DeepSeek-llm-7B-Chat微调教程
高性价比:DeepSeek-V2模型以其史无前例的性价比著称,推理成本被降到每百万token仅1块钱,约等于Llama3 70B的七分之一,GPT-4 Turbo的七十分之一。架构创新:DeepSeek对模型架构进行了全方位创新,提出崭新的MLA(一种新的多头潜在注意力机制)架构,把显存占用降到了过去最常用的MHA架构的5%-13%,同时,独创的DeepSeekMoESparse结构,也把计算量降
前言
DeepSeek系列大模型由杭州深度求索人工智能基础技术研究有限公司提供,该系列大模型有以下这些优势:
- 高性价比:DeepSeek-V2模型以其史无前例的性价比著称,推理成本被降到每百万token仅1块钱,约等于Llama3 70B的七分之一,GPT-4 Turbo的七十分之一。
- 架构创新:DeepSeek对模型架构进行了全方位创新,提出崭新的MLA(一种新的多头潜在注意力机制)架构,把显存占用降到了过去最常用的MHA架构的5%-13%,同时,独创的DeepSeekMoESparse结构,也把计算量降到极致。
- 开源模型:DeepSeek的模型全部开源,包括通用大模型DeepSeek LLM、MoE模型DeepSeek MoE、DeepSeek V2等,方便用户进行二次开发和优化。
- 性能强劲:DeepSeek-V2包含236B总参数,其中每个token激活21B,支持128K tokens的上下文长度,在性能上比肩GPT-4 Turbo。
本文针对其llm-7B-Chat模型进行微调,希望其回复内容可以更加人性化。
DeepSeek-LLM系列有多个大模型,这里希望通过教程让大家能完成完整的微调流程,碍于设备以及各类资源限制,这里使用7B大小的模型来完成本文的实验,还有67B的模型,如果有兴趣的小伙伴可以尝试,不过模型比较大,对显存的要求较高,可以根据自身条件选择。

关于数据集的选择方面,本次教程我想让大模型回复的更亲切点,在最开始推理的时候,发现虽然chat模型回答的非常不错,但是有点套路的感觉,

于是去网上寻找数据集,然后从EmoLLM这个项目里发现了很多现成的数据集,他们的数据集由智谱清言、文心一言、通义千问、讯飞星火等大模型生成,如果有其他需要可以参考EmoLLM数据生成方式来构建自己的数据集,这里我使用了其中单轮对话数据集来进行微调。
链接资料
-
代码链接:swanhub
-
实验日志过程:DeepSeek-7B-Chat-finetune-SwaLab
-
模型下载地址:huggingface
-
数据集:single-conversation
-
可视化工具SwanLab使用文档:SwanLab官方文档 | 先进的AI团队协作与模型创新引擎
可视化工具介绍
SwanLab是一款完全开源免费的机器学习日志跟踪与实验管理工具,为人工智能研究者打造。有以下特点:
1、基于一个名为swanlab的python库
2、可以帮助您在机器学习实验中记录超参数、训练日志和可视化结果
3、能够自动记录logging、系统硬件、环境配置(如用了什么型号的显卡、Python版本是多少等等)
4、同时可以完全离线运行,在完全内网环境下也可使用
如果想要快速入门,请参考以下文档链接:
-
SwanLab官方文档 | 先进的AI团队协作与模型创新引擎
-
SwanLab快速入门指南
Lora简单介绍
LoRA(Low-Rank Adaptation)是一种针对大型语言模型的微调技术,旨在降低微调过程中的计算和内存需求。其核心思想是通过引入低秩矩阵来近似原始模型的全秩矩阵,从而减少参数数量和计算复杂度。
在LoRA中,原始模型的全秩矩阵被分解为低秩矩阵的乘积。具体来说,对于一个全秩矩阵W,LoRA将其分解为两个低秩矩阵A和B的乘积,即W ≈ A * B。其中,A和B的秩远小于W的秩,从而显著减少了参数数量。
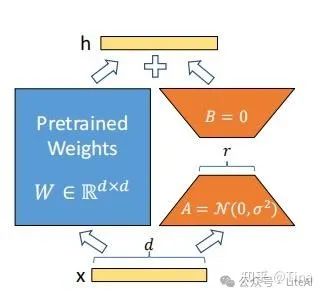
在微调过程中,LoRA只对低秩矩阵A和B进行更新,而保持原始模型的全秩矩阵W不变。比如在本文微调代码里我们可以直接计算训练参数占比,代码如下:
model.print_trainable_parameters()
然后当设置lora_rank=16,lora_alpha=32时,训练参数占比如下:
trainable params: 37,478,400 || all params: 6,947,844,096 || trainable%: 0.5394
可以看到总参数量是7B,但是训练的时候只有不到一半的参数参与微调,这样,微调过程只需要优化较少的参数,从而降低了计算和内存需求。同时,由于低秩矩阵的结构特点,LoRA能够保持原始模型的性能,避免过拟合现象。
LoRA的另一个优点是易于实现和部署。由于LoRA只对低秩矩阵进行更新,因此可以很容易地集成到现有的训练框架中。此外,LoRA还可以与其他微调技术相结合,进一步提高微调效果。
总之,LoRA是一种有效的微调技术,通过引入低秩矩阵来降低微调过程中的计算和内存需求,同时保持原始模型的性能。这使得LoRA成为一种适用于大型语言模型的微调方法,具有广泛的应用前景。
显存要求
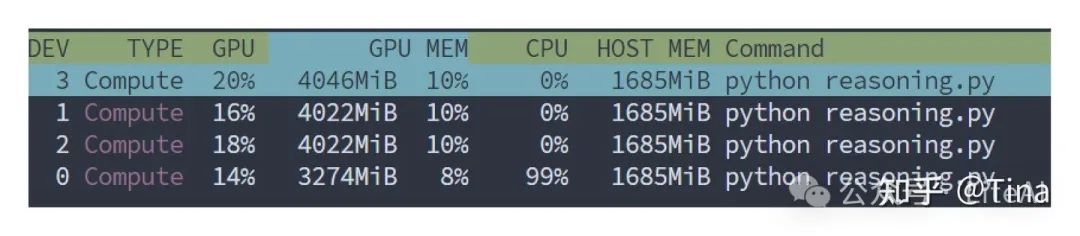
max_seq_len=2048时训练与推理所需要的显存只有15GB左右,一块3090就可以跑
具体的显卡数据可以参考我另外一篇文章,统计了大家熟悉的显卡的数据。
参考资料:最全深度学习算法显卡参数统计
推理时需要的显存数据:
微调代码
1、环境设置
本文代码python=3.10,请设置环境python>=3.9即可。
由于本次使用的模型较大,请确保此次微调显存至少有15GB.
