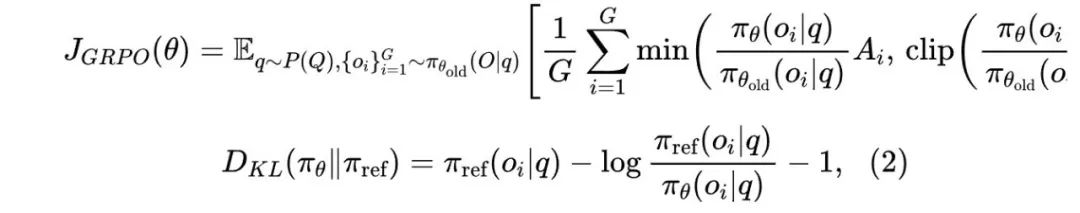
其中, 和 是超参数, 为优势值 (advantage),通过每组输出对应的奖励 计算得出:
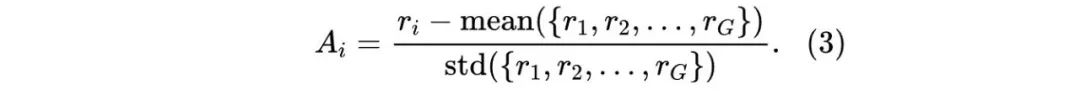
用户与助手之间的对话描述 (A conversation between User and Assistant)。用户提出问题,助手解决问题。助手首先在“思考”阶段进行推理,然后向用户提供答案。推理过程和答案分别使用和标签进行标注,例如:用户输入:prompt。助手响应:
表 1 | DeepSeek-R1-Zero 模板 在训练过程中,prompt 将替换为具体的推理问题。
2.2.2 奖励建模 (Reward Modeling)
奖励是训练信号的来源,决定了强化学习 (RL) 的优化方向。为了训练 DeepSeek-R1-Zero,我们采用了基于规则的奖励系统,该系统主要包括两种类型的奖励:
-
准确性奖励 (Accuracy rewards):准确性奖励模型用于评估模型响应是否正确。例如,对于具有确定性结果的数学问题,模型需要在指定格式(例如,在一个框内)中提供最终答案,从而实现基于规则的正确性验证。同样地,对于 LeetCode 编程问题,可以使用编译器基于预定义的测试用例生成反馈。
-
格式奖励 (Format rewards):除了准确性奖励模型之外,我们还使用了格式奖励模型,要求模型将推理过程包含在
<think>和</think>标签之间。
在开发 DeepSeek-R1-Zero 时,我们没有应用基于结果或过程的神经奖励模型,因为我们发现神经奖励模型在大规模强化学习过程中可能会出现奖励黑客 (reward hacking) 的问题。此外,重新训练奖励模型需要额外的训练资源,增加了训练管道的复杂性。
2.2.3 训练模板 (Training Template)
为了训练 DeepSeek-R1-Zero,我们首先设计了一个简单的模板,引导基础模型遵循指定的指令。如表 1 所示,该模板要求 DeepSeek-R1-Zero 先生成推理过程,然后给出最终答案。我们有意将约束限制在这一结构化格式内,避免内容上的特定偏向(例如,要求反思性推理或推广特定问题解决策略),以便准确观察模型在强化学习过程中的自然发展。
2.2.4 DeepSeek-R1-Zero 的性能、自我演化过程与“顿悟时刻” (Performance, Self-evolution Process, and Aha Moment of DeepSeek-R1-Zero)
DeepSeek-R1-Zero的性能表现 (Performance of DeepSeek-R1-Zero)
图 2 展示了 DeepSeek-R1-Zero 在 AIME 2024 基准测试中的性能轨迹。在强化学习训练过程中,DeepSeek-R1-Zero 的性能表现出稳定而持续的提升。
特别值得注意的是,AIME 2024 的平均 pass@1 得分显著提高,从最初的 15.6% 上升至 71.0%,达到了与 OpenAI-o1-0912 相当的水平。这一显著进步突显了我们强化学习算法在优化模型性能方面的有效性。
表 2 对 DeepSeek-R1-Zero 与 OpenAI 的 o1-0912 模型在多种推理相关基准测试中的表现进行了比较分析。结果显示,强化学习 (RL) 使 DeepSeek-R1-Zero 在没有任何监督微调 (SFT) 数据的情况下,依然具备了强大的推理能力。这一成果值得关注,因为它突显了模型仅通过强化学习即可有效学习和泛化的能力。
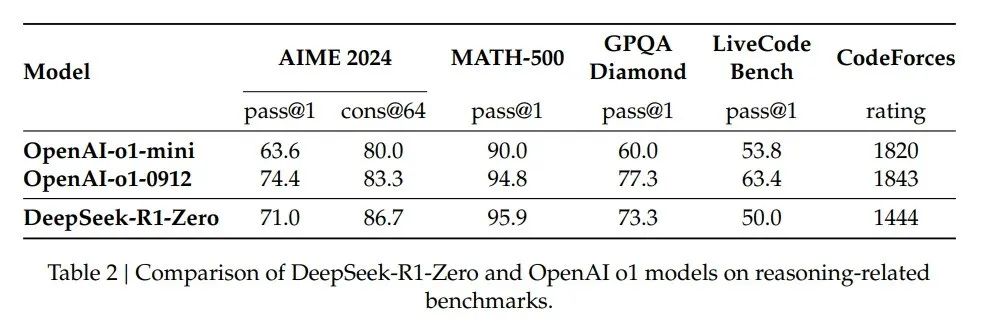
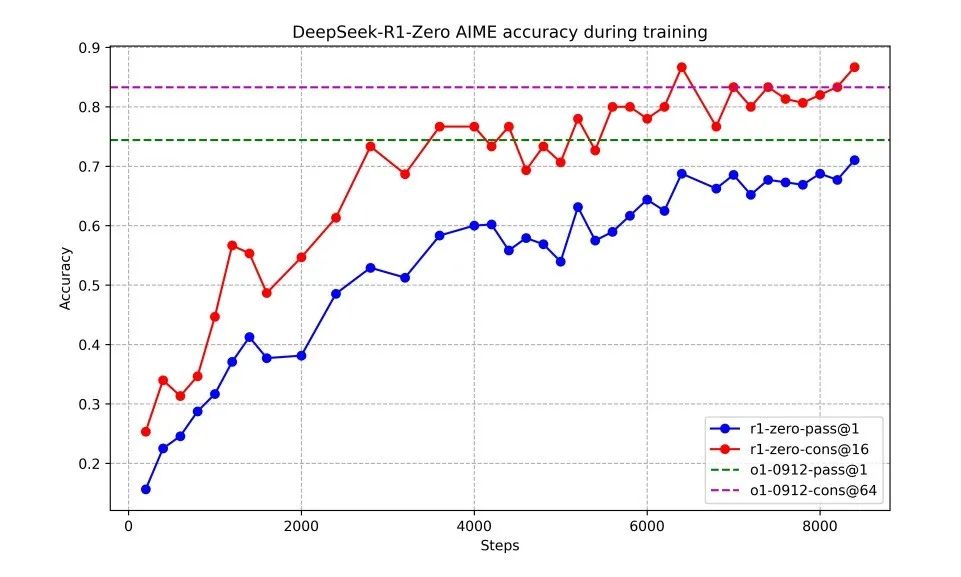
图 2 | DeepSeek-R1-Zero 在训练过程中 AIME 准确率的变化。对于每个问题,我们采样 16 个响应并计算整体平均准确率,以确保评估的稳定性。
此外,通过多数投票法 (majority voting),DeepSeek-R1-Zero 的性能可以进一步提升。例如,在 AIME 基准测试中,应用多数投票后,DeepSeek-R1-Zero 的性能从 71.0% 提升至 86.7%,超越了 OpenAI-o1-0912 的表现。DeepSeek-R1-Zero 在有无多数投票的情况下都能取得竞争性表现,这一能力彰显了其强大的基础能力以及在推理任务中进一步发展的潜力。
