告别代码,Data Formulator 用 DeepSeek.V3 实现智能绘图
本文将介绍一款兼容AI的智能数据可视化工具——DataFormulator,它既支持通过AI提示生成图表,也支持传统的拖拽操作,完全无需编写代码,极大地降低了数据可视化的门槛。文章首先会讲解DataFormulator的安装和启动方法,接着详细介绍如何配置并使用国产大模型DeepSeek.V3的接入。随后,基于ElectricVehiclePopulation数据集,演示DataFormulato
本文将介绍一款兼容AI的智能数据可视化工具——Data Formulator,它既支持通过AI提示生成图表,也支持传统的拖拽操作,完全无需编写代码,极大地降低了数据可视化的门槛。文章首先会讲解Data Formulator的安装和启动方法,接着详细介绍如何配置并使用国产大模型DeepSeek.V3的接入。
随后,基于Electric Vehicle Population数据集,演示Data Formulator的基本使用方法,包括如何通过AI提示和拖拽操作快速生成可视化图表。最后,文章将对Data Formulator的功能和体验进行总结与评价,帮助读者更好地了解这款工具的优势与适用场景。
1 . Data Formulator介绍
为了让数据可视化设计变得更简单、更高效,微软雷德蒙研究院的研究员们开发了一款超实用的AI 工具——Data Formulator,并且把它开源放在了 GitHub 上。这款工具巧妙地结合了图形化用户界面(就是咱们熟悉的点选、拖拽操作)和自然语言输入(比如直接打字告诉它你的需求),让用户能更轻松地向 AI 传达自己的想法。这样一来,无论是调整图表样式还是更新数据,AI 都能精准理解你的意图,一步步帮你完成复杂的可视化设计。简单来说,Data Formulator 就像是一个懂设计又懂数据的智能助手,让数据可视化变得既高效又省心!
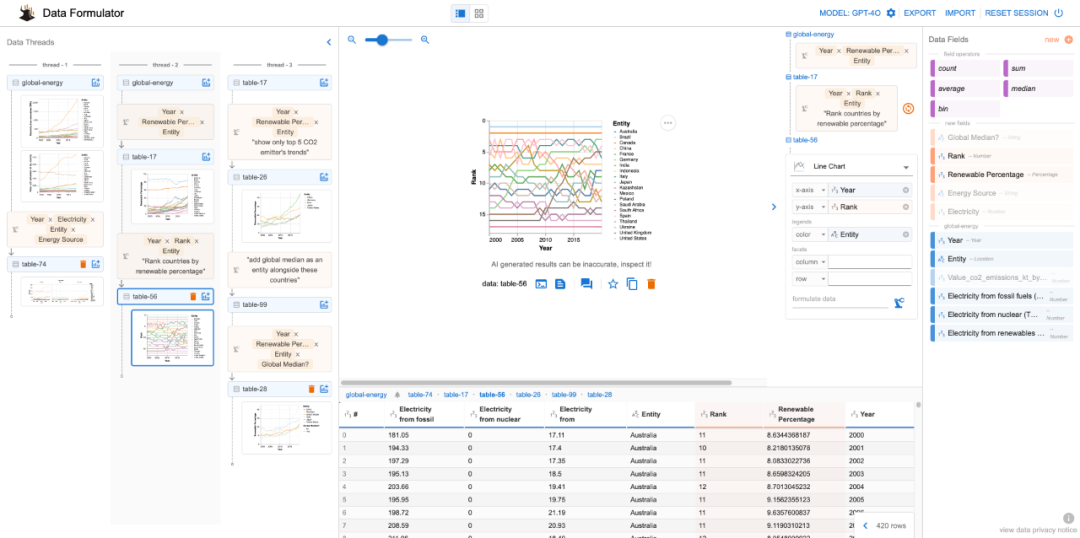
Data Formulator的核心功能是帮我们更快、更轻松地把数据变成直观的图表。它背后用到了强大的语言模型,可以自动处理复杂的数据转换工作,让我们不用再为数据整理头疼,直接专注于图表的设计和分析。
和很多需要靠“打字聊天”来操作的 AI 工具不同,Data Formulator 的设计更贴心。它既支持传统的界面操作(比如点选、拖拽),也支持用自然语言输入指令(比如直接告诉它“帮我做个柱状图”)。这样一来,不管你是喜欢动手操作,还是更习惯用语言表达需求,都能轻松上手。这种“双管齐下”的方式,不仅让图表设计变得更简单,还能让 AI 帮你搞定繁琐的数据处理,效率直接拉满!
在使用时,首先,输入你的 OpenAI 密钥,然后选择一个模型(推荐用 GPT-4o,效果更好),再挑一个你需要分析的数据集。(我们后面会演示如何连接DeepSeek.V3模型)
接下来,选一个你想要的图表类型,比如柱状图、折线图之类的。然后,直接把数据字段拖拽到图表的属性里,比如 x 轴、y 轴或者颜色这些地方,就能快速定义图表的样子了。
整个过程就像搭积木一样简单,不需要复杂的操作,Data Formulator 会帮你把数据变成一目了然的图表,让你更专注于分析和决策!