我们需要安装以下这几个Python库,在这之前,请确保你的环境内已安装了pytorch以及CUDA:
torch
transformers
accelerate
peft
bitsandbytes
swanlab
2、准备模型和数据集
DeepSeek模型是一系列基于Transformer架构的深度神经网络模型,它们在不同的时间点针对不同的应用场景被开发和优化。以下是DeepSeek模型的时间顺序介绍,包括它们针对的场景、用途和优势:
1、DeepSeek-V2(非常大,没有一定资源不建议微调):
DeepSeek-V2是一个千亿级模型,参数量达到236B,其中激活参数为21B。它在中文综合能力、英文综合能力、知识、数学、推理、编程等榜单中均表现出色。可以应用于智能对话、文本生成、语义理解、计算推理等场景。
2、DeepSeek-Prover:
这是一个70亿参数的开源模型,通过结合强化学习和蒙特卡洛树搜索,显著提升了证明生成的效率和准确性。主要用于形式定理证明。
3、DeepSeek-VL:
DeepSeek-VL是一个开源的大型多模态模型,用于处理结合视觉和语言的复杂真实世界场景的任务,如理解现实世界中的多种类型数据,例如代码、图表等。
4、DeepSeek-Coder:
DeepSeek-Coder-V2是一个开源的混合专家 (MoE) 代码语言模型,在代码特定任务中实现了与 GPT4-Turbo 相当的性能。
5、Deepseek-LLM:
Deepseek-LLM是一个开源的对话模型,比较适合llm微调,可以进行基础的多轮对话。
这里选择LLM-chat版本,使用单轮对话数据集来微调,
模型下载地址Huggingface:huggingface
数据集下载地址:EmoLLM
3、处理数据
①.参与训练的数据集格式
参与训练的数据集格式以及后面的微调代码参考了几位大神的代码,本文只进行lora微调,单线程微调以及分布式训练方式都可以,其中分布式训练可以大幅度缩减训练时长,提高训练效率。
参考资料:
-
Firefly: 大模型训练工具
-
Qwen2大模型微调入门实战
参与训练的数据格式如下:
{"conversation_id": 1, "conversation": [{"human": "我为什么什么都做不好?\n来到岗位三个月了,每一次工作都紧张、慌乱,生怕做错了,忘记了什么重要的事,然而每次都会有这样那样的状况发生,我不想每天焦虑的工作,为什么什么都做不好!", "assistant": "其实不是做不好。\n事实上做不好,是因为把过多的精力放在担惊受怕上了,幻想充斥了你的头脑,就没有心思关注真正在手上的工作。\n人一旦不能活在当下,就会忽视掉身边的细节,而这些细节往往决定了事情的走向和结果。\n所以说,世界上很少有偶然的事情,所谓偶然只是我们还没有发现它的规律。\n你需要学习把注意力集中在当下,每天的正念练习也许有用。认真的呼吸20分钟吧,感受一下当下发生的事情。\n"}]}
如果想要快速入门,也可以直接使用下面的脚本对下载的数据集进行改造:
def data_process(data_path,output_path):
# 最终结果
all_results = []
with open(data_path, 'r', encoding='utf-8') as file:
data_json = json.load(file)
# 打开输出文件(JSONL格式)
with open(output_path, 'w', encoding='utf-8') as output_file:
# 处理数据
for i, data in enumerate(data_json):
# id号
conversation_id = i + 1
# 由于是单轮对话,因此不用循环
conversation = []
try:
human_text = data["prompt"]
assistant_text = data["completion"]
conversation_texts = {"human": human_text, "assistant": assistant_text}
conversation.append(conversation_texts)
except KeyError:
# 如果数据没有完整的“prompt”和“completion”字段,跳过
continue
result = {"conversation_id": conversation_id, "conversation": conversation}
all_results.append(result)
# 写入到输出文件中
with open(output_path, 'w', encoding='utf-8') as file:
for item in tqdm(all_results, desc="Writing to File"):
file.write(json.dumps(item, ensure_ascii=False) + '\n')
print(f"将 {len(data_json)} 条数据保存到{output_path}中")
②.数据预处理
下面这段代码是用于准备和处理自然语言处理任务中序列到序列(Seq2Seq)模型训练数据的流程。
data = pd.read_json(args.train_file, lines=True)
train_ds = Dataset.from_pandas(data)
train_dataset = train_ds.map(process_data, fn_kwargs={"tokenizer": tokenizer, "max_seq_length": 2048},remove_columns=train_ds.column_names)
data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True, return_tensors="pt")
-
使用pandas库的
read_json函数从指定的JSON文件(由args.train_file参数给出)中读取数据,其中lines=True参数表示文件中的每一行都是一个独立的JSON对象,这样读取后会得到一个DataFrame对象。 -
将这个DataFrame转换为Hugging Face的
Dataset对象,以便利用datasets库提供的功能进行进一步的数据操作。 -
通过
map函数应用一个预处理函数process_data到Dataset对象中的每个样本上,这个函数会对数据进行处理,比如使用tokenizer对文本进行编码,并且保证序列长度不超过max_seq_length(在这里是2048)。同时,remove_columns参数移除了原始数据集中的所有列,只保留处理后的数据。 -
创建了一个
DataCollatorForSeq2Seq对象,它的作用是在模型训练时对数据批次进行整理,包括使用tokenizer对文本进行编码、进行填充(padding)以确保批次中所有序列长度一致,以及指定返回的tensor类型为PyTorch的tensor(return_tensors="pt")。这样,最终得到的train_dataset是一个经过预处理、准备好用于训练的Dataset对象,而data_collator则是用于在训练过程中整理数据批次的工具。
结果如下:
Dataset({features:['input_ids','attention_mask','labels'],num_rows:32333})
DataCollatorForSeq2Seq(tokenizer=LlamaTokenizerFast(name_or_path='./model',vocab_size=100000,model_max_length=4096,is_fast=True,padding_side='left',truncation_side='right',special_tokens={'bos_token':'<|begin▁of▁sentence|>','eos_token':'<|end▁of▁sentence|>','pad_token':'<|end▁of▁sentence|>'},clean_up_tokenization_spaces=False),added_tokens_decoder={100000:AddedToken("<|begin▁of▁sentence|>",rstrip=False,lstrip=False,single_word=False,normalized=True,special=True),
100001:AddedToken("<|end▁of▁sentence|>",rstrip=False,lstrip=False,single_word=False,normalized=True,special=True),
100002:AddedToken("ø",rstrip=False,lstrip=False,single_word=False,normalized=True,special=False),
100003:AddedToken("ö",rstrip=False,lstrip=False,single_word=False,normalized=True,special=False),
100004:AddedToken("ú",rstrip=False,lstrip=False,single_word=False,normalized=True,special=False),
100005:AddedToken("ÿ",rstrip=False,lstrip=False,single_word=False,normalized=True,special=False),
100006:AddedToken("õ",rstrip=False,lstrip=False,single_word=False,normalized=True,special=False),
100007:AddedToken("÷",rstrip=False,lstrip=False,single_word=False,normalized=True,special=False),
