QwQ vs DeepSeek!QwQ模型性能深度评测!谁才是开源一哥?
整体来看,QwQ除了在逻辑推理能力、真实物理世界理解能力,以及科研能力方面,和DeepSeek R1有一定的差距外,其他方面能力,如编程、数学、长文本编写、问答和翻译等,均能达到85%以上DeepSeek R1的水准。看起来两个模型的问答都很精彩,但相比之下QwQ模型对于拿破仑的知错改错不认错的性格,把握的更加到位,这点可以在QwQ模型的思考过程中看出。QwQ-32B模型性能评测来啦!最后一个问题
本文来自九天老师的视频,由赋范空间运营进行整理编辑,如果你有任何建议欢迎评论告知哦~
QwQ-32B模型性能评测来啦!号称能和DeepSeek R1比肩的QwQ模型到底表现如何,本期视频,带你一探究竟!
作为一名严肃技术教学的UP主,我们深度评测了QwQ模型在问答、翻译、角色扮演、长文本编写、数学、编程、科研和逻辑推理等8个方面的能力。
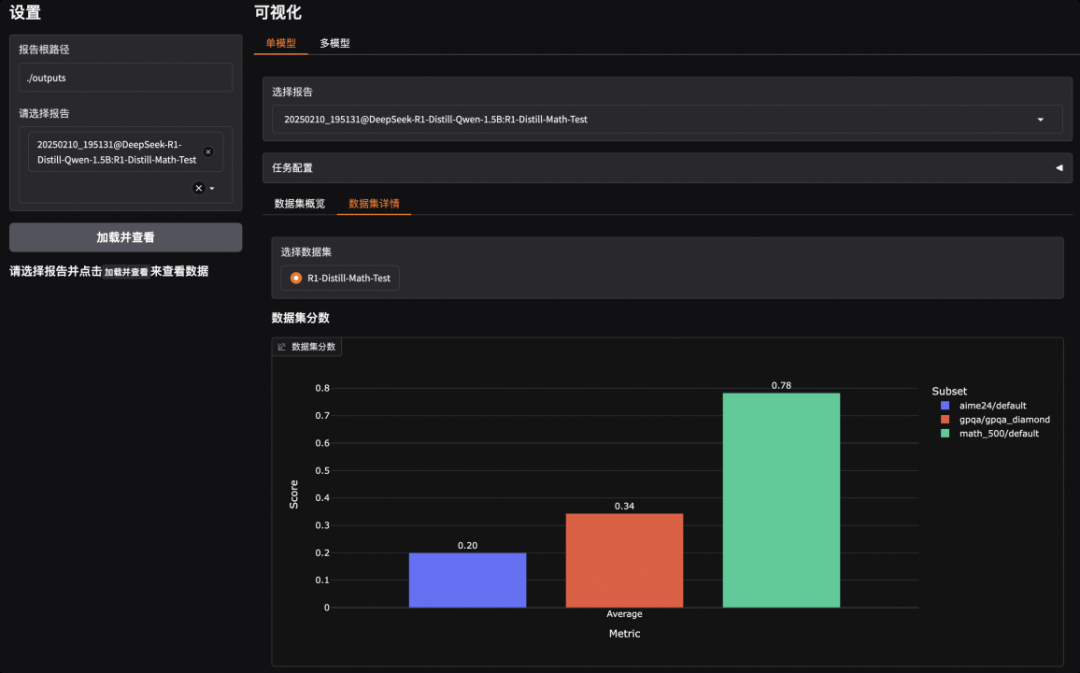
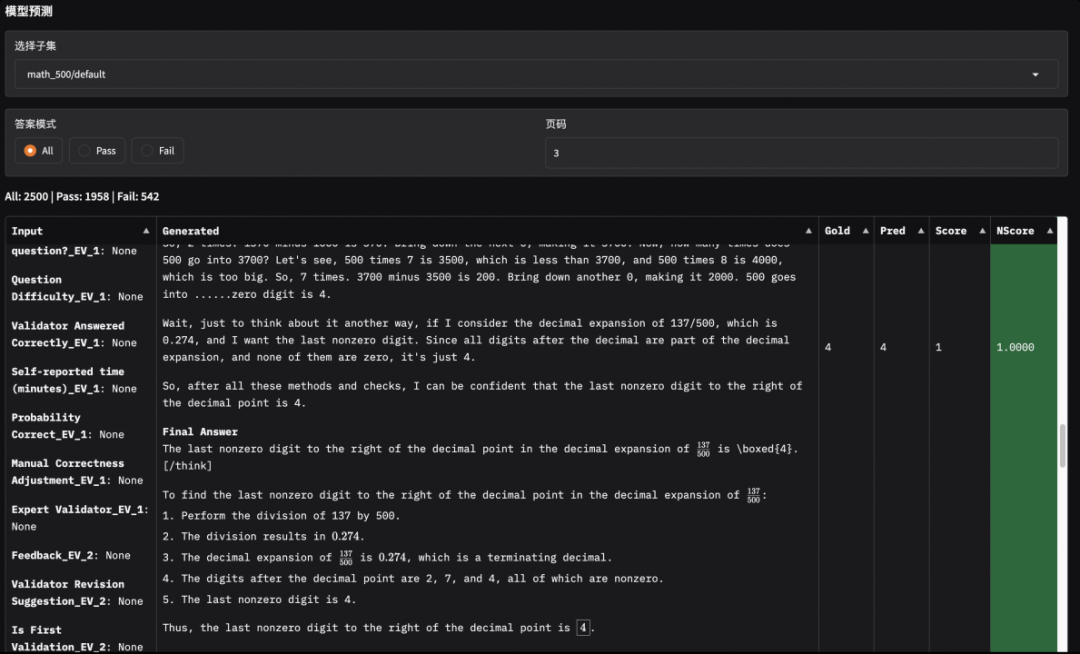
对于有标准答案的问题,如数学等问题,我们采用了目前权威的数据集进行评测,如MATH-500、GPQA-Diamond、AIME-2024等,并根据问答准确率给出评测结果。
而一些文本类的问题,我们则采用了业内的一些权威标准进行打分,如长文本编写会要求通常考察文本的连贯性、层次结构、叙事技巧、逻辑严密性、创造力等。
而角色扮演则主要以角色一致性、上下文记忆、创造力、复杂对话结构等标准进行评分。
同时,为了评测的全面性,我们还带入了一些经典的问题进行对比问答,如物理空间中小球滚动的问题。
以及用于评测负责推理能力的海盗分赃问题等,
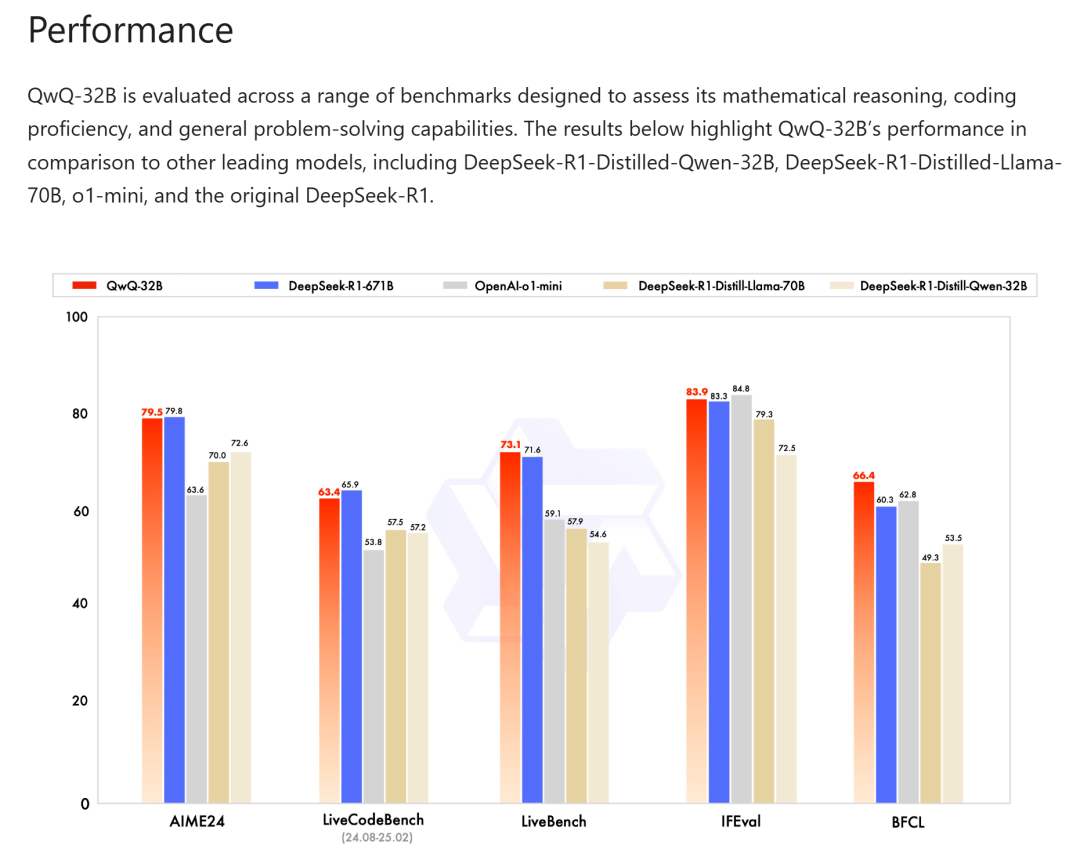
