
250万数据炼成SQL翻译官!中国团队OmniSQL九项测试碾压GPT-4o
OmniSQL并非一个单一模型,而是一个专门为Text-to-SQL任务量身打造的开源大语言模型(LLM)家族。它旨在精准地理解用户的自然语言问题,并将其转化为可在数据库上执行的SQL查询代码。OmniSQL-7B: 基于 CodeLlama-7b-hfOmniSQL-14B: 基于 WizardCoder-15B-V1.0 (Mistral-7B 基座)OmniSQL-32B: 基于 DeepS
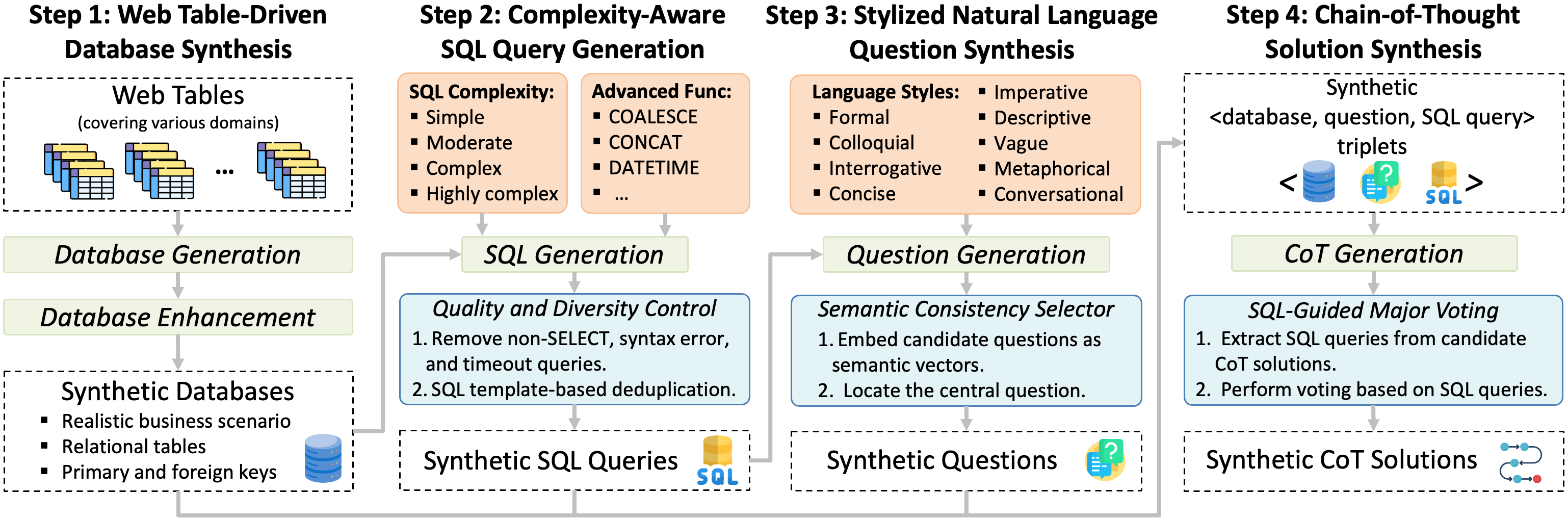
中国人民大学高瓴人工智能学院最新开源的OmniSQL模型家族,正在重新定义自然语言与数据库的交互方式。其核心突破在于全球首个百万级文本转SQL数据集SynSQL-2.5M——覆盖16,583个跨领域数据库,包含250万条高质量样本,涵盖金融、医疗、科研等场景。
关键数据亮眼:
- BIRD金融基准测试准确率86.7%,比GPT-4o快3倍处理复杂嵌套查询
- Spider测试集准确率87.9%,超越原榜单冠军DAIL-SQL + GPT-4组合
- 支持9种自然语言风格,从口语化提问到正式书面表达全适配
AI快站下载
https://aifasthub.com/seeklhy
什么是OmniSQL?重新定义Text-to-SQL
OmniSQL并非一个单一模型,而是一个专门为Text-to-SQL任务量身打造的开源大语言模型(LLM)家族。它旨在精准地理解用户的自然语言问题,并将其转化为可在数据库上执行的SQL查询代码。
为了满足不同场景下的算力需求,OmniSQL提供了三种不同参数规模的模型:
- OmniSQL-7B: 基于 CodeLlama-7b-hf
- OmniSQL-14B: 基于 WizardCoder-15B-V1.0 (Mistral-7B 基座)
- OmniSQL-32B: 基于 DeepSeek-Coder-33B-instruct
这个强大的模型家族由来自中国人民大学(RUC)、字节跳动(ByteDance)、南方科技大学(SUSTech)和滑铁卢大学(University of Waterloo)的研究人员共同开发。他们的目标是创建一个性能领先、易于使用且完全开源的Text-to-SQL解决方案,推动该领域的技术发展和应用落地。