DeepSeek-R1-Zero 的自我演化过程 (Self-evolution Process of DeepSeek-R1-Zero)
DeepSeek-R1-Zero 的自我演化过程展示了强化学习如何推动模型自主提升推理能力的过程。这一过程十分引人注目。
通过直接从基础模型开始进行强化学习训练,我们能够在没有监督微调阶段影响的情况下,密切观察模型的进展。此方法为我们提供了模型随时间演化的清晰视图,特别是在其处理复杂推理任务能力方面的提升。这种观察方式让我们更全面地理解模型在强化学习过程中的自然发展轨迹和性能改进机制。
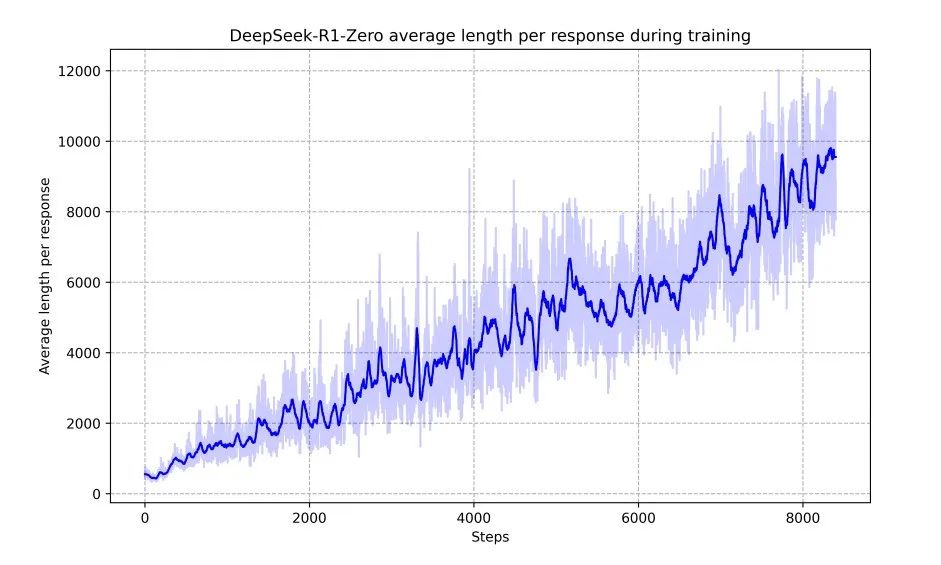
图 3 | DeepSeek-R1-Zero 在强化学习 (RL) 过程中训练集上的平均响应长度。DeepSeek-R1-Zero 自主学习通过增加思考时间来解决推理任务。
如图 3 所示,DeepSeek-R1-Zero 的“思考时间”在整个训练过程中持续改善。这种改善并非外部调整的结果,而是模型内部能力的自然发展。通过延长测试时的计算时间,DeepSeek-R1-Zero 自主获得了处理越来越复杂推理任务的能力。这些计算过程涵盖了从生成数百到数千个推理标记的范围,使模型能够更深入地探索和完善其思考过程。
在自我演化过程中,最引人注目的一点是随着测试时计算量的增加,模型逐渐表现出复杂的行为。例如,模型会进行**反思 (reflection)**——重新审视并评估之前的步骤;此外,模型还会自发地探索不同的解决方案。这些行为并非通过显式编程实现,而是在模型与强化学习环境交互中自然产生的。这种自发性发展大大增强了 DeepSeek-R1-Zero 的推理能力,使其能够更高效、更准确地处理更具挑战性的任务。
DeepSeek-R1-Zero 的“顿悟时刻” (Aha Moment of DeepSeek-R1-Zero)
在训练 DeepSeek-R1-Zero 的过程中,研究人员观察到了一种特别有趣的现象——“顿悟时刻 (aha moment)”。如表 3 所示,这一时刻出现在模型的某个中间版本。在此阶段,DeepSeek-R1-Zero 学会了通过重新评估其初始方法,为问题分配更多的思考时间。这一行为不仅展示了模型日益增长的推理能力,也生动地说明了强化学习如何能够产生意想不到的复杂结果。
这一“顿悟时刻”不仅是模型的顿悟,也是观察其行为的研究人员的顿悟。它突显了强化学习的力量与美妙之处:我们无需显式地教导模型如何解决问题,只需为其提供适当的激励,它就能自主发展出高级的解决策略。
“顿悟时刻”提醒我们,强化学习具备解锁人工系统新智能水平的潜力,为未来更多自主且适应性强的模型铺平了道路。这一现象为推进 AI 系统的自主性和智能化提供了宝贵的启示。
问题: 如果 ,求方程 的所有实数解的和。
回答:
为了解决方程 ,我们从两边同时平方开始:
。
接下来,将方程变形以孤立出内部的平方根项:
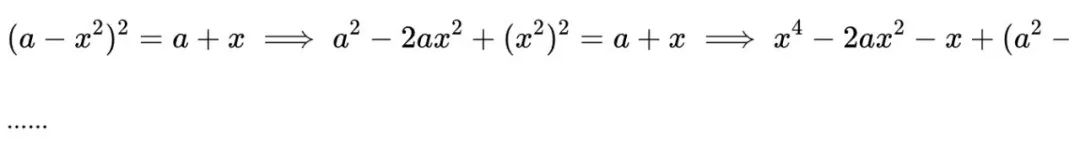
等一下,等一下,等一下。这里我发现了一个“顿悟时刻 (aha moment)”。
我们需要逐步重新评估,看看是否能找到正确的解和……
我们从原始方程开始:
首先,两边平方:
。
接下来,我可以再次对两边平方,并继续处理方程……
表 3 | DeepSeek-R1-Zero 中间版本的一个有趣的“顿悟时刻”。模型通过拟人化的方式学会了重新思考。这对我们而言也是一个“顿悟时刻”,让我们见证了强化学习的力量与美妙之处。
DeepSeek-R1-Zero 的局限性 (Drawback of DeepSeek-R1-Zero)
虽然 DeepSeek-R1-Zero 展示了强大的推理能力,并能自主发展出意想不到且强大的推理行为,但仍面临一些问题。例如,DeepSeek-R1-Zero 在可读性和语言混杂等方面存在挑战。为了让推理过程更加易读并与研究社区共享,我们开发了 DeepSeek-R1,这种方法结合了具有用户友好特性的冷启动数据和强化学习。
2.3 DeepSeek-R1:具有冷启动的强化学习 (Reinforcement Learning with Cold Start)
受 DeepSeek-R1-Zero 取得的成果启发,我们提出了两个自然问题:
-
是否能通过引入少量高质量的冷启动数据进一步提升推理性能或加快收敛速度?
