
DeepSeek + Ollama 部署自己本地的 AI 大模型(Windows,AMD 显卡也能用)
随着 DeepSeek 在春节期间的爆火,DeepSeek 的 app 在登上了应用下载的 Top1 宝座,但是实际使用时却发现经常出现“服务器繁忙,请稍后再试。”的提示,导致用户体验非常差,而且也没办法做一些自定义的开发,如果你家里刚好有一台电脑,也刚好有张显卡(Mac 电脑用的是统一内存,所以不一定需要显卡,如果有显卡坞那肯定是锦上添花),那就跟着我来一起本地部署一下吧,本文将以 Window
DeepSeek + Ollama 部署自己本地的 AI 大模型(Windows,AMD 显卡也能用)
简介
随着 DeepSeek 在春节期间的爆火,DeepSeek 的 app 在登上了应用下载的 Top1 宝座,但是实际使用时却发现经常出现“服务器繁忙,请稍后再试。”的提示,导致用户体验非常差,而且也没办法做一些自定义的开发,如果你家里刚好有一台电脑,也刚好有张显卡(Mac 电脑用的是统一内存,所以不一定需要显卡,如果有显卡坞那肯定是锦上添花),那就跟着我来一起本地部署一下吧,本文将以 Windows11 系统来安装。
Ollama 的介绍
一、什么是 Ollama?
Ollama 是一款基于 Go 语言构建的开源工具,它致力于简化和优化机器学习模型的使用。它的目标是让开发者和数据科学家能够更轻松地使用和部署大型语言模型(LLM),并提供了一系列工具和框架,以支持模型的加载、管理和运行。
二、功能特点
- 操作简便:Ollama 提供了一个简单的命令行界面,采用类似 Docker 的操作方式,有 list、pull、push、run 等命令,用户通过简单的命令即可完成从模型下载到运行的一系列操作。
- 强大 API 接口:提供一套 API 接口,它可以与 Python、JavaScript 等编程语言一起使用,方便开发者将其集成进自己的应用中,其基于 Go 语言中的 Web 框架 gin 提供了一些 API 接口,实现类似于调用 OpenAI 服务的效果。
- 灵活性高:不仅支持官方提供的多种预训练模型,如 DeepSeek、Llama 2、Mistral、Qwen 等,还能完美支持用户自己训练的模型。
- 多模型并行支持:可同时运行多个模型实例,且相互之间互不干扰。可以支持多种不同的模型架构和框架,包括 OpenAI 的 GPT 系列、Google 的 BERT、DeepSeek等。
- 跨平台兼容:支持 Windows、macOS、Linux(包括 ARM 架构如树莓派)等多种操作系统。
- RAG 集成:可结合本地文档库实现检索增强生成(Retrieval-Augmented Generation)。
- 多模态扩展:支持 Whisper(语音)、BakLLaVA(图像)等多模态插件。
- 官网无墙:无需通过科学上网,就可以直接访问 Ollama 的官网,同时官方在官网中提供了类似 GitHub、DockerHub 的 ModelHub(用于存放大语言模型的仓库,有 llama 2、mistral、qwen、deepseek 等模型,同时你也可以自定义模型上传到仓库里来给别人使用)。
三、Ollama 的应用
Ollama 在本地开发和测试、私有化部署、教育和研究、边缘计算等领域都有应用。在本地开发和测试时,开发者可以在本地环境中快速进行基于大型语言模型的应用程序开发与测试工作,无需依赖云服务,便于快速原型设计和调试;在私有化部署时,企业能在内网运行定制模型,在医疗、金融等对数据隐私要求极高的场景中,保障数据安全,防止数据泄露;在教育和研究时,学术机构的研究人员和学生可以低成本运行实验性模型,探索 LLM 能力边界,进行各种语言模型的实验和研究;在边缘计算时,可在 IoT 设备(如 NVIDIA Jetson)上部署轻量级模型,满足边缘计算场景下的需求。
