LLMs基础学习(七)DeepSeek专题(3)
DeepSeek模型中的一些技术,归一化(Batch Norm、Layer Norm和RMS Norm),动态的Dynamic Tanh(DyT),多令牌预测(MTP)。
LLMs基础学习(七)DeepSeek专题(3)
文章目录
图片和视频链接:https://www.bilibili.com/video/BV1gR9gYsEHY?spm_id_from=333.788.player.switch&vd_source=57e4865932ea6c6918a09b65d319a99a
Batch Norm 和 Layer Norm
规范化原因
- 随着网络深度增加,各层特征分布趋近激活函数输出上下限,会使激活函数饱和,导致梯度消失。规范化能让特征值分布回归正态分布,落入激活函数敏感区间,避免梯度消失,加快收敛速度。
- 机器学习假设训练和测试数据服从独立同分布(Independent and Identically Distributed,IID),规范化可防止数据分布对模型产生不利影响。
基本介绍
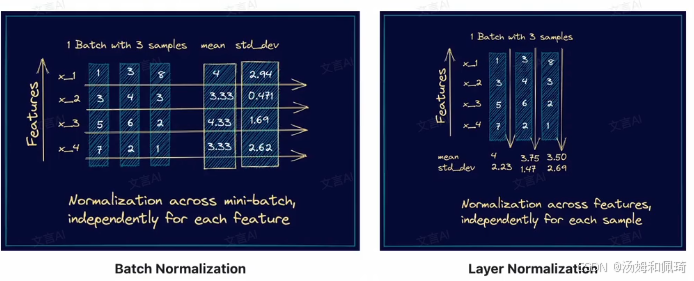
- 定义区别:Batch Norm 对一批样本中的每个特征进行归一化;Layer Norm 对每个样本中的所有特征进行归一化 。
- 图示说明:通过两张图展示。Batch Norm 图中,对一个 batch(含 3 个样本)里每个特征分别计算均值和标准差,实现 “在 mini - batch 维度上,对每个特征独立归一化” ;Layer Norm 图中,对每个样本内的所有特征计算均值和标准差,即 “在特征维度上,对每个样本独立归一化” 。
- 适用场景:
- 在计算机视觉领域,特征依赖不同样本间统计参数,Batch Norm 能消除不同特征间大小关系,保留样本间大小关系,所以更有效。
- 在自然语言处理(NLP)领域,单个样本不同特征是词语随时间的变化,样本内特征分布非常紧密,Layer Norm 更合适。
细节对比
-
Batch Normalization(Batch Norm):
- 对于输入的小批量数据 X = { x 1 , x 2 , ⋯ , x m } \mathbf{X}=\{x_1,x_2,\cdots,x_m\} X={x1,x2,⋯,xm} ,计算过程如下:
-
计算小批量的均值 μ B \mu_B μB 和方差 σ B 2 \sigma_B^2 σB2 :
-
-
- μ B = 1 m ∑ i = 1 m x i \mu_B=\frac{1}{m}\sum_{i = 1}^{m}x_i μB=m1∑i=1mxi
- σ B 2 = 1 m ∑ i = 1 m ( x i − μ B ) 2 \sigma_B^2=\frac{1}{m}\sum_{i = 1}^{m}(x_i - \mu_B)^2 σB2=m1∑i=1m(xi−μB)2
- 对每个元素 x i x_i xi 进行归一化: x ^ i = x i − μ B σ B 2 + ϵ \hat{x}_i=\frac{x_i - \mu_B}{\sqrt{\sigma_B^2+\epsilon}} x^i=σB2+ϵxi−μB
- 引入可学习的缩放参数 γ \gamma γ 和偏移参数 β \beta β : y i = γ x ^ i + β y_i=\gamma\hat{x}_i+\beta yi=γx^i+β
-
Layer Normalization(Layer Norm):
- 对于输入向量 x = ( x 1 , x 2 , ⋯ , x d ) \mathbf{x}=(x_1,x_2,\cdots,x_d) x=(x1,x2,⋯,xd) ,计算过程如下:
-
计算输入向量的均值 μ L \mu_L μL 和方差 σ L 2 \sigma_L^2 σL2 :
