
DeepSeek打造您人生中的第一个一百万
最近DeepSeek可以说的超级火,不仅仅是IT圈,在教育圈,医疗圈,甚至是娱乐圈都是火爆了。趁着这波热度很多人默默的卖课,卖教程甚至于骗点击流量,大大的挣了一波。这个时候试问屏幕前的您,眼红了没有。不要急,今天小编便教教大家如何通过DeepSeek打造人生中的第一个一百万
简介
最近DeepSeek可以说的超级火,不仅仅是IT圈,在教育圈,医疗圈,甚至是娱乐圈都是火爆了。趁着这波热度很多人默默的卖课,卖教程甚至于骗点击流量,大大的挣了一波。这个时候试问屏幕前的您,眼红了没有。不要急,今天小编便教教大家如何通过DeepSeek打造人生中的第一个一百万(百试百灵,包教包会)。
工欲善其事,必先利其器
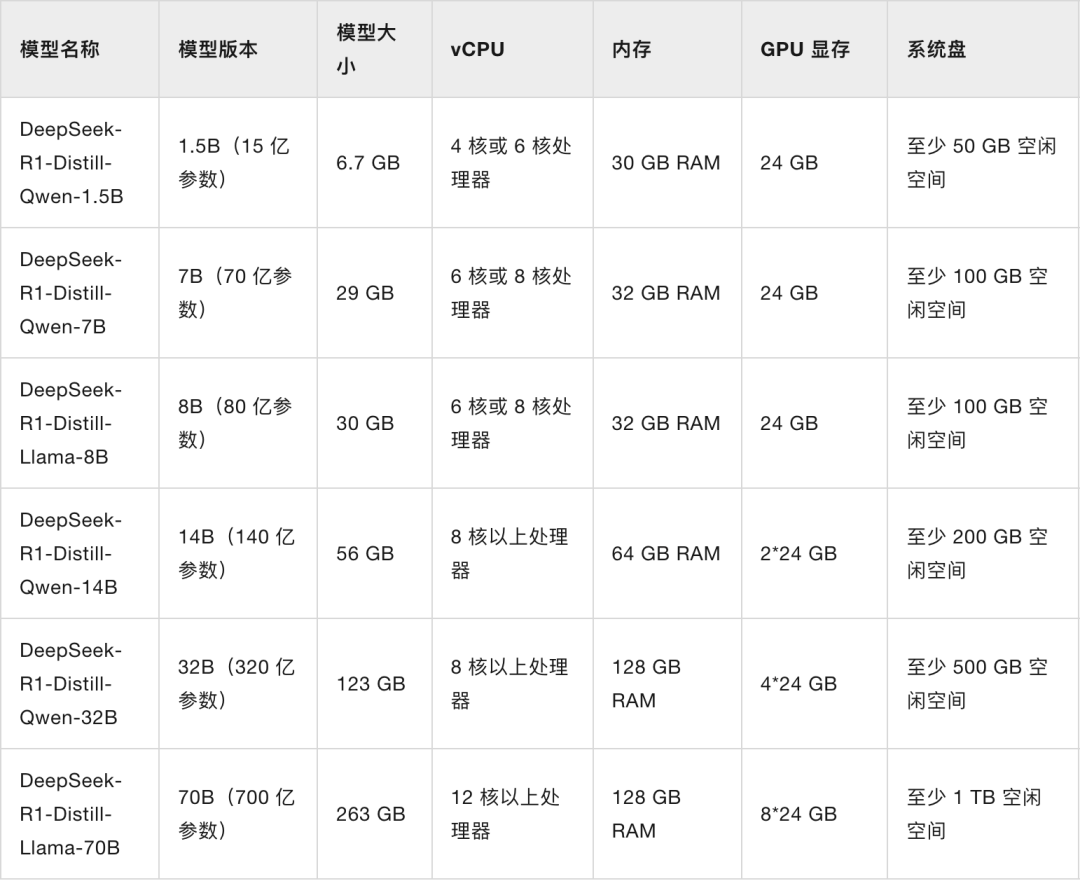
你说你都要赚一百万的人了,那搞个好点的设备不过分吧。实测挣的多少与设备的性能成正比哈。不开玩笑了,本文就是教您打造DeepSeek R1的本地部署。具体的配置推荐如下:
| DeepSeek版本 | 笔记本内存 | CPU | GPU情况 |
|---|---|---|---|
| 1.5B | 16G | i5 CPU | 无GPU 2-3并发可流畅运行 |
| 7B | 32G | 推荐i7 CPU | 无GPU 2-3并发可流畅运行 |
| 8B | 32G | 推荐Ultra 7 CPU | 无GPU 2-3并发可流畅运行 |
条条大路通罗马 Ollama(模型管理) + AnythingLLM/Dify/Open-WebUI/ChatBox(前端功能扩展)
准备好机器之后剩下的就是抵达罗马的大道,本文会介绍并带着大家安装以Ollama为基准的各种DeepSeek环境。对于想要在本地或自托管环境中运行 LLM 的用户而言,Ollama 提供了一个无需 GPU、在 CPU 环境也可高 效完成推理的轻量化 “本地推理” 方案。而要让 Ollama 真正 “接地气”,往往需要与其他开源项目进行配合 ——例如将文档、数据源或应用前端与 Ollama 打通,这便衍生出许多解决方案。
Ollama 简介
在进入对比之前,先简单回顾一下 Ollama 的定位和特性:
- 本地推理: CPU 即可运行:适合 Mac 或 Linux 环境。 若无 GPU 的情况下,也能让开源模型(如 Deepseek、LLaMA、GPT-Neo、Mistral 等)跑起来。
- 轻量易用: 安装方式简洁,一键下载二进制文件或通过 Homebrew、pkg 安装。 只需一个命令行工具就能加载模型并进行对话、推理。
- 量化优化: 支持对常见大语言模型做 4-bit 或 8-bit 等量化,进一步降低资源占用。
- 发展活跃: 在 GitHub 上有不错的社区支持和更新节奏,适合初中级开发者快速上手
那如何安装Ollama呢?
很简单,首先进入Ollama的官网 点击此链接 Ollama 如下图

