DeepSeek-R1 本地部署与使用 · Windows系统 · 教程
通过本教程,您已掌握在 Windows 系统下部署 DeepSeek-R1 的完整流程,涵盖从安装 Ollama、下载模型到优化配置的关键步骤。但训练成本仅为后者的几十分之一。以下是使用 DeepSeek-R1 生成的推理数据,针对研究界广泛使用的几种密集模型进行微调而创建的模型。DeepSeek 团队已经证明,较大模型的推理模式可以提炼为较小的模型,从而获得比在小模型上通过 RL 发现的推理模式
一、为什么要部署 DeepSeek 本地版?
1.1 DeepSeek 是什么?
DeepSeek 是由中国公司“深度求索”开发的一款开源大语言模型,专注于通用人工智能(AGI)领域的研发。它基于深度学习技术和大规模数据训练,在数学推理、代码生成、长文本理解等任务上表现突出。
DeepSeek-R1作为第一代推理模型,性能对标于 OpenAI-o1,其中包括基于 Llama 和 Qwen 从 DeepSeek-R1 提炼出的六个密集模型。但训练成本仅为后者的几十分之一。
其核心特点包括:
- 开源特性:遵循 MIT 协议,允许用户自由修改、商用及二次开发。
- 多模型版本:提供从 1.5B 到 70B 参数量的蒸馏模型,以及原始模型 R1 系列,适应不同硬件需求。
- 推理能力:通过强化学习(RL)训练实现“顿悟”现象,显著提升复杂问题解决能力。
1.2 DeepSeek 的热门现状
- 用户激增与服务器压力:近期因用户量暴增和频繁恶意攻击,官方服务器常出现“繁忙”提示,本地部署成为稳定使用的首选方案。
- 国产芯片适配:龙芯 3A6000、华为昇腾等国产硬件已成功运行 DeepSeek-R1 7B 模型,推动本地化部署普及。
1.3 本地部署的优势
- 数据隐私:无需上传数据至云端,避免隐私泄露风险。
- 离线使用:无网络环境下仍可运行,适合敏感场景或网络不稳定地区。
- 性能可控:根据硬件选择模型规模,平衡速度与精度。
二、部署前准备(Windows 系统)
2.1 硬件要求
| 模型版本 | 参数量 | 内存 | 推荐 GPU(单卡) | 适用场景 |
|---|---|---|---|---|
| DeepSeek-R1-1.5B | 15亿 | 1.1GB | GTX 1650(4GB显存) | 低资源设备部署、实时文本生成、嵌入式系统 |