- μ L = 1 d ∑ i = 1 d x i \mu_L=\frac{1}{d}\sum_{i = 1}^{d}x_i μL=d1∑i=1dxi
- σ L 2 = 1 d ∑ i = 1 d ( x i − μ L ) 2 \sigma_L^2=\frac{1}{d}\sum_{i = 1}^{d}(x_i - \mu_L)^2 σL2=d1∑i=1d(xi−μL)2
-
对每个元素 x i x_i xi 进行归一化: x ^ i = x i − μ L σ L 2 + ϵ \hat{x}_i=\frac{x_i - \mu_L}{\sqrt{\sigma_L^2+\epsilon}} x^i=σL2+ϵxi−μL
-
引入可学习的缩放参数 γ \gamma γ 和偏移参数 β \beta β : y i = γ x ^ i + β y_i=\gamma\hat{x}_i+\beta yi=γx^i+β
小结
以表格形式呈现 Layer Norm 和 Batch Norm 的区别:
| 特性 | Layer Normalization(Layer Norm) | Batch Normalization(Batch Norm) |
|---|---|---|
| 归一化范围 | 在单个样本的特征维度上进行归一化,即对每个样本的所有特征进行归一化。 | 在整个 batch 维度上进行归一化,即对每个神经元的输出在当前小批量中进行归一化。 |
| 依赖性 | 对 batch size 不敏感,适用于小 batch 训练。 | 依赖于 batch size,当 batch size 较小时,均值和方差估计不准确,可能导致效果不稳定。 |
| 适用场景 | 适用于 RNN、Transformer 等模型。 | 常用于 CNN、深度网络等。 |
| 训练与推理 | 训练和推理时使用相同的统计量,即每个样本的均值和标准差是独立计算的。 | 训练时使用当前 batch 的均值和方差,推理时使用整个训练集的均值和方差(通常通过移动平均估计)。 |
RMS Norm 和 Layer Norm
基础知识
- RMSNorm 是 LayerNorm 的一个简单变体,出自 2019 年的论文《Root Mean Square Layer Normalization》 ,被 T5、Gamma 和 DeepSeek 模型使用 。
- 提出动机是 LayerNorm 运算量较大,RMSNorm 性能与 LayerNorm 相当,但能节省 7% - 64% 的运算。
- 而这主要的区别是:RMSNorm 不需要同时计算均值和方差这两个统计量,只需要计算均方根 Rooe Mean Square 这一个统计量。
具体计算过程
- 对于输入向量 x = ( x 1 , x 2 , ⋯ , x d ) \mathbf{x}=(x_1,x_2,\cdots,x_d) x=(x1,x2,⋯,xd) ,RMSNorm 的计算过程如下:
- 计算输入向量的均方根(RMS): RMS ( x ) = 1 d ∑ i = 1 d x i 2 \text{RMS}(\mathbf{x}) = \sqrt{\frac{1}{d}\sum_{i = 1}^{d}x_{i}^{2}} RMS(x)=d1∑i=1dxi2
- 对每个元素 x i x_i xi 进行归一化: x ^ i = x i RMS ( x ) + ϵ \hat{x}_i = \frac{x_i}{\text{RMS}(\mathbf{x}) + \epsilon} x^i=RMS(x)+ϵxi
- 引入可学习的缩放参数 γ \gamma γ : y i = γ x ^ i y_i = \gamma\hat{x}_i yi=γx^i
-
为什么 RMSNorm 仅保留缩放参数 γ \gamma γ ,去除了平移参数 β \beta β ,效果依然 ok?
