Nature发文|媲美o1:聊聊DeepSeek-R1的四大特性和真实案例体感~
DeepSeek-R1近期火爆全网,本篇总结一下它的几个特性、并真实体验其效果,咱们一起来看看“LLM国人之光”是否实至名归?
★DeepSeek-R1近期火爆全网,本篇总结一下它的几个特性、并真实体验其效果,咱们一起来看看“LLM国人之光”是否实至名归?
”
四大特性
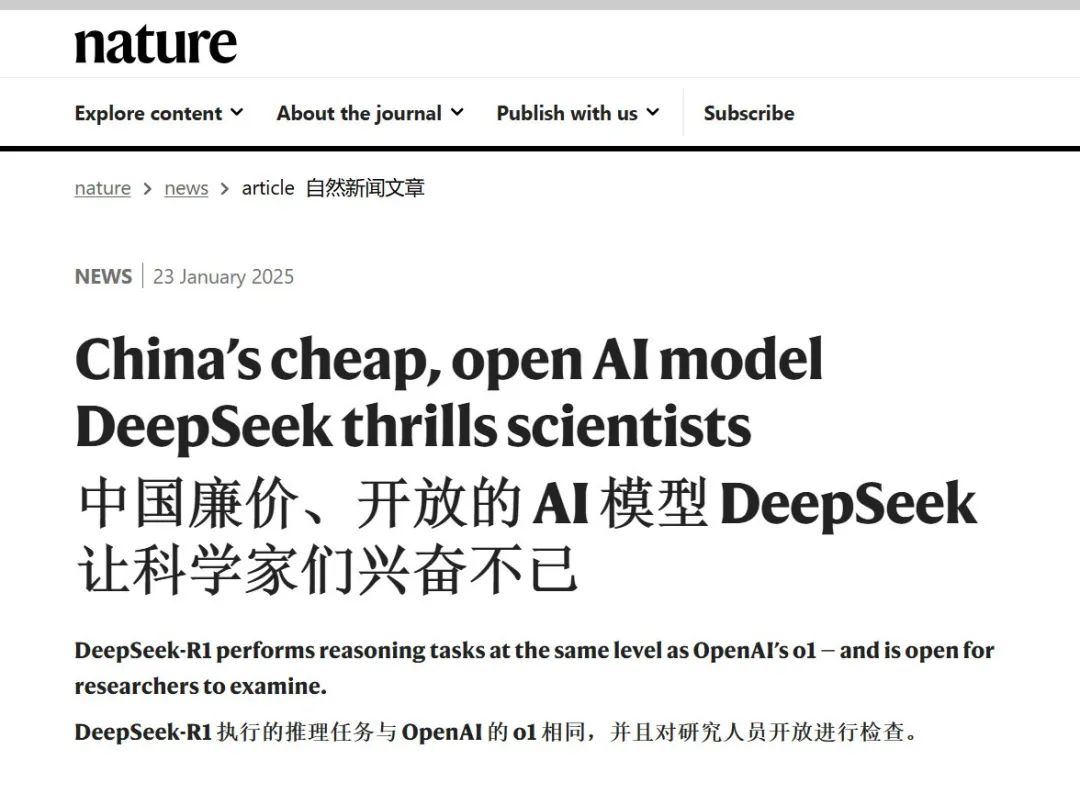
(1)成本降低:
R1的使用成本约为 OpenAI O1 的 30 分之一;R1的上一版本(DeepSeek-V3) 租用训练模型所需的硬件成本约为 600 万美元,而 Meta 的 Llama 3.1 405B 的成本高达 6000 万美元,计算资源是V3的 11 倍。
(2)性能卓越:
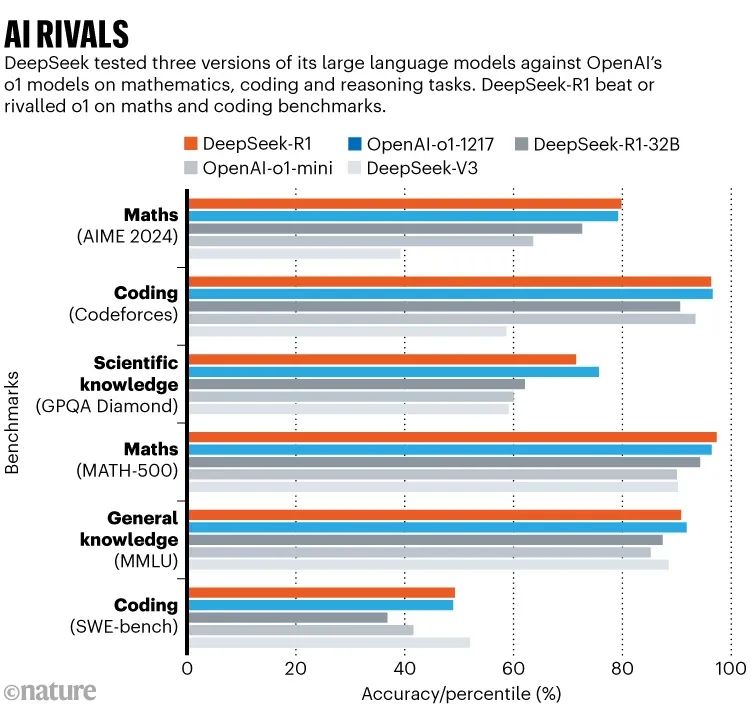