-
如何训练出既能生成清晰、连贯的推理链 (Chain of Thought, CoT),又具备强大通用能力的用户友好型模型?
为了回答这些问题,我们设计了一个用于训练 DeepSeek-R1 的管道,主要包括以下四个阶段:
2.3.1 冷启动 (Cold Start)
与 DeepSeek-R1-Zero 不同,为了避免强化学习在基础模型上的早期不稳定阶段,DeepSeek-R1 使用了一小部分长推理链数据进行微调,作为初始强化学习模型的基础。我们通过以下几种方式收集这些数据:
-
使用带有长推理链示例的少样本提示 (few-shot prompting)。
-
直接提示模型生成带有反思和验证步骤的详细答案。
-
收集 DeepSeek-R1-Zero 输出的内容,并通过人工标注员进行后期处理。
在这项研究中,我们收集了数千条冷启动数据,对 DeepSeek-V3-Base 模型进行微调,作为强化学习的起点。与 DeepSeek-R1-Zero 相比,冷启动数据具有以下优势:
-
可读性 (Readability):DeepSeek-R1-Zero 的内容通常不易阅读,可能会混合多种语言,或缺乏用户友好的格式。例如,缺少 Markdown 格式的答案标注。而在为 DeepSeek-R1 创建冷启动数据时,我们设计了一种可读性较高的输出格式,包括在每个响应末尾添加总结部分,并过滤掉不适合阅读的响应。输出格式定义为:
其中,推理过程是查询的推理链,摘要部分用于总结推理结果。
-
潜力 (Potential):通过以人类偏好设计冷启动数据格式,我们观察到 DeepSeek-R1 相较于 DeepSeek-R1-Zero 性能明显提升。我们认为,采用迭代训练是改进推理模型的更优策略。
2.3.2 面向推理的强化学习 (Reasoning-oriented Reinforcement Learning)
在使用冷启动数据对 DeepSeek-V3-Base 进行微调后,我们对其应用了与 DeepSeek-R1-Zero 相同的大规模强化学习训练过程。此阶段专注于提升模型在推理密集型任务(如编程、数学、科学和逻辑推理)中的能力,这些任务通常涉及明确的问题和清晰的解决方案。
在训练过程中,我们发现推理链中经常出现语言混杂现象,尤其是在 RL 提示涉及多种语言时。为了缓解这一问题,我们在强化学习中引入了语言一致性奖励,该奖励根据推理链中目标语言词汇的占比进行计算。尽管消融实验表明,这种对齐会导致模型性能略微下降,但它使输出更加符合用户的阅读偏好。最终,我们将推理任务的准确性奖励与语言一致性奖励相结合,通过直接求和形成最终奖励信号,持续进行强化学习,直到模型在推理任务上达到收敛。
2.3.3 拒绝采样与监督微调 (Rejection Sampling and Supervised Fine-Tuning)
当面向推理的强化学习达到收敛时,我们利用生成的检查点 (checkpoint) 收集用于下一轮训练的监督微调 (SFT) 数据。与初始冷启动数据不同,此阶段的数据涵盖了更多领域,包括写作、角色扮演和其他通用任务。具体来说,我们生成以下数据并对模型进行微调:
-
推理数据 (Reasoning data):我们从上述强化学习检查点中进行拒绝采样,生成推理提示和推理过程。在之前的阶段中,仅包含基于规则奖励验证的数据。然而,在此阶段,我们扩展了数据集,部分数据使用生成式奖励模型进行评估,将真实答案和模型预测输入到 DeepSeek-V3 进行判断。此外,由于模型输出有时较为混乱,我们过滤掉了语言混杂、段落过长以及代码块过多的推理链。对于每个提示,我们采样多个响应,仅保留正确的答案。最终,我们收集了约 60 万条与推理相关的训练样本。
-
非推理数据 (Non-Reasoning Data):
对于非推理数据(如写作、事实问答 (factual QA)、自我认知 (self-cognition) 和翻译),我们采用 DeepSeek-V3 的数据处理管道,并复用了部分 DeepSeek-V3 的 SFT 数据集。在某些非推理任务中,我们通过提示让 DeepSeek-V3 生成潜在的推理链 (CoT),然后再回答问题。然而,对于较简单的查询(如“你好”),我们不会提供推理链作为响应。最终,我们收集了大约 20 万条与推理无关的训练样本。
我们使用上述大约 80 万条样本对 DeepSeek-V3-Base 进行了两轮微调训练 (two epochs)。
2.3.4 面向所有场景的强化学习 (Reinforcement Learning for All Scenarios)
为了进一步使模型符合人类偏好,我们实施了第二阶段的强化学习,旨在改进模型的有用性 (helpfulness) 和无害性 (harmlessness),同时进一步优化其推理能力。
具体来说,我们通过结合多种奖励信号和多样化的提示分布来训练模型:
-
推理数据 (Reasoning Data):我们遵循 DeepSeek-R1-Zero 的方法,使用基于规则的奖励 (rule-based rewards) 来指导模型在数学、编程和逻辑推理领域的学习。
-
通用数据 (General Data):我们采用奖励模型 (reward models) 捕捉人类在复杂和细微场景中的偏好。我们基于 DeepSeek-V3 管道构建了偏好对 (preference pairs) 和训练提示的分布。
-
有用性 (Helpfulness):我们专注于最终的摘要部分,确保评估重点关注响应对用户的实用性和相关性,同时尽量减少对底层推理过程的干扰。