| DeepSeek-R1-7B | 70亿 | 4.7GB | RTX 3070/4060(8GB显存) | 中等复杂度任务(文本摘要、翻译)、轻量级多轮对话系统 |
| DeepSeek-R1-8B | 80亿 | 4.9GB | RTX 4070(12GB显存) | 需更高精度的轻量级任务,代码生成、逻辑推理 |
| DeepSeek-R1-14B | 140亿 | 9GB | RTX 4090/A5000(16GB显存) | 企业级复杂任务、长文本理解与生成 |
| DeepSeek-R1-32B | 320亿 | 20GB | A100 40GB(24GB显存) | 高精度专业领域任务、多模态任务预处理 |
| DeepSeek-R1-70B | 700亿 | 43GB | 2x A100 80GB/4x RTX 4090(多卡并行) | 科研机构/大型企业、大规模数据分析、高复杂度生成任务 |
| DeepSeek-R1-671B | 6710亿 | 404GB | 8x A100/H100(服务器集群) | 国家级/超大规模 AI 研究、通用人工智能(AGI)探索 |
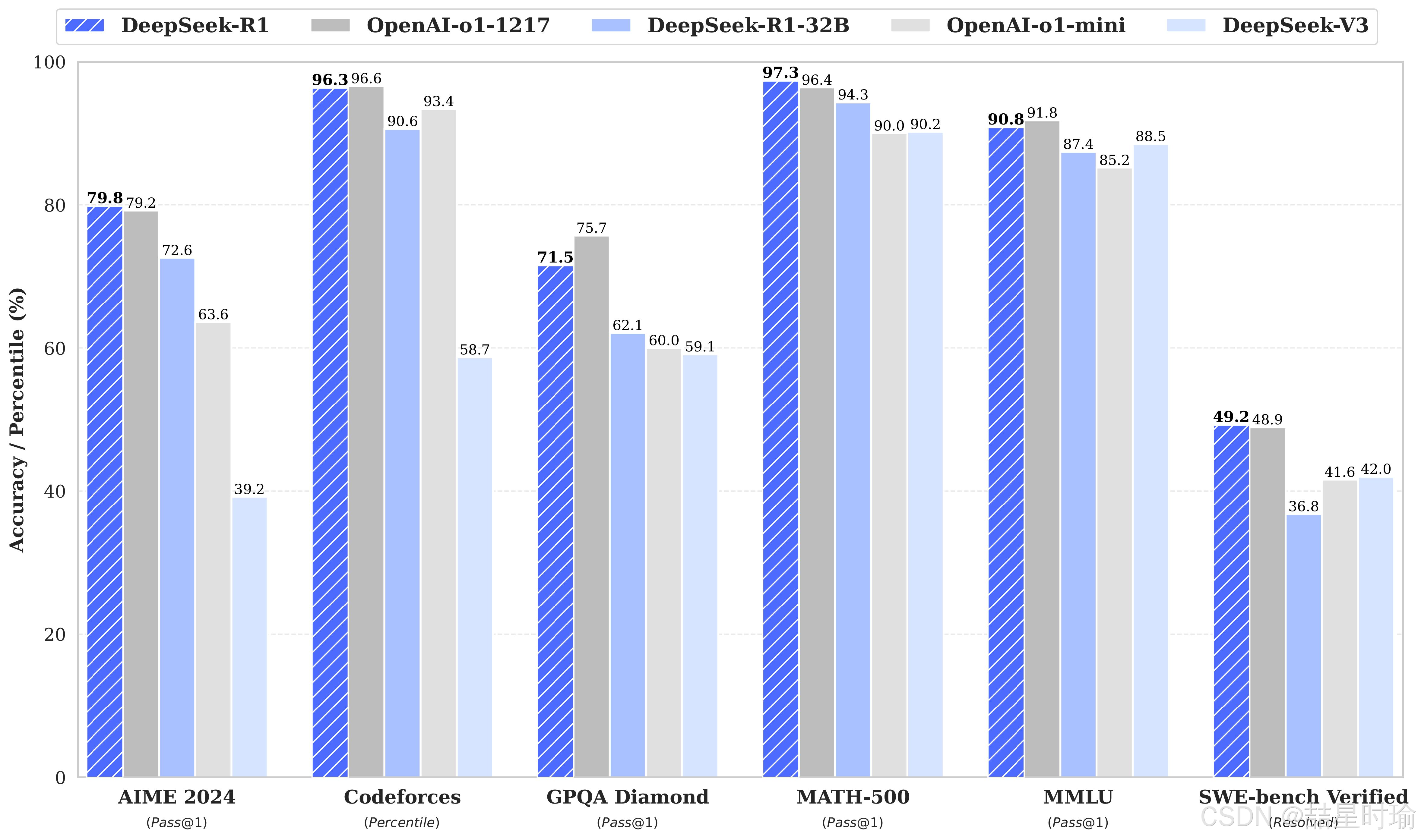
图源自deepseek-r1
2.2 软件依赖
- Ollama:轻量化模型管理工具,支持一键部署 DeepSeek-R1 系列。
- Python 3.8+(可选):用于数据预处理或高级配置。
- CUDA/cuDNN(GPU 用户):需与显卡驱动版本匹配。
三、本地部署详细步骤
3.1 安装 Ollama
1.下载安装包:
1.访问 Ollama 官网
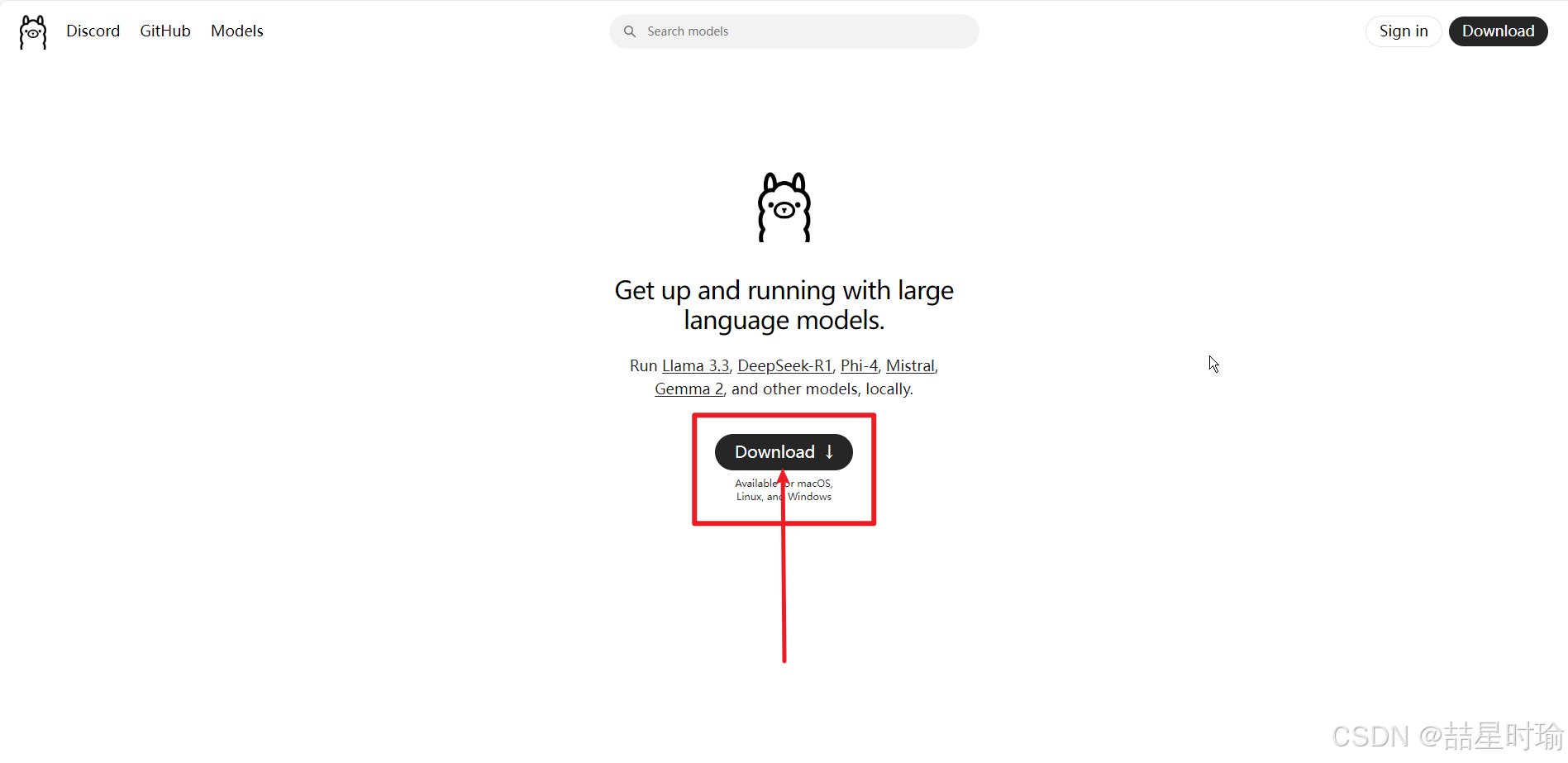
2.下载 OllamaSetup.exe。
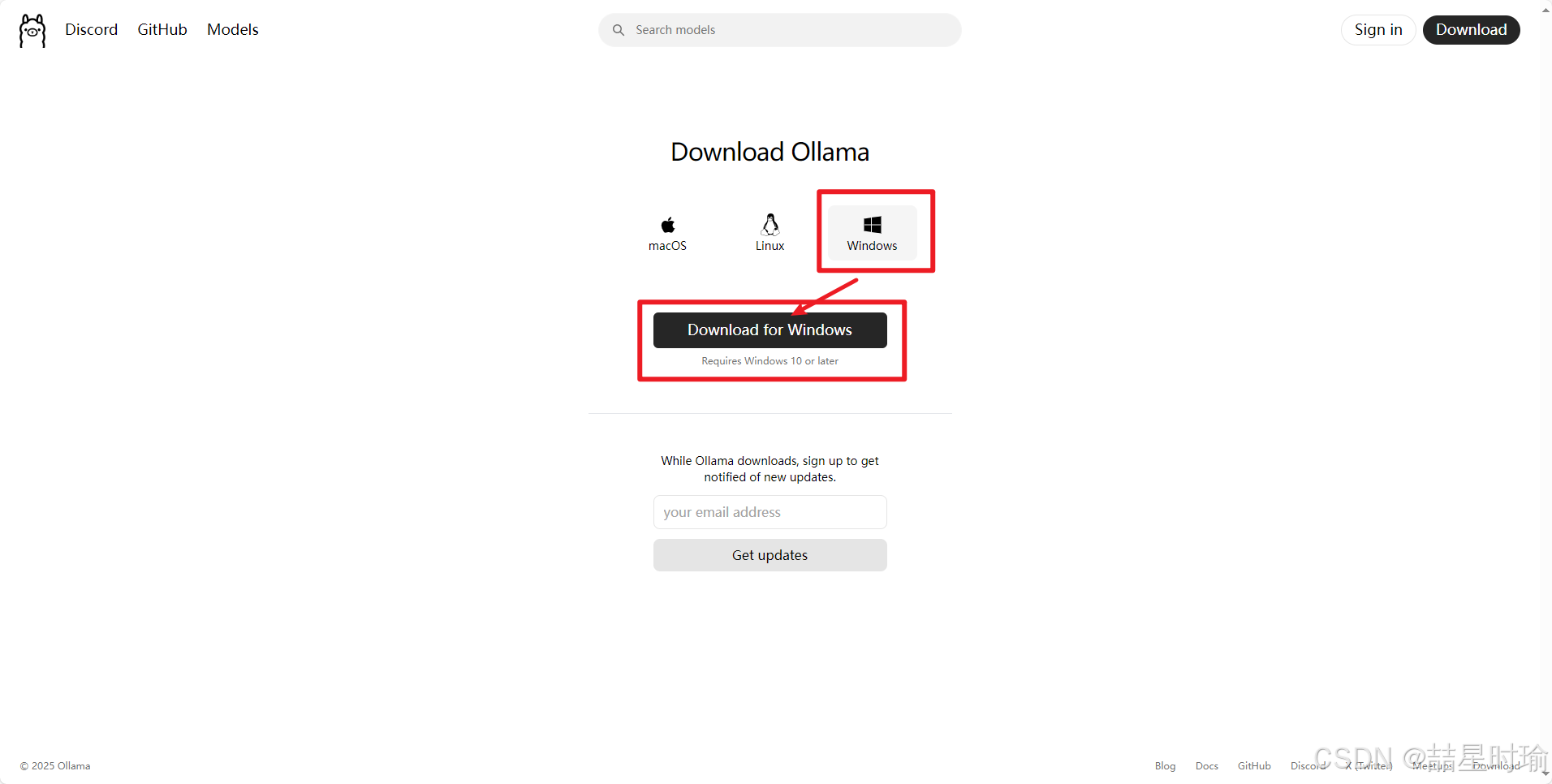
2.运行安装程序:
1.双击安装包

2.点击install
3.开始安装
4.完成安装
3.验证安装:
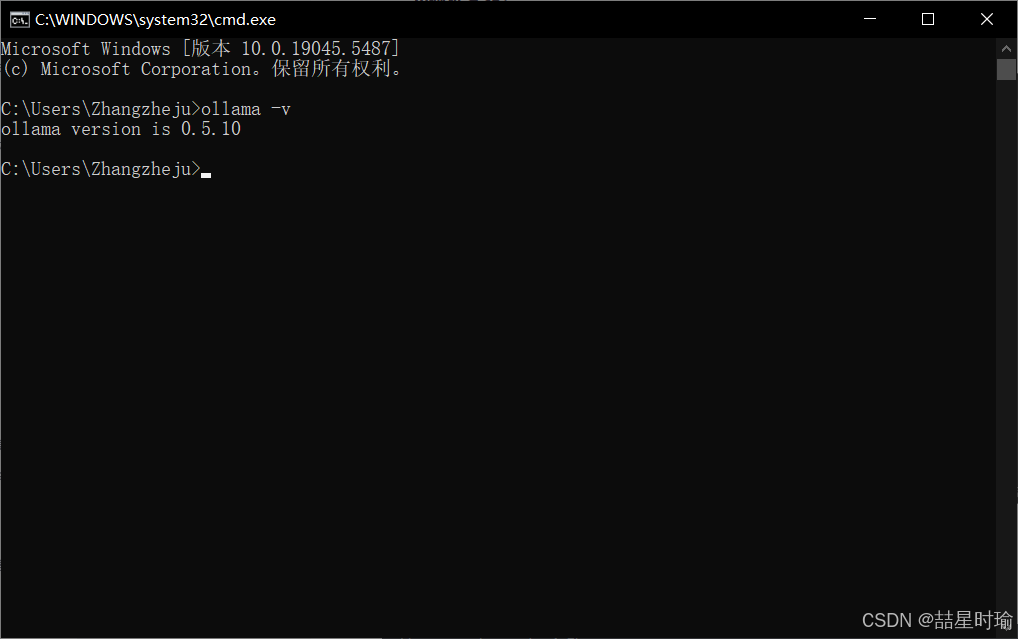
- 打开 CMD 或 PowerShell,输入
ollama -v,显示版本号即成功。
3.2 下载 DeepSeek-R1 模型
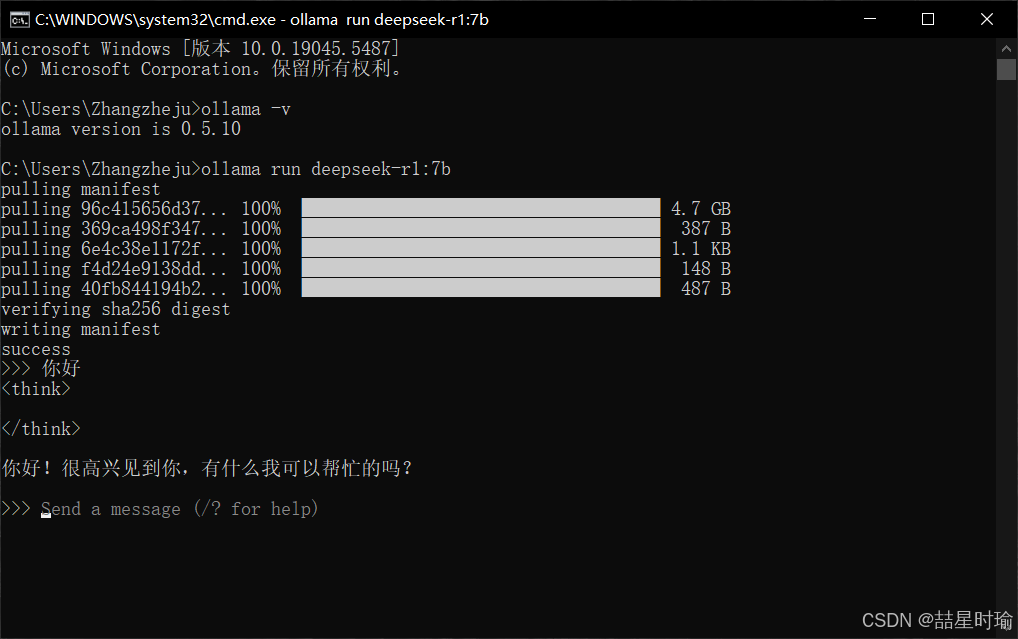