点击Download就能进入如下页面

注意C盘的磁盘使用率最好大于12GB,下载完毕直接点击安装即可。
下面是一些ollama参数和配置标识,不感兴趣的童靴直接跳过即可。
| 参数 | 标识与配置 |
|---|---|
| OLLAMA_MODELS | 表示模型文件的存放目录,默认目录为当前用户目录即 C:\Users%username%.ollama/models Windows系统建议不要放在C盘,可放在其他盘(D:\ollama\models) |
| OLLAMA_HOST | 表示ollama服务监听的网络地址,默认为127.0.0.1 如果想要允许其他电脑访问Ollama(如局域网中的其他电脑),建议设置成0.0.0.0 |
| OLLAMA_POST | 标识ollama服务监听的默认端口,默认为11434 如果端口有冲突,可以修改设置成其他端口(如8080等) |
| OLLAMA_ORIGINS | 标识HTTP客户端请求来源,使用半角逗号分割列表 如果本地使用不受限制,可以设置成星号* |
| OLLAMA_KEEP_ALIVE | 标识大模型加载到内存中后的存活时间,默认为5m即5分钟(如纯数字300代表300秒,0代表处理请求响应后立即卸载模型,任何负数则表示一直存活) 建议设置成24h,即模型在内存中保持24小时,提高访问速度 |
| OLLAMA_NUM_PARALLEL | 表示请求处理的并发数量,默认为1(即单并发串行处理请求) |
| OLLAMA_MAX_QUEUE | 表示请求队列长度,默认值为512 建议按照实际需求进行调整,超过队列长度的请求会被抛弃 |
| OLLAMA_DEBUG | 表示输出Debug日志,应用压法阶段可以设置成1(即输出详细日志信息,便于排查问题) |
| OLLAMA_MAX_LOADED_MODELS | 表示最多同时加载到内存中模型的数量,默认为1(即只能由1个模型在内存中) |
拉取模型(联网) 下载后可拷贝Models目录下两个文件夹到其它离线、跨平台设备中
windows打开powershell
需要获取哪个版本可以在deepseek-r1查看
ollama run deepseek-r1:8b
ollama拉取deepseek
拉取完毕后,即可断网进行沟通,如下