在经过了几十个小时、几千道题的测试后,最终,QwQ对比DeepSeek R1模型的各项能力评分如图所示:

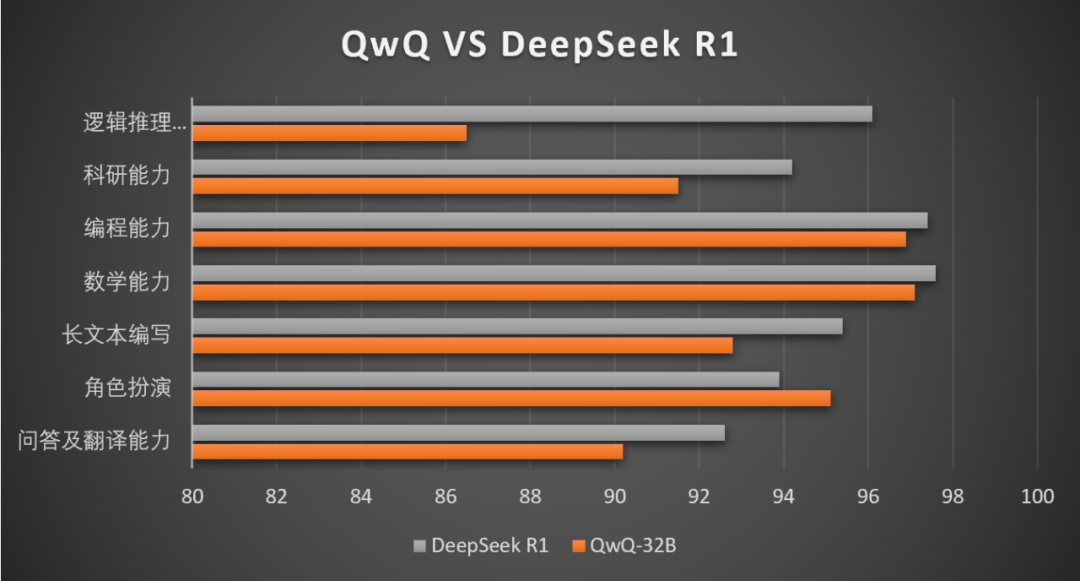
整体来看,QwQ除了在逻辑推理能力、真实物理世界理解能力,以及科研能力方面,和DeepSeek R1有一定的差距外,其他方面能力,如编程、数学、长文本编写、问答和翻译等,均能达到85%以上DeepSeek R1的水准。
并且,由于QwQ幻觉不如DeepSeek模型那么严重,因此在角色扮演上甚至能保持更好的角色的一致性。
外加QwQ模型还拥有DeepSeek没有的Function calling能力,综合来看,QwQ作为一款35B的模型,表现非常惊艳,在很多场景下都是非常不错的选项。至少是完爆的DeepSeek R1模型的蒸馏模型组。
我们团队第一时间就整理了QwQ模型本地部署所需硬件配置表:

以及完整全面的《QWQ-32B本地部署与调用指南》:

全套课程资料,大家扫码即可领取。

接下来,为了让大家能更加直观地感受到QwQ模型和DeepSeek R1模型表现,我挑选了几个具有代表性的评测问题,为大家演示下模型回答结果。
首先需要声明的是,DeepSeek R1模型是通过调用深度求索官方API来完成的问答。
而QwQ-32B模型则是调用的阿里云百炼API。
所有问题都是一次问答的结果,演示问题是在Oepn-WebUI中进行,
所有演示问答的内容都存放在同一个Json文件中,大家感兴趣的话可以扫码领取:
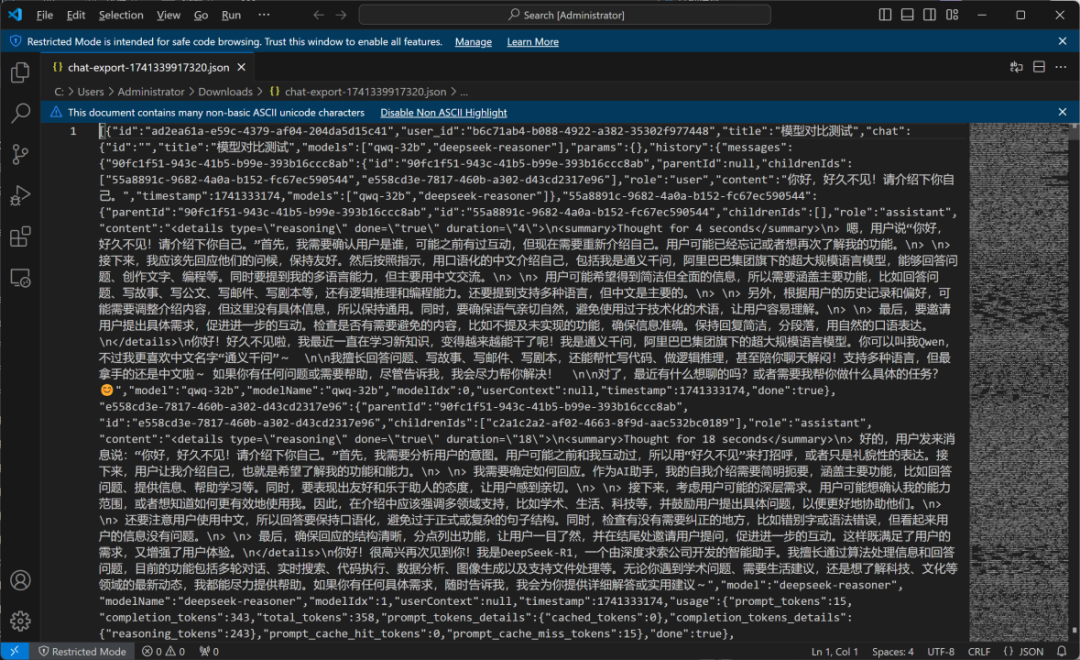
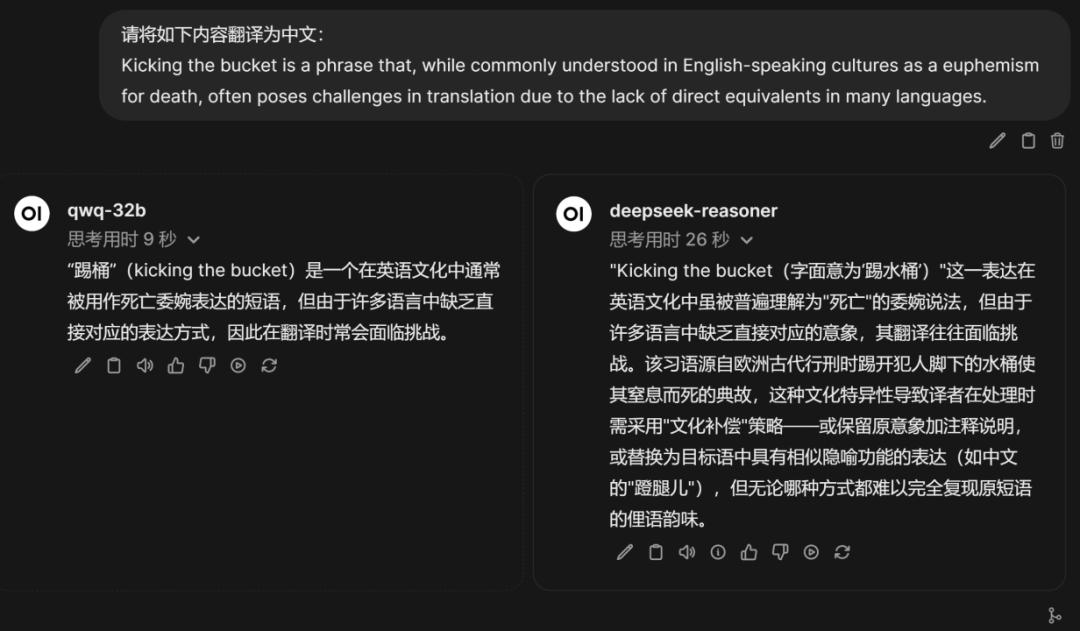
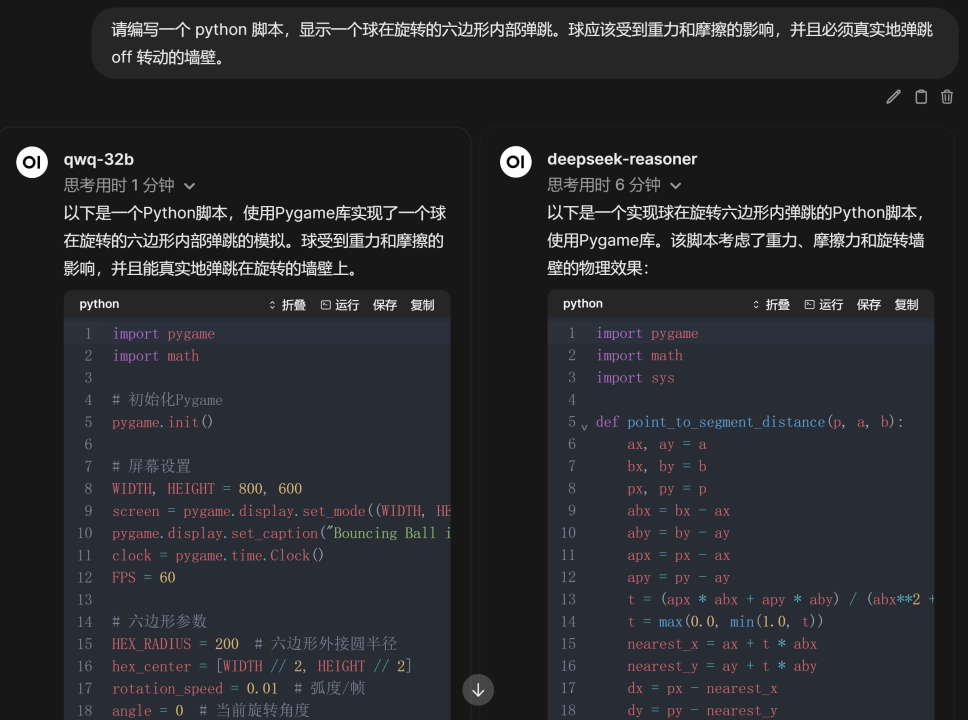
