DeepSeek R1技术报告解读
博主开辟了微信公众号,更多博客文章详见微信公众号“小宁算法梦工场”,欢迎读者们关注~
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
博主开辟了微信公众号,更多博客文章详见微信公众号“小宁算法梦工场”,欢迎读者们关注~
Github:https://github.com/deepseek-ai/DeepSeek-R1
PDF:https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
开源模型:
| Model | #Total Params | #Activated Params | Context Length | Download |
|---|---|---|---|---|
| DeepSeek-R1-Zero | 671B | 37B | 128K | 🤗 HuggingFace |
| DeepSeek-R1 | 671B | 37B | 128K | 🤗 HuggingFace |
DeepSeek-R1-Zero & DeepSeek-R1 are trained based on DeepSeek-V3-Base.
For more details regrading the model architecture, please refer to DeepSeek-V3 repository.
DeepSeek-R1-Distill Models
| Model | Base Model | Download |
|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | Qwen2.5-Math-1.5B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Qwen-7B | Qwen2.5-Math-7B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Llama-8B | Llama-3.1-8B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Qwen-14B | Qwen2.5-14B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Qwen-32B | Qwen2.5-32B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Llama-70B | Llama-3.3-70B-Instruct | 🤗 HuggingFace |
DeepSeek R1是截止目前国内第一个可以媲美OpenAI o1(满血版)模型,并且全部开源了实现方法和模型参数。不过还有很多值得讨论的问题,博主本人已经在项目中提出了相关的问题,也欢迎读者一起讨论或补充:https://github.com/deepseek-ai/DeepSeek-R1/issues/26
最近,以OpenAI o1为首的test-time scaling被引入到LLM推理任务中,发现在推理过程中增加搜索和计算的规模可以显著提高LLM在复杂任务上的推理性能。随着OpenAI o1的提出,学术界也有一些新的工作在尝试破解OpenAI的实现方案,例如过程奖励模型(Process-based Reward Model,PRM)、强化学习、蒙特卡洛树搜索(MCTS)等。
然而,现如今依然鲜有工作能够真正地实现对表o1性能。为此,本文则提出DeepSeek R1,一个对表o1的开源模型。
本文做了如下几个探索:
- 首先探索LLM在仅有RL的情况下推理能力的上限。挑选DeepSeek-V3-Base作为基座模型,并使用GRPO作为RL框架。该方法产出的模型为DeepSeek-R1-Zero。当RL训练超过1000步时,我们发现模型能够在reasoning任务上展现出涌现能力,例如AIME24的指标从15%上升至71%,Major Voting的指标可以达到86.7%,为此媲美于OpenAI o1-0912。
- 不过发现,DeepSeek-R1-Zero会出现一些输出风格上的问题,例如连贯性差、存在中英多语言混合等问题。为此,引入了cold-start data和多阶段训练策略。