操作步骤
一、前置工作
系统要求:
- Windows:推荐使用 Windows 10 版本号 22H2,或比该版本更高的。
- Linux:官方对于 Linux 没有特殊的版本要求,建议使用当前的稳定版本。
注意:由于 Ollama 使用 Unicode 字符表示进度,在一些旧的 Windows 终端当中可能会出现未知的正方形,可以尝试修改字体设置改善这种情况。
显卡要求:
- NVIDIA:使用版本号为 452.39 的驱动程序或版本号更高的驱动程序。
- AMD:使用版本号为 25.1.1 的驱动程序或版本号更高的驱动程序。
存储空间的要求:由于需要存储大模型,可能会需要几 GB 到几百 GB 的存储空间,默认安装在系统盘,后续可以通过修改环境变量来修改路径,这将会在“Ollama 的安装”当中介绍。
支持软件的安装:
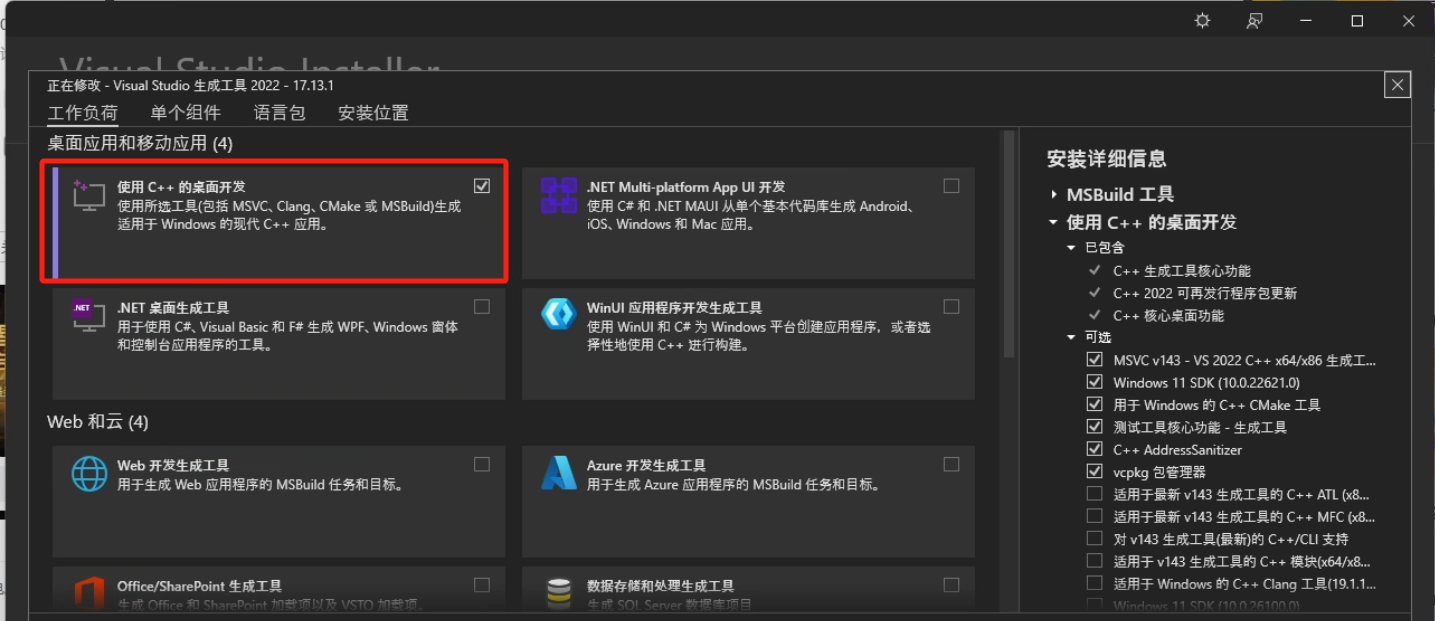
- CMake(开发人员):CMake 是开源、跨平台的构建工具,可以让我们通过编写简单的配置文件去生成本地的 Makefile,在运行前要确保 CMake 的环境变量设置完成。这个软件可以先不安装,因为 Visual Studio 2022 的“使用 C++ 的桌面开发”模块时会包含。
- Visual Studio 2022 :需要包含“使用 C++ 的桌面开发”,该模块包含 CMake,所以不需要单独安装 CMake 了(open-webui 需要使用)。
- AMD GPU(可选):可以选择 ROCm 或 Ninja(Linux 中没有),ROCm 不兼容 Visual Studio CMake 生成器,在配置时需使用 -GNINJA。
- NVIDIA GPU(可选):CUDA SDK,CUDA 仅兼容 Visual Studio CMake 生成器。
二、Ollama 的安装
1、下载与安装
Ollama 支持多平台安装,本文主要介绍 Windows,并会捎带提及 Linux。
- Windows:Windwos 安装包下载
- Linux:
curl -fsSL https://ollama.com/install.sh | sh如果需要手动安装可以查看一下这个链接:手动安装说明
2、安装包下载完毕后双击打开安装,安装程序安装不可以选择安装路径,后续可以通过修改环境变量做目录迁移
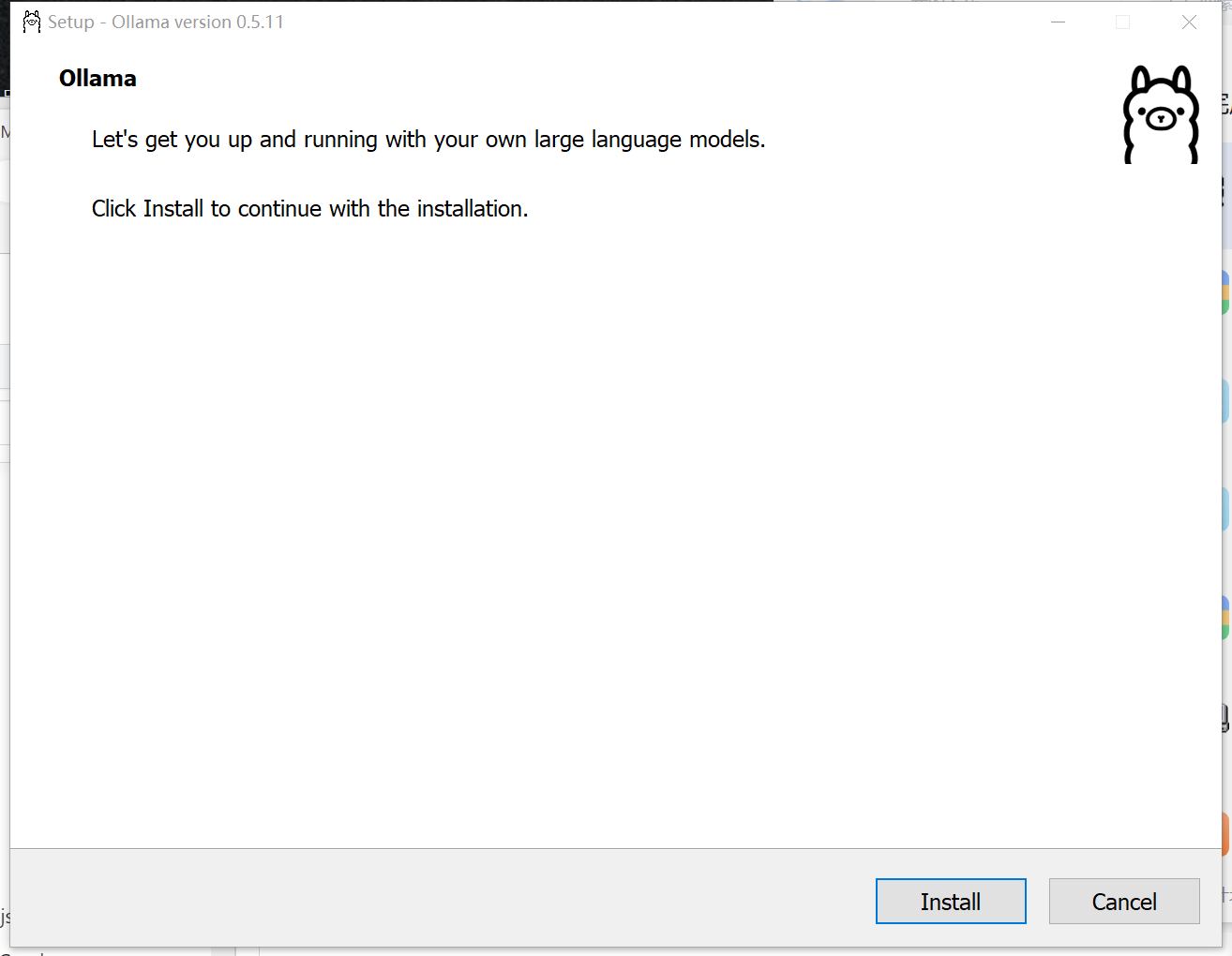
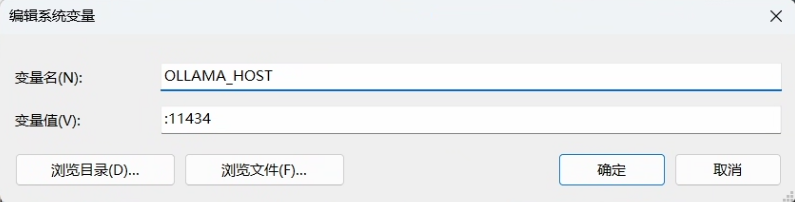
安装完毕后就会显示在菜单栏右下角。在环境变量当中我们可以添加一个 OLLAMA_HOST 来查看 Ollama 是否运行,环境变量设置如下图所示
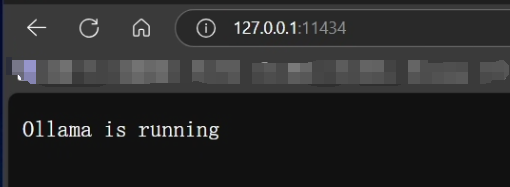
设置完成后全部点击确定,打开浏览器输入:http://127.0.0.1:11434
3、在终端测试 Ollama 是否安装成功
Windows 中我们可以使用 cmd 或 Power Shell 来运行,测试成功如下图所示
4、Ollama 主目录与模型存放目录的迁移
Ollama 的主目录和模型存放目录默认都在系统盘当中,由于大模型的空间占用非常大,这样到后期会严重影响系统的性能,下面以 Windows 为例一起来看看如何对这两个目录进行迁移