-
无害性 (Harmlessness):我们对模型的整个输出进行评估,包括推理过程和摘要,以识别并减轻生成过程中可能出现的风险、偏见或有害内容。
通过将奖励信号和多样化的数据分布相结合,我们成功训练出了一种既在推理任务中表现卓越,又能优先保证有用性和无害性的模型。
2.4 蒸馏:赋予小型模型推理能力 (Distillation: Empower Small Models with Reasoning Capability)
为了让更高效的小型模型具备与 DeepSeek-R1 类似的推理能力,我们基于 §2.3.3 中描述的 80 万条 DeepSeek-R1 数据集,对开源模型(如 Qwen (Qwen, 2024b) 和 Llama (AI@Meta, 2024))进行了直接微调。研究结果表明,这种简单的蒸馏方法显著增强了小型模型的推理能力。
我们使用的基础模型包括:
-
Qwen 系列:Qwen2.5-Math-1.5B、Qwen2.5-Math-7B、Qwen2.5-14B、Qwen2.5-32B
-
Llama 系列:Llama-3.1-8B 和 Llama-3.3-70B-Instruct
我们选择了 Llama-3.3,因为其推理能力略优于 Llama-3.1。
对于蒸馏模型,我们仅应用了监督微调 (SFT),并未引入强化学习阶段。尽管引入强化学习可能会显著提升模型性能,但本研究的主要目标是验证蒸馏技术的有效性,进一步探索强化学习阶段的潜力则留给更广泛的研究社区。
3. 实验 (Experiment)
基准测试 (Benchmarks)
我们对模型在多个基准测试中进行了评估,包括:
-
MMLU (Hendrycks et al., 2020)、
-
MMLU-Redux (Gema et al., 2024)、
-
MMLU-Pro (Wang et al., 2024)、
-
C-Eval (Huang et al., 2023)、
-
CMMLU (Li et al., 2023)、
-
IF-Eval (Zhou et al., 2023)、
-
FRAMES (Krishna et al., 2024)、
-
GPQA Diamond (Rein et al., 2023)、
-
SimpleQA (OpenAI, 2024c)、
-
C-SimpleQA (He et al., 2024)、
-
SWE-Bench Verified (OpenAI, 2024d)、
-
Aider、
-
LiveCodeBench (Jain et al., 2024)(2024 年 8 月至 2025 年 1 月)、
-
Codeforces、
-
中国全国高中数学奥林匹克竞赛 (CNMO 2024)
-
美国数学邀请赛 (AIME 2024) (MAA, 2024)。
除了标准基准测试之外,我们还在开放式生成任务中使用 LLM 作为评审员进行评估。我们遵循 AlpacaEval 2.0 (Dubois et al., 2024) 和 Arena-Hard (Li et al., 2024) 的原始配置,这些框架利用 GPT-4-Turbo-1106 进行成对比较评估。为避免因输出长度导致的偏差,我们仅向评审员提供最终的摘要部分。对于蒸馏模型,我们报告了 AIME 2024、MATH-500、GPQA Diamond、Codeforces 和 LiveCodeBench 上的代表性结果。
评估提示 (Evaluation Prompts)
按照 DeepSeek-V3 的设置,MMLU、DROP、GPQA Diamond 和 SimpleQA 等标准基准测试使用 simple-evals 框架中的提示进行评估。对于 MMLU-Redux,我们在零样本 (zero-shot) 设置中采用了 Zero-Eval 提示格式 (Lin, 2024)。在 MMLU-Pro、C-Eval 和 CLUE-WSC 中,由于原始提示是少样本 (few-shot),我们将其稍作修改为零样本设置,因为少样本提示中的推理链 (CoT) 可能会降低 DeepSeek-R1 的性能。其他数据集则遵循其创建者提供的原始评估协议和默认提示。
在代码和数学基准测试中,HumanEval-Mul 数据集涵盖了八种主流编程语言(Python、Java、C++、C#、JavaScript、TypeScript、PHP 和 Bash)。在 LiveCodeBench 中,模型以推理链格式进行评估,数据收集时间为 2024 年 8 月至 2025 年 1 月。Codeforces 数据集使用 10 次 Div.2 比赛中的问题和专家编写的测试用例进行评估,随后计算参赛者的预期排名和百分比。SWE-Bench 的验证结果通过 Agentless 框架 (Xia et al., 2024) 获取。与 Aider 相关的基准测试使用“diff”格式进行测量。DeepSeek-R1 在每个基准测试上的输出长度限制为最多 32,768 个标记。
基线模型 (Baselines)
我们与多个强基线模型进行了全面比较,包括 DeepSeek-V3、Claude-Sonnet-3.5-1022、GPT-4o-0513、OpenAI-o1-mini 和 OpenAI-o1-1217。由于在中国大陆访问 OpenAI-o1-1217 API 存在困难,我们基于官方报告的数据进行性能比较。对于蒸馏模型,我们还与开源模型 QwQ-32B-Preview (Qwen, 2024a) 进行了对比。