-
均值调整的必要性降低:在 Transformer 等架构中,残差连接(Residual Connection)直接将输入加到输出上,保留了输入向量的均值信息。即使归一化过程未显式调整均值(如 RMSNorm ),模型仍可通过残差路径传递原始均值,降低了平移参数的必要性。
-
缩放参数主导分布调整:在自然语言等高维空间中,向量方向(由缩放参数 γ \gamma γ 调节)比绝对位置(由平移参数 β \beta β 调节)更重要。RMSNorm 通过调整向量模长,保留方向信息,更符合任务需求。
-
实验验证的适应性:论文实证表明,RMSNorm 在多项任务中与 LayerNorm 性能相当,甚至更优。这表明平移参数在某些场景下可能被过参数化,或其对模型性能的影响被其他机制(如注意力机制、前馈网络 )补偿。
-
14.3 对比
以表格形式呈现 Layer Norm 和 RMS Norm 的区别:
| 特性 | Layer Normalization(LayerNorm) | RMS Normalization(RMSNorm) |
|---|---|---|
| 归一化方式 | 对每个样本在特征维度上计算均值和方差,进行归一化。 | 对每个样本在特征维度上仅计算均方根(RMS),进行归一化。 |
| 是否引入平移参数 | 是,通过可学习的平移参数 β \beta β 。 | 否,没有平移参数。 |
| 计算复杂度 | 较高,需要计算均值和方差。 | 较低,仅需计算均方根。 |
| 适用场景 | 广泛用于 NLP 和序列模型(如 Transformer ),在需要较强表达能力的任务中表现优异。 | 适用于对计算效率要求较高的场景,尤其在大规模模型或资源受限的环境中。 |
| 表达能力 | 强,引入了可学习的平移参数,能够更好地拟合数据分布。 | 较弱,没有平移参数,但计算效率更高。 |
小结
对于 LayerNorm 和 RMSNorm,LayerNorm 包含缩放和平移两部分,RMSNorm 去除了平移部分,只保留了缩放部分。
Dynamic Tanh (DyT)
基本信息
- 研究聚焦于 “没有归一化层的 Transformer (Transformers without Normalization)” 。此论文于 2025 年 3 月 14 日在 arxiv 平台发布,并且已经被 CVPR 2025 会议接收。作者团队阵容强大,涵盖了 Jiachen Zhu、Xinlei Chen、Kaiming He、Yann LeCun、Zhuang Liu 等人,分别来自 Meta、NYU(纽约大学)、MIT(麻省理工学院)、普林斯顿大学等知名机构。
DyT 是什么
-
定义阐述:Dynamic Tanh (DyT) 是一种用于替代传统归一化层(比如 Layer Norm 或 RMSNorm )的简单元素级操作。其具体定义为
-
DyT ( x ) = γ ⋅ tanh ( α x ) + β \text{DyT}(x)=\gamma\cdot\tanh(\alpha x)+\beta DyT(x)=γ⋅tanh(αx)+β 。
-
在这个公式中, α \alpha α 是可学习的标量参数,它能够动态地调整输入的缩放因子;而 γ \gamma γ 和 β \beta β 同样是可学习的参数,主要作用是对输出进行缩放和平移。这一操作旨在通过简单的元素级计算来实现类似归一化层的功能,却无需进行复杂的统计计算。
-
Tanh 函数介绍:
-
数学定义:Tanh 函数(双曲正切函数)的数学表达式为 tanh ( x ) = e x − e − x e x + e − x = e 2 x − 1 e 2 x + 1 \tanh(x)=\frac{e^{x}-e^{-x}}{e^{x}+e^{-x}}=\frac{e^{2x}-1}{e^{2x}+1} tanh(x)=ex+e−xex−e−x=e2x+1e2x−1 ,这是基于指数函数的一种非线性变换形式。
-
输出范围:该函数的输出值域被限定在 (-1, 1) 区间内。这种以零为中心的输出特性,在神经网络中具有重要意义。它有助于缓解在梯度更新过程中可能出现的偏移问题,使得网络在训练过程中能够更稳定地收敛,加快模型学习的速度。
-
函数图像:
-
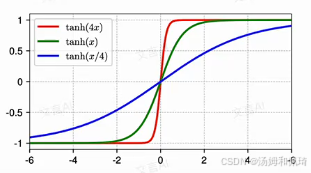