Ollama 主目录的迁移:
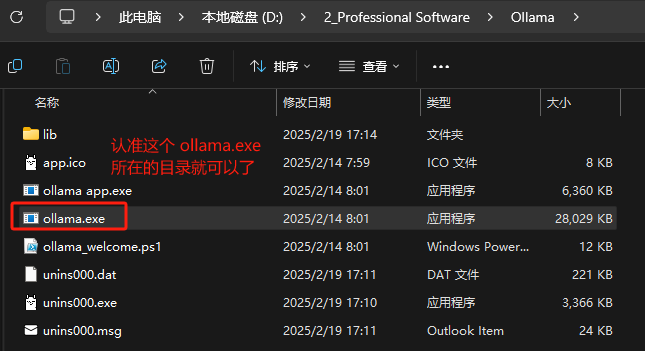
(1)迁移目录前需要先把 Ollama 退出。默认安装路径为 C:\Users\<username>\AppData\Local\Programs\Ollama,我们直接把这个目录复制到我们想要放的地方,假设为 D:\2_Professional Software\
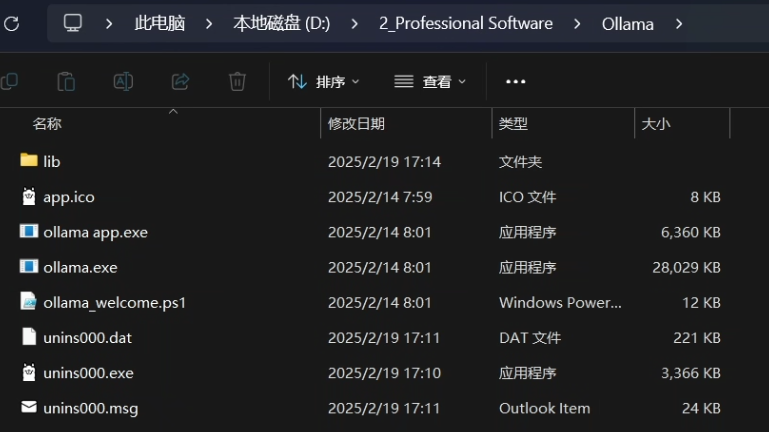
(2)修改环境变量中的 Path(用户变量和系统变量的都可以,只是前者针对当前用户,后者针对整个系统)
把原来的修改为新的目录,如果没有则添加上去就好
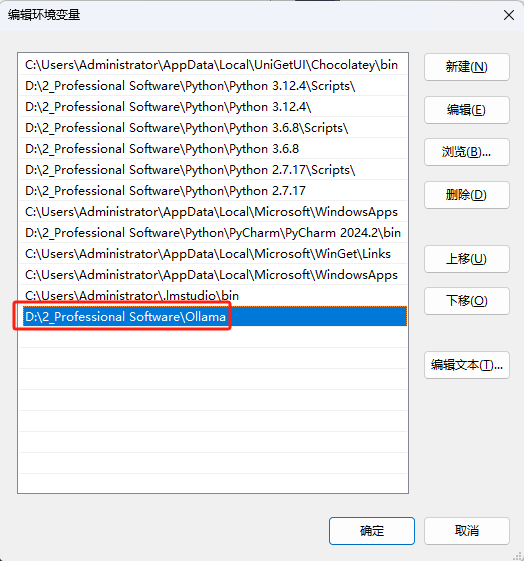
修改完环境变量后最好重启一下电脑。
(3)迁移完成后打开 cmd 测试一下 ollama 命令是否还能正常执行
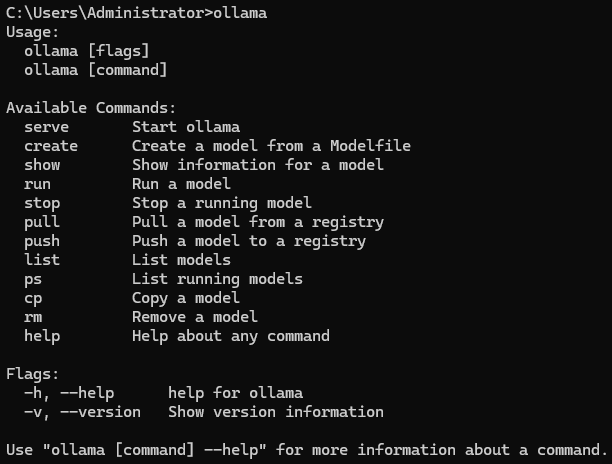
(4)由于主目录的迁移开始菜单和开机启动可能会受到影响,需修改以下目录下的 Ollama.lnk(Ollama 的快捷方式)
开机启动的 Ollama.lnk:C:\Users\Administrator\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Startup\Ollama.lnk
开始菜单中的 Ollama.lnk:C:\Users\Administrator\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Ollama\Ollama.lnk
C:\Users\Administrator\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Ollama.lnk
到此,Ollama 的主目录已经完成迁移了。
Ollama 模型目录的迁移:
(1)默认路径
Windows:C:\Users\<username>\.ollama\models
Linux:/usr/share/ollama/.ollama/models # 作为系统服务启动时
Linux:/home/<username>/.ollama/models # 当前用户启动时
在官网的模型仓库下载的模型默认会下载到这个路径下,如果保持默认在系统目录很快将会导致系统盘空间不足导致系统性能下降。
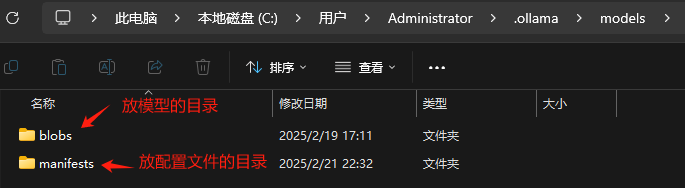
(2)进行目录迁移,如果你之前就在默认路径下载过模型那么就应该把整个原来的 models 文件进行迁移,确保 manifests 目录的存在,这样才能保持 Ollama 对原来的模型正常获取
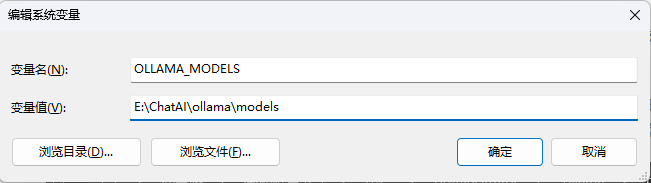
(3)假设我们想要放模型的目录是 E:\ChatAI\ollama\models,在迁移完成原模型目录后就应该修改环境变量了,这次我们应该在系统变量中添加一个 OLLAMA_MODELS 的变量,环境变量设置如下图所示
修改完环境变量后最好重启一下电脑,或者重启一下 Ollama 和 cmd
(4)迁移完成后查看是否能读取原来的模型,如下图所示

到此,Ollama 的模型目录已经完成迁移了,后续使用命令下载模型时也会下载到该目录下。
三、模型管理