1.基础命令:验证完成后在控制台内输入
ollama run deepseek-r1:7b
此命令会自动下载 7B 参数模型(约 4.7GB),需确保磁盘空间充足。
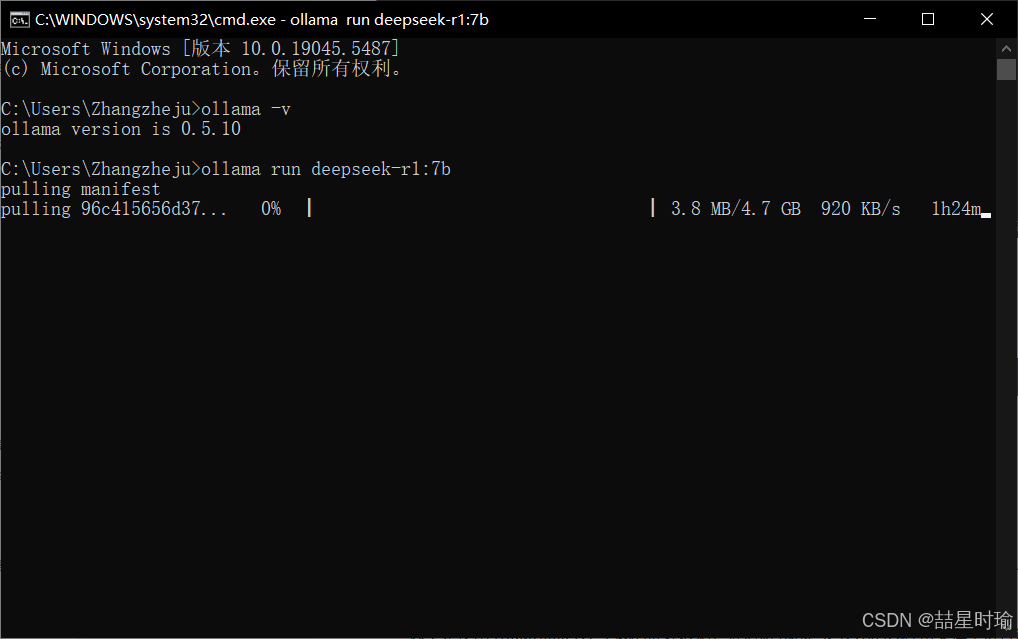
安装成功✅。
2.其他版本:
DeepSeek 团队已经证明,较大模型的推理模式可以提炼为较小的模型,从而获得比在小模型上通过 RL 发现的推理模式更好的性能。
以下是使用 DeepSeek-R1 生成的推理数据,针对研究界广泛使用的几种密集模型进行微调而创建的模型。评估结果表明,提炼出的较小密集模型在基准测试中表现优异。
DeepSeek-R1-Distill-Qwen-1.5B
ollama run deepseek-r1:1.5b
DeepSeek-R1-Distill-Qwen-7B
ollama run deepseek-r1:7b
DeepSeek-R1-Distill-Llama-8B
ollama run deepseek-r1:8b
DeepSeek-R1-Distill-Qwen-14B
ollama run deepseek-r1:14b