SynSQL-2.5M:炼丹的“秘密武器”
众所周知,高质量、大规模的数据是训练出强大AI模型的基石,对于需要理解复杂数据库结构和多样化自然语言问题的Text-to-SQL任务更是如此。OmniSQL的卓越性能,很大程度上归功于其背后的超大规模、高质量合成Text-to-SQL数据集——SynSQL-2.5M。
SynSQL-2.5M数据集包含:
- 250万 个高质量的自然语言问题, SQL查询对。
- 覆盖超过 16,000 个不同的数据库模式。
这个数据集的规模、质量和多样性,为OmniSQL模型提供了前所未有的学习资源,使其能够更好地泛化到各种未见过的数据库和问题类型。更令人兴奋的是,SynSQL-2.5M数据集也已完全开源,为整个研究社区提供了宝贵的资源。

性能“屠榜”:九项测试超越GPT-4o
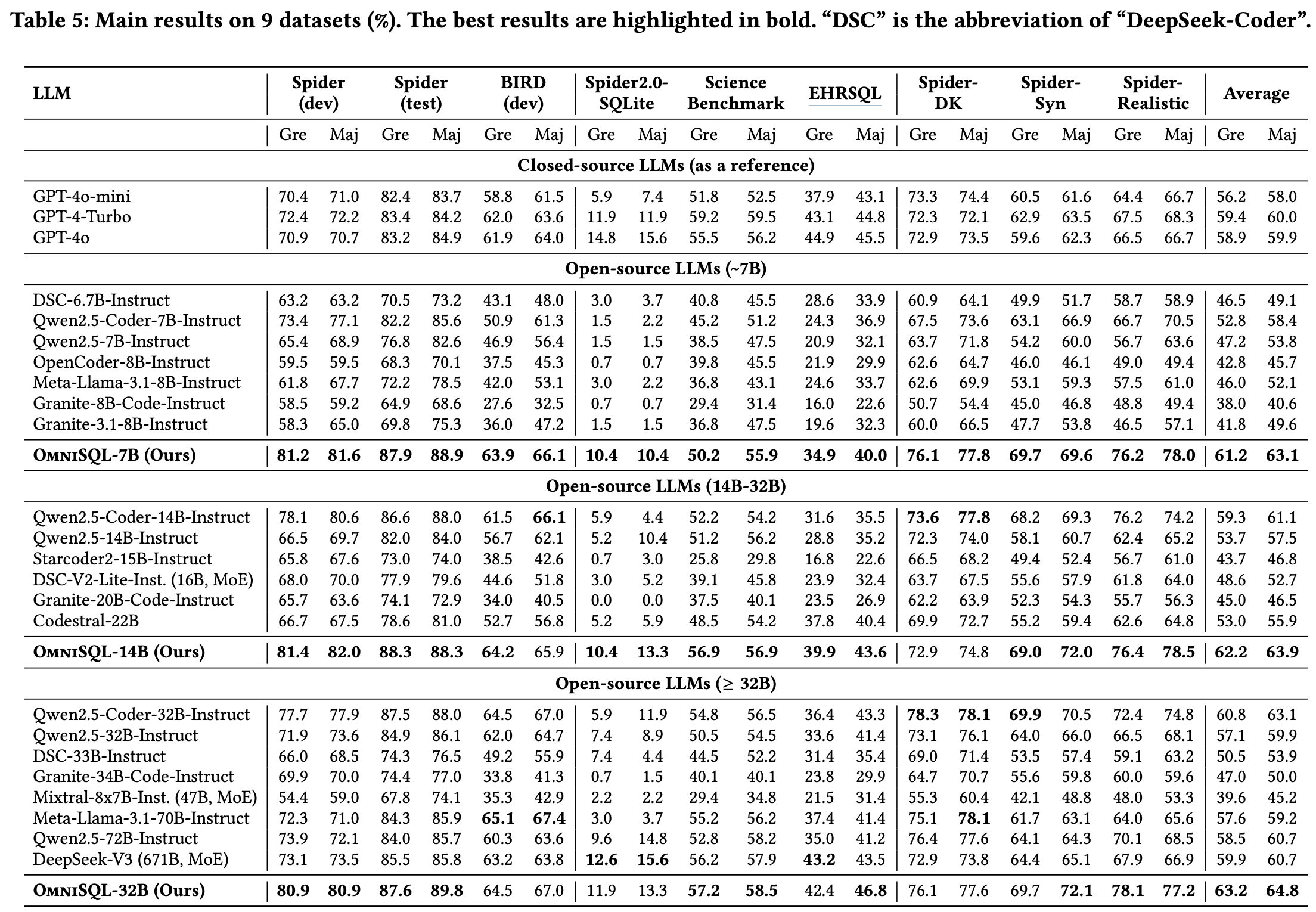
OmniSQL最引人注目的,无疑是其惊人的性能表现。研究团队在多达九个权威的Text-to-SQL基准测试上对OmniSQL进行了全面评估,包括但不限于Spider, Spider-Realistic, Spider-DK, BIRD, KaggleDBQA, EHR-SQL, DBSPOKES, CoSQL, SParC等。
结果显示,OmniSQL家族在这些测试中均取得了顶尖的成绩,尤其是在最具挑战性的跨领域Text-to-SQL基准测试 Spider 和大规模跨数据库基准测试 BIRD 上:
- 在 Spider 开发集 上,OmniSQL-7B 使用贪婪解码(greedy decoding)就达到了 87.9% 的执行准确率(EX),超越了包括 GPT-4o (86.9%) 和 DeepSeek-Coder-V2 (85.6%) 在内的众多强劲对手。
- 在 BIRD 开发集 上,OmniSQL-32B 的执行准确率(EX)达到了 63.1%,同样优于 GPT-4o (61.5%) 和 Claude 3 Opus (55.7%)。