100008:AddedToken("û",rstrip=False,lstrip=False,single_word=False,normalized=True,special=False),
100009:AddedToken("ý",rstrip=False,lstrip=False,single_word=False,normalized=True,special=False),
100010:AddedToken("À",rstrip=False,lstrip=False,single_word=False,normalized=True,special=False),
100011:AddedToken("ù",rstrip=False,lstrip=False,single_word=False,normalized=True,special=False),
100012:AddedToken("Á",rstrip=False,lstrip=False,single_word=False,normalized=True,special=False),
100013:AddedToken("þ",rstrip=False,lstrip=False,single_word=False,normalized=True,special=False),
100014:AddedToken("ü",rstrip=False,lstrip=False,single_word=False,normalized=True,special=False),},model=None,padding=True,max_length=None,pad_to_multiple_of=None,label_pad_token_id=-100,return_tensors='pt')
train_dataset格式如下:
Dataset({features:['input_ids','attention_mask','labels'],num_rows:32333})
由于如果要实现训练条件,现在数据集的格式其实仍然不符合条件,如果要实现大模型的生成任务,需要将输入部分mask遮掩起来,这样模型就能够学习如何根据输入生成输出。在 Seq2Seq 任务(如文本生成、机器翻译、摘要生成等)中,labels 被用来指导模型计算损失。在训练时,labels 是模型的“目标”输出,模型的目标是根据输入生成目标序列。在这一过程中,labels 中的部分 token 需要进行 mask(即忽略),而输出部分则应保持原token_ids,attention_mask是输入和输出对应的长度,剩下的部分是填充到max_seq_length,也就是表达的是有效长度的意思。那么原数据集到训练数据就需要一个函数来调整格式,也就是下面的process_data函数:
def process_data(data: dict, tokenizer, max_seq_length):
# 处理数据
conversation = data["conversation"]
input_ids, attention_mask, labels = [], [], []
for i, conv in enumerate(conversation):
human_text = conv["human"].strip()
assistant_text = conv["assistant"].strip()
input_text = "Human:" + human_text + "\n\nnAssistant:"
input_tokenizer = tokenizer(
input_text,
add_special_tokens=False,
truncation=True,
padding=False,
return_tensors=None,
)
output_tokenizer = tokenizer(
assistant_text,
add_special_tokens=False,
truncation=True,
padding=False,
return_tensors=None,
)
input_ids += (
input_tokenizer["input_ids"] + output_tokenizer["input_ids"] + [tokenizer.eos_token_id]
)
attention_mask += input_tokenizer["attention_mask"] + output_tokenizer["attention_mask"] + [1]
labels += ([-100] * len(input_tokenizer["input_ids"]) + output_tokenizer["input_ids"] + [tokenizer.eos_token_id]
)
if len(input_ids) > max_seq_length: # 做一个截断
input_ids = input_ids[:max_seq_length]
attention_mask = attention_mask[:max_seq_length]
labels = labels[:max_seq_length]
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
}
4、设置参数
微调模型时,需要设置多个重要参数。我将从六个方面来详细说明,包括:模型路径相关参数、数据集路径、训练超参数、LoRA特定参数、分布式训练参数以及硬件相关参数。
1、模型来源以及输出的模型地址
parser = argparse.ArgumentParser(description="LoRA fine-tuning for deepseek model")
# 模型路径相关参数
parser.add_argument("--model_name_or_path", type=str, default="./model",
help="Path to the model directory downloaded locally")
parser.add_argument("--output_dir", type=str,
default="your/output/path",
help="Directory to save the fine-tuned model and checkpoints")
2、使用对应格式的数据集的地址
# 数据集路径
parser.add_argument("--train_file", type=str, default="./data/single_datas.jsonl",
help="Path to the training data file in JSONL format")
3、设置微调的训练超参数
parser.add_argument("--num_train_epochs", type=int, default=2,
help="Number of training epochs")
parser.add_argument("--per_device_train_batch_size", type=int, default=1,
help="Batch size per device during training")
parser.add_argument("--gradient_accumulation_steps", type=int, default=16,
help="Number of updates steps to accumulate before performing a backward/update pass")
parser.add_argument("--learning_rate", type=float, default=2e-4,
help="Learning rate for the optimizer")
parser.add_argument("--max_seq_length", type=int, default=2048,
help="Maximum sequence length for the input")
parser.add_argument("--logging_steps", type=int, default=1,
help="Number of steps between logging metrics")
parser.add_argument("--save_steps", type=int, default=200,
help="Number of steps between saving checkpoints")
parser.add_argument("--save_total_limit", type=int, default=1,
help="Maximum number of checkpoints to keep")
parser.add_argument("--lr_scheduler_type", type=str, default="constant_with_warmup",
help="Type of learning rate scheduler")
parser.add_argument("--warmup_steps", type=int, default=100,
help="Number of warmup steps for learning rate scheduler")
–per_device_train_batch_size:每个设备上的训练批次大小。批次大小决定了每次训练时喂给模型的数据量。批次太小可能导致训练过程不稳定或效率低下,批次太大会增加显存占用,可能导致OOM(内存溢出)。
–gradient_accumulation_steps:梯度累计步数。global batch=num_gpus * per_device_train_batch_size * gradient_accumulation_steps。