在前面安装时已经介绍过如何通过修改环境变量来修改模型存放的目录了,除此之外我们还可以使用命令来修改,如下所示
Windows 用户:
(1)打开 cmd 进行 OLLAMA_MODELS 的设置
# 只设置当前用户
setx OLLAMA_MODELS "E:\ChatAI\ollama\models"
# 为所有用户设置
setx OLLAMA_MODELS "E:\ChatAI\ollama\models" /M(2)重启 cmd(setx 命令在 Windows 中设置环境变量时,这个变量的更改只会在新打开的 cmd 中生效)
(3)重启 Ollama 服务
Linux 一般用户:
(1)输入以下命令配置环境变量
# 打开下面文件
vim ~/.bashrc
# 添加设置
export OLLAMA_MODELS="/path/to/ollama_model"(2)使用以下命令是环境变量生效
# 找到 ollama 的进程 ID
sudo pgrep -f ollama
# 杀死该进程
sudo kill [pid]
# 使用 ollama 命令重启服务(如果没有 ollama 命令则需要先进到 ollama 的主目录后再执行该命令)
sudo ollama server或者
OLLAMA_MODELS="/path/to/ollama_model" ollama serveLinux root:
在服务文件中设置环境变量,需要为新的目录设置 ollama 用户的读写权限
# 打开服务文件
sudo vim /etc/systemd/system/ollama.service
# 在文件中Service字段后添加
[Service]
Environment="OLLAMA_MODELS=/home/xxx/ollama/models"
Environment="http_proxy=xxxxxx"
# 设置目录访问权限 (根据反馈做了些调整)
sudo chown ollama:ollama /home/xxx/ollama
sudo chmod u+w /home/xxx/ollama
sudo chown ollama:ollama /home/xxx/ollama/models
sudo chmod u+w /home/xxx/ollama/models
# 重启服务
sudo systemctl daemon-reload
sudo systemctl restart ollama.service
# 确认状态
sudo systemctl status ollama.service四、Ollama 中常用的命令
在 Ollama 安装完成之后,后续与模型的交互基本都是通过命令来进行的,下面我们来看看 Ollama 有什么命令和如何使用的
| 命令 | 用法 | 作用 |
|---|---|---|
| server | ollama server | 开启 ollama 服务 |
| create | ollama create <your-model-name> -f Modelfile | 用 Modelfile 文件来创建模型 |
| show | ollama show <your-model-name> | 输出模型信息 |
| run | ollama run <your-model-name> | 运行指定的模型,如果模型不存在将会从官方提供的模型库中下载 |
| stop | ollama stop <your-model-name> | 停止模型的运行 |