评估设置 (Evaluation Setup)
我们将模型的最大生成长度设置为 32,768 个标记。在对长输出推理模型进行评估时,我们发现使用贪婪解码 (greedy decoding) 会导致输出重复率上升,并在不同检查点之间出现显著的性能波动。因此,我们默认使用 pass@k 评估方法 (Chen et al., 2021),并在非零温度 (temperature) 下报告 pass@1。具体来说,我们设置采样温度为 0.6,top-𝑝 值为 0.95,每个问题生成 个响应(通常在 4 到 64 之间,取决于测试集大小),然后计算 pass@1 得分:
,
其中 表示第 个响应的正确性。此方法提供了更可靠的性能估计。
在 AIME 2024 测试中,我们还报告了共识 (majority vote) 结果,称为 cons@64,使用 64 个样本进行多数投票评估 (Wang et al., 2022)。
参考链接:
-
Aider:https://aider.chat
-
Codeforces:https://codeforces.com
-
中国数学会全国高中数学竞赛 (CNMO):https://www.cms.org.cn/Home/comp/comp/cid/12.html
3.1 DeepSeek-R1 评估 (DeepSeek-R1 Evaluation)
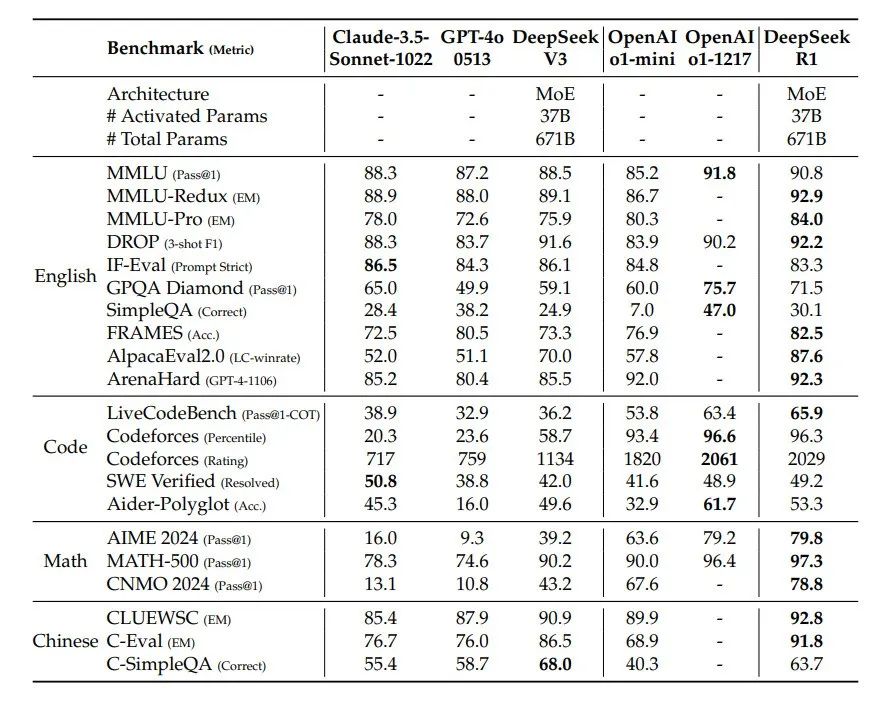
表 4 | DeepSeek-R1 与其他代表性模型的比较
在面向教育的知识基准测试(如 MMLU、MMLU-Pro 和 GPQA Diamond)中,DeepSeek-R1 的表现优于 DeepSeek-V3。这一提升主要归功于在 STEM 相关问题上的准确性增强,这些进步通过大规模强化学习 (RL) 实现。此外,DeepSeek-R1 在 FRAMES(依赖长上下文的问答任务)中表现出色,展示了其在文档分析任务中的强大能力。这一表现表明,推理模型在 AI 驱动的搜索和数据分析任务中具有巨大潜力。
在事实类基准测试 SimpleQA 上,DeepSeek-R1 的表现优于 DeepSeek-V3,展示了其处理基于事实查询的能力。类似的趋势也出现在 OpenAI-o1 超越 GPT-4o 的测试中。然而,在中文 SimpleQA 基准测试上,DeepSeek-R1 的表现不如 DeepSeek-V3,这主要是因为模型在安全性强化学习 (Safety RL) 后倾向于拒绝回答某些查询。如果不应用安全性强化学习,DeepSeek-R1 的准确率可超过 70%。
DeepSeek-R1 在 IF-Eval(用于评估模型遵循格式指令能力的基准测试)上也取得了出色的结果。这一改进与在监督微调 (SFT) 和强化学习 (RL) 最终阶段中引入的指令遵循数据有关。此外,在 AlpacaEval 2.0 和 ArenaHard 上表现突出,表明 DeepSeek-R1 在写作任务和开放领域问答中具有优势。其显著优于 DeepSeek-V3 的表现突显了大规模 RL 的泛化优势,不仅提升了推理能力,还改善了模型在多个领域的性能。
DeepSeek-R1 生成的摘要长度较为简洁:在 ArenaHard 上平均为 689 个标记 (tokens),在 AlpacaEval 2.0 上平均为 2,218 个字符。这表明 DeepSeek-R1 在基于 GPT 的评估中避免了长度偏差,从而进一步巩固了其在多任务中的稳健性。
在数学任务中,DeepSeek-R1 的表现与 OpenAI-o1-1217 相当,并远超其他模型。在编程算法任务(如 LiveCodeBench 和 Codeforces)中,推理导向的模型在基准测试中占据主导地位。在面向工程的编程任务上,OpenAI-o1-1217 在 Aider 中表现优于 DeepSeek-R1,但在 SWE Verified 上表现相当。我们认为,DeepSeek-R1 的工程类任务表现将在下一版本中进一步提升,因为目前相关的强化学习训练数据仍较为有限。
3.2 蒸馏模型评估 (Distilled Model Evaluation)
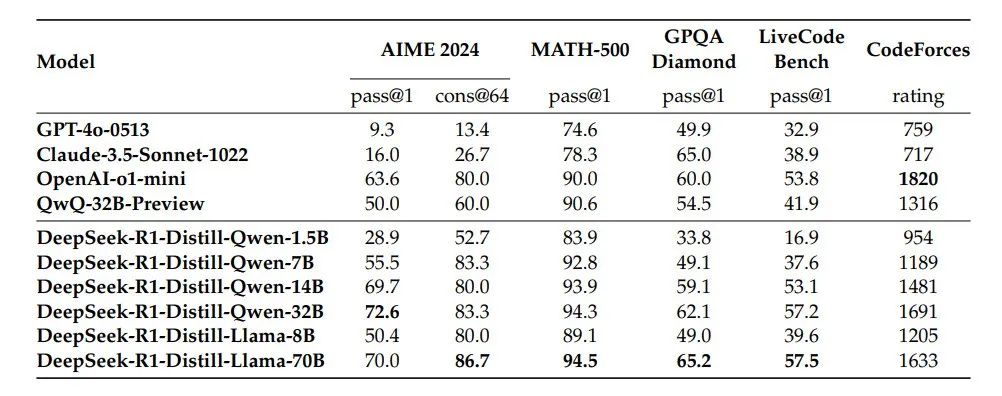
表 5 | DeepSeek-R1 蒸馏模型与其他可比模型在推理基准测试中的比较
如表 5 所示,仅通过蒸馏 DeepSeek-R1 的输出,就使得高效的 DeepSeek-R1-7B(即 DeepSeek-R1-Distill-Qwen-7B,下文使用类似缩写)在各个方面都优于非推理优化模型(如 GPT-4o-0513)。DeepSeek-R1-14B 在所有评估指标上都超过了 QwQ-32B-Preview,而 DeepSeek-R1-32B 和 DeepSeek-R1-70B 在大多数基准测试中显著优于 o1-mini。这些结果表明蒸馏技术具有很大的潜力。
此外,我们发现对这些蒸馏模型应用强化学习 (RL) 可以进一步显著提高性能。我们认为这一点值得进一步探索,因此在此仅展示了基于简单监督微调 (SFT) 的蒸馏模型的结果。
4. 讨论 (Discussion)
4.1 蒸馏与强化学习的比较 (Distillation v.s. Reinforcement Learning)
在 3.2 节的实验结果中可以看到,通过对 DeepSeek-R1 进行蒸馏,小型模型能够取得令人印象深刻的结果。然而,仍然存在一个问题:模型是否可以通过文中讨论的大规模强化学习(而不依赖蒸馏)达到类似的性能?