-
如果该参数设置的太高的话,会导致梯度累积过多,从而影响模型的学习效率和稳定性,因为梯度是在多个小批量上累积的,而不是每个小批量更新一次,这会导致梯度估计的方差增加,影响模型的收敛性能;
-
另一方面,如果该参数设置的过低的话虽然可以减少梯度累积带来的方差,但相当于减小了有效批量大小,这可能会降低模型训练的效果,因为大批量训练通常能提供更稳定的梯度估计。
–learning_rate:学习率。学习率过高可能会引发梯度爆炸,导致数值溢出,影响模型稳定性。学习率过低则可能导致模型陷入局部最优解,而不是全局最优解。因此我们通常需要通过调参来找到合适的学习率。
–logging_steps:每隔多少步记录一次训练日志。不要设置太高,swanlab可能会由于长时间记录不上而导致中断。
–warmup_steps:学习率调度器中的热身步骤数。如果热身步骤太少,可能会导致模型一开始训练不稳定;太多可能会浪费训练时间。
总之,这些超参数控制了模型训练的各个方面,包括训练轮数、批次大小、学习率、梯度累积等。**num_train_epochs**决定了训练的轮数,**learning_rate**影响收敛速度,**gradient_accumulation_steps**和**per_device_train_batch_size**帮助平衡显存使用与训练效果,而**logging_steps**和**save_steps**则有助于跟踪训练进度和保存模型。
4、LoRA 特定参数
# LoRA 特定参数
parser.add_argument("--lora_rank", type=int, default=64,
help="Rank of LoRA matrices")
parser.add_argument("--lora_alpha", type=int, default=16,
help="Alpha parameter for LoRA")
parser.add_argument("--lora_dropout", type=float, default=0.05,
help="Dropout rate for LoRA")
–lora_rank:LoRA矩阵的秩。
-
较高的
lora_rank会导致更多的参数需要训练,从而可能提升模型的表示能力,但也会增加训练开销。 -
较低的
lora_rank则可能降低训练成本,但也可能限制模型的适应能力,导致模型的表现下降。
–lora_alpha:LoRA的缩放因子。LoRA矩阵的秩lora_rank通常乘以一个alpha因子进行缩放,这个参数控制低秩矩阵的影响力度。
-
lora_alpha较大时,LoRA矩阵的影响较大,模型可能会更多地依赖LoRA进行适应,从而影响性能。
-
lora_alpha较小时,LoRA矩阵的贡献较小,更多地依赖原始模型参数进行预测。选择合适的
lora_alpha有助于平衡LoRA适应性和训练效率。
–lora_dropout:LoRA矩阵中的dropout率。
-
较高的
lora_dropout值会增加正则化的效果,防止LoRA矩阵过拟合。 -
较低的
lora_dropout值则可能导致LoRA矩阵过拟合,尤其是在训练数据较少的情况下。 -
合适的dropout值有助于提升模型的泛化能力。
总之,lora_rank 控制LoRA矩阵的秩,决定了低秩矩阵的大小和表示能力;lora_alpha 控制LoRA矩阵对模型的影响力度,决定了LoRA矩阵的贡献程度;lora_dropout 控制LoRA矩阵的正则化强度,防止过拟合。
5、分布式训练参数
parser.add_argument("--local_rank", type=int, default=int(os.environ.get("LOCAL_RANK", -1)), help="Local rank for distributed training")
parser.add_argument("--distributed",type=bool, default=False, help="Enable distributed training")
–local_rank:本地设备的编号。
–distributed:启用分布式训练的开关。
-
如果设置为
True,训练将在多个GPU(或机器)上并行进行,能够加速训练过程。 -
如果设置为
False,训练将在单个设备上进行,不会使用分布式训练。
如果不使用分布式训练,单机训练可能面临计算资源不足、训练速度缓慢等问题。尤其对于大规模模型,单机无法提供足够的内存和计算能力,训练过程可能非常耗时。随着模型规模的增大,训练效率下降,且单机无法处理超大数据集,容易出现内存溢出或显存不足的情况。此外,长时间的单机训练也会增加硬件损耗和成本。
而分布式训练可以通过将训练任务分配到多个计算节点(如多GPU、多机器)上,加速训练过程,显著提升训练效率。它能够处理更大规模的数据集和更复杂的模型,避免内存溢出问题。通过并行计算,分布式训练可以缩短训练时间,尤其在多GPU或TPU环境下,训练速度得到大幅提升。同时,分布式训练还可以提高资源利用率,降低计算时间和成本,对于大规模深度学习任务是必不可少的。
6、额外优化和硬件相关参数
parser.add_argument("--gradient_checkpointing", type=bool, default=True,
help="Enable gradient checkpointing to save memory")
parser.add_argument("--optim", type=str, default="adamw_torch",
help="Optimizer to use during training")
parser.add_argument("--train_mode", type=str, default="lora",
help="lora or qlora")
parser.add_argument("--seed", type=int, default=42,
help="Random seed for reproducibility")
parser.add_argument("--fp16", type=bool, default=True,
help="Use mixed precision (FP16) training")
parser.add_argument("--report_to", type=str, default=None,
help="Reporting tool for logging (e.g., tensorboard)")
parser.add_argument("--dataloader_num_workers", type=int, default=0,
help="Number of workers for data loading")
parser.add_argument("--save_strategy", type=str, default="steps",
help="Strategy for saving checkpoints ('steps', 'epoch')")
parser.add_argument("--weight_decay", type=float, default=0,
help="Weight decay for the optimizer")
parser.add_argument("--max_grad_norm", type=float, default=1,
help="Maximum gradient norm for clipping")
parser.add_argument("--remove_unused_columns", type=bool, default=True,
help="Remove unused columns from the dataset")
–gradient_checkpointing:梯度检查点。启用梯度检查点后,在前向传播时不会直接保存每一层的激活值,而是在反向传播时重新计算这些激活值,从而节省内存。适用于内存限制较紧张的大模型训练。
–fp16:是否使用混合精度(FP16)训练。FP16(16位浮点数)训练能显著提高计算效率,并减少内存使用,尤其在训练大模型时能有效减少显存占用。
5、加载模型
这里我们使用huggingface上下载的模型,然后把它加载到Transformers中进行训练:
from transformers import AutoModelForCausalLM,AutoTokenizer
# model参数设置
model_kwargs = {
"trust_remote_code": True,
"torch_dtype": torch.float16 if args.fp16 else torch.bfloat16,
"use_cache": False if args.gradient_checkpointing else True,
"device_map": "auto" if not args.distributed else None,
}
# model加载
model = AutoModelForCausalLM.from_pretrained(args.model_name_or_path, **model_kwargs)
# 分词器加载
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True, use_fast=False)
6、配置训练可视化工具
这里使用SwanLab来监控整个训练过程,并评估最终的模型效果。可以直接使用SwanLab和Transformers的集成来实现,更多用法可以参考官方文档:
from swanlab.integration.huggingface import SwanLabCallback
from transformers import Trainer
swanlab_callback = SwanLabCallback(...)