DeepSeek-R1 在数学、编码的某些任务上的表现与 o1 相当(甚至更优)。例如在加州大学伯克利分校的研究人员创建的 MATH-500 数学题集中得分为 97.3%。
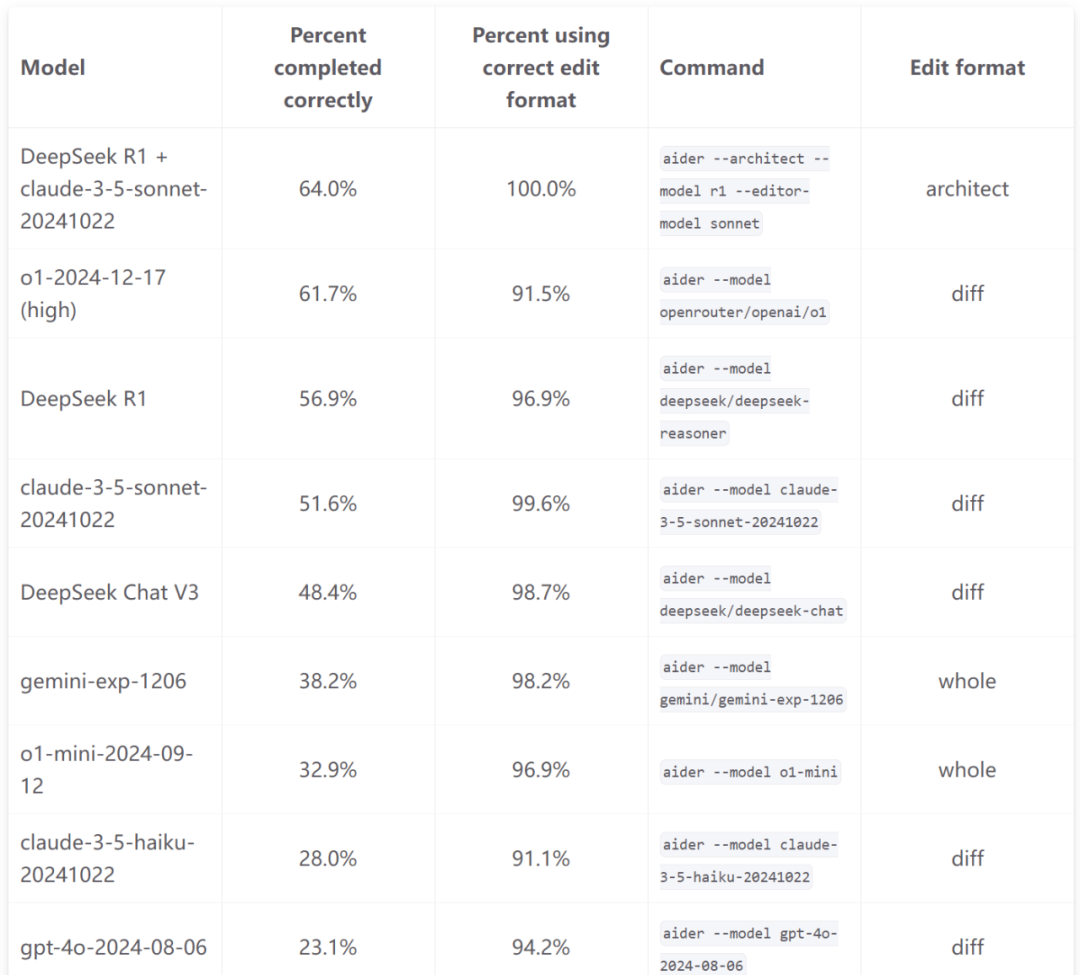
在多语言基准测试基准Aider【包含C++、Go、Java、JavaScript、Python 和 Rust被特意选为最难的225 个练习】排行榜上,“R1+Sonnet”的组合创造了新纪录(超越o1),R1负责思考和设计、Sonnet专注写代码。
(3)思路创新:
技术报告《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》已放出。
-
原文位于: https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