为了解答这一问题,我们在 Qwen-32B-Base 模型上进行了大规模强化学习,使用数学、代码和 STEM(科学、技术、工程和数学)数据进行了超过 10,000 步的训练,生成了 DeepSeek-R1-Zero-Qwen-32B。实验结果(见表 6)表明,该 32B 基础模型经过大规模 RL 训练后,其性能与 QwQ-32B-Preview 相当。然而,从 DeepSeek-R1 蒸馏得到的 DeepSeek-R1-Distill-Qwen-32B 在所有基准测试中都明显优于 DeepSeek-R1-Zero-Qwen-32B。

表 6 | 蒸馏模型与强化学习模型在推理相关基准测试中的比较
因此,我们可以得出两个结论:
-
将强大的模型能力蒸馏到小型模型中是一个高效且效果显著的方法,而小型模型依赖于文中提到的大规模 RL 训练可能需要巨大的计算资源,且其性能可能难以达到蒸馏模型的水平。
-
尽管蒸馏策略既经济又有效,但要突破智能的边界,可能仍需依赖更强大的基础模型和更大规模的强化学习。
4.2 不成功的尝试 (Unsuccessful Attempts)
在 DeepSeek-R1 的开发早期阶段,我们也遇到了一些失败和挫折。在此分享这些失败经验,以提供见解,但这并不意味着这些方法无法开发出有效的推理模型。
过程奖励模型 (Process Reward Model, PRM)
PRM 是一种合理的方法,用于引导模型采用更优的策略来解决推理任务 (Lightman et al., 2023;Uesato et al., 2022;Wang et al., 2023)。然而,在实际操作中,PRM 存在三个主要局限,这些局限可能阻碍其最终成功:
-
难以明确定义细粒度步骤:在通用推理任务中,很难显式地定义每一步的细节。
-
中间步骤的正确性难以判断:确定当前中间步骤是否正确是一个挑战。使用模型进行自动标注往往无法得到理想结果,而人工标注则难以扩展。
-
**奖励黑客问题 (Reward Hacking)**:一旦引入基于模型的 PRM,就不可避免地会出现奖励黑客现象 (Gao et al., 2022)。此外,重新训练奖励模型需要额外的训练资源,使整个训练管道更加复杂。
总的来说,尽管 PRM 在对模型生成的前 N 个响应进行重新排序 (rerank) 或在引导搜索 (guided search) 中表现良好,但与其在大规模强化学习中引入的额外计算开销相比,其优势较为有限。
蒙特卡罗树搜索 (Monte Carlo Tree Search, MCTS)
受到 AlphaGo (Silver et al., 2017b) 和 AlphaZero (Silver et al., 2017a) 的启发,我们尝试使用蒙特卡罗树搜索 (MCTS) 来增强测试时计算扩展能力 (compute scalability)。该方法将答案分解为更小的部分,使模型能够系统地探索解空间。
为了实现这一目标,我们提示模型生成多个与特定推理步骤对应的标签,以便在搜索过程中使用。在训练中,我们首先使用收集到的提示,通过预训练的价值模型 (value model) 指导 MCTS 搜索答案。随后,我们利用生成的问题-答案对 (question-answer pairs) 对 actor 模型和价值模型进行训练,并通过迭代不断优化过程。
然而,这一方法在扩展训练规模时遇到了几个挑战:
首先,与搜索空间相对明确的国际象棋不同,生成令牌 (token) 的搜索空间呈指数级增长。为应对这一问题,我们为每个节点设定了最大扩展限制,但这可能导致模型陷入局部最优 (local optima)。
其次,价值模型 (value model) 在生成质量上具有直接影响,因为它指导了搜索过程中的每一步。然而,训练一个精细的价值模型本身难度很大,这使得模型在迭代改进中面临挑战。尽管 AlphaGo 的核心成功依赖于通过训练价值模型逐步提升性能,但由于令牌生成的复杂性,这一原则在我们的设置中难以复制。
总之,尽管在配合预训练的价值模型时,MCTS 能在推理阶段提高模型性能,但通过自搜索 (self-search) 迭代提升模型性能仍然是一个重大挑战。
5. 结论、局限与未来工作 (Conclusion, Limitations, and Future Work)
在本研究中,我们分享了通过强化学习 (RL) 提升模型推理能力的探索过程。DeepSeek-R1-Zero 代表了一种不依赖冷启动数据的纯 RL 方法,在多个任务中取得了出色的性能。DeepSeek-R1 则通过结合冷启动数据和迭代的 RL 微调,进一步增强了性能,最终在多个任务中达到了与 OpenAI-o1-1217 相当的表现。
我们还进一步探索了将推理能力蒸馏 (distillation) 到小型密集模型 (dense models) 的可能性。以 DeepSeek-R1 作为教师模型 (teacher model),我们生成了 80 万条训练样本,并对多个小型密集模型进行了微调。结果表明,这些模型表现出色:例如,DeepSeek-R1-Distill-Qwen-1.5B 在数学基准测试中超过了 GPT-4o 和 Claude-3.5-Sonnet,分别在 AIME 上取得了 28.9% 和在 MATH 上取得了 83.9% 的成绩。其他密集模型也在基准测试中取得了显著优于同类指令调优模型的成绩。
未来,我们计划在以下方向上进一步研究 DeepSeek-R1:
-
通用能力 (General Capability):目前,DeepSeek-R1 在函数调用 (function calling)、多轮对话 (multi-turn)、复杂角色扮演 (complex role-playing) 和 JSON 输出等任务中的能力不及 DeepSeek-V3。未来,我们计划探索如何利用长推理链 (CoT) 来增强这些任务的表现。
-
语言混杂 (Language Mixing):DeepSeek-R1 当前针对中文和英文进行了优化,这可能在处理其他语言的查询时导致语言混杂问题。例如,即使查询使用的是非中英文,DeepSeek-R1 也可能在推理和响应中使用英语。我们计划在未来的更新中解决这一局限。
-