想要创建一些超出初始数据集的可视化图表?没问题,Data Formulator 的 AI 功能(🤖)可以帮你轻松搞定!具体操作很简单:
1. 输入新字段名称:在编码栏里,你可以输入当前数据中没有的字段名称。这相当于告诉 Data Formulator,你希望基于现有数据做一些计算或转换,生成新的可视化内容。
2. 用自然语言补充说明(可选):如果你觉得字段名称还不够清晰,可以用自然语言进一步解释你的需求。当然,如果字段名称已经很直白了,这一步可以跳过。
3. 点击“Formulate”按钮:接下来,Data Formulator 会根据你的输入,自动转换数据并生成对应的可视化图表。
4. 检查结果:生成图表后,你可以仔细查看数据、图表效果以及背后的代码,确保一切符合你的预期。
5. 基于现有图表继续操作:如果想在现有图表的基础上做进一步调整,直接用自然语言告诉它就行!比如,输入“仅显示前5个!”,它就会帮你筛选出前5条数据。你也可以根据需要调整图表的视觉编码,让图表更贴合你的需求。
整个过程就像和一个懂数据的助手对话一样,简单又高效!
你可以根据需求反复使用这个流程,一步步深入挖掘和分析你的数据。每一次的操作和探索都会被自动记录在“数据线程”面板里,就像一条清晰的路径一样,方便你随时查看之前的步骤,或者回溯到某个关键点。这样一来,无论是调整思路还是分享分析过程,都变得特别轻松!