Tanh 函数的图像呈现出平滑的 S 型曲线(Sigmoid 曲线 )形态。
-
当输入值趋近于正无穷大时,函数的输出趋近于 1;当输入值趋近于负无穷大时,输出趋近于 -1 。
-
而在原点附近(即 x = 0 x = 0 x=0 处),曲线的斜率达到最大,且其值为 1,此时输出近似于线性变化。此外,还展示了 tanh ( 4 x ) \tanh(4x) tanh(4x)、 tanh ( x ) \tanh(x) tanh(x)、 tanh ( x / 4 ) \tanh(x/4) tanh(x/4) 三条不同参数下的曲线图像,通过对比可以更直观地看出参数变化对函数形态的影响。
-
-
DyT 解决的问题
-
归一化层复习:首先给出了归一化层的基本公式
-
y = γ ∗ x − μ σ 2 + ϵ + β y=\gamma * \frac{x - \mu}{\sqrt{\sigma^{2}+\epsilon}}+\beta y=γ∗σ2+ϵx−μ+β 。
-
其中, μ \mu μ 代表输入的均值, σ 2 \sigma^{2} σ2 是输入的方差, γ \gamma γ 和 β \beta β 是可学习的参数。
-
不同的归一化方法在计算这些统计量的方式上存在差异。例如,
- **批量归一化(BN )**主要应用于卷积神经网络(ConvNets),它计算的是跨批次和通道的均值和方差;
- **层归一化(LN )**则主要用于 Transformer 模型,针对每个样本中每个 token 计算均值和方差;
- **均方根归一化(RMSNorm )**是对 LN 的一种简化,去除了均值中心化步骤,仅计算均方根相关统计量。
-
归一化层的作用:
-
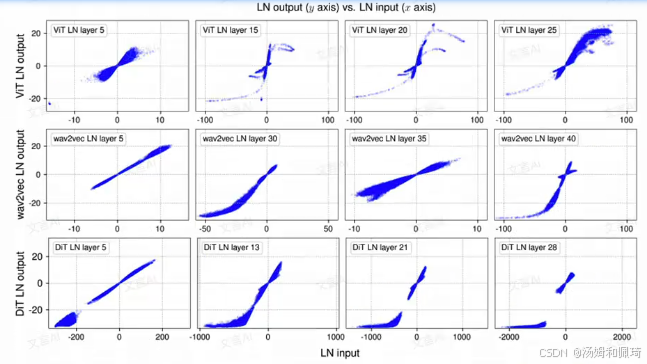
下图展示了 Vision Transformer(ViT )、wav2vec 2.0(语音 Transformer 模型 )和 Diffusion Transformer(DiT )中选定层归一化(LN )层的输入与输出。通过对小批量样本采样,绘制出每个模型中四个 LN 层的输入 / 输出值(输出为 LN 中仿射变换之前的值 ),发现其 S 形曲线与 tanh 函数形状高度相似,早期层中较接近线性的形状也可用 tanh 曲线中心部分描述,这成为提出 DyT 并引入可学习缩放因子 α 的启发点。
-
从图中可以清晰地看到,这些点的分布趋势与 tanh 函数的形状高度契合。这一发现启发了研究者提出 Dynamic Tanh (DyT) 作为替代方案,并引入一个可学习的缩放因子 α \alpha α ,目的是为了适应不同的 x 轴尺度变化,从而更好地模拟和改进归一化层的功能。同时,还对归一化(将输入进行均值归一化和方差归一化,使其均值为 0,方差为 1 )和仿射变换(引入可学习的缩放参数 γ \gamma γ 和偏移参数 β \beta β ,对归一化后的数据进行灵活调整 )的概念进行了简要解释。
-
归一化(Normalization):对输入x进行均值归一化和方差归一化,使其均值为 0,方差为 1,公式为 x ^ i = x i − μ B σ B 2 + ϵ \hat{x}_i = \frac{x_i - \mu_B}{\sqrt{\sigma_B^2 + \epsilon}} x^i=σB2+ϵxi−μB ,其中 μ B \mu_B μB 是输入的均值 , σ B 2 \sigma_B^2 σB2 是输入的方差 , ϵ \epsilon ϵ 是防止分母为零的极小值。
-
仿射变换(Affine Transformation):引入可学习的缩放参数 γ \gamma γ 和偏移参数 β \beta β ,对归一化后的数据进行灵活调整,公式为 y i = γ x ^ i + β y_i = \gamma\hat{x}_i + \beta yi=γx^i+β 。
-
-
解决的问题:传统的归一化层,以 Layer Norm 为例,一直被认为是训练深度网络尤其是 Transformer 模型的必要组件,它在稳定训练过程和加速收敛方面发挥了重要作用。然而,它也存在一些问题。
- 其一,计算开销较大,需要计算每个 token 的均值和方差,这在大规模数据和复杂模型中会带来较高的计算成本;
- 其二,架构复杂性较高,归一化层的统计计算方式在一定程度上限制了模型设计的灵活性,使得模型架构的调整和创新受到约束;