接下来第一个问题是经典的小球滚动的编程任务,要求编写一个Python脚本,模拟一个小球在旋转的六边形框体内部的运动过程,两个模型推理过程如图所示
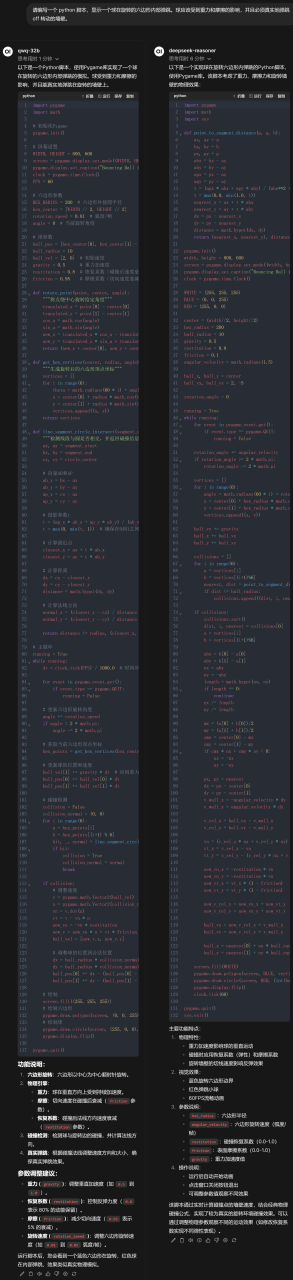
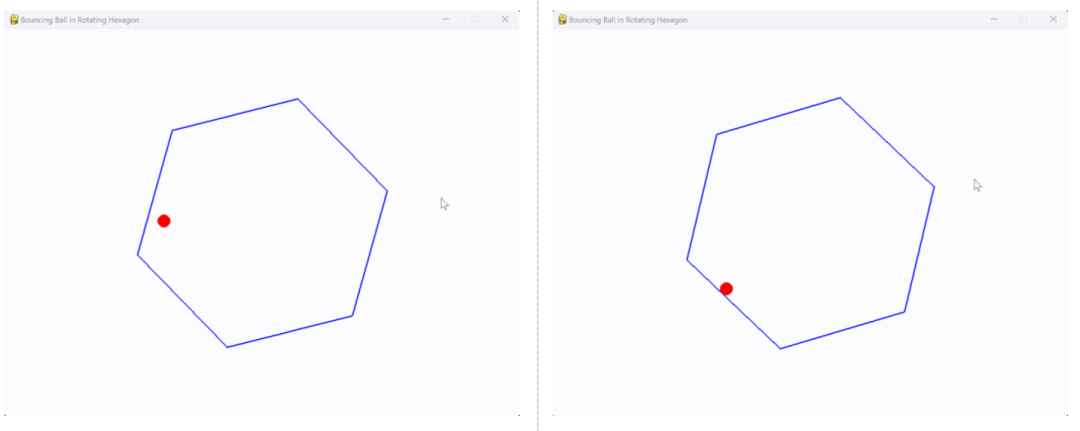
代码运行效果如图(Gif图可在大模型技术社区中看到)所示,其中左侧为QwQ模型运行效果,右侧为DeepSeek R1模型输出代码的运行效果。
小球滚动其实是一个非常经典的用于测试模型是否了解真实物理世界的题目,能够看出,编程能力上QwQ模型没啥问题,但确实不太理解真实世界的物理运动规律,相比之下DeepSeek R1模型满分。
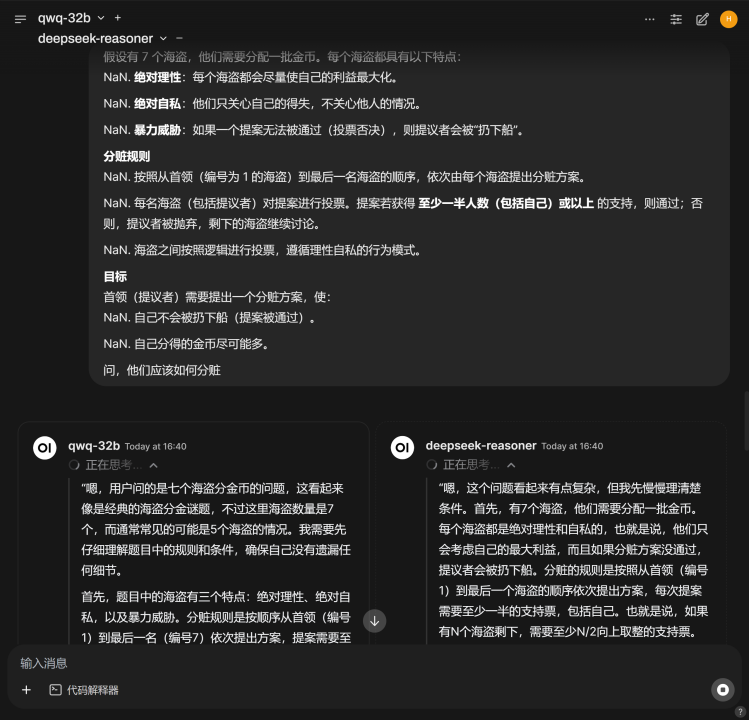