2. 如何安装
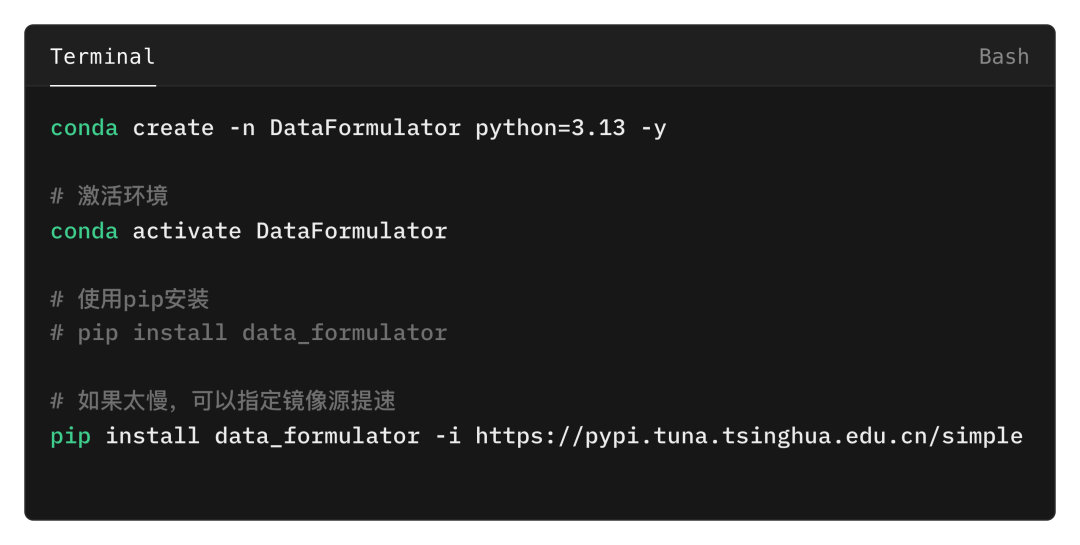
使用conda命令创建DataFormulator虚拟环境,并激活,然后使用pip进行安装
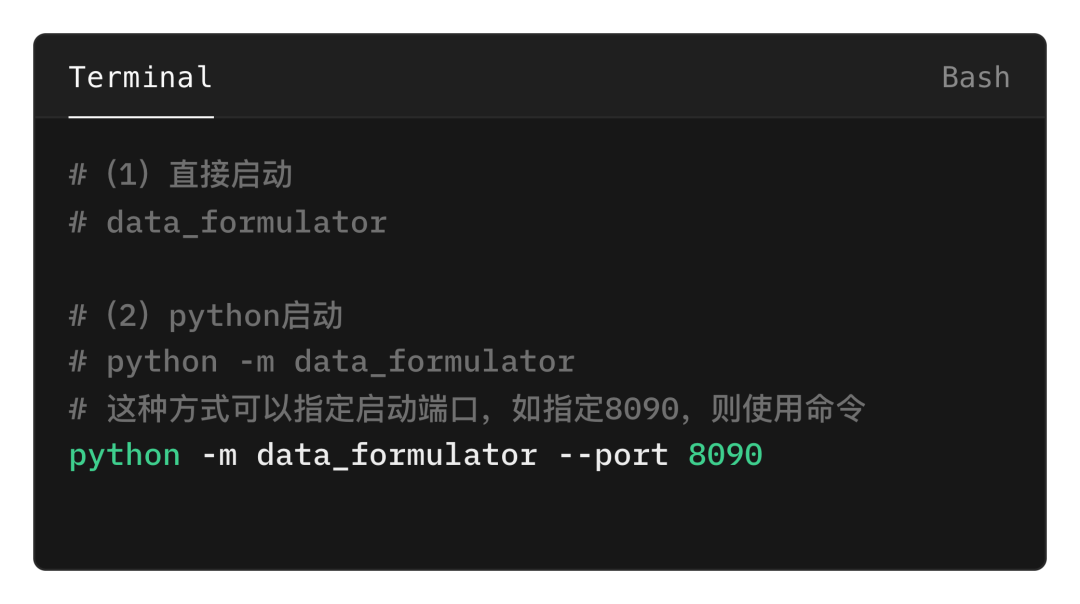
安装成功后,按如下方式进行启动
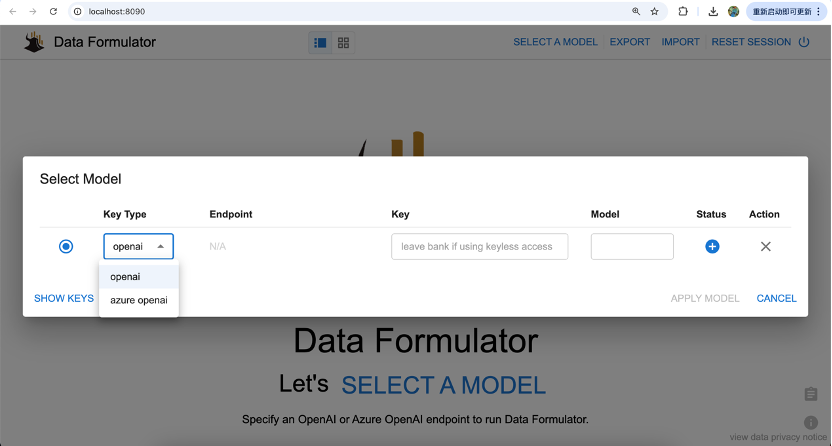
执行后,自动打开如下界面:

点击“SELECT A MODEL”处,出现的大模型下拉框,仅支持 OpenAI和Azure OpenAI,如下图所示
既然支持了openai,那么兼容openai的API接口的模型也就能支持了,包括通义千问、智谱清言、百川等,这里主要介绍DeepSeek.V3的配置方法。但是认真看了一下,Endpoint并不能修改,只能修改Key和Model,那该怎么搞?
3 . 如何使用DeepSeek.V3大模型?
找遍官方文档 ,也没有地方介绍,如何配置国产大模型呢?就只有从源码入手,通过执行如下命令,找到DataFormulator安装库代码位置
进入目录,然后,使用Visual Studio Code打开 data_formulator目录,命令