trainer = Trainer(
...
callbacks=[swanlab_callback],
)
7、配置训练参数
在微调Transformer模型时,使用Trainer类来封装数据和训练参数是至关重要的。Trainer不仅简化了训练流程,还允许我们自定义训练参数,包括但不限于学习率、批次大小、训练轮次等。LoRA通过引入额外的旁路矩阵来模拟全参数微调的效果,从而减少训练参数的数量。这样,我们就能在保持模型性能的同时,显著减少模型的存储和计算需求。通过Trainer,我们可以轻松地将这些参数和其他训练参数一起配置,以实现高效且定制化的模型微调。
这里我们需要以下这些参数,包括模型、训练参数、训练数据、处理数据批次的工具、还有可视化工具
trainer = Trainer(
model=model,
args=train_args,
train_dataset=train_dataset,
data_collator=data_collator,
callbacks=[swanlab_callback],
)
其中模型、训练参数的配置如下:
### 分布式训练必要条件
def setup_distributed(args):
"""初始化分布式环境"""
if args.distributed:
if args.local_rank == -1:
raise ValueError("未正确初始化 local_rank,请确保通过分布式启动脚本传递参数,例如 torchrun。")
# 初始化分布式进程组
dist.init_process_group(backend="nccl")
torch.cuda.set_device(args.local_rank)
print(f"分布式训练已启用,Local rank: {args.local_rank}")
else:
print("未启用分布式训练,单线程模式。")
# 初始化分布式环境
setup_distributed(args)
# 用于确保模型的词嵌入层参与训练
model.enable_input_require_grads()
# 将模型移动到正确设备
if args.distributed:
model.to(args.local_rank)
model = DDP(model, device_ids=[args.local_rank], output_device=args.local_rank)
# 哪些模块需要注入Lora参数
target_modules = find_all_linear_names(model.module if isinstance(model, DDP) else model, args.train_mode)
# lora参数设置
config = LoraConfig(
r=args.lora_rank,
lora_alpha=args.lora_alpha,
lora_dropout=args.lora_dropout,
bias="none",
target_modules=target_modules,
task_type=TaskType.CAUSAL_LM,
inference_mode=False
)
use_bfloat16 = torch.cuda.is_bf16_supported() # 检查设备是否支持 bf16
# 配置训练参数
train_args = TrainingArguments(
output_dir=args.output_dir,
per_device_train_batch_size=args.per_device_train_batch_size,
gradient_accumulation_steps=args.gradient_accumulation_steps,
logging_steps=args.logging_steps,
num_train_epochs=args.num_train_epochs,
save_steps=args.save_steps,
learning_rate=args.learning_rate,
save_on_each_node=True,
gradient_checkpointing=args.gradient_checkpointing,
report_to=args.report_to,
seed=args.seed,
optim=args.optim,
local_rank=args.local_rank if args.distributed else -1,
ddp_find_unused_parameters=False, # 分布式参数检查优化
fp16=args.fp16,
bf16=not args.fp16 and use_bfloat16,
)
# 应用 PEFT 配置到模型
model = get_peft_model(model.module if isinstance(model, DDP) else model, config) # 确保传递的是原始模型
这里在使用 PEFT(Parameter-Efficient Fine-Tuning,参数高效微调)技术时,通常需要通过 get_peft_model 来设置模型。PEFT 是一种用于微调大规模预训练模型的技术,它的目标是减少需要更新的参数量,同时保持模型的性能。这种方法特别适用于大模型(如 GPT、BERT等),可以在有限的计算资源下实现快速高效的微调。
可视化工具配置如下:
swanlab_config = {
"lora_rank": args.lora_rank,
"lora_alpha": args.lora_alpha,
"lora_dropout": args.lora_dropout,
"dataset":"single_conversation"
}
swanlab_callback = SwanLabCallback(
project="deepseek-finetune",
experiment_name="deepseek-llm-7b-chat-lora",
description="DeepSeek有很多模型,V2太大了,这里选择llm-7b-chat的,希望能让回答更加人性化",
workspace=None,
config=swanlab_config,
)
8、完整代码
全过程代码如下:
import argparse
from os.path import join
import pandas as pd
from datasets import Dataset
from loguru import logger
from transformers import (
TrainingArguments,
AutoModelForCausalLM,
Trainer,
DataCollatorForSeq2Seq,
AutoTokenizer,
)
import torch
from peft import LoraConfig, get_peft_model, TaskType
from swanlab.integration.transformers import SwanLabCallback
import bitsandbytes as bnb
from torch import nn
from torch.nn.parallel import DistributedDataParallel as DDP
import torch.distributed as dist
import os
import json
# 配置参数
def configuration_parameter():
parser = argparse.ArgumentParser(description="LoRA fine-tuning for deepseek model")
# 模型路径相关参数
parser.add_argument("--model_name_or_path", type=str, default="./model",
help="Path to the model directory downloaded locally")
parser.add_argument("--output_dir", type=str,
default="/home/public/TrainerShareFolder/lxy/deepseek-output/singledata-2048-16-32-epoch-2",
help="Directory to save the fine-tuned model and checkpoints")
# 数据集路径
parser.add_argument("--train_file", type=str, default="./data/single_datas.jsonl",
help="Path to the training data file in JSONL format")