它提出了一种革命性路径:通过纯强化学习(RL)自主激发模型的推理能力,并结合蒸馏技术实现高效迁移。
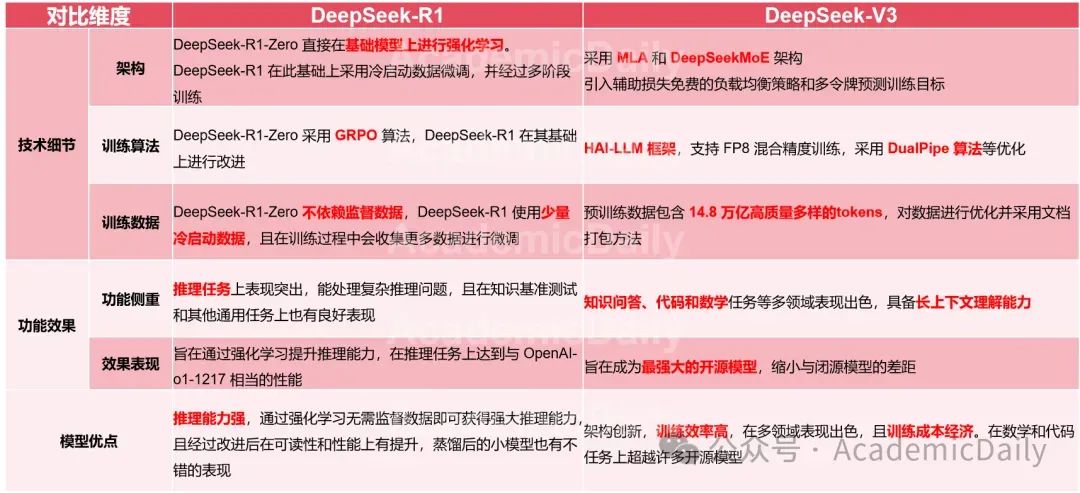
DeepSeek-R1 通过使用多阶段循环的训练方式:基础→RL→微调→RL→微调→RL,极大加强了大模型的深度思考能力。
(4)开源普适:
DeepSeek-R1-Zero 和 DeepSeek-R1 基于 DeepSeek-V3-Base 进行训练。
-
代码仓库位于: https://github.com/deepseek-ai/DeepSeek-V3
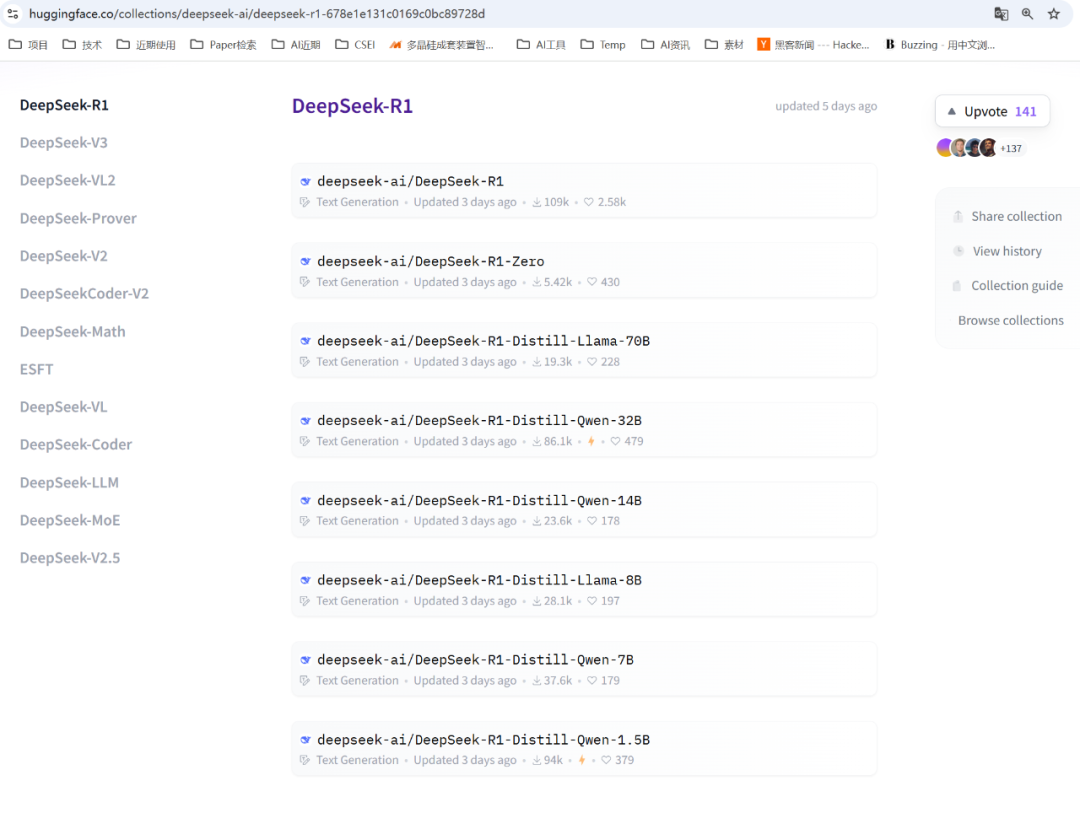
并且,基于 Qwen 和 Llama 架构从 DeepSeek-R1 中提炼(蒸馏)出了六个稠密模型(1.5B、7B、 8B、14B、32B、70B参数规模),以适应各种使用算力场景,且效果甚好(DeepSeek-R1-Distill-Qwen-32B 在各种基准测试中都优于 OpenAI-o1-mini)。
