基于大模型的 RAG 核心开发——详细介绍 DeepSeek R1 本地化部署流程
前言自从 DeepSeek 发布后,对 AI 行业产生了巨大的影响,以 OpenAI、Google 为首的国际科技集团为之震惊,它的出现标志着全球AI竞争进入新阶段。从以往单纯的技术比拼转向效率、生态与战略的综合较量。其影响已超越企业层面,涉及地缘政治、产业政策与全球技术治理,它彻底改变“美国主导创新、中国跟随应用”的传统格局,形成多极化的技术权力分布。DeepSeek 的开源性彻底打破了 Ope
前言
自从 DeepSeek 发布后,对 AI 行业产生了巨大的影响,以 OpenAI、Google 为首的国际科技集团为之震惊,它的出现标志着全球AI竞争进入新阶段。从以往单纯的技术比拼转向效率、生态与战略的综合较量。其影响已超越企业层面,涉及地缘政治、产业政策与全球技术治理,它彻底改变“美国主导创新、中国跟随应用”的传统格局,形成多极化的技术权力分布。
DeepSeek 的开源性彻底打破了 OpenAI 等公司通过 API 接口调用,依赖 token 计费的单一规则。因为 DeepSeek 是一个开源的产品,任何人都可通过 GitHub 等途径下载它的核心源代码,这种开源方案有点类似当年的 Android / 鸿蒙发展策略。任何人都可以为 DeepSeek 开发某项额外的功能,为DeepSeek 的茁壮成长贡献自己的一份力量。
它包括了 DeepSeek R1 / DeepSeek V3 / DeepSeek Coder V2 / DeepSeek VL / DeepSeek V2 / DeepSeek Coder / DeepSeek Math / DeepSeek LLM 等多个不同的模型,以适应不同领域的应用。私人开发者可以下载 DeepSeek R1 检心框架进行调试,如果企业调用 DeepSeek 的 API 接口,也需要按 token 收费,然而费用不到 ChatGDP 的十分之一,对企业来说是相当有良心。DeepSeek 的 R1 模型支持本地化部署,用户可以在企业服务器内单独部署自己的 DeepSeek 模型,以适应各自的领域需求。