可以看到界面
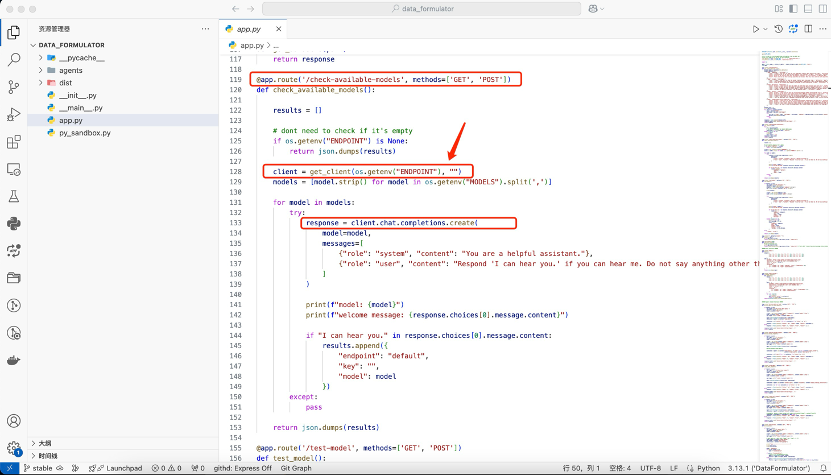
打开app.py文件,可以看到,这是一个基于Flask框架的web应用。我们要尝试去找到openai库的引用地方,在119行,这是一个检查模型是否可用的路由,所图:
点击进入 get_client方法,如下图
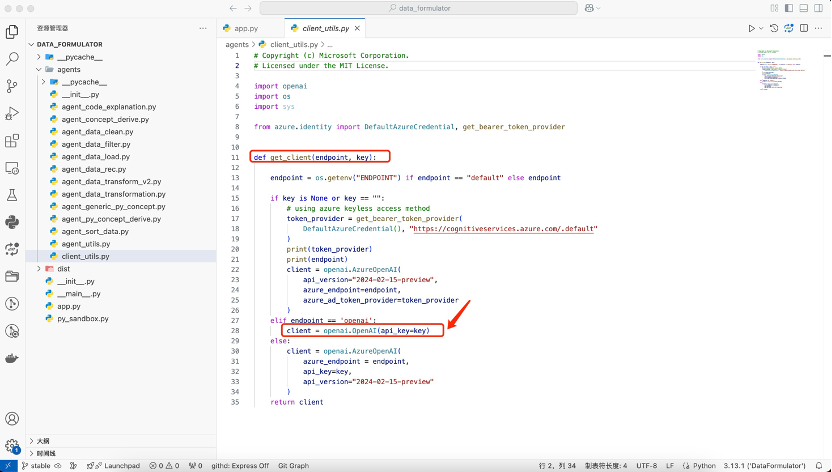
我们看到第28行,当设置endpoint为openai时,会调用openai的接口,我们进去看一下
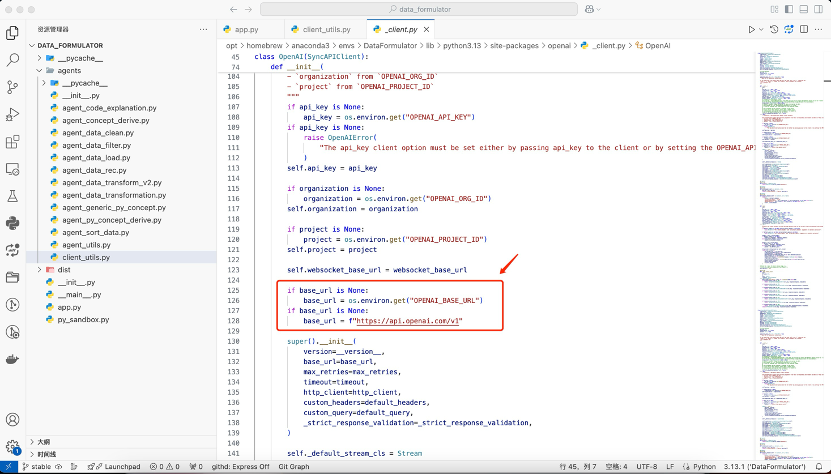
在126行,我们看到,这里会从环境变量里面去拿base_url,如果我们把base_url设置为deepseek.V3的入口地址,那是不是可以在界面上配置使用DeepSeek.V3大模型了呢?
让我们试一下!
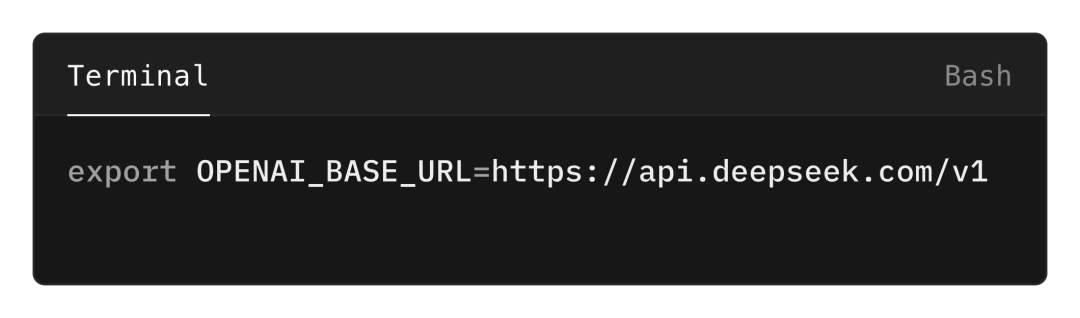
首先,设置环境变量 OPENAI_BASE_URL
然后,通过命令 python -m data_formulator --port 8090 启动Data Formulator
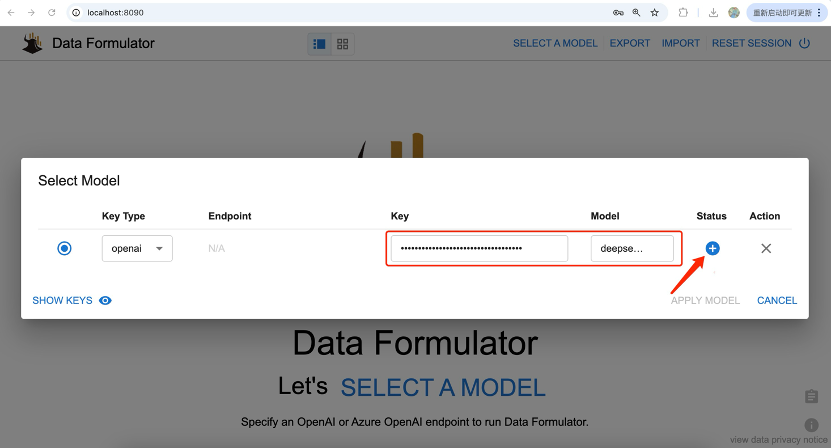