- 其三,从性能角度来看,研究表明归一化层的非线性特性,例如对极端值的压缩等功能,有可能被其他更简单的方式替代**。DyT 通过采用无需进行复杂统计计算的非线性操作**,有效地解决了上述问题,并且在实际应用中能够保持甚至提升模型的性能。
DyT的实现
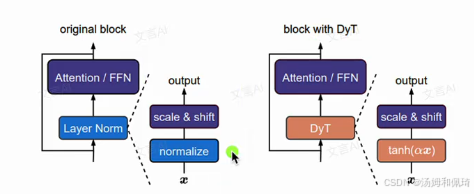
- 理论分析:通过图示的方式,对原始的 Transformer 块和采用 DyT 层的 Transformer 块进行了直观对比。从图中可以清晰地看到,在原始 Transformer 块中,包含了 Attention/FFN 模块以及 Layer Norm 层,经过归一化和缩放平移操作后输出;而在采用 DyT 层的 Transformer 块中,DyT 层直接替代了 Layer Norm 层,通过 tanh ( α x ) \tanh(\alpha x) tanh(αx) 操作以及后续的缩放平移操作输出。这表明 DyT 是一种对常用层归一化(Layer Norm )甚至在某些情况下对 RMSNorm 的直接替代方案。并且,研究表明采用 DyT 的 Transformer 在性能上能够匹配甚至超越使用传统归一化层的对应模型,这为其实际应用提供了有力的理论支持。
- code 实现:提供了基于 PyTorch 的 DyT 类的具体代码实现。在 init 方法中,首先调用父类的初始化方法,然后初始化了三个可学习参数:self.alpha 作为标量参数,用于动态缩放;self.gamma 作为通道级缩放参数;self.beta 作为通道级偏移参数。在 forward 方法中,先对输入 x 进行动态缩放和非线性压缩操作,即通过 torch.tanh(self.alpha * x) 实现,然后再进行仿射变换,通过 self.gamma * x + self.beta 返回最终结果。这样的代码实现简洁明了,清晰地展现了 DyT 的计算过程在实际编程中的体现。
DyT(Dynamic Tanh)的 PyTorch 代码实现:
class DyT(nn.Module):
def __init__(self, dim, init_alpha=0.5):
super().__init__()
self.alpha = nn.Parameter(torch.tensor(init_alpha)) # 标量参数
self.gamma = nn.Parameter(torch.ones(dim)) # 通道级缩放
self.beta = nn.Parameter(torch.zeros(dim)) # 通道级偏移
def forward(self, x):
x = torch.tanh(self.alpha * x) # 动态缩放 + 非线性压缩
return self.gamma * x + self.beta # 仿射变换
DyT的优势
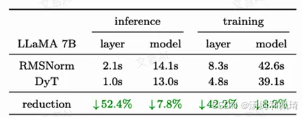
- 计算效率显著提升:通过表格对比了在 LLaMA 7B 模型中,RMSNorm 和 DyT 在推理(inference)和训练(training)两个阶段的耗时情况。
- 从表格数据可以看出,在推理阶段,DyT 使得归一化层的推理时间减少了 52.4%,整体模型的推理时间减少了 7.8%;在训练阶段,归一化层的耗时减少了 42.2%,整体模型的耗时减少了 8.2% 。
- 这充分表明 DyT 在计算效率方面具有明显优势,能够大幅缩短模型在推理和训练过程中的时间消耗,对于实际应用中的实时性和大规模训练场景具有重要意义。
- 性能相当或更优:在不同任务场景下对 DyT 的性能进行了验证。
- 在视觉任务中,ViT - L 模型在 ImageNet 数据集上的准确率提升了 0.5%;扩散模型 DiT - B 的性能指标降低了 1.0% ,这意味着模型性能得到了优化。
- 在语言模型方面,在 LLaMA 7B、13B、34B、70B 等不同规模的模型训练中,损失与使用 RMSNorm 时持平甚至更优。
- 在自监督任务中,MAE ViT - B 和 DINO ViT - B 的性能基本保持不变,说明 DyT 在这些任务中能够稳定地发挥作用,并且在部分任务中还能实现性能的提升。
- 简化架构与训练流程:DyT 具有独特的优势。