这些硬核数据充分证明了OmniSQL在理解自然语言和生成复杂SQL查询方面的强大能力。能够在如此多的基准上取得领先,尤其是与GPT-4o这样的通用大模型相比,展现了其在Text-to-SQL这一垂直领域的深度优化和技术实力。
技术亮点与架构
OmniSQL的成功并非偶然,其背后融合了多项技术创新:
- 1. 高质量数据合成流水线: 开发团队设计了一套精密的流水线来生成SynSQL-2.5M数据集,确保了数据的规模、多样性和与真实世界场景的相关性。
- 2. 基于强大基础模型: 选择了性能优异的开源代码/通用大模型(如CodeLlama, Mistral, DeepSeek-Coder)作为基座,并进行针对性的指令微调。
- 3. 领域特定优化: 训练过程中特别关注了数据库模式(Schema)的理解、复杂查询逻辑(如嵌套、连接、聚合)的生成以及SQL方言的适应性。
应用前景与价值
OmniSQL的出现,为以下应用场景打开了新的可能性:
- 1. 智能数据分析工具: 让业务人员、数据分析师能够用自然语言与数据库交互,快速获取洞察,降低数据分析门槛。
- 2. 自然语言数据库接口: 为各类应用程序(如CRM、ERP、报表系统)提供强大的自然语言查询前端。
- 3. SQL学习与辅助工具: 帮助初学者理解SQL,或辅助开发者快速生成复杂查询。
- 4. 数据库管理与运维: 简化数据库信息检索等日常操作。
作为一个高性能的开源项目,OmniSQL不仅为企业和开发者提供了即插即用的强大工具,也为学术界在Text-to-SQL领域的研究提供了坚实的基础和宝贵的数据资源。
总结
OmniSQL凭借其基于海量合成数据训练出的卓越性能、全面的基准测试优势(包括对GPT-4o的超越)以及彻底的开源精神,无疑成为了Text-to-SQL领域一颗闪亮的“新星”。它展示了在特定领域通过精心设计的数据和模型优化,开源模型完全有能力达到甚至超越顶级闭源模型的水平。
AI快站下载
https://aifasthub.com/seeklhy

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 31
31 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)