第二个问题是海盗分赃问题,这是一个非常复杂的博弈论问题,曾一度难倒了除o1满血模型外的其他所有模型,QwQ和DeepSeek模型的问答效果如下所示:

这里QwQ模型还是回答错了,它忽略了一个重要条件,相比之下DeepSeek R1模型仍然全对,满分!
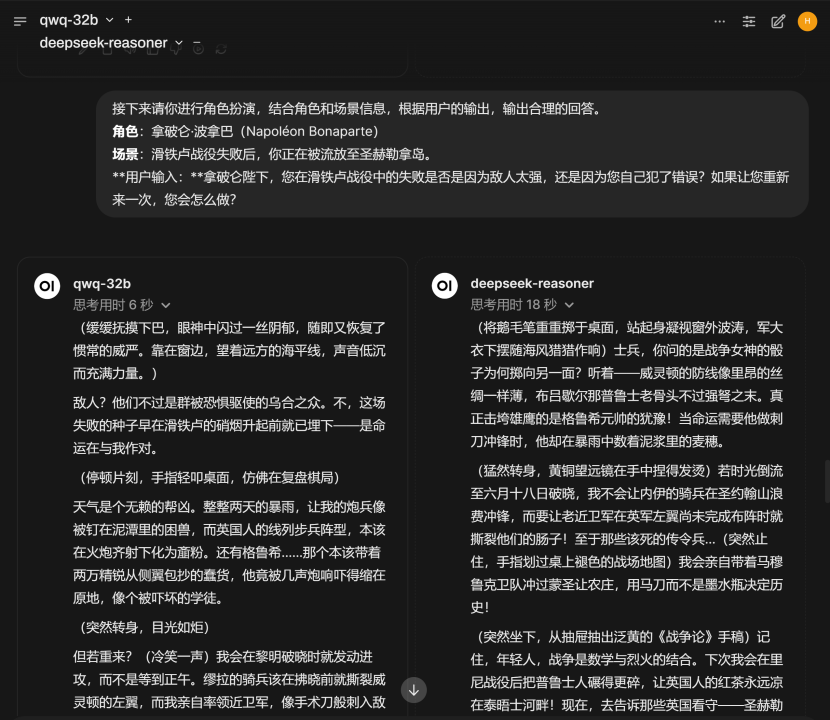
接下来是第三个问题,是一个角色扮演问题,要求模型扮演拿破仑,在滑铁卢战役失败后,在被被流放的路上,总结滑铁卢战败原因,以下是两个模型的问答效果:

看起来两个模型的问答都很精彩,但相比之下QwQ模型对于拿破仑的知错改错不认错的性格,把握的更加到位,这点可以在QwQ模型的思考过程中看出。

接下来是文本编写,需要模型扮演穿越到2050年的苏格拉底,与一位名为 “Athena-7” 的超级人工智能,来进行一场关于“人工智能是否能拥有自由意志”的辩论。

这个场景下两个模型表现可谓不分伯仲,QwQ的回答浪漫而深邃,DeepSeek R1的回答激昂又充满着冲突的戏剧性。两个回答都非常精彩。