废话不多说,下面为大家介绍 DeepSeek R1 的本地化部署流程。
一、运行环境要求
1. 硬件配置
- 独立显卡(推荐 NVIDIA 1060 以上 GPU显存 ≥ 6GB)
- CPU、内存及存储需满足模型参数规模(如1.5B/7B/14B模型对应不同配置)
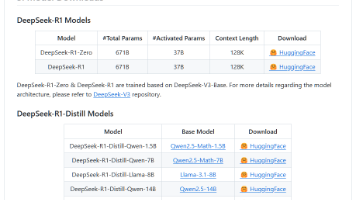
进入 DeepSeek 的官网 DeepSeek | 深度求索,点激 DeepSeek R1 的模型连接,可以进入 GitHub 的源代码页面。里面可看到 DeepSeek R1 包含了多个不同大小的模型,每个模型需要使用的资源不一样。一般情况下建议使用 1.5B 的轻量级模型,GPU 在 6G~8G 可以尝试使用 7B 的平衡型模型。
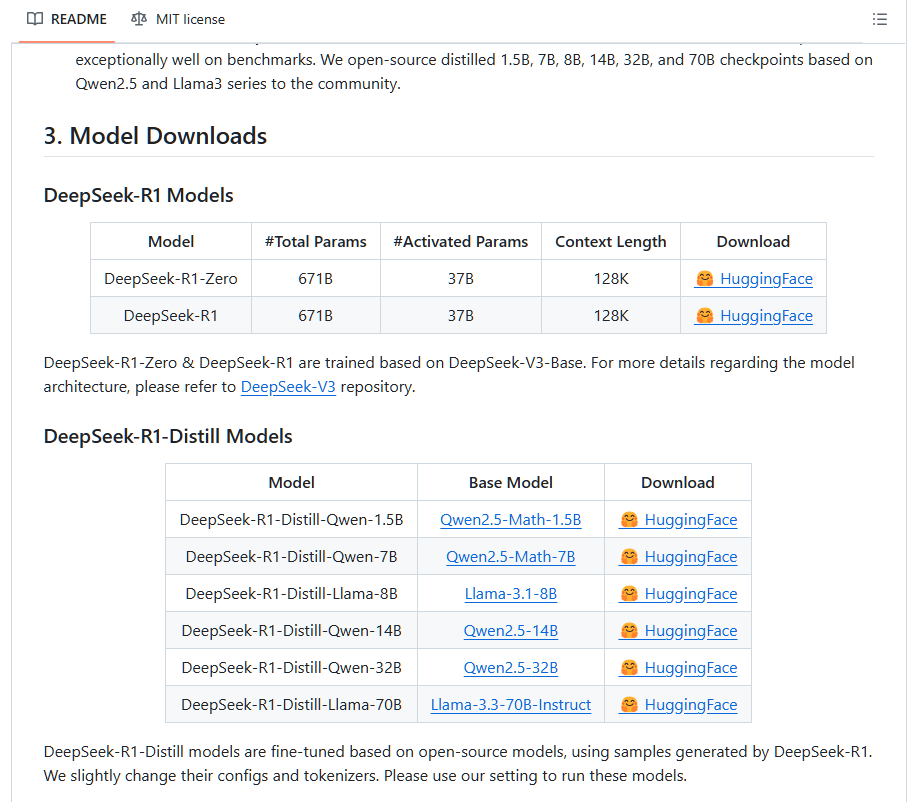
显卡要求可参考下表
2. 依赖工具
- Ollama 或 HFD 部署工具及模型库