- 一方面,它是一种逐 token 操作,不需要进行跨 token 或通道的聚合计算,这大大简化了模型的计算流程,降低了架构的复杂性。
- 另一方面,在大多数任务中,无需对原有的训练参数(例如学习率等 )进行调整,可直接使用,仅在大型语言模型(LLM)场景下需要微调 α \alpha α 的初始化,这使得训练流程更加便捷高效,减少了调参的工作量和复杂性。
小结
DyT 通过引入简单的动态缩放 ( α \alpha α) 和基于 tanh \tanh tanh 的非线性表示,成功替代了传统的归一化层。这种替代方案有效地解决了传统归一化层存在的计算开销大以及架构复杂性高的问题。并且,在多个不同类型的任务中,DyT 都实现了与传统方法相当甚至更优的性能表现。其核心优势主要体现在以下几个方面:
- 高效性:显著减少了计算耗时,在推理和训练过程中都能大幅提升效率,非常适合资源敏感型的应用场景,例如实时性要求高的在线服务或者计算资源有限的边缘设备。
- 普适性:能够广泛覆盖视觉、语言、生成模型等多种不同类型的任务,具有很强的通用性,无需针对不同任务类型进行复杂的调整和适配。
- 理论突破:重新审视和理解了归一化层的本质作用,为无归一化网络的设计提供了新的思路和方向,推动了深度学习领域在网络架构设计方面的理论创新。
DyT 的提出不仅仅是一种工程上的优化,更重要的是它挑战了深度学习中关于归一化层的传统假设,为未来网络架构的创新和发展开辟了新的道路,具有深远的理论和实践意义。
分内容围绕多令牌预测(Multi - Token Prediction, MTP)展开,详细介绍了其原理、优势、DeepSeek 模型中的实现方式等内容,具体如下:
多令牌预测(Multi - Token Prediction, MTP)
MTP简介
- 当前主流预测方式:目前,基于自回归的大型语言模型大多采用单 token 预测的方式。这种方式是根据当前已经生成的上文内容,逐个地预测下一个最有可能出现的 token。例如,当给定上文 “我喜欢” 时,模型会预测下一个最可能的单词,像 “阅读”“运动” 等单个 token。
- MTP 的核心思路:MTP 的核心思想在于打破这种逐个预测的模式,让模型能够一次性预测出多个 token。这样做的目的是为了提升模型在多个方面的性能,包括训练效率、生成文本的质量以及推理速度。例如,当输入上文是 “现在 DeepSeek 的发展” ,传统单 token 预测模式会依次预测 “真的”“好”“火”“。” 等单个 token,而 MTP 则可以并行地一次性预测出这几个 token 。
- 这就要求模型不仅要学会预测下一个 token 的能力,还需要具备同时预测多个(n 个)token 的能力。
MTP 的优势
- 训练过程:在训练过程中,MTP 的训练目标函数不再仅仅关注单个 token 的预测准确性,而是同时考虑多个 token 的估计准确性。通过这种方式,模型能够更好地捕捉 token 之间的依赖关系。比如在句子 “我喜欢在晴朗的天气里进行户外运动” 中,“晴朗的天气” 和 “户外运动” 这些 token 之间存在语义上的关联,MTP 可以让模型学习到这种关联,从而提升模型的整体效果。
- 推理维度:从推理的角度来看,MTP 的优势十分明显。传统的单 token 自回归生成方式,需要一步一步地生成每个 token,每一步都依赖上一步的结果,这在一定程度上限制了推理速度。而 MTP 一次性生成多个 tokens,大大减少了自回归生成的步数。例如,原本需要 10 步生成一个句子,使用 MTP 可能只需要 3 - 4 步就能完成,从而实现了推理加速的效果。
- 缓解短视预测问题:传统的单步预测方式容易导致模型过度关注局部的模式,比如过于注重语法规则,而忽略了整体的语义理解。例如,模型可能会生成语法正确但语义不合理的句子。而 MTP 通过强制模型同时优化多个位置的预测,促使模型建立起全局性的文本理解。模型需要综合考虑多个 token 之间的语义关系,从而避免只关注局部模式,这对于提升模型在实际应用中的性能起到了关键作用,正如在相关技术报告中提到的 “性能超越其他开源模型” ,MTP 在其中发挥了重要作用。
实现细节
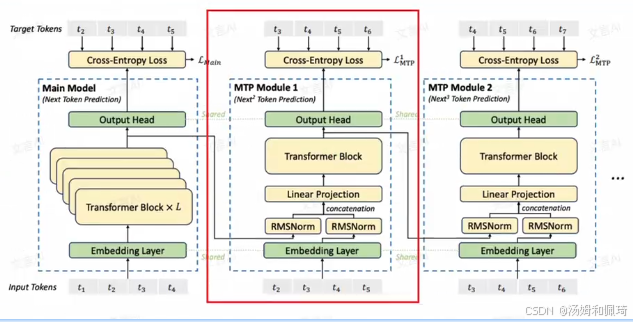