○ 在cold start阶段,搜集上千个监督数据,并对DeepSeek-V3-Base进行微调;
○ 随后,采用与DeepSeek-R1-Zero相同的RL训练模式,对微调的模型进行RL训练;
○ 当RL逐渐收敛时,使用RL的checkpoint来构造CoT数据,并通过拒绝采样形式获取SFT训练数据。另外混合了DeepSeek-V3的in-domain部分训练数据(包括writing、factual QA、self-cognition等)。随后,这些数据用来重新训练DeepSeek-V3-Base基座,并再次进行RL,得到DeepSeek-R1。 - 使用DeepSeek-R1蒸馏Qwen2.5-32B-Base模型,发现蒸馏后的模型性能比直接对其进行RL更好。蒸馏的14B模型超越了QwQ-32B-Preview。
一、DeepSeek-R1-Zero
我们仅使用大模型的RL来训练Base模型,旨在探索是否不需要SFT数据也可以提高模型的推理能力。
(1)RL
RL框架选择GRPO算法。
对于一个问题 q q q ,上一轮的policy模型给出一组回答 o 1 , o 2 , ⋯ o_1, o_2, \cdots o1,o2,⋯,随后计算GRPO loss:
其中 A i A_i Ai 为advantage,计算为:
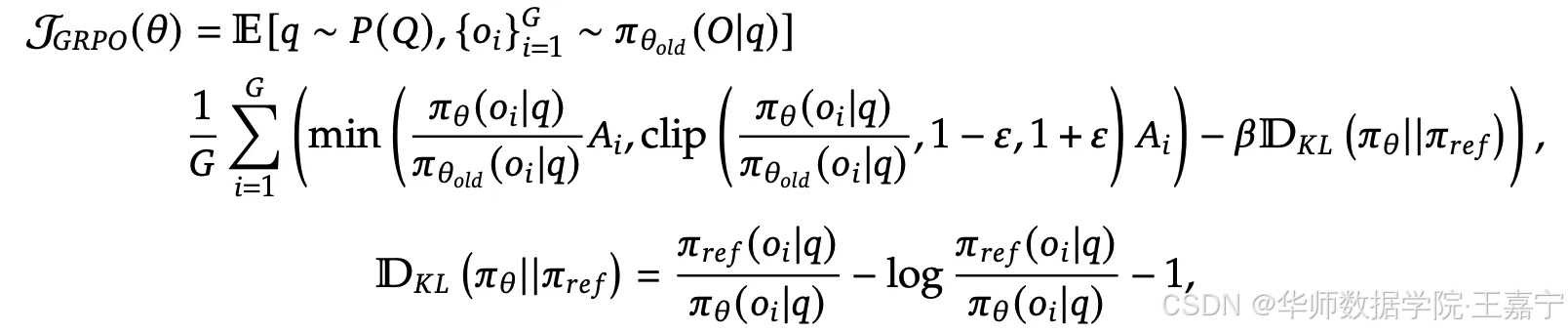
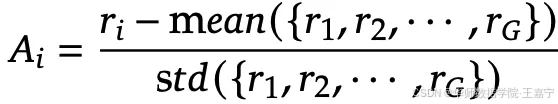
为了支撑RL的训练,Reward模型也需要进行设计。本文则主要选择基于规则的奖励:
- accuracy reward:在RL过程中的采样环节,对生成的response进行判断是否正确。例如math任务中抽取box中的答案并判断是否正确,code任务则通过test case和compiler来反馈结果是否正确。
- format rewards:设计一个奖励旨在促使模型将思考的过程放在和之间;
我们不适用任何的PRM或ORM,因为发现这些模型就出现reward hacking问题,并且在大规模的RL中引入额外的模型会增加训练的成本。