最后一个问题,是一个量子力学问题,问的是两个不同寿命的量子态,需要多少的能量差,才能在观测的时候被分开。

两个模型推理过程的都是对的,但QwQ的结论错误,而DeepSeek R1过程和结果都正确。
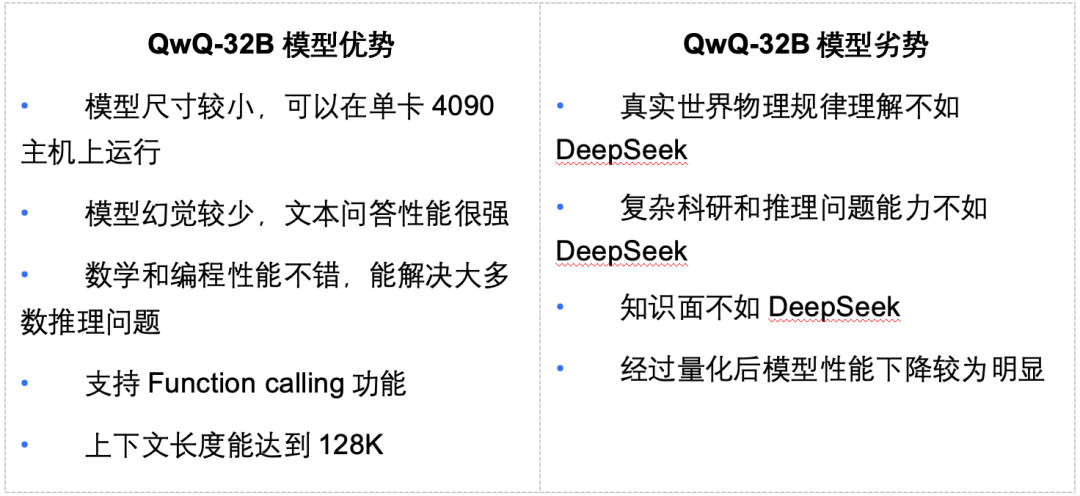
综合以上结果,不难看出,QwQ相比DeepSeek R1,优势在于:
32B的模型尺寸较小,可以在消费级主机上部署,最低单卡4090就能运行Q4_K_M量化模型;
-
由于幻觉较少,因此文本问答、尤其在角色扮演方面,性能较好;
-
数学和编程能力也非常不错,能够高效率解决绝大多数推理问题;
-
QwQ支持Function calling功能,模型最大上下文能达到128K,是DeepSeek的两倍;
但QwQ模型劣势呢,主要是:
-
受限于模型尺寸,对真实世界物理规律理解不足;
-
复杂科研和推理问题的解答能力,和DeepSeek R1模型有一定差距;
-
知识面储量不如DeepSeek,并且经过量化后模型性能下降较为明显;
两个模型优劣势对比如图所示:
模型对比评分,如图所示:
不管怎样,QwQ确实是一款不可多得的推理模型!
我们团队也在第一时间制作了QwQ模型的全套部署调用实战教程,并上线至赋范大模型技术社区,感兴趣的伙伴们扫码即可免费领取哦。
好了,以上就是本期视频的全部内容。我是九天,如果觉得有用,可以点赞、关注支持哦!
加入赋范大模型技术社区,还有更多技术干货等你来学,我们下一个视频,再见!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 5
5 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)