- 整体架构:如图片中的图示所示,DeepSeek 模型使用 D 个顺序排列的模块,来实现对 D 个 tokens 的预测。每个 MTP 模块都具有特定的结构和功能。
- 模块具体结构:
- 输入 token 处理:首先,输入的 token 会先接入一层共享的 embedding layer。这一层的作用是将离散的 token 转换为连续的向量表示,以便后续的模型处理能够更好地捕捉 token 的语义信息。
- 归一化处理:
- 对于第 i 个 token t i t_i ti 和第 k 个预测深度,进行以下操作。
- 首先,将第 k - 1 层的隐层输出 h i k − 1 ∈ R d h^{k - 1}_i \in \mathbb{R}^d hik−1∈Rd 进行归一化处理,采用的是 RMSNorm(Root Mean Square Layer Normalization ),即 R M S N o r m ( h i k − 1 ) RMSNorm(h^{k - 1}_i) RMSNorm(hik−1) 。同时,对第 i + k i + k i+k 位置的 token embedding E m b ( t i + k ) ∈ R d Emb(t_{i + k}) \in \mathbb{R}^d Emb(ti+k)∈Rd 也进行归一化处理,得到 h i k = R M S N o r m ( E m b ( t i + k ) ) h^k_i = RMSNorm(Emb(t_{i + k})) hik=RMSNorm(Emb(ti+k)) 。这一步的归一化处理有助于稳定模型的训练和提高模型的泛化能力。
- 线性变换:将上述两个经过归一化处理的结果进行 concat(拼接)操作后,通过注意力矩阵 M k ∈ R d × 2 d M_k \in \mathbb{R}^{d \times 2d} Mk∈Rd×2d 进行一层线性变换,从而得到新的 h i k ∈ R d h^k_i \in \mathbb{R}^d hik∈Rd 。这里需要注意的是,当 k = 1 k = 1 k=1 时, h i k − 1 h^{k - 1}_i hik−1 对应 main model 的隐层表征。
- Transformer 层处理:将经过线性变换得到的 h i k h^k_i hik 输入到 Transformer 层中,经过 Transformer 层的处理后,获得第 k 个预测深度的输出 h k h^k hk 。Transformer 层通过自注意力机制等操作,能够更好地捕捉输入序列中不同位置之间的关系。
- 输出概率计算:最后将 h k h^k hk 通过一个各个 Module 共享的映射 O u t H e a d ∈ R V × d OutHead \in \mathbb{R}^{V \times d} OutHead∈RV×d 进行变换,再经过 softmax 函数 s o f t m a x ( . ) softmax(.) softmax(.) 进行计算,从而得到词库 V 维度的输出概率。通过这种方式,模型能够预测出每个 token 在词库中出现的概率,进而选择概率最高的 token 作为预测结果。
- 应用效果:DeepSeek V3 的论文中报告了使用 MTP 模块的效果。在推理过程中,模型并不使用 MTP 模块,而是仅在训练过程中利用该模块来约束模型的优化。实验结果表明,通过使用 MTP 模块进行训练,能够有效地提升模型的回复质量。具体体现在,在 MMLU(Massive Multitask Language Understanding )、GSM8K(Grade School Math 8K )等公开基准测试指标上,模型均有显著的提升。这充分证明了 MTP 模块在提高模型性能方面的有效性。
小结
- 核心思想强调:再次强调 MTP 的核心思想是让模型一次性预测多个 token ,通过这种方式来提升模型的训练效率、生成质量和推理速度。
- 能力要求重申:明确指出模型不仅需要具备预测下一个 token 的能力,还需要同时具备预测 n 个 token 的能力,这是 MTP 区别于传统单 token 预测的关键所在。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 25
25 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)