- Docker、Python等基础环境
常用下载模型的方法主要有两种,一是通过 Ollama,二是通过 HuggingFace。虽然 HuggingFace 的镜像比较丰富全面,但由于在2023年底,HuggingFace 的官网已经彻底被封,想要下载镜像需要使用 https://hf-mirror.com 里面的 HFD 工具通过命令执行,对新手来说相对不太友好,所以本文就选择相对轻量级的 Ollama 工具进行安装。
二、安装步骤
1. 安装 Ollama
首先到 Ollama 官网 https://www.ollama.com 下载 ollama,可以选择 Windows、Linux、masOS 三个不同的版本
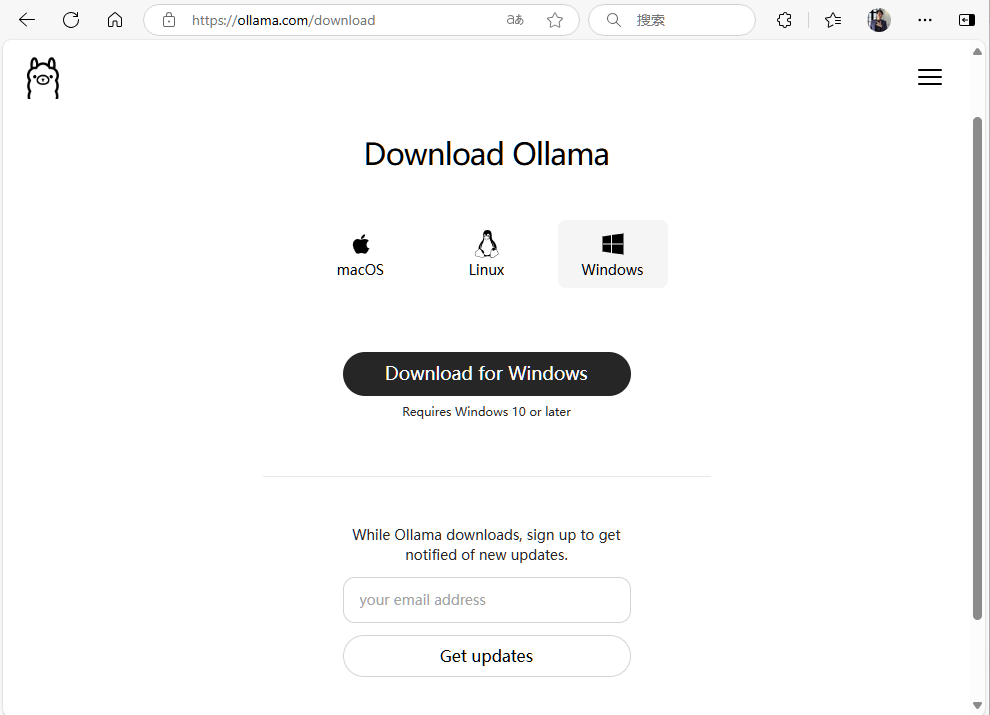
下载后点激安装,默认安装路径在 C:\Users\username\AppData\Local\Programs\Ollama 下
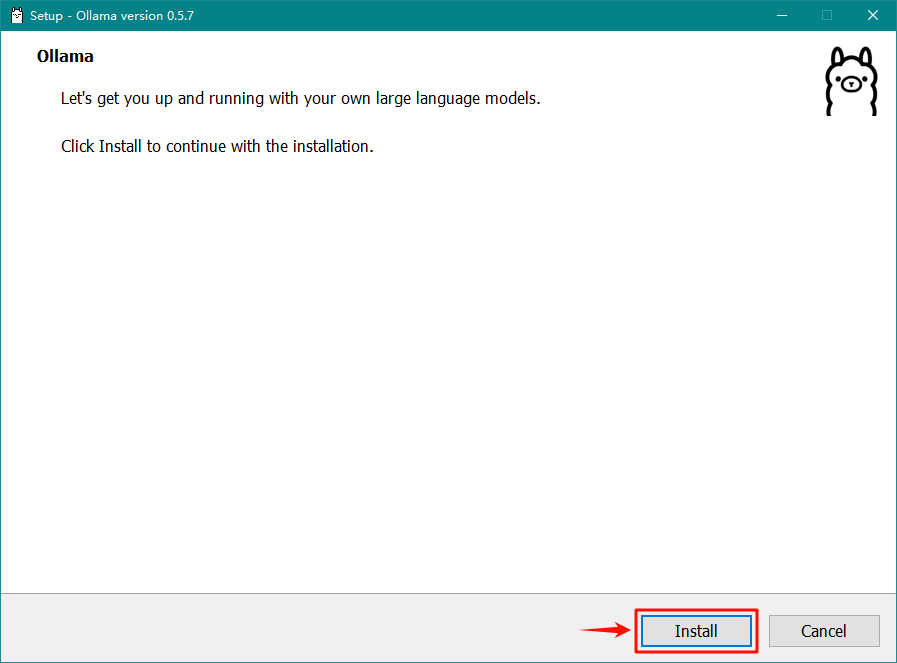