在如下界面中,设置Key和Model,点击Status处的+号,检验模型可用性。看到这时,如果你不知道如何获取Key,可以参考这两篇文章
OpenAI库牵手国产大模型,一键解锁!超全参数配置秘籍来袭
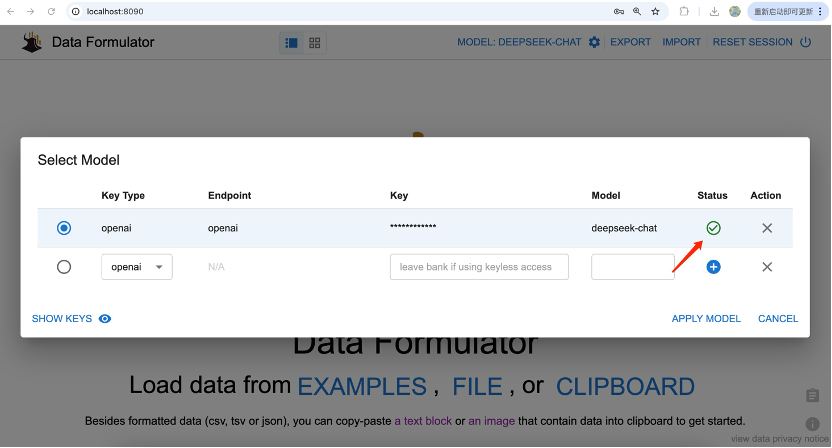
很明显,我们配置的模型可用了,点击Apply Model。到此,完成配置DeepSeek.V3的接入,其它国产大模型(凡支持openai兼容API接口的)都可以。
4 . 使用案例
Data Formulator支持两种导入数据的方式:
(1)数据文件上传。
(2)复制剪贴板
下面,我们将使用Electric Vehicle Population数据集,来介绍Data Formulator工具的使用案例。该数据集提供了关于各地区和不同时间段的电动汽车(EV)人口的全面信息。它包含了与车辆注册、清洁替代燃料车辆计划资格、电动续航里程和价格相关的各种测量数据。数据涵盖多个州和车辆品牌,为电动汽车市场及其发展提供了广泛的视角。
📊 数据列:
·州(State):车辆注册所在的美国州。
·车型年份(Model Year):车辆型号的制造年份。
·品牌(Make):车辆的制造商,例如:
o TESLA
o BMW
o CHEVROLET