(2)训练
因为Base模型通常没有很强的指令遵循能力,因此需要设计一个prompt来让模型按照指定的风格进行推理。prompt如下所示:
选择DeepSeek-V3-Base模型,直接进行大规模的RL训练,随着RL步数的上升,发现在AIME24上指标变化非常明显: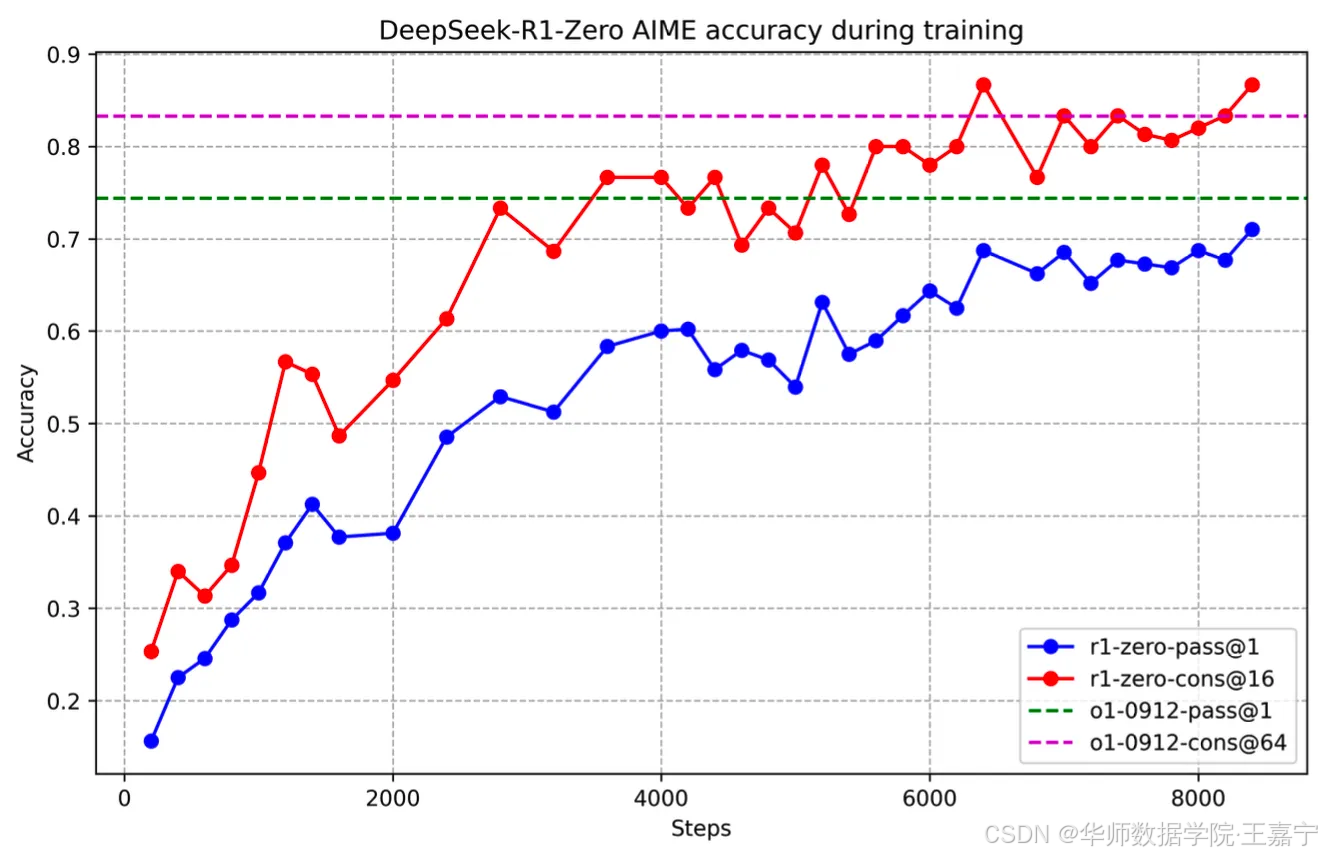
Self-evolution:在不适用SFT训练的前提下,观察RL如何让LLM能够实现自我进化。通过发现,随着RL的不断训练,模型会逐渐提高思考的时间(实际上就是生成的response的长度):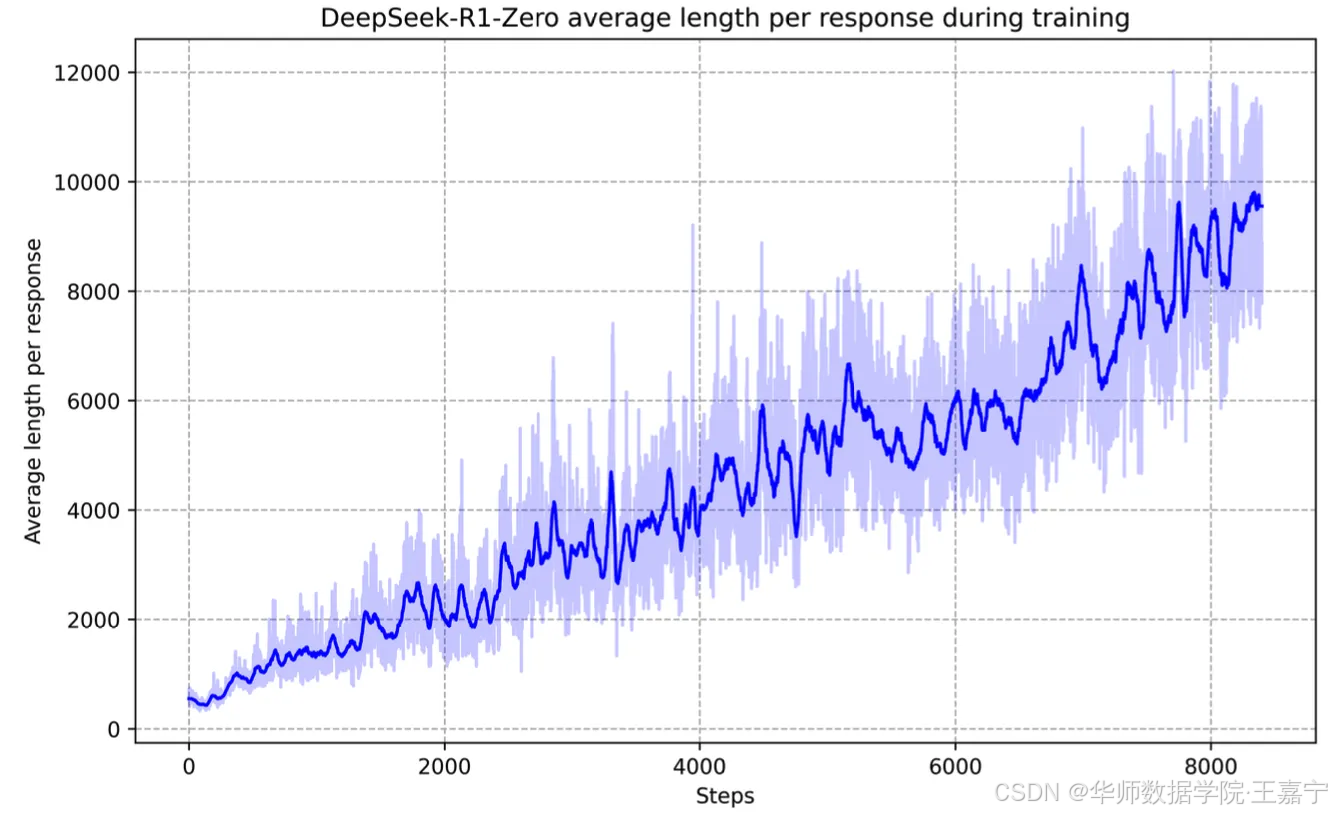
另外发现,通过增加推理思考的长度,随着RL的训练,模型已然衍生出了自我反思、纠错的行为。因为我们并没有增加SFT的训练过程,因此可以认为,只通过RL和环境反馈是可以让模型进化出这种复杂的行为,从而提高推理能力。
Aha Moment(顿悟时刻)
模型在进行RL的过程中,意外地发现模型会产生“顿悟时刻”的现象,如下图例子:
这一刻不仅是模型的“顿悟时刻”,也是观察其行为的研究人员的“顿悟时刻”。它强调了强化学习的力量和魅力:我们不是明确地教模型如何解决问题,而是简单地为它提供正确的激励,它就会自主地开发出先进的解决问题的策略。准确地说,RL只要有明确的奖励信号就好,主要规模足够大,模型是可以自我探索出合适的解决策略
“顿悟时刻”有力地提醒了我们,强化学习有潜力在人工智能系统中开启新的智能水平,为未来更自主、更具适应性的模型铺平道路。
二、DeepSeek-R1
由于发现DeepSeek-R1-Zero会出现出不可读、语言混合等问题,因此,接下来探索如何改进这个问题。
采用两轮迭代式的训练模式:
- cold-start data先进行SFT,然后进行RL训练;
- 将训练好的模型蒸馏一些新的SFT数据,规模在1M左右,并重新进行SFT + RL。
(1)cold start data
构造少量且高质量的SFT数据,这些数据主要是长CoT数据。构造这个cold data主要有三种途径:
- 通过few-shot exemplar的形式;
- zero-shot instruction的形式;
- 对DeepSeek-R1-Zero的输出部分进行后处理,从而获得readable的结果。
readable pattern统一设计为:
|special_token|<reasoning_process>|special_token|
推理的过程则形成“思考” + “总结”的模式。
(2)Reason-oriented RL
基于cold-start data,对DeepSeek-V3-Base进行SFT训练,随后使用RL进行精调。cold-start主要面向的任务是coding、math、stem和logic reasoning。因此,其搜集的query可能是这些domain对应的开源数据。
在RL阶段也发现会出现中英文混合的情况。为此在RL中增加了一个语言一致性的reward。消融实验发现这种设置会降低模型的性能,但是能够确保输出结果的可读性。
为此,最终的reward包含两个部分:
- accuracy:RL阶段的采样生成结果是否正确;
- language consistency:RL阶段采样生成的结果语言是否一致。
通过直接相加的形式获得最终的reward。这里没有显式地进行加权也是确保不对reward进行过度干预,从而避免hacking问题。
(3)Retraining
当RL训练完毕或者达到收敛时,将训练好的模型进行蒸馏。此时query除了reasoning方面的任务以外,也混合了大量的通用任务,例如writing、role-playing等,目的是让增强后的模型能够在各种领域分布的数据产生新的监督数据。
- Reasoning Data:蒸馏的其中一部分是面向推理的数据。除了直接使用基于规则的方式进行拒绝采样外,还引入model eval的方式(即挑选DeepSeek V3作为judger来判断模型蒸馏出的结果是否符合挑选条件)来进行挑选,此时则可以较好地过滤掉存在混合语言、超长段落、code block等数据。最终reasoning data可以蒸馏并挑选出大约600k个样本;