DeepSeek-R1-Distill-Qwen-32B
ollama run deepseek-r1:32b
DeepSeek-R1-Distill-Llama-70B
ollama run deepseek-r1:70b全模型 DeepSeek-R1
ollama run deepseek-r1:671b3.3 配置前端工具(Chatbox)
3.3.1 下载 Chatbox:
访问 Chatbox 官网,下载 Windows 版安装包,按照提示完成安装。

选择为使用这台电脑的任何人按照(所有用户),点击下一步。
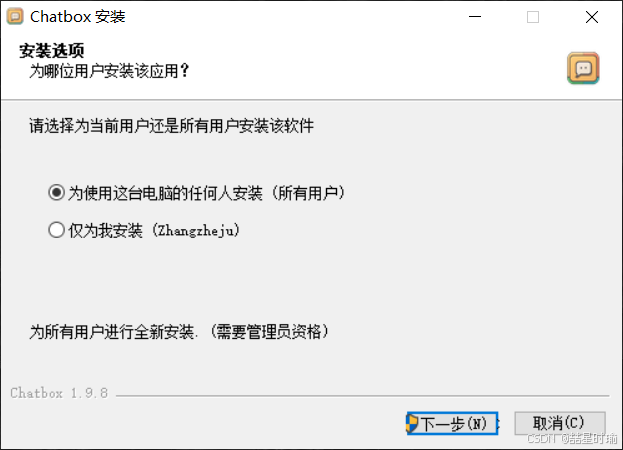
修改按照地址(不建议原路径安装占用C盘内存),点击安装。
等待安装。
3.3.2 配置 Chatbox:
打开chatbox
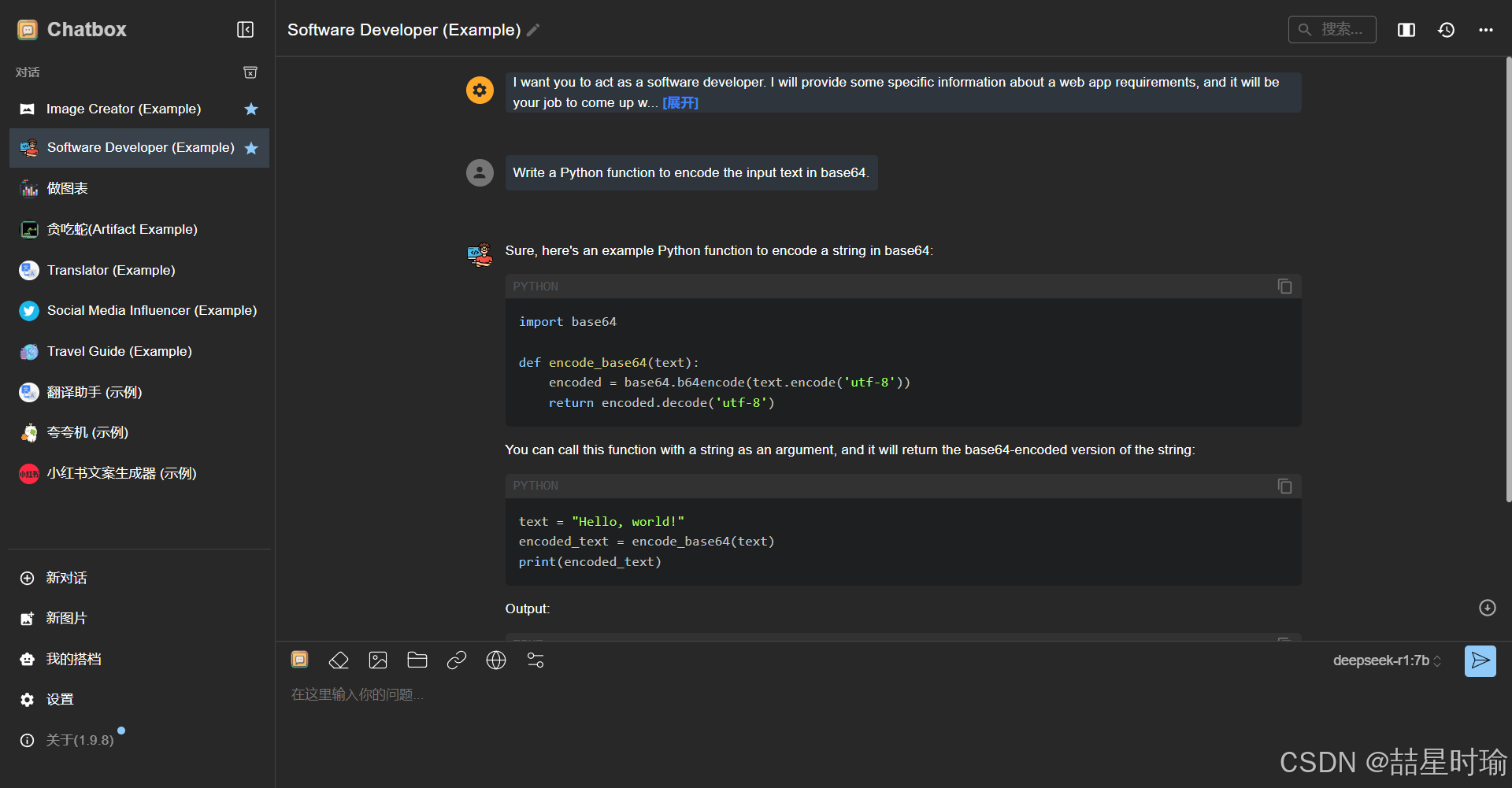
打开设置选择ollama API
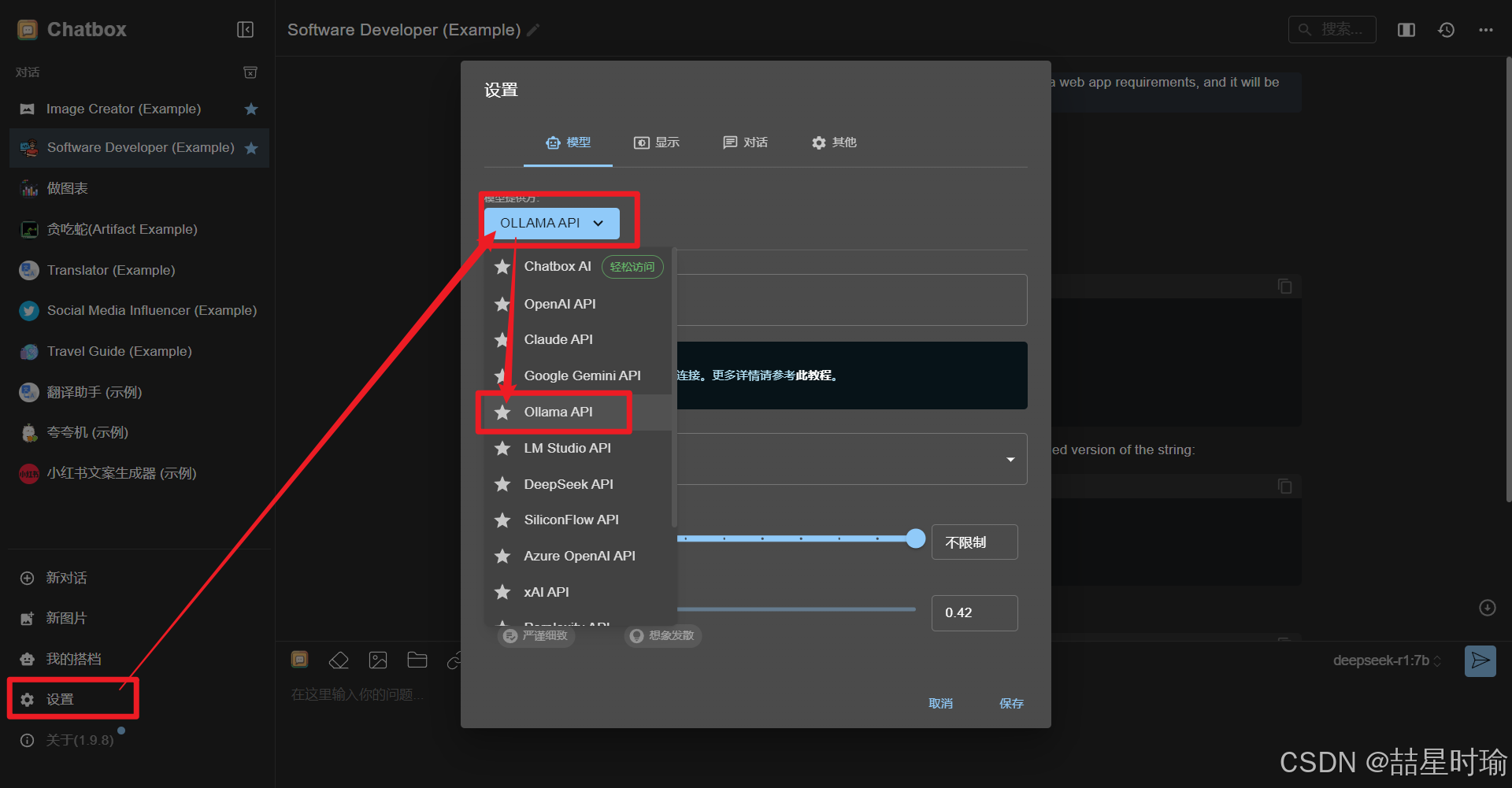
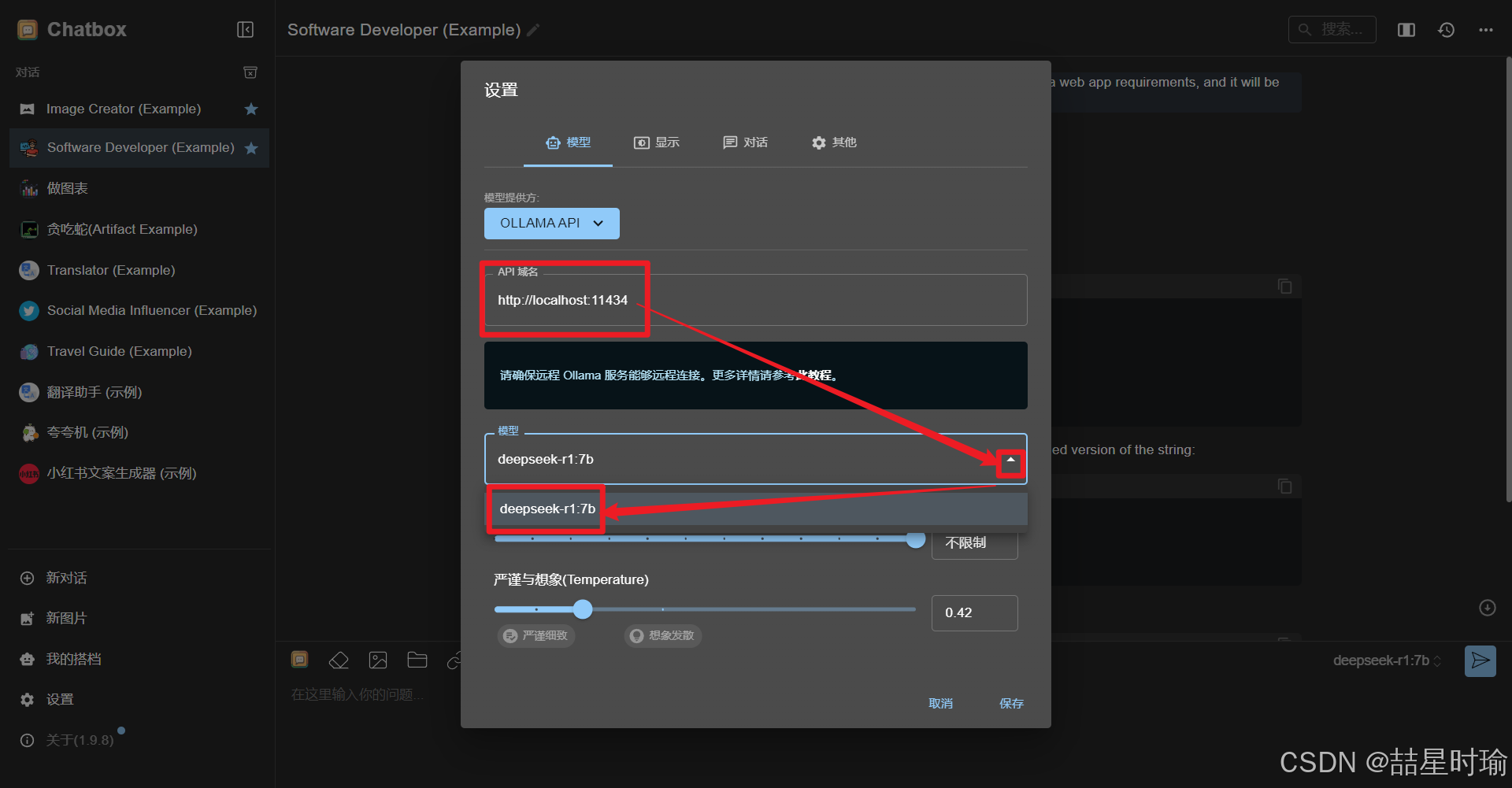