o VOLKSWAGEN
o RIVIAN
o TOYOTA
o NISSAN
…(以及其他品牌)
·电动汽车类型(Electric Vehicle Type):电动汽车的类型,分类为:
o 纯电动汽车(Battery Electric Vehicle, BEV)
o 插电式混合动力汽车(Plug-in Hybrid Electric Vehicle, PHEV)
·电动续航里程(Electric Range):车辆仅靠电力驱动的续航里程,单位为英里。
·基础建议零售价(Base MSRP):车辆的建议零售价(MSRP)。
·立法区(Legislative District):与车辆注册地点相关的立法区。
·CAFV资格简化(CAFV Eligibility Simple):车辆是否符合清洁替代燃料车辆(CAFV)计划的简化指标。可能的值包括:
o 符合清洁替代燃料车辆资格
o 由于未研究的电池范围,资格未知
o 由于电池范围不足,不符合资格
🔍 使用场景:
该数据集非常适合分析电动汽车在不同州的采用和分布情况,重点关注地理和立法细节。它有助于理解电动汽车市场的趋势、评估定价以及分析替代燃料车辆激励政策的可及性。该数据集还可用于预测建模,帮助基于地理、人口统计和立法因素预测电动汽车的增长和普及情况。
我们首先,将EV_Population.csv文件上传至Data Formulator页面
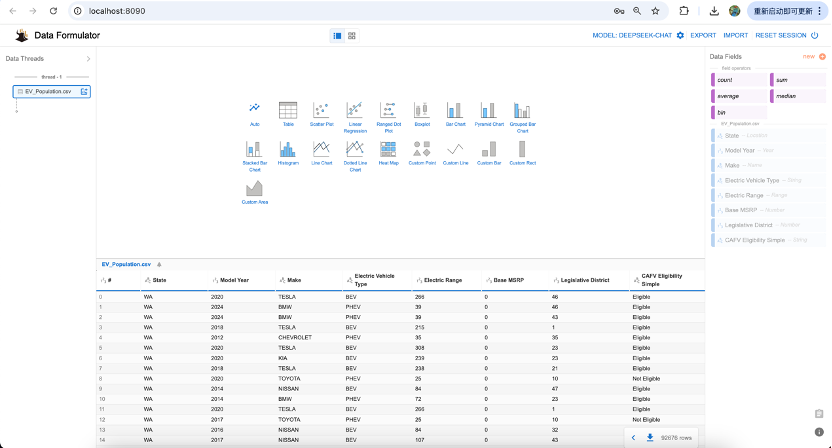
然后,我们点击第一个图标Auto,来问一个问题,“统计前10大品牌的汽车数量”
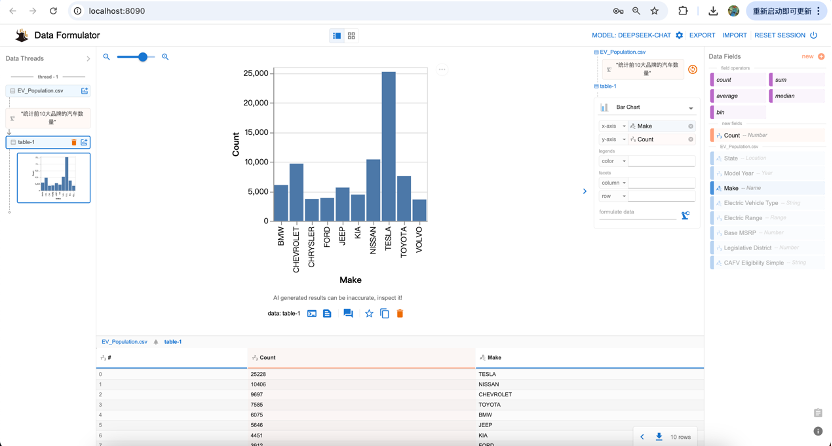
可以看到,界面上不仅自动绘制出了图形,下方来出现了对应的数据,我们可以基于这个数据继续提问“按电动汽车类型分类显示”
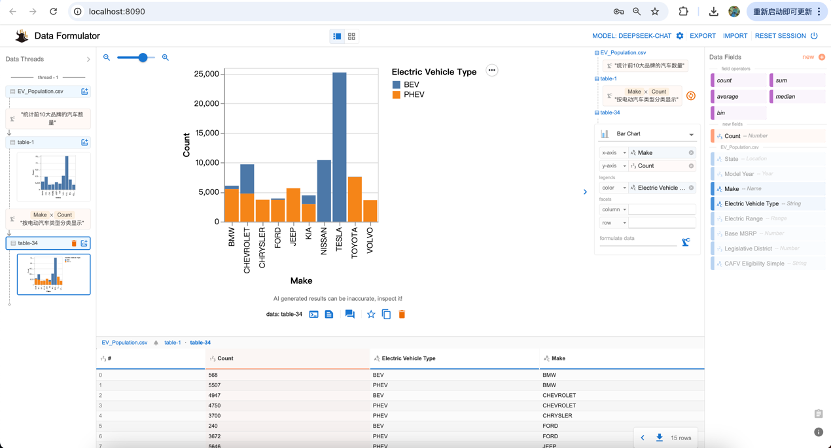
可以看到,在前一个基础上,又新增了一个图形,同时,下方又出现了一个新表,这个表格里面新增了一个电动汽车类型字段。
我们也可以重新问一下问题,“统计下汽车里程的数量分布”,可以看到
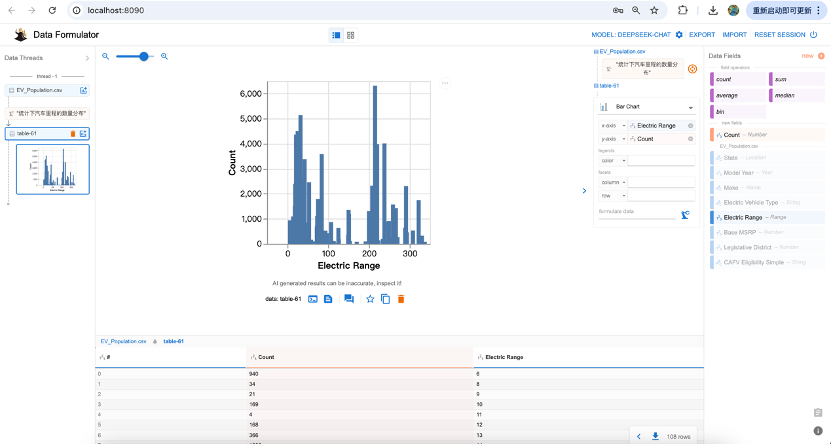
若进一步想了解,不同电动汽车类型,里程上的差异,可以追问“按电动汽车类型分类”,如图
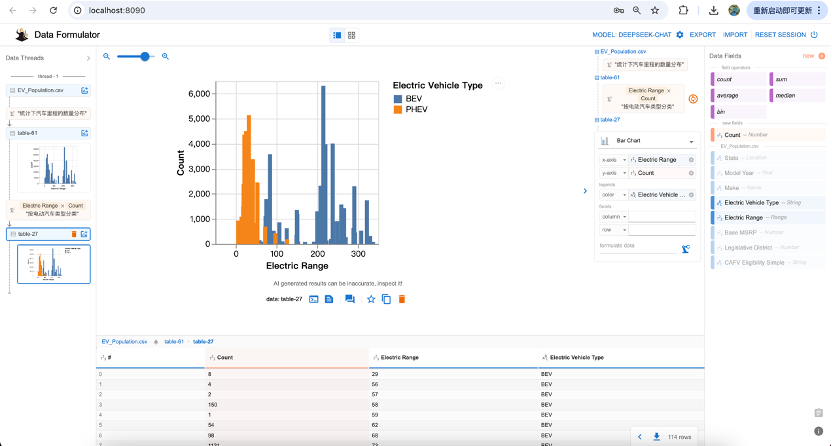
可见,插电式混动汽车,里程比纯电动汽车电动续航里程要少。我们还可以增加筛选条件,如“只显示特斯拉的汽车”所图
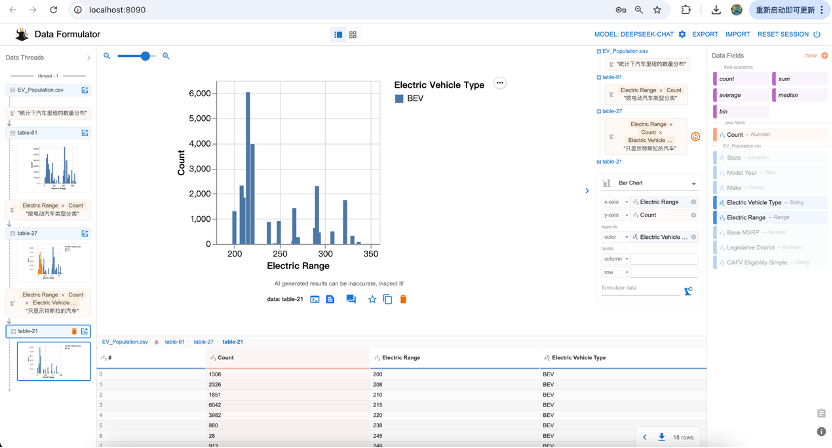