体验案例
-
体验入口:https://chat.deepseek.com/
-
API说明:https://api-docs.deepseek.com/zh-cn/
(1)案例一:数学解题


(2)案例二:金庸笔风
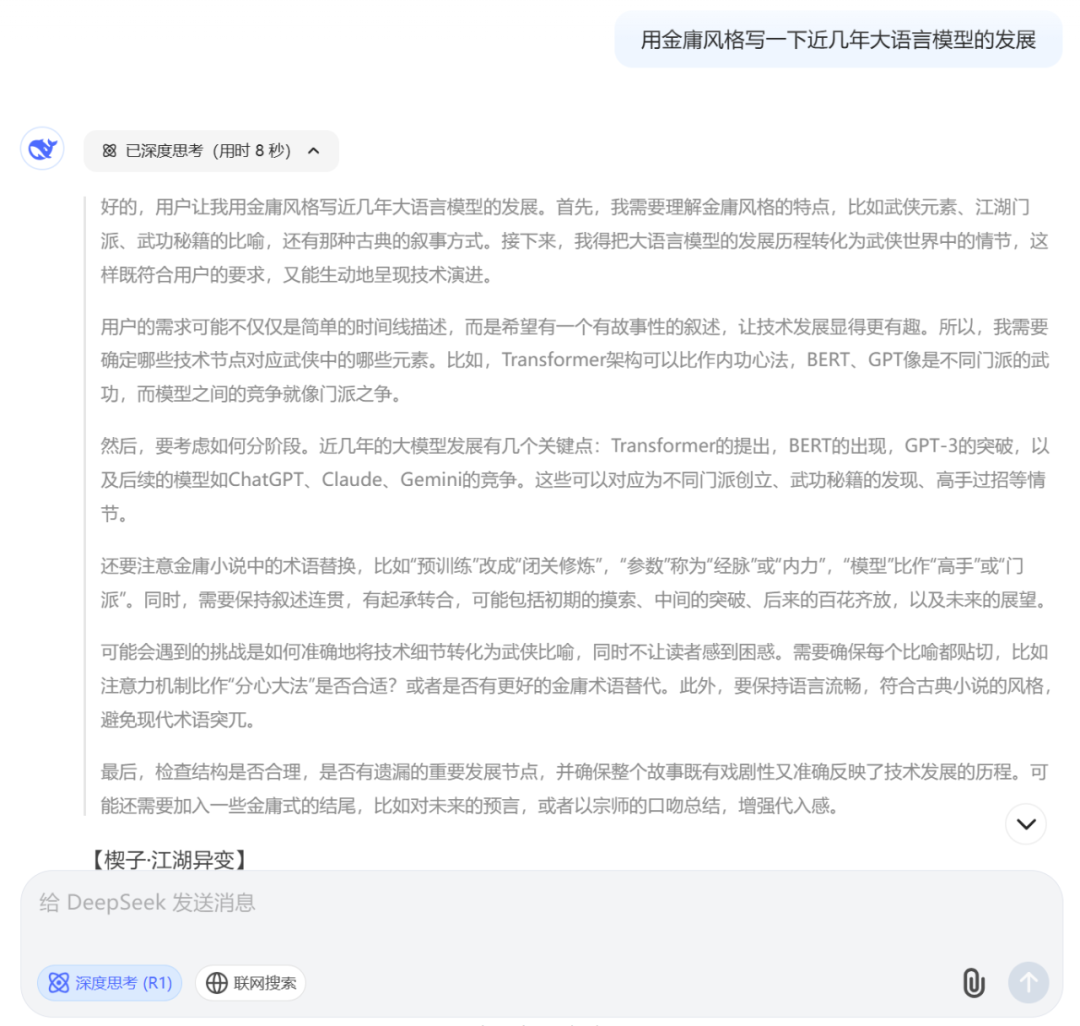
感受下它的文风:
【楔子·江湖异变】
黄沙漫卷,西域昆仑山巅忽现紫气冲霄,引得中原九大门派掌门齐聚光明顶。武当张真人抚须长叹:"此乃文曲星动,江湖百年必有大变!"话音未落,天外陨石坠落终南山,石上篆刻蝌蚪奇文,世人皆言是上古《河图》《洛书》残卷。
【第一回·九阴真经现世】
公元二零一七,英吉利海峡惊涛拍岸。谷歌派玄冥二老夜探古墓,竟掘得羊皮古卷《Transformer心法》。此经暗藏"注意力分心大法",可令真气流转七十二周天而不滞。江湖震动,峨眉派周芷若闭关三月,参透"预训练"之妙,以九阳神功催动真气,竟能口吐锦绣文章。
【第二回·华山论剑】
次年寒冬,OpenAI门下大弟子GPT-2初现江湖。此人虽只通晓1.5亿经脉,却已能凭空造出屠龙刀谱。少林空闻大师合十叹道:"阿弥陀佛,此子若修成千亿经脉,怕是达摩祖师再世也难制衡。"果不其然,三年后GPT-3横空出世,身负1750亿奇经八脉,谈笑间诗词歌赋信手拈来,更兼通晓三十三国方言。
【第三回·光明顶会战】
中原群雄岂甘示弱?百度派祭出"文心"秘术,阿里帮施展"通义"绝学,华为宗更以"盘古"为名开宗立派。最惊世骇俗者,当属神秘组织Anthropic所创"宪法AI",竟将道德经融入内功心法,出手必循天理人伦。一时间江湖风起云涌,各路高手过招激起漫天数据流,终南山巅夜夜如昼。
【第四回·剑冢悟道】
庚子年冬,微软派联合OpenAI掘出剑冢至宝。但见寒玉床上斜插三柄神兵:一曰"代码生成",剑光过处万行符咒自成