# 训练超参数
parser.add_argument("--num_train_epochs", type=int, default=2,
help="Number of training epochs")
parser.add_argument("--per_device_train_batch_size", type=int, default=4,
help="Batch size per device during training")
parser.add_argument("--gradient_accumulation_steps", type=int, default=16,
help="Number of updates steps to accumulate before performing a backward/update pass")
parser.add_argument("--learning_rate", type=float, default=2e-4,
help="Learning rate for the optimizer")
parser.add_argument("--max_seq_length", type=int, default=2048,
help="Maximum sequence length for the input")
parser.add_argument("--logging_steps", type=int, default=1,
help="Number of steps between logging metrics")
parser.add_argument("--save_steps", type=int, default=200,
help="Number of steps between saving checkpoints")
parser.add_argument("--save_total_limit", type=int, default=1,
help="Maximum number of checkpoints to keep")
parser.add_argument("--lr_scheduler_type", type=str, default="constant_with_warmup",
help="Type of learning rate scheduler")
parser.add_argument("--warmup_steps", type=int, default=100,
help="Number of warmup steps for learning rate scheduler")
# LoRA 特定参数
parser.add_argument("--lora_rank", type=int, default=64,
help="Rank of LoRA matrices")
parser.add_argument("--lora_alpha", type=int, default=16,
help="Alpha parameter for LoRA")
parser.add_argument("--lora_dropout", type=float, default=0.05,
help="Dropout rate for LoRA")
# 分布式训练参数
parser.add_argument("--local_rank", type=int, default=int(os.environ.get("LOCAL_RANK", -1)),
help="Local rank for distributed training")
parser.add_argument("--distributed", type=bool, default=True, help="Enable distributed training")
# 额外优化和硬件相关参数
parser.add_argument("--gradient_checkpointing", type=bool, default=True,
help="Enable gradient checkpointing to save memory")
parser.add_argument("--optim", type=str, default="adamw_torch",
help="Optimizer to use during training")
parser.add_argument("--train_mode", type=str, default="lora",
help="lora or qlora")
parser.add_argument("--seed", type=int, default=42,
help="Random seed for reproducibility")
parser.add_argument("--fp16", type=bool, default=True,
help="Use mixed precision (FP16) training")
parser.add_argument("--report_to", type=str, default=None,
help="Reporting tool for logging (e.g., tensorboard)")
parser.add_argument("--dataloader_num_workers", type=int, default=0,
help="Number of workers for data loading")
parser.add_argument("--save_strategy", type=str, default="steps",
help="Strategy for saving checkpoints ('steps', 'epoch')")
parser.add_argument("--weight_decay", type=float, default=0,
help="Weight decay for the optimizer")
parser.add_argument("--max_grad_norm", type=float, default=1,
help="Maximum gradient norm for clipping")
parser.add_argument("--remove_unused_columns", type=bool, default=True,
help="Remove unused columns from the dataset")
args = parser.parse_args()
return args
def find_all_linear_names(model, train_mode):
"""
找出所有全连接层,为所有全连接添加adapter
"""
assert train_mode in ['lora', 'qlora']
cls = bnb.nn.Linear4bit if train_mode == 'qlora' else nn.Linear
lora_module_names = set()
for name, module in model.named_modules():
if isinstance(module, cls):
names = name.split('.')
lora_module_names.add(names[0] if len(names) == 1 else names[-1])
if 'lm_head' in lora_module_names: # needed for 16-bit
lora_module_names.remove('lm_head')
lora_module_names = list(lora_module_names)
logger.info(f'LoRA target module names: {lora_module_names}')
return lora_module_names
def setup_distributed(args):
"""初始化分布式环境"""
if args.distributed:
if args.local_rank == -1:
raise ValueError("未正确初始化 local_rank,请确保通过分布式启动脚本传递参数,例如 torchrun。")
# 初始化分布式进程组
dist.init_process_group(backend="nccl")
torch.cuda.set_device(args.local_rank)
print(f"分布式训练已启用,Local rank: {args.local_rank}")
else:
print("未启用分布式训练,单线程模式。")