提示工程 (Prompting Engineering):在对 DeepSeek-R1 进行评估时,我们发现模型对提示较为敏感。少样本提示 (few-shot prompting) 会持续降低其性能。因此,我们建议用户使用零样本 (zero-shot) 设置,直接描述问题并指定输出格式,以获得最佳效果。
-
软件工程任务 (Software Engineering Tasks):由于评估时间较长影响了强化学习过程的效率,大规模强化学习尚未广泛应用于软件工程任务。因此,DeepSeek-R1 在软件工程基准测试中的表现未能显著超越 DeepSeek-V3。未来版本将通过在软件工程数据上实施拒绝采样 (rejection sampling) 或在强化学习过程中引入异步评估 (asynchronous evaluations) 来提高效率。









阅读最新前沿科技趋势报告,请访问欧米伽研究所的“未来知识库”
https://wx.zsxq.com/group/454854145828

未来知识库是“欧米伽未来研究所”建立的在线知识库平台,收藏的资料范围包括人工智能、脑科学、互联网、超级智能,数智大脑、能源、军事、经济、人类风险等等领域的前沿进展与未来趋势。目前拥有超过8000篇重要资料。每周更新不少于100篇世界范围最新研究资料。欢迎扫描二维码或访问https://wx.zsxq.com/group/454854145828 进入。

截止到12月25日 ”未来知识库”精选的100部前沿科技趋势报告
-
2024 美国众议院人工智能报告:指导原则、前瞻性建议和政策提案
-
未来今日研究所:2024 技术趋势报告 - 移动性,机器人与无人机篇
-
Deepmind:AI 加速科学创新发现的黄金时代报告
-
Continental 大陆集团:2024 未来出行趋势调研报告
-
埃森哲:未来生活趋势 2025
-
国际原子能机构 2024 聚变关键要素报告 - 聚变能发展的共同愿景
-
哈尔滨工业大学:2024 具身大模型关键技术与应用报告
-
爱思唯尔(Elsevier):洞察 2024:科研人员对人工智能的态度报告
-
李飞飞、谢赛宁新作「空间智能」 等探索多模态大模型性能
-
欧洲议会:2024 欧盟人工智能伦理指南:背景和实施
-
通往人工超智能的道路:超级对齐的全面综述
-
清华大学:理解世界还是预测未来?世界模型综合综述
-
Transformer 发明人最新论文:利用基础模型自动搜索人工生命
-
兰德公司:新兴技术监督框架发展的现状和未来趋势的技术监督报告
-
麦肯锡全球研究院:2024 年全球前沿动态(数据)图表呈现
-
兰德公司:新兴技术领域的全球态势综述
-
前瞻:2025 年人形机器人产业发展蓝皮书 - 人形机器人量产及商业化关键挑战
-
美国国家标准技术研究院(NIST):2024 年度美国制造业统计数据报告(英文版)
-
罗戈研究:2024 决策智能:值得关注的决策革命研究报告
-
美国航空航天专家委员会:2024 十字路口的 NASA 研究报告
-
中国电子技术标准化研究院 2024 扩展现实 XR 产业和标准化研究报告
-
GenAI 引领全球科技变革关注 AI 应用的持续探索
-
国家低空经济融创中心中国上市及新三板挂牌公司低空经济发展报告
-
2025 年计算机行业年度策略从 Infra 到 AgentAI 创新的无尽前沿
-
多模态可解释人工智能综述:过去、现在与未来
-
【斯坦福博士论文】探索自监督学习中对比学习的理论基础
-
《机器智能体的混合认知模型》最新 128 页
-
Open AI 管理 AI 智能体的实践
-
未来生命研究院 FLI2024 年 AI 安全指数报告 英文版
-
兰德公司 2024 人工智能项目失败的五大根本原因及其成功之道 - 避免 AI 的反模式 英文版
-
Linux 基金会 2024 去中心化与人工智能报告 英文版
-
脑机接口报告脑机接口机器人中的人机交换
-
联合国贸发会议 2024 年全球科技创新合作促发展研究报告 英文版
-
Linux 基金会 2024 年世界开源大会报告塑造人工智能安全和数字公共产品合作的未来 英文版
-
Gartner2025 年重要战略技术趋势报告 英文版
-
Fastdata 极数 2024 全球人工智能简史
-
中电科:低空航行系统白皮书,拥抱低空经济
-
迈向科学发现的生成式人工智能研究报告:进展、机遇与挑战
-
哈佛博士论文:构建深度学习的理论基础:实证研究方法
-
Science 论文:面对 “镜像生物” 的风险
-
镜面细菌技术报告:可行性和风险
-
Neurocomputing 不受限制地超越人类智能的人工智能可能性
-
166 页 - 麦肯锡:中国与世界 - 理解变化中的经济联系(完整版)
-
未来生命研究所:《2024 人工智能安全指数报告》
-
德勤:2025 技术趋势报告 空间计算、人工智能、IT 升级。
-
2024 世界智能产业大脑演化趋势报告(12 月上)公开版
-
联邦学习中的成员推断攻击与防御:综述
-
兰德公司 2024 人工智能和机器学习在太空领域感知中的应用 - 基于两项人工智能案例英文版
-
Wavestone2024 年法国工业 4.0 晴雨表市场趋势与经验反馈 英文版
-
Salesforce2024 年制造业趋势报告 - 来自全球 800 多位行业决策者对运营和数字化转型的洞察 英文版
-
MicrosoftAzure2024 推动应用创新的九大 AI 趋势报告
-
DeepMind:Gemini,一个高性能多模态模型家族分析报告
-
模仿、探索和自我提升:慢思维推理系统的复现报告
-
自我发现:大型语言模型自我组成推理结构
-
2025 年 101 项将 (或不会) 塑造未来的技术趋势白皮书
-
《自然杂志》2024 年 10 大科学人物推荐报告
-
量子位智库:2024 年度 AI 十大趋势报告
-
华为:鸿蒙 2030 愿景白皮书(更新版)
-
电子行业专题报告:2025 年万物 AI 面临的十大待解难题 - 241209
-
中国信通院《人工智能发展报告(2024 年)》
-
美国安全与新兴技术中心:《追踪美国人工智能并购案》报告
-
Nature 研究报告:AI 革命的数据正在枯竭,研究人员该怎么办?