| pull | ollama pull <your-model-name> | 从官方提供的模型库中下载指定的模型 |
| push | ollama push <your-model-name> | 将本地的模型推送至官方的模型库中 |
| list | ollama list | 列出当前已注册的模型(即可用的) |
| ps | ollama ps | 列出正在运行的模型 |
| cp | ollama cp <original-model> <copied-model> | 复制一个模型 |
| rm | ollama rm <your-model-name> | 删除一个模型 |
| help | ollama help | 显示帮助信息 |
注意:在任何命令下 都可以使用 -h 或 --help 参数来获取该命令的帮助信息。
五、Ollama 的 Modelfile
Modelfile 是用于定制和创建个性化模型的关键工具。Modelfile 允许用户从现有的模型库中选择基础模型,并通过添加特定的参数和设置来调整模型的行为。
例如,我从别的地方靠来了一个大模型,直接放到模型目录下,然后运行 ollama list 命令是看不到新模型的,我们需要使用 create 命令调用 Modelfile 文件才能在 Ollama 中创建模型,下面来演示一下这一过程:
(1)我们在别的地方拷来了一个 deepseek-r1-32B.gguf 的大模型(.gguf 的后缀直接在 Ollama 官方模型库下载的模型改个名字加个后缀就可以了),然后我们需要创建一个 Modelfile 的文件,该文件与大模型放在同一目录下即可,然后我们把下面的内容写到该文件当中
From ./deepseek-r1-32B.gguf保存退出
(2) 在放模型的目录栏中输入 cmd 打开命令行
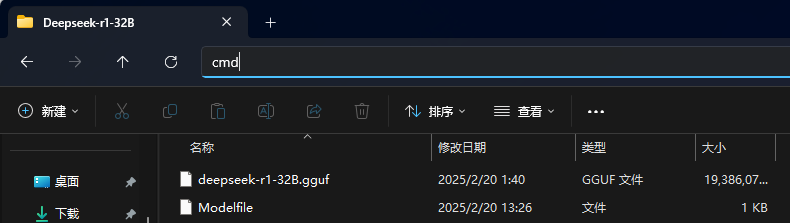
输入以下命令在 Ollama 中创建模型
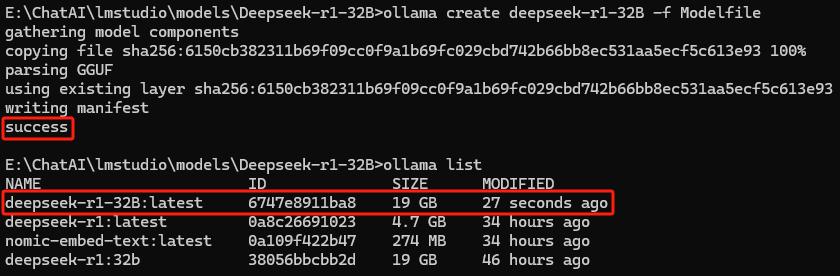
ollama create <model_name> -f Modelfile创建成功如下图所示
| Modelfile 的格式 | |
|---|---|
| 指令 | 描述 |
| FROM(必填) | 定义要使用的模型,可以定义已存在的,也可以定义官方模型库当中的 |
| PARAMETER | 设置 Ollama 运行模型的参数 |
| TEMPLATE | 设置发送给模型的所有提示模板 |
| SYSTEM | 设置模板中的系统消息 |
| ADAPTER | 定义要应用于模型的 (Q)LoRA 适配器 |
| LICENSE | 指定的许可证 |
| MESSAGE | 指定消息历史记录 |
1、FROM(必填)
指令定义了创建模型时使用的基模型。
FROM <model name>:<tag>使用官方模型库的模型创建:
From deepseek-r1-32b使用 Safetensors(Hugging Face 的文件格式)模型来创建:
FROM <model directory>注意:模型目录应包含支持架构的 Safetensors 权重
使用 GGUF 文件构建:
From ./deepseek-r1-32B.gguf注意:.gguf 文件的路径应该为绝对路径或者相对于 Modelfile 的相对路径
2、PARAMETER
该指令用于定义模型运行时的参数设置。
PARAMETER <parameter> <parametervalue>参数和需要填写的值如下表所示:
| 参数 | 描述 | 值类型 | 示例 |
|---|---|---|---|
| mirostat | 启用 Mirostat 采样以控制困惑度。(默认:0,0 = 禁用,1 = Mirostat,2 = Mirostat 2.0) | int | mirostat 0 |
| mirostat_eta | 影响算法对生成文本反馈的响应速度。较低的学习率会导致调整速度变慢,而较高的学习率会使算法更加灵敏。(默认:0.1) | float | mirostat_eta 0.1 |
| mirostat_tau | 控制输出文本的连贯性和多样性之间的平衡。较低的值将导致文本更加专注和连贯。(默认:5.0) | float | mirostat_tau 5.0 |
| num_ctx | 设置用于生成下一个标记的上下文窗口大小。(默认:2048) | int | num_ctx 4096 |
| repeat_last_n | 设置模型回溯的长度,以防止重复。(默认:64,0 = 禁用,-1 = num_ctx) | int | repeat_last_n 64 |
| repeat_penalty | 设置重复的惩罚强度。更高的值(例如,1.5)将更强烈地惩罚重复,而更低的值(例如,0.9)将更加宽容。(默认:1.1) | float | repeat_penalty 1.1 |
| temperature | 模型温度。提高温度将使模型回答更具创造性。(默认:0.8) | float | temperature 0.7 |
| seed | 设置用于生成的随机数种子。将此设置为特定数字将使模型对于相同的提示生成相同的文本。(默认:0) | int | seed 42 |
| stop | 设置要使用的停止序列。当遇到此模式时,LLM将停止生成文本并返回。可以通过在 modelfile 中指定多个单独的参数来设置多个停止模式。 | string | stop "AI assistant:" |
| num_predict | 预测生成文本时的最大标记数。(默认:-1,无限生成) | int | num_predict 42 |
| top_k | 降低生成无意义文本的概率。更高的值(例如 100)将提供更多样化的答案,而较低的值(例如 10)将更加保守。(默认:40) | int | top_k 40 |
| top_p | 与 top-k 协同工作。更高的值(例如,0.95)将导致文本更加多样化,而较低的值(例如,0.5)将生成更加专注和保守的文本。(默认:0.9) | float | top_p 0.9 |
| min_p | 替代 top_p,旨在确保质量和多样性的平衡。参数 p 代表一个标记被考虑的最小概率,相对于最可能标记的概率。例如,当 p=0.05 且最可能标记的概率为 0.9 时,小于 0.045 的 logits 被过滤掉。(默认:0.0) | float | min_p 0.05 |
3、TEMPLATE
完整提示模板(TEMPLATE)的数量要传递给模型。它可能包括(可选)系统消息、用户消息和模型的响应。注意:语法可能因模型而异。模板使用 Go 模板语法。
模板变量如下表所示:
| 变量 | 描述 |
|---|---|
| {{ .System }} | 系统消息,用于指定自定义行为 |
| {{ .Prompt }} | 用户提示信息 |
| {{ .Response }} | 模型响应。当生成响应时,此变量之后的文本将被省略 |
示例如下:
TEMPLATE """{{ if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}{{ if .Prompt }}<|im_start|>user
{{ .Prompt }}<|im_end|>
{{ end }}<|im_start|>assistant
"""这段模板代码分为三部分:
- 如果 System 变量存在(通过 {{ if .System }} 判断),就会生成一个以 <|im_start|>system 开头,{{ .System }} 是插入 System 变量的值,然后以 <|im_end|> 结尾的部分。
- 如果 Prompt 变量存在(通过 {{ if .Prompt }} 判断),就会生成一个以 <|im_start|>user 开头,{{ .Prompt }} 是插入 Prompt 变量的值,然后以 <|im_end|> 结尾的部分。
- 最后固定生成 <|im_start|>assistant 这部分文本。
4、SYSTEM
在适用的情况下,用于指定模板中使用的系统消息。
SYSTEM """<system message>"""5、ADAPTER
该指令指定了一个经过微调的 LoRA 适配器,该适配器应应用于基础模型。适配器的值应为一个绝对路径或相对于 Modelfile 的路径。基础模型应通过指令指定。如果基础模型与适配器微调时所用的基础模型不同,则行为将不稳定。
Safetensor 适配器:
ADAPTER <path to safetensor adapter>当前支持的 Safetensor 适配器:
- Llama (Llama 2, Llama 3, and Llama 3.1)
- Mistral (Mistral 1, Mistral 2, and Mixtral)
- Gemma (Gemma 1 and Gemma 2)
GGUF 适配器:
ADAPTER ./ollama-lora.gguf6、LICENSE
该指令允许您指定与该 Modelfile 一起使用的模型共享或分发的合法许可证。
LICENSE """
<license text>
"""7、MESSAGE
该指令可以指定模型在响应时使用的消息历史记录。使用多个 MESSAGE 命令来迭代构建的对话,将会让模型以类似的方式回答,换句话来说就是指定语言风格。
MESSAGE <role> <message>该指令中的角色(role)如下表所示:
| 角色 | 描述 |
|---|---|
| system | 为模型提供 SYSTEM 消息的另一种方式 |
| user | 用户可能会问的问题模板 |
| assistant | 模型应该如何响应的模板消息 |
示例如下:
MESSAGE user Is Toronto in Canada?
MESSAGE assistant yes
MESSAGE user Is Sacramento in Canada?
MESSAGE assistant no
MESSAGE user Is Ontario in Canada?
MESSAGE assistant yes六、DeepSeek 模型的使用
在安装好 Ollama,并设置好所有环境变量之后我们可以从各种路径去下载我们要使用的大模型了,这里我们推荐去 Ollama 的官方模型库下载,当然如果条件允许还可以去模型更加丰富的 Hugging Face 下载,下面将演示如何从官方模型库下载模型并调用
1、打开官方模型库找到我们想要下载的模型