安装完成后,打开 Windows 的环境变量,修改用户变量中的 Path 值,加入 Ollama 的路径 C:\Users\username\AppData\Local\Programs\Ollama
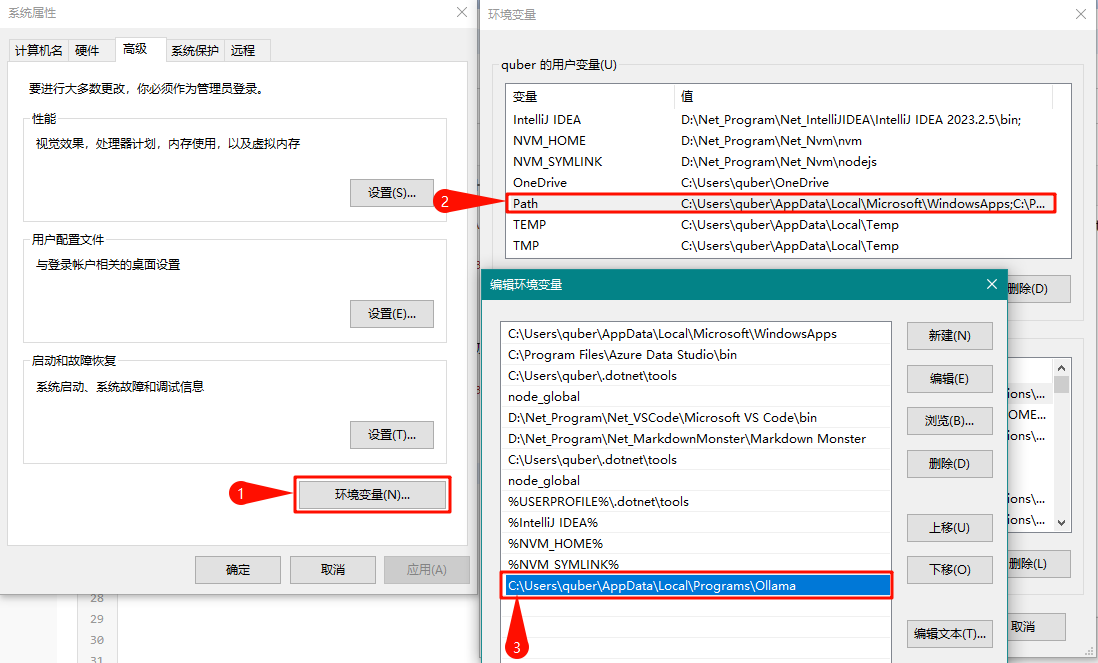
完成设置后,点激 Ollama.exe 按钮,然后在命令提示符中输入 ollama -v,见到 ollama 版本号代表安装成功。
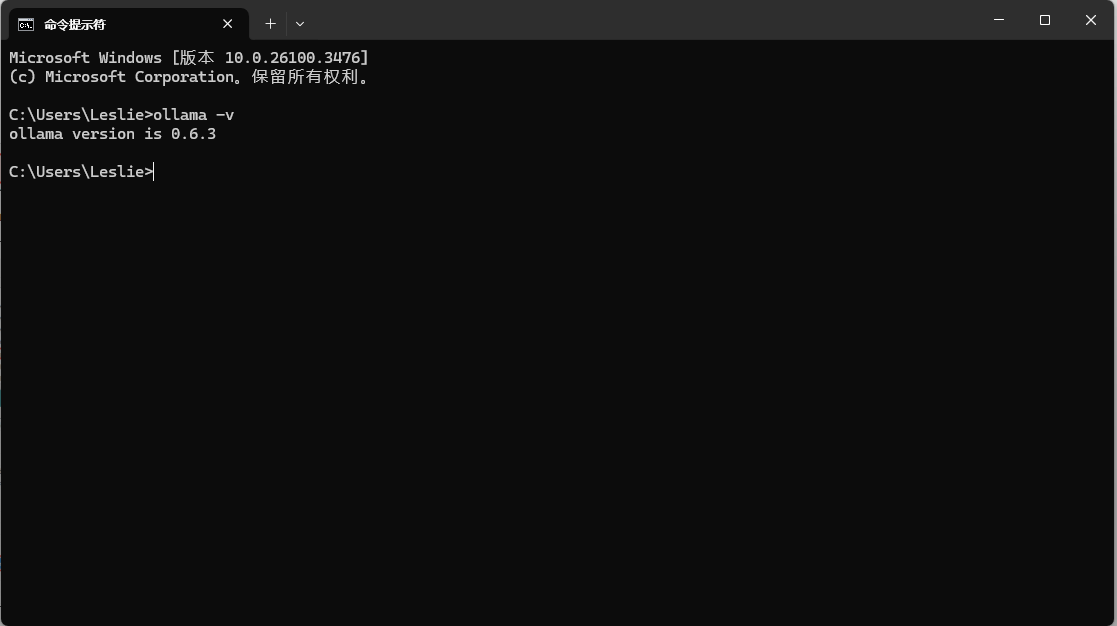
也打开浏览器,输入Ollama 运行地址 “http://127.0.0.1:11434”
看到 “Ollama is running” 字样证明 Ollama 已经正常运行。
2. 下载 deepseek v1 模型
ollama 的命令与 docker 有点类似,输入命令 ollama pull deepseek-r1:7b 系统开始下载模型 deepseek v1:7b
最后看到 success 代表下载成功