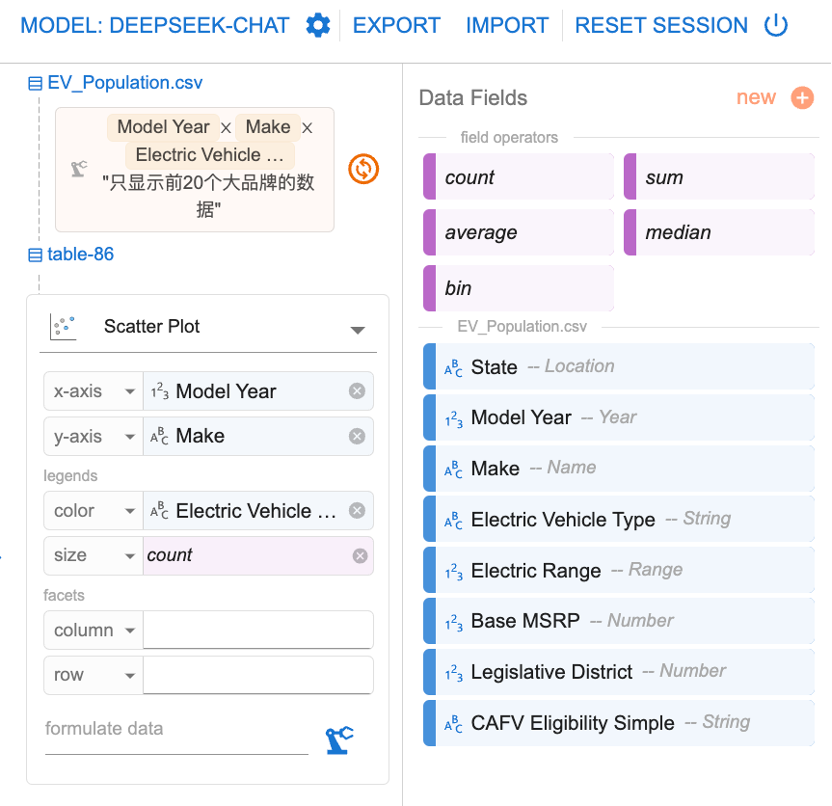
除了这种,通过自然语言提示大模型绘图的功能之外,我们还可以自己通过拖拉拽的方式来绘制图形。如下图所示:
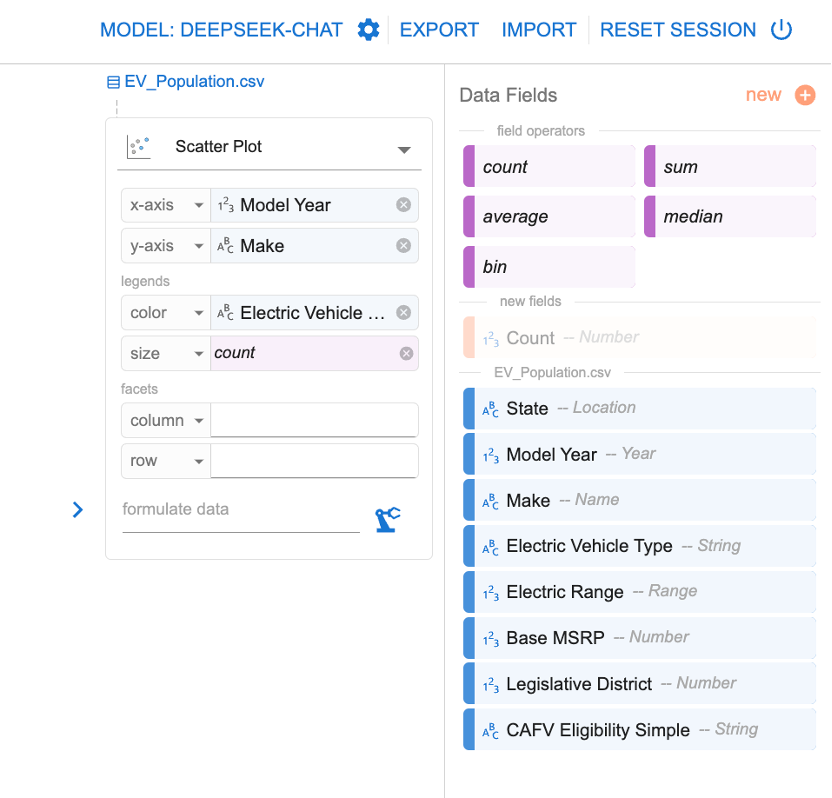
通过如上设置,我们得到自定义图表:
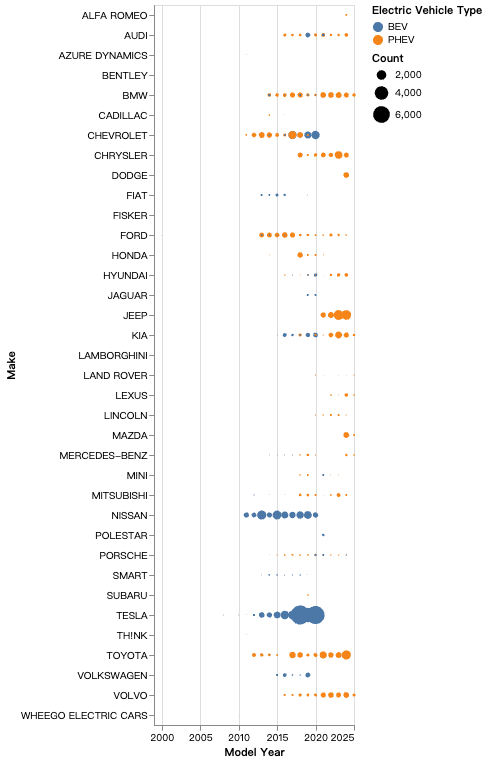
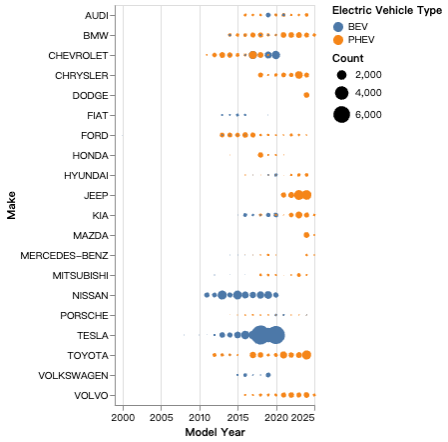
该图按年份,展示了逐年各汽车品牌生产汽车数量的变化。如果觉得品牌太多,我们可以进行提示“只显示前20个大品牌的数据”,得到图:
以下是具体效果:
5 . 总结与评价
1、 无代码使用,可以用来绘制图表,放到报告或PPT中都挺实用
2、 后台基于Python,能支持较大数据,相比数据一大,excel就弄卡死的情况会好很多
3、 可通过上传或剪贴板复制数据的方式导入数据
4、 目前所支持的图表,还是比较有限,对图表的细粒度控制还有优化空间

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 39
39 0
0- 0



 已为社区贡献79条内容
已为社区贡献79条内容

所有评论(0)