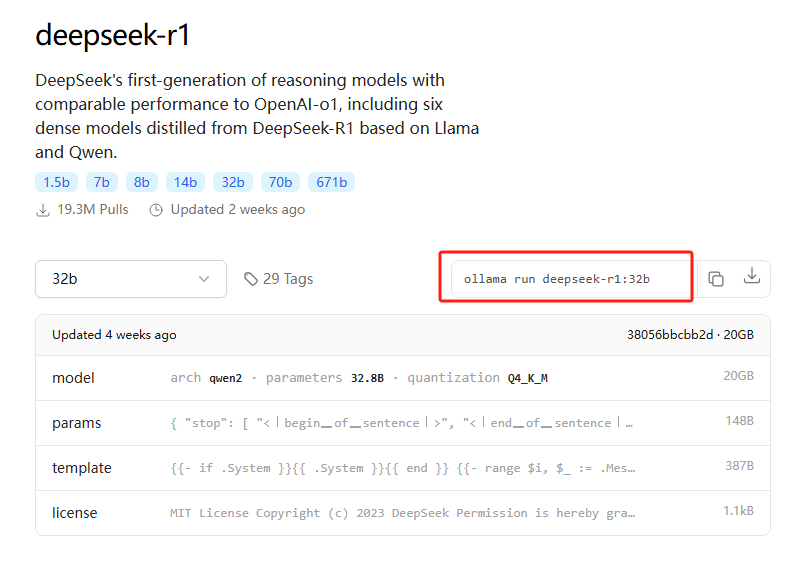
打开想要的模型后复制这条命令,之后在 cmd 中运行该条命令,这里我们下载 1.5b 的模型进行演示,下载完成后如下图所示
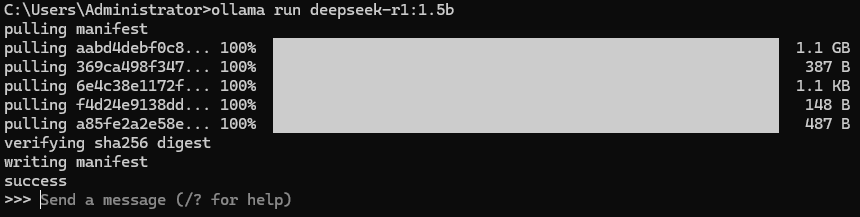
下载完成后会自动进行哈希校验,以确保下载模型的完整性,并写入 manifest,这个过程就相当于 ollama create 了
注意:从官方的模型库下载到最后可能会很慢,可以 Ctrl + C 中断后再次运行该命令,会自动断点续传。
2、下载的模型会放到我们之前通过环境变量指定的目录下
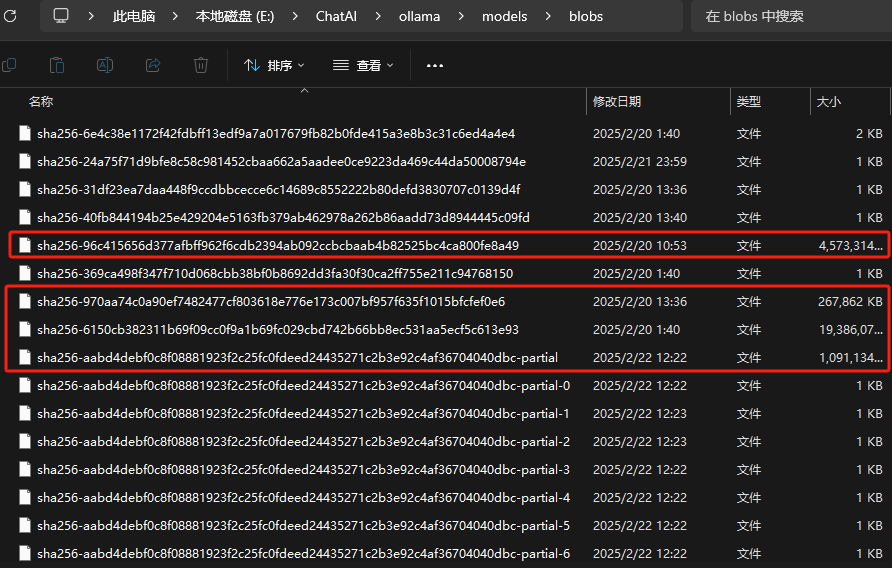
3、这里我提前下好了 deepseek-r1:32b 的模型,模型运行我就以 32B 的来进行演示

一开始可能会在这个过程一段时间,这是因为需要先将模型加载进内存当中,而 32B 的大小为 19GB,这也是为什么官方会推荐 33B 的大模型至少需要 32GB RAM 的原因
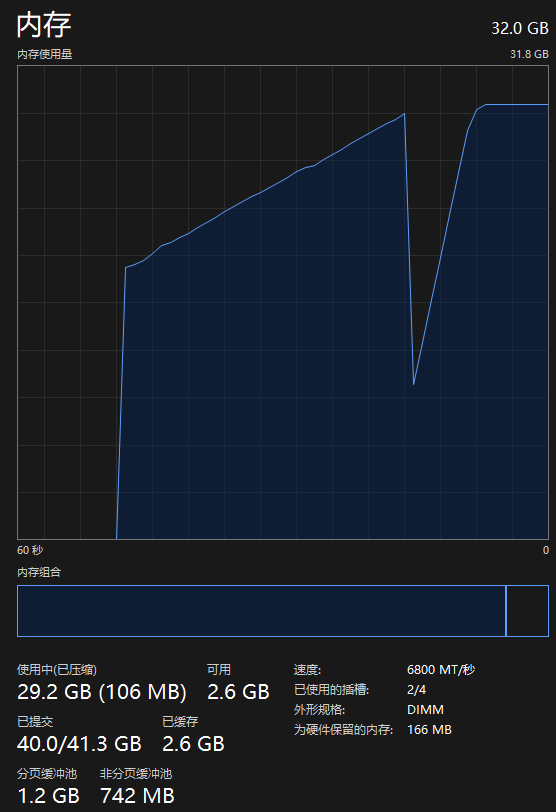
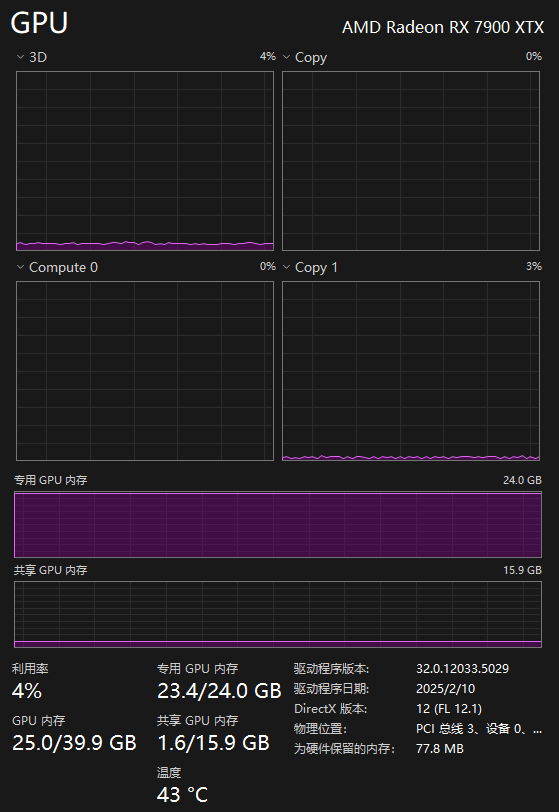
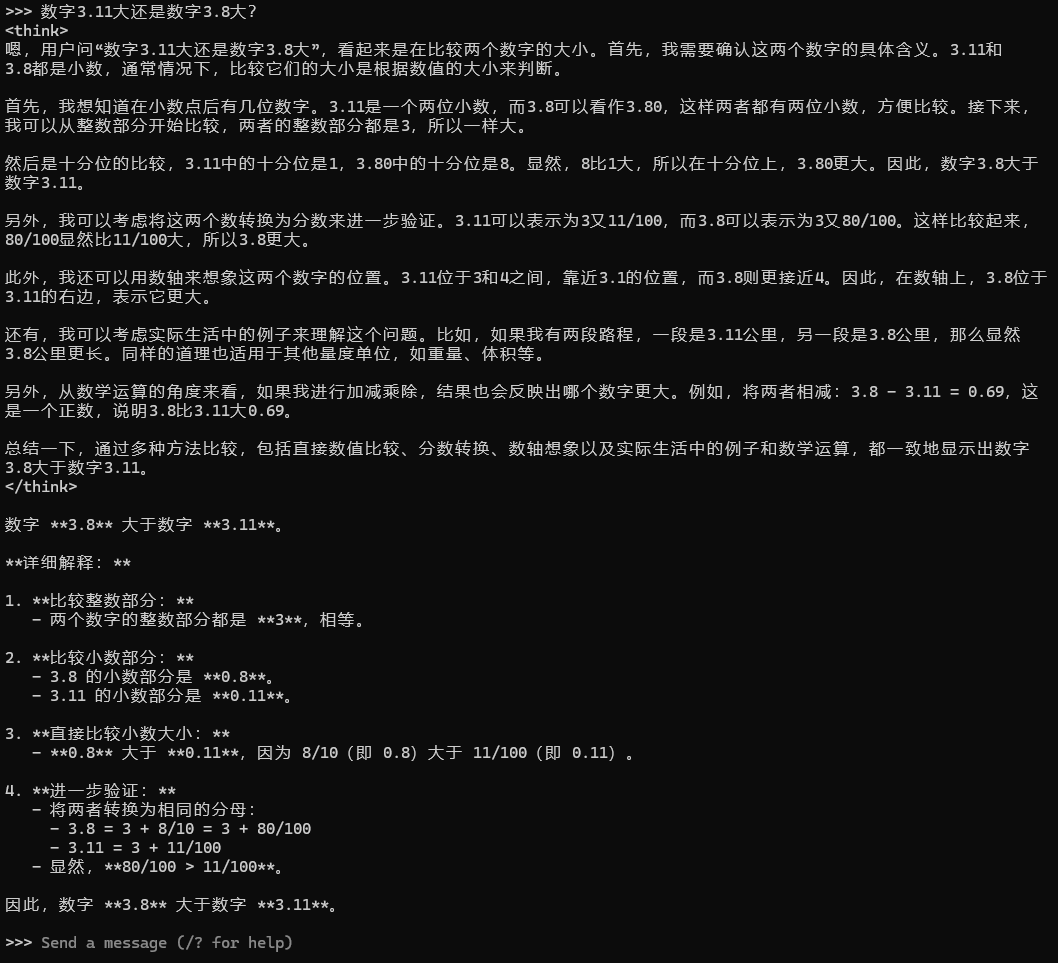
如果显存不够的话将会调用内存来运行,单这会严重影响性能。模型也不会长时间占用内存,默认占用5分钟,超过这一时间会主动释放,当你需要再次使用时会重新加载到内存,如果想长时间占用则需要在模型参数当中进行设置。下面一起看看 32B 大模型的效果演示吧

Ollama 官方模型库不同 DeepSeek 模型的介绍
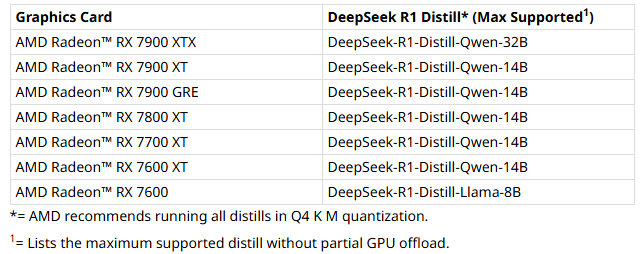
官方建议运行 7B 的大模型至少需要 8GB 的 RAM(运行内存);13B 的大模型至少需要 16GB 的 RAM,33B 的大模型至少需要 32GB 的 RAM。Ollama 官方模型库提供的 DeepSeek 大模型如下表所示:
| 模型名 | 参考数据量 | 模型大小 | 设备推荐 |
|---|---|---|---|
| deepseek-r1:1.5b | 15亿 | 1.1GB | 1GB以上显存的显卡 |
| deepseek-r1:7b | 70亿 | 4.7GB | 8GB以上显存的显卡 |
| deepseek-r1:8b | 80亿 | 4.9GB | |
| deepseek-r1:14b | 140亿 | 9.0GB | 12GB以上显存的显卡 |
| deepseek-r1:32b | 320亿 | 20GB | 24GB以上显存的显卡 |
| deepseek-r1:70b | 700亿 | 43GB | 40GB以上显存的显卡 |
| deepseek-r1:671b | 6710亿 | 404GB | 134GB以上显存的显卡 |
- b:billion 的首字母,代表十亿,这代表了训练模型时使用了多少参考数据进行训练
- r1:r1 代表了这是一个使用 deepseek 算法训练的推理模型,除了 r1 版本外还有 v2、v3 这类没有很强推理能力的模型,用于翻译找错上面会比 r1 的效率高很多

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 14
14 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)