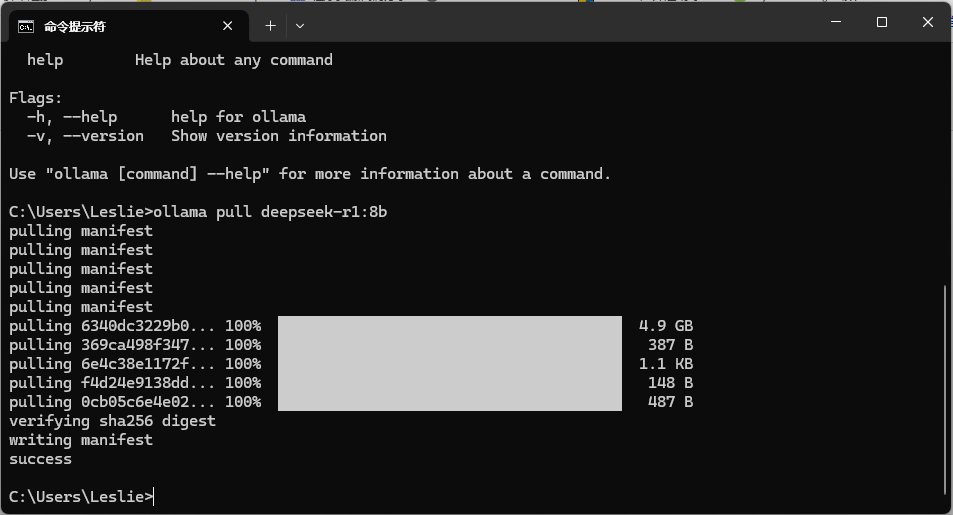
此时输入命令 ollama ls 可以查看已下载的模型
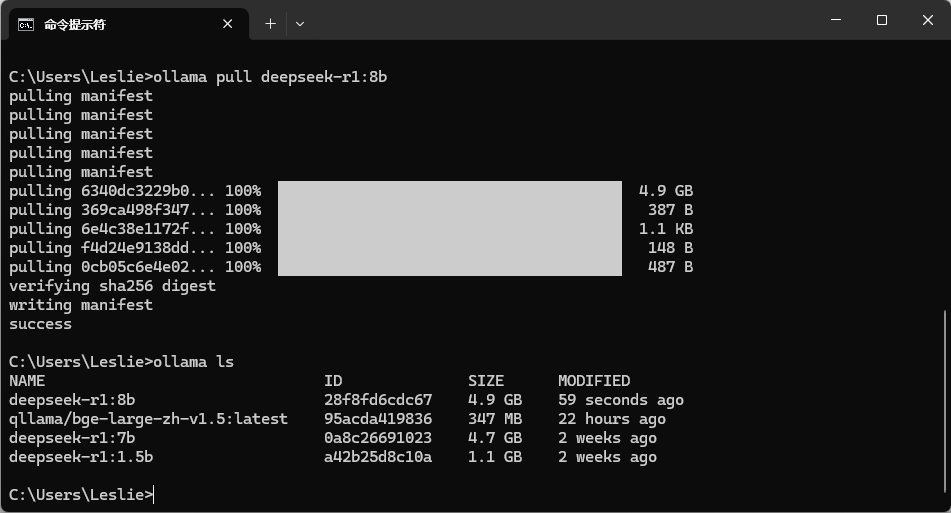
3. 运行模型
输入命令 “ollama run deepseek-r1:7b” 启动模型
成功启动后就可以尝试输入问题让 deepseek 回答。
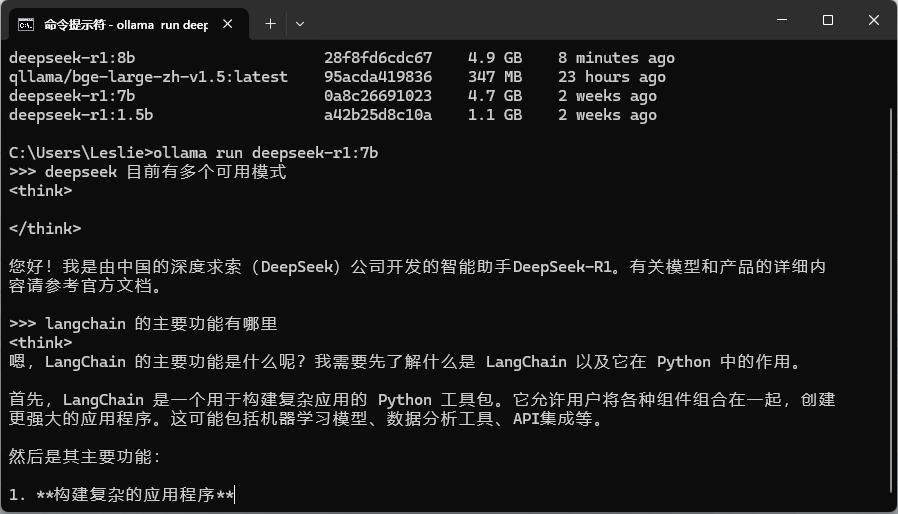
按下 CTRL+D 可以退出当前对话
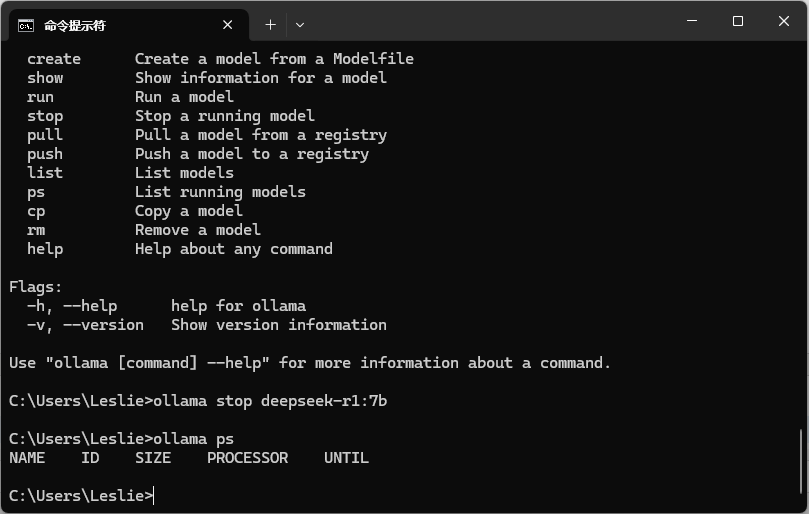
若要查看当前运行的模型,可以输入 ollama ps
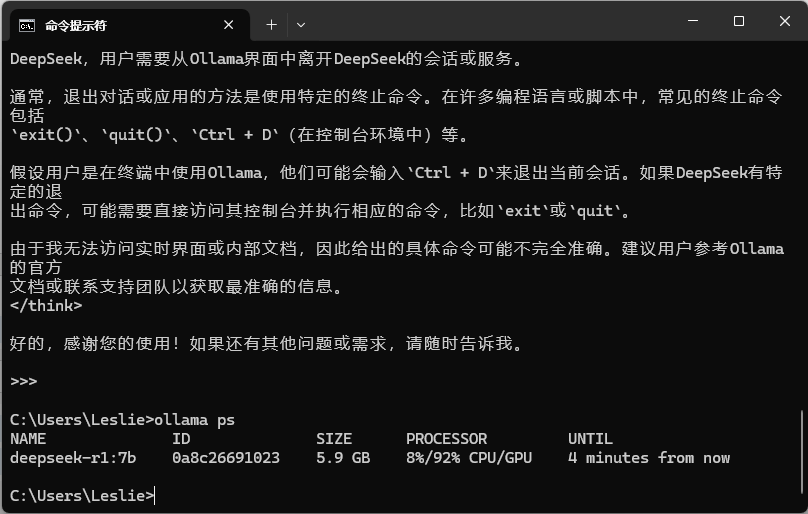
若要停止模式运行,可输入 ollama stop deepseek-r1:7b。
停止后再输入 ollama ps,可以知道停止命令是否成功
三、可视化部署