自动填充域名,选择模型,当前模型为deepseek-r1:7b,点击保存
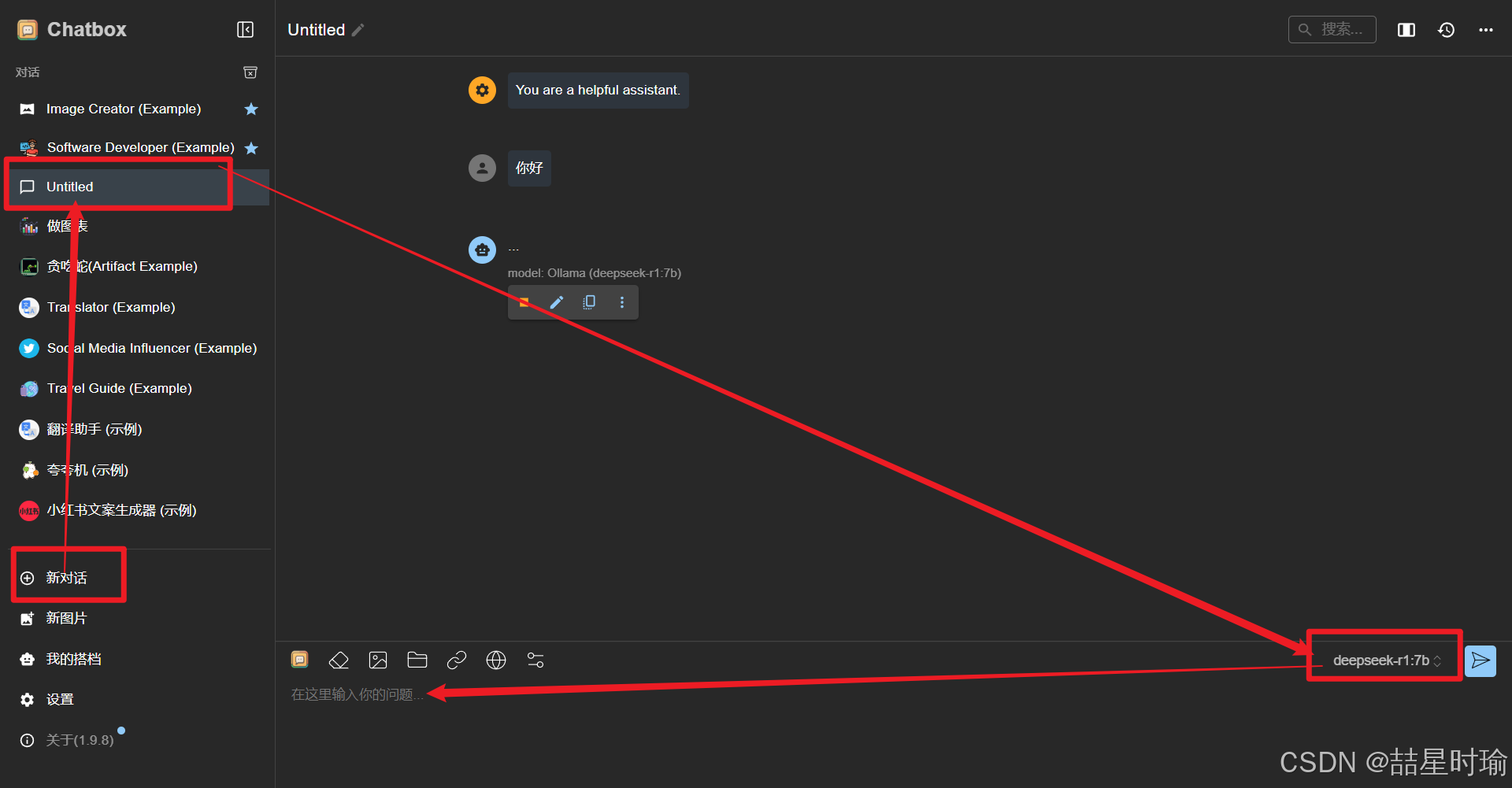
3.3.3 开启对话
四、优化配置与高级功能
4.1 官方推荐参数设置
- Temperature(温度值):设为
0.6,避免重复输出或逻辑混乱。 - 提示词格式:
[file name]: {file_name} [file content begin] {file_content} [file content end] {question} - 数学问题专用指令:在提问中包含“请逐步推理,并将答案置于
\boxed{}内”。
4.2 文件上传与本地搜索
- 通过 Chatbox 上传文件(如 PDF、TXT),模型可基于文件内容回答相关问题。示例:
[file name]: 技术文档.pdf [file content begin] ...(文件内容)... [file content end] 请总结本文档的核心技术点。
4.3 多模型切换
- 在 Ollama 中可同时管理多个模型,通过以下命令切换:
ollama list # 查看已安装模型 ollama run deepseek-r1:14b # 切换到 14B 模型
五、总结
通过本教程,您已掌握在 Windows 系统下部署 DeepSeek-R1 的完整流程,涵盖从安装 Ollama、下载模型到优化配置的关键步骤。本地部署不仅规避了服务器拥堵风险,还能充分利用硬件资源实现高效推理。对于开发者,可进一步参考 DeepSeek 官方 GitHub 文档,探索模型微调与二次开发的可能性。
附录:
- Ollama 官方文档:https://ollama.ai/docs/
- DeepSeek 官方 GitHub:DeepSeek · GitHub
- Chatbox 官方支持:https://chatboxai.app/support
希望这份扩展后的教程能够帮助您顺利完成 DeepSeek 的本地部署,并在实际应用中发挥其强大的功能!
转载吱一声~~~

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 32
32 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)