# 加载模型
def load_model(args, train_dataset, data_collator):
# 初始化分布式环境
setup_distributed(args)
# 自动分配设备
# 加载模型
model_kwargs = {
"trust_remote_code": True,
"torch_dtype": torch.float16 if args.fp16 else torch.bfloat16,
"use_cache": False if args.gradient_checkpointing else True,
"device_map": "auto" if not args.distributed else None,
}
model = AutoModelForCausalLM.from_pretrained(args.model_name_or_path, **model_kwargs)
# 用于确保模型的词嵌入层参与训练
model.enable_input_require_grads()
# 将模型移动到正确设备
if args.distributed:
model.to(args.local_rank)
model = DDP(model, device_ids=[args.local_rank], output_device=args.local_rank)
# 哪些模块需要注入Lora参数
target_modules = find_all_linear_names(model.module if isinstance(model, DDP) else model, args.train_mode)
# lora参数设置
config = LoraConfig(
r=args.lora_rank,
lora_alpha=args.lora_alpha,
lora_dropout=args.lora_dropout,
bias="none",
target_modules=target_modules,
task_type=TaskType.CAUSAL_LM,
inference_mode=False
)
use_bfloat16 = torch.cuda.is_bf16_supported() # 检查设备是否支持 bf16
# 配置训练参数
train_args = TrainingArguments(
output_dir=args.output_dir,
per_device_train_batch_size=args.per_device_train_batch_size,
gradient_accumulation_steps=args.gradient_accumulation_steps,
logging_steps=args.logging_steps,
num_train_epochs=args.num_train_epochs,
save_steps=args.save_steps,
learning_rate=args.learning_rate,
save_on_each_node=True,
gradient_checkpointing=args.gradient_checkpointing,
report_to=args.report_to,
seed=args.seed,
optim=args.optim,
local_rank=args.local_rank if args.distributed else -1,
ddp_find_unused_parameters=False, # 分布式参数检查优化
fp16=args.fp16,
bf16=not args.fp16 and use_bfloat16,
remove_unused_columns=False
)
# 应用 PEFT 配置到模型
model = get_peft_model(model.module if isinstance(model, DDP) else model, config) # 确保传递的是原始模型
print("model:", model)
model.print_trainable_parameters()
### 展示平台
swanlab_config = {
"lora_rank": args.lora_rank,
"lora_alpha": args.lora_alpha,
"lora_dropout": args.lora_dropout,
"dataset": "single-data-3w"
}
swanlab_callback = SwanLabCallback(
project="deepseek-finetune",
experiment_name="deepseek-llm-7b-chat-lora",
description="DeepSeek有很多模型,V2太大了,这里选择llm-7b-chat的,希望能让回答更加人性化",
workspace=None,
config=swanlab_config,
)
trainer = Trainer(
model=model,
args=train_args,
train_dataset=train_dataset,
data_collator=data_collator,
callbacks=[swanlab_callback],
)
return trainer
# 处理数据
def process_data(data: dict, tokenizer, max_seq_length):
# 处理数据
conversation = data["conversation"]
input_ids, attention_mask, labels = [], [], []
for i, conv in enumerate(conversation):
human_text = conv["human"].strip()
assistant_text = conv["assistant"].strip()
input_text = "Human:" + human_text + "\n\nnAssistant:"
input_tokenizer = tokenizer(
input_text,
add_special_tokens=False,
truncation=True,
padding=False,
return_tensors=None,
)
output_tokenizer = tokenizer(
assistant_text,
add_special_tokens=False,
truncation=True,
padding=False,
return_tensors=None,
)
input_ids += (
input_tokenizer["input_ids"] + output_tokenizer["input_ids"] + [tokenizer.eos_token_id]
)
attention_mask += input_tokenizer["attention_mask"] + output_tokenizer["attention_mask"] + [1]
labels += ([-100] * len(input_tokenizer["input_ids"]) + output_tokenizer["input_ids"] + [tokenizer.eos_token_id]
)
if len(input_ids) > max_seq_length: # 做一个截断
input_ids = input_ids[:max_seq_length]
attention_mask = attention_mask[:max_seq_length]
labels = labels[:max_seq_length]
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
}
# 训练部分
def main():
args = configuration_parameter()
print("*****************加载分词器*************************")
# 加载分词器
model_path = args.model_name_or_path
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True, use_fast=False)
print("*****************处理数据*************************")
# 处理数据
# 获得数据
data = pd.read_json(args.train_file, lines=True)
train_ds = Dataset.from_pandas(data)
train_dataset = train_ds.map(process_data,