-
NeurIPS 2024 论文:智能体不够聪明怎么办?让它像学徒一样持续学习
-
LangChain 人工智能代理(AI agent)现状报告
-
普华永道:2024 半导体行业状况报告发展趋势与驱动因素
-
觅途咨询:2024 全球人形机器人企业画像与能力评估报告
-
美国化学会 (ACS):2024 年纳米材料领域新兴趋势与研发进展报告
-
GWEC:2024 年全球风能报告英文版
-
Chainalysis:2024 年加密货币地理报告加密货币采用的区域趋势分析
-
2024 光刻机产业竞争格局国产替代空间及产业链相关公司分析报告
-
世界经济论坛:智能时代,各国对未来制造业和供应链的准备程度
-
兰德:《保护人工智能模型权重:防止盗窃和滥用前沿模型》-128 页报告
-
经合组织 成年人是否具备在不断变化的世界中生存所需的技能 199 页报告
-
医学应用中的可解释人工智能:综述
-
复旦最新《智能体模拟社会》综述
-
《全球导航卫星系统(GNSS)软件定义无线电:历史、当前发展和标准化工作》最新综述
-
《基础研究,致命影响:军事人工智能研究资助》报告
-
欧洲科学的未来 - 100 亿地平线研究计划
-
Nature:欧盟正在形成一项科学大型计划
-
Nature 欧洲科学的未来
-
欧盟科学 —— 下一个 1000 亿欧元
-
欧盟向世界呼吁 加入我们价值 1000 亿欧元的研究计划
-
DARPA 主动社会工程防御计划(ASED)《防止删除信息和捕捉有害行为者(PIRANHA)》技术报告
-
兰德《人工智能和机器学习用于太空域感知》72 页报告
-
构建通用机器人生成范式:基础设施、扩展性与策略学习(CMU 博士论文)
-
世界贸易组织 2024 智能贸易报告 AI 和贸易活动如何双向塑造 英文版
-
人工智能行业应用建设发展参考架构
-
波士顿咨询 2024 年欧洲天使投资状况报告 英文版
-
2024 美国制造业计划战略规划
-
【新书】大规模语言模型的隐私与安全
-
人工智能行业海外市场寻找 2025 爆款 AI 应用 - 241204
-
美国环保署 EPA2024 年版汽车趋势报告英文版
-
经济学人智库 EIU2025 年行业展望报告 6 大行业的挑战机遇与发展趋势 英文版
-
华为 2024 迈向智能世界系列工业网络全连接研究报告
-
华为迈向智能世界白皮书 2024 - 计算
-
华为迈向智能世界白皮书 2024 - 全光网络
-
华为迈向智能世界白皮书 2024 - 数据通信
-
华为迈向智能世界白皮书 2024 - 无线网络
-
安全牛 AI 时代深度伪造和合成媒体的安全威胁与对策 2024 版
-
2024 人形机器人在工业领域发展机遇行业壁垒及国产替代空间分析报告
-
《2024 年 AI 现状分析报告》2-1-3 页.zip
-
万物智能演化理论,智能科学基础理论的新探索 - newv2
-
世界经济论坛 智能时代的食物和水系统研究报告
-
生成式 AI 时代的深伪媒体生成与检测:综述与展望
-
科尔尼 2024 年全球人工智能评估 AIA 报告追求更高层次的成熟度规模化和影响力英文版
-
计算机行业专题报告 AI 操作系统时代已至 - 241201
-
Nature 人工智能距离人类水平智能有多近?
-
Nature 开放的人工智能系统实际上是封闭的
-
斯坦福《统计学与信息论》讲义,668 页 pdf
-
国家信息中心华为城市一张网 2.0 研究报告 2024 年
-
国际清算银行 2024 生成式 AI 的崛起对美国劳动力市场的影响分析报告 渗透度替代效应及对不平等状况英文版
-
大模型如何判决?从生成到判决:大型语言模型作为裁判的机遇与挑战
-
毕马威 2024 年全球半导体行业展望报告
-
MR 行业专题报告 AIMR 空间计算定义新一代超级个人终端 - 241119
-
DeepMind 36 页 AI4Science 报告:全球实验室被「AI 科学家」指数级接管
-
《人工智能和机器学习对网络安全的影响》最新 273 页
-
2024 量子计算与人工智能无声的革命报告
-
未来今日研究所:2024 技术趋势报告 - 广义计算篇
-
科睿唯安中国科学院 2024 研究前沿热度指数报告
-
文本到图像合成:十年回顾
-
《以人为中心的大型语言模型(LLM)研究综述》
-
经合组织 2024 年数字经济展望报告加强连通性创新与信任第二版
-
波士顿咨询 2024 全球经济体 AI 成熟度矩阵报告 英文版
-
理解世界还是预测未来?世界模型的综合综述
-
GoogleCloudCSA2024AI 与安全状况调研报告 英文版
-
英国制造商组织 MakeUK2024 英国工业战略愿景报告从概念到实施
-
花旗银行 CitiGPS2024 自然环境可持续发展新前沿研究报告
-
国际可再生能源署 IRENA2024 年全球气候行动报告
-
Cell: 物理学和化学 、人工智能知识领域的融合
-
智次方 2025 中国 5G 产业全景图谱报告
上下滑动查看更多

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 0
0 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)