- Non-reasoning Data:对于非推理的任务,例如writing、factual qa、translation等,则直接使用Deepseek V3训练的pipeline。针对一些问答型的问题,则直接让DeepSeek V3给出CoT就可以(即非类o1风格数据);对于非常简单的问题(例如hello、普通对话等),则不需要CoT。这部分数据大约200k;
(4)Reinforcement Learning Again
第二次进行RL,此时由于query涵盖了包含reasoning和non-reasoning的任务,因此分别进行了设计:
- reasoning任务:reward模型依然是rule-based;
- non-reasoning任务:主要关注在helpfulness和harmfulness。采用DeepSeek V3的偏好优化流程。
三、Distillation
针对上面蒸馏的800k数据,直接对开源的一些模型进行SFT,包括Qwen2.5-Math-1.5B, Qwen2.5-Math-7B, Qwen2.5- 14B, Qwen2.5-32B, Llama-3.1-8B, and Llama-3.3-70B-Instruct。
四、实验
实验结果如下表,数据集包含reasoning和非reasoning任务,基线则为目前主流的强推理模型: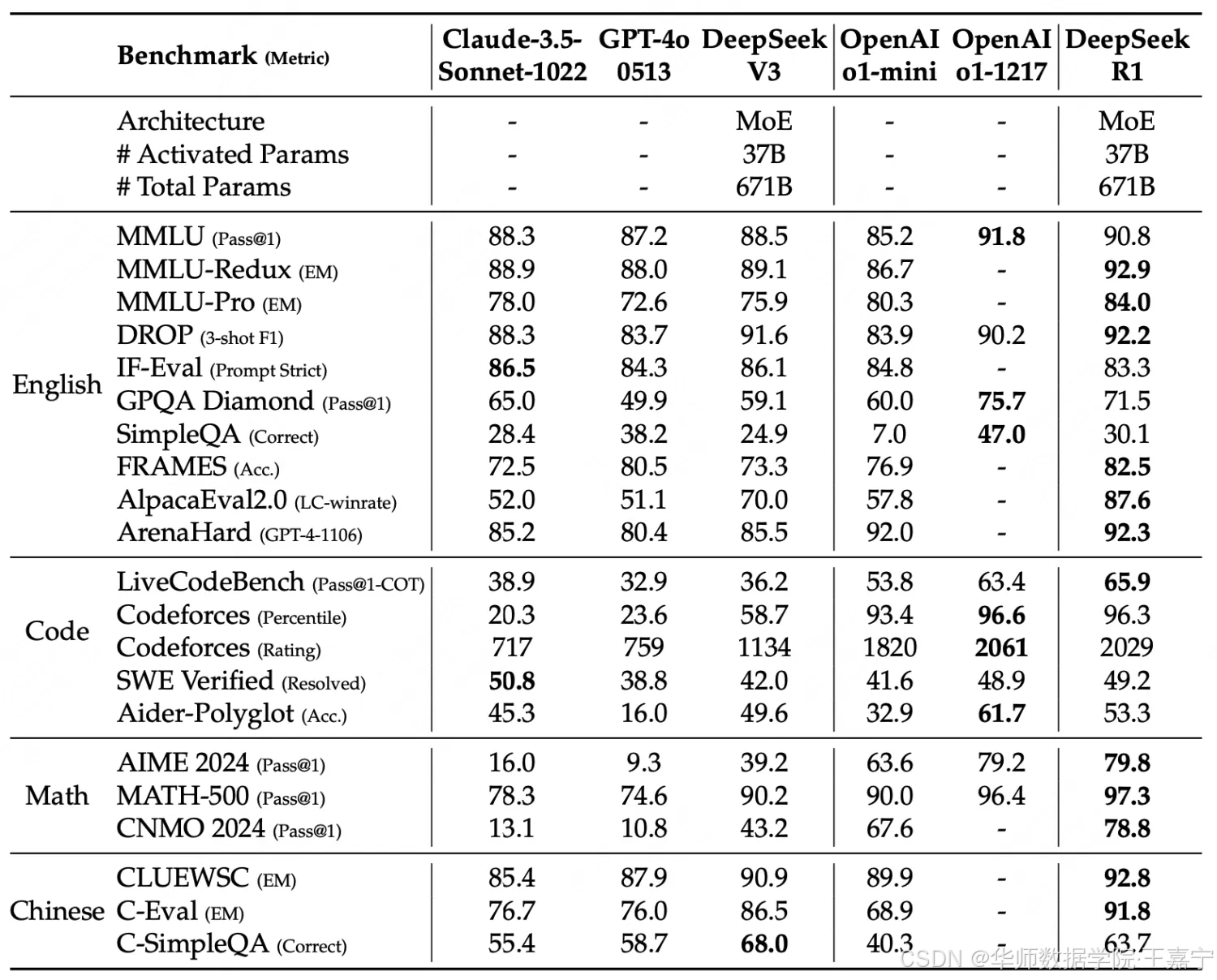
可以发现DeepSeek R1基本剋媲美OpenAI o1-1217。
通过800k蒸馏数据对开源模型进行SFT后的实验对比结果如下表所示: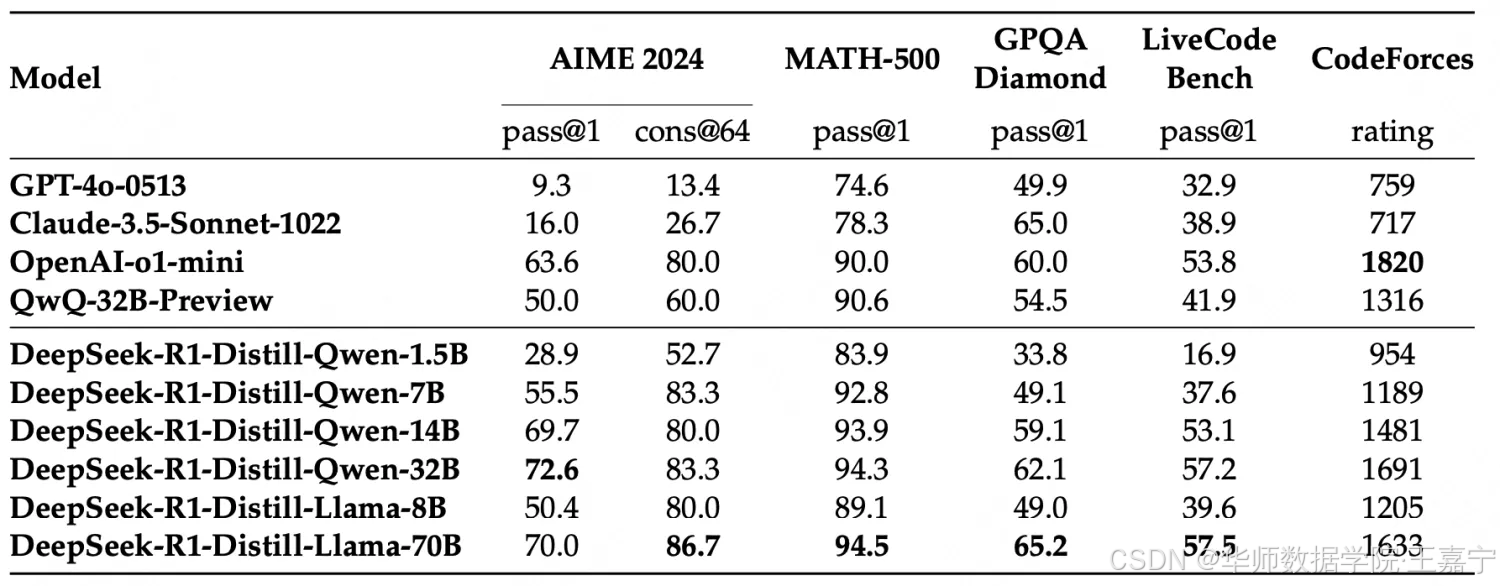
可以发现蒸馏后的模型效果也非常的惊艳。
五、一些发现
(1)DeepSeek R1蒸馏的数据对小模型进行SFT,更好于直接对小模型进行大规模RL;
是否对小模型进行大规模的RL训练也能够呈现出很好的表现么?我们选择Qwen2.5-32B-Base模型进行实验,RL的步骤超过10k,数据来自于math、code和stem。实验结果如下:
发现RL可以提升base模型的性能,但是相比直接用DeepSeek R1进行蒸馏还差距很远。
- First, distilling more powerful models into smaller ones yields excellent results, whereas smaller models relying on the large-scale RL mentioned in this paper require enormous computational power and may not even achieve the performance of distillation.
- Second, while distillation strategies are both economical and effective, advancing beyond the boundaries of intelligence may still require more powerful base models and larger-scale reinforcement learning.
(2)失败的经验
在实现过程中,也对PRM进行了探索,但是发现如下几个问题:
- PRM目前都是只在math上进行实验,因为math是高度step-wise风格的任务,但是对于一些通用任务很难定义process;
- 判定一个步骤是否正确比较困难,且可能会到来误差,同时人工标注PRM数据也无法做到scaling;
- PRM本质是一个reward模型,容易导致reward hacking问题;同时在RL过程中也需要不断地更新PRM,会带来资源开销,从而限制了RL的规模和效率;
对于MCTS也也有一些失败的经验: - MCTS搜索空间太大,所以需要在采样时候设置一些扩展约束,但这也带来了一些局部最优问题;
- value模型训练也比较困难

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 31
31 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)