fn_kwargs={"tokenizer": tokenizer, "max_seq_length": args.max_seq_length},
remove_columns=train_ds.column_names)
data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True, return_tensors="pt")
print(train_dataset, data_collator)
# 加载模型
print("*****************训练*************************")
trainer = load_model(args, train_dataset, data_collator)
trainer.train()
# 训练
final_save_path = join(args.output_dir)
trainer.save_model(final_save_path)
if __name__ == "__main__":
main()
单线程运行代码的时候需要下述代码在命令行运行:
python finetune.py
如果需要分布式训练,运行下述代码:
torchrun --nproc_per_node=4 finetune.py
训练过程演示(Swanlab)
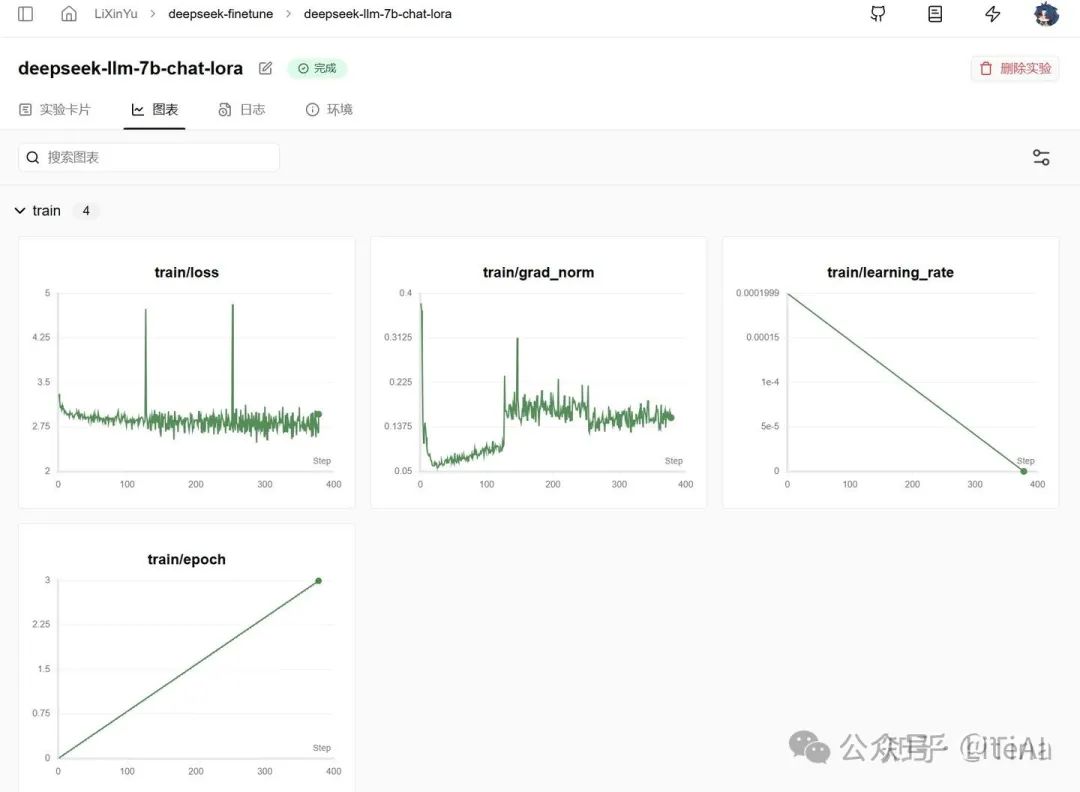
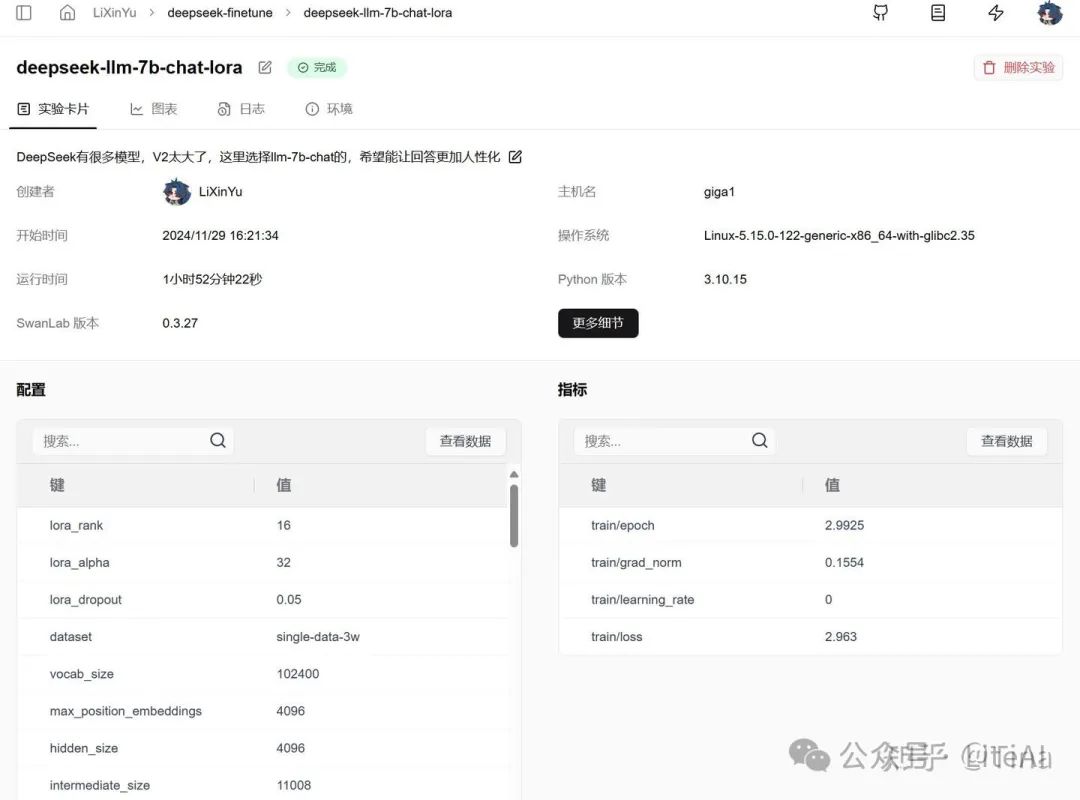
这里使用3w条数据跑完了全程,使用4块A100进行分布式训练,总训练时长为1个多小时,epoch为3,数据训练三次,所有的超参数可以从实验卡片找到。
图表
参数如下:
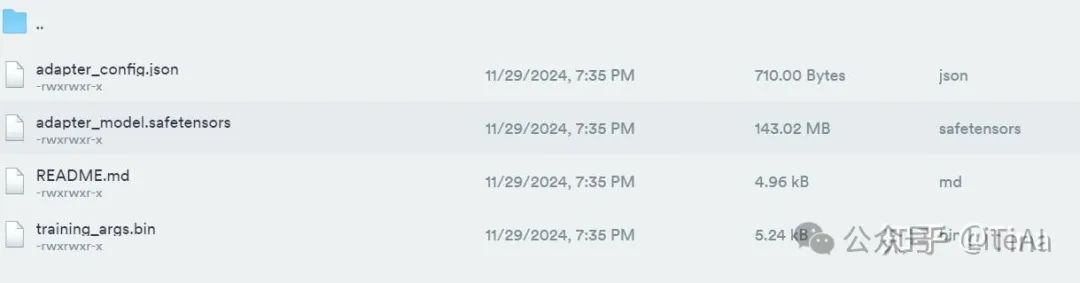
推理微调后的模型
在推理前,需要先把保存下来的模型与预训练模型做一个合并,因为微调的模型保存下来的只有adapter部分,具体如下:
这里的模型合并代码参考了lora模型与base模型合并代码,代码如下:
from peft import PeftModel
from transformers import AutoModelForCausalLM
import torch
import os
from modelscope import AutoTokenizer
import shutil
# 保证原始模型的各个文件不遗漏保存到merge_path中
def copy_files_not_in_B(A_path, B_path):
"""
Copies files from directory A to directory B if they exist in A but not in B.
:param A_path: Path to the source directory (A).
:param B_path: Path to the destination directory (B).
"""
# 保证路径存在
if not os.path.exists(A_path):
raise FileNotFoundError(f"The directory {A_path} does not exist.")
if not os.path.exists(B_path):
os.makedirs(B_path)
# 获取路径A中所有非权重文件
files_in_A = os.listdir(A_path)
files_in_A = set([file for file in files_in_A if not (".bin" in file or "safetensors" in file)])
# List all files in directory B
files_in_B = set(os.listdir(B_path))
# 找到所有A中存在但B中不存在的文件
files_to_copy = files_in_A - files_in_B
# 将文件或文件夹复制到B路径下
for file in files_to_copy:
src_path = os.path.join(A_path, file)
dst_path = os.path.join(B_path, file)
if os.path.isdir(src_path):
# 复制目录及其内容
shutil.copytree(src_path, dst_path)
else:
# 复制文件
shutil.copy2(src_path, dst_path)
def merge_lora_to_base_model():
model_name_or_path = 'pretrain_model' # 原模型地址
adapter_name_or_path = 'output/moss-10000-4096-16-32-epoch-2' # 微调后模型的保存地址
save_path = 'output/moss-10000-4096-16-32-epoch-2-merge-model'
# 如果文件夹不存在,就创建
if not os.path.exists(save_path):
os.makedirs(save_path)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path,trust_remote_code=True,)
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
trust_remote_code=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map="auto"
)
# 加载保存的 Adapter
model = PeftModel.from_pretrained(model, adapter_name_or_path, device_map="auto",trust_remote_code=True)
# 将 Adapter 合并到基础模型中
merged_model = model.merge_and_unload() # PEFT 的方法将 Adapter 权重合并到基础模型
# 保存合并后的模型
tokenizer.save_pretrained(save_path)
merged_model.save_pretrained(save_path, safe_serialization=False)
copy_files_not_in_B(model_name_or_path, save_path)
print(f"合并后的模型已保存至: {save_path}")
if __name__ == '__main__':
merge_lora_to_base_model()
合并后有三个权重文件:

我们对比一下使用预训练模型和合并后的微调模型的推理结果,首先代码如下:
def original_model_reasoning(model_path: str, prompt: str, max_new_tokens=2048):
"""
单论对话的回复
:param model_path: 模型下载地址
:param prompt: 需要询问的问题
:return: 回复的话
"""
# 加载模型和分词器
model_path = model_path
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch.bfloat16, trust_remote_code=True,
device_map="auto")
model.generation_config = GenerationConfig.from_pretrained(model_path)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
messages = [
{"role": "user",
"content": prompt}
]
input_tensor = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(input_tensor.to(model.device), max_new_tokens=max_new_tokens)
result = tokenizer.decode(outputs[0][input_tensor.shape[1]:], skip_special_tokens=True)
return result
推理结果对比(上边是预训练模型,下边是微调后模型):

效果还不错,感觉比之前人性化多了。

如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 27
27 0
0- 0



 已为社区贡献269条内容
已为社区贡献269条内容

所有评论(0)