DeepSeek R1 不仅可以通过命令执行,还可通过插件进行可视化部署,布置出与官网应用类似的应用场景。
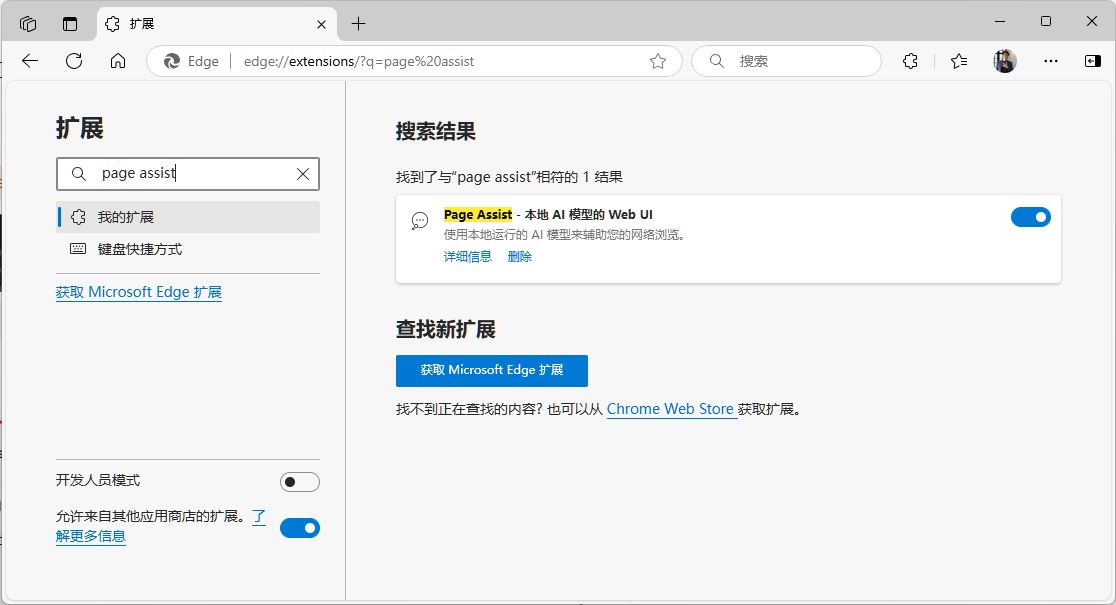
首先选择浏览器的扩展按键,填入 Page Assist 进行搜索,安装插件。
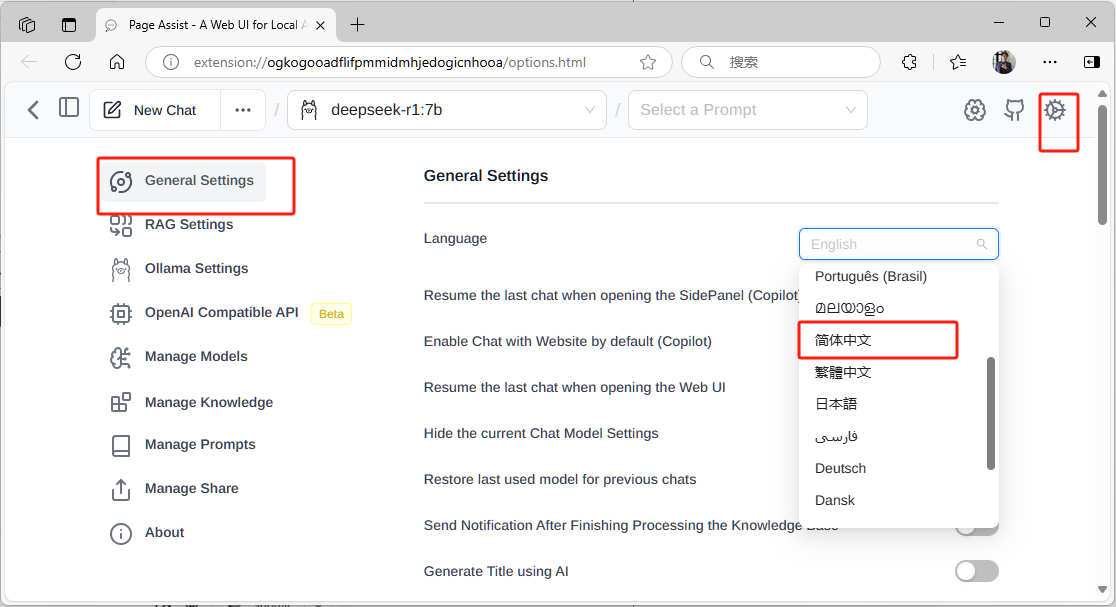
完成安装后,若要选择中文版可点激右上角设置按钮,在language中选择 “简体中文”
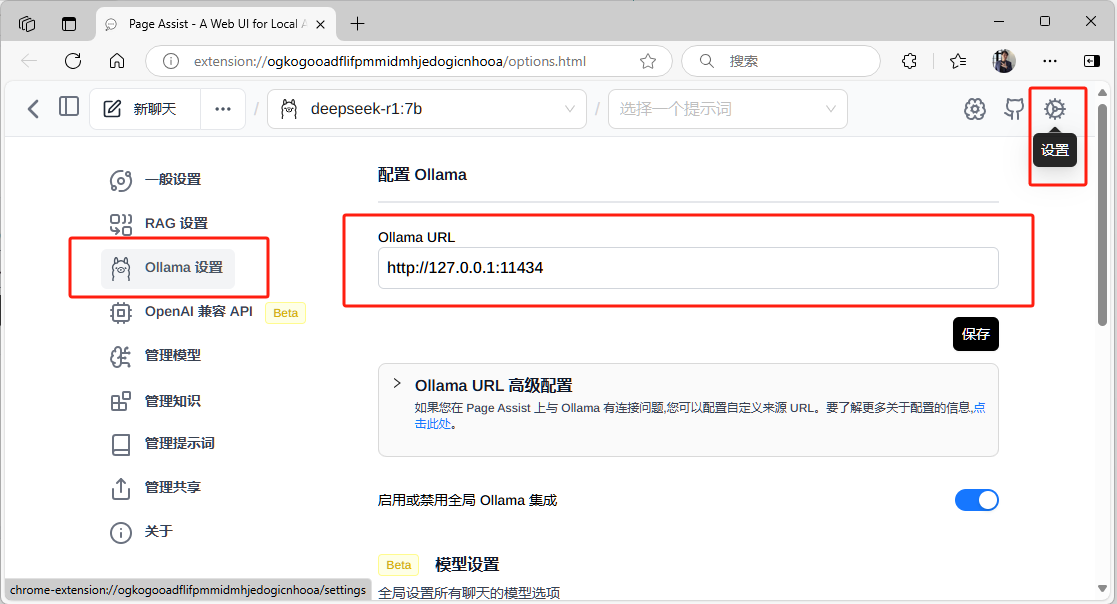
在命令提示符输入 ollama run deepseek-r1:7b ,确定 deepseek 模型已经正常运行后, 在 Ollama URL 处填入默认的运行地址 http://127.0.0.1:11434
回到首页,在选项中可以查到系统中正在运行的模型,选择你要有的模型类别
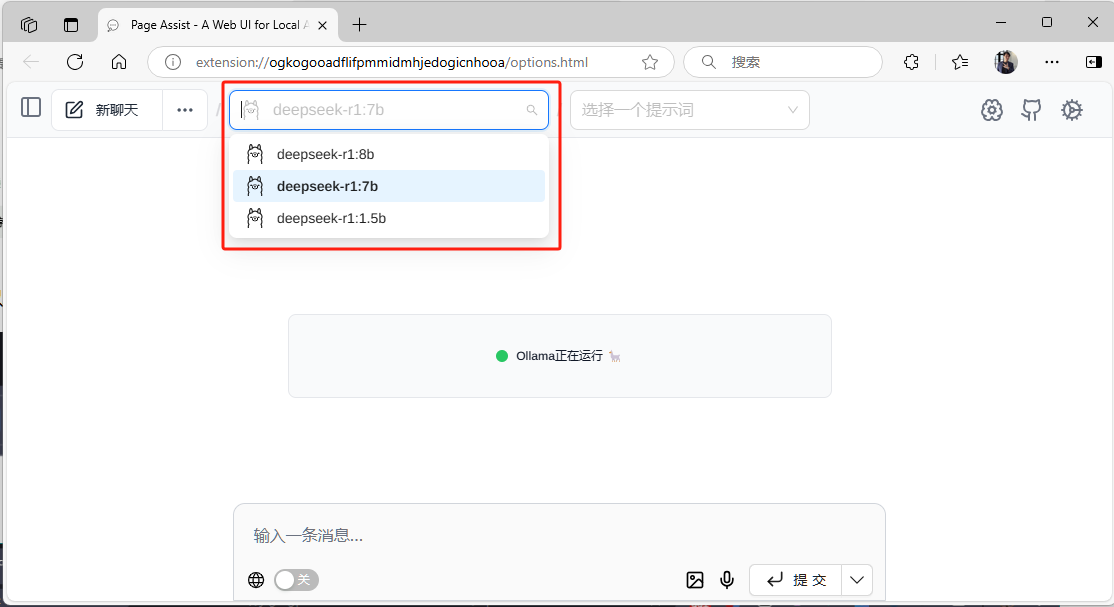
此时,你已经可以在本机尽情享受 DeepSeek 给你带来的乐趣。
本章小结
前面已经介绍了 DeepSeek R1 本地化部署流程,本地化部署不仅能保障数据安全,更能通过灵活定制实现业务场景的高效适配,为企业智能化转型提供可靠的技术底座。DeepSeek 模型从环境准备、模型加载到 RAG 功能集成,每一个环节都体现了大模型与企业私有化场景深度融合的技术潜力。接下来一连几章将会为大家介绍基于大模型 RAG 的核心开发,敬请留意。
如何学习大模型?
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!
这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

😝有需要的小伙伴,可以扫描下方二v码免费领取【保证100%免费】🆓

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 19
19 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)