deepseek8b 自我介绍
AnythingLLM、Dify、Open-WebUI、ChatBox简介
AnythingLLM
定位:将本地文档或数据源整合进一个可检索、可对话的知识库,让 AI 助手 “懂你” 的资料。
主要功能:
- 文档管理:将 PDF、Markdown、Word 等多格式文件索引进系统。
- 智能检索:可基于向量数据库搜索相关文档片段,并在聊天时自动引用。
- 界面 +API:既提供用户友好的前端管理界面,也能通过 API 与其他系统集成。
对接 Ollama 思路:
- 在配置文件或启动脚本中,将 “语言模型推理” 后端地址指定为 Ollama 的本地服务。
- 当用户发起提问时,AnythingLLM 会先做知识检索,再将检索到的上下文发送给 Ollama 做语言生成。
适用场景:
- 企业内部文档问答、个人知识管理、高度依赖文本内容的问答场景。
Dify
定位:多功能的 AI 应用构建平台,支持多种大语言模型,方便开发者快速搭建 ChatGPT-like 服务或插件化应用。
主要功能:
- 对话管理:可自定义对话流或应用场景,为不同场景配置不同模型或工作流。
- 插件扩展:支持将其他第三方服务或插件加入对话流程中,提高可用性。
- 多模型兼容:除 Ollama 外,也兼容 OpenAI API、ChatGLM 等其他模型。
对接 Ollama 思路:
- 在 “模型管理” 或 “模型配置” 界面/文件中,添加对 Ollama 的引用,可能需要指定本地运行地址 (如 localhost:port)。
- 使用 Dify 的对话页面或 API 时,后台调用 Ollama 进行推理,再将结果返回前端。
适用场景:
- 多模型切换、多功能插件集成;需要可视化对话配置或工作流管理的团队与开发者。
Open-WebUI
定位:社区驱动的网页版用户界面,针对多种本地模型提供可视化使用入口,类似一个 “本地 ChatGPT 面板”。
主要功能:
- 浏览器聊天界面:在局域网或本机通过网页即可与模型交互。
- 支持多后端:LLaMA、GPT-NeoX 等,以及 CPU/GPU 等不同推理环境。
- 插件/扩展机制:在社区里可找到各式各样的扩展功能(如多语言 UI、模型切换、对话模板等)。
对接 Ollama 思路:
- 通常可在 Open-WebUI 的后台配置或启动脚本中,指定 Ollama 作为推理后端;
- 或使用适配 Ollama 协议的插件,让 Open-WebUI 调用 Ollama 进行对话。
适用场景:
- 需要 “纯聊天 + 模型管理” 界面的普通用户或开发者;
- 想要单纯体验各种本地模型的人群。
Chatbox
定位:一款 AI 客户端应用和智能助手,支持众多先进的 AI 模型和 API,可在 Windows、MacOS、Android、iOS、Linux 和网页版上使用。
主要功能:
- 浏览器聊天界面:在局域网或本机通过网页即可与模型交互。
- 兼容多模型本地化使用,无论是脚本编写,图像绘制,游戏,还是旅行计划均可以在该客户端配置。
对接ollama思路:
- 通常在Chatbox设置的模型中选择OLLAMA API模型即可
适用场景:
- 需要 “纯聊天 + 模型管理” 界面的普通用户或开发者;
- 想要单纯体验各种本地模型的人群。
推荐使用Chatbox,该客户端功能丰富。下面将介绍Chatbox安装
Chatbox安装
下载地址
Chatbox AI官网:办公学习的AI好助手,全平台AI客户端,官方免费下载
直接双击安装即可,安装完毕后,如下进行配置:

配置完毕后即可聊天。
最后献上以上的几个客户端的优缺点比较。

优缺点比较图
希望大家能通过DeepSeek赚上第一个人生一百万,有问题直接评论打上666,绝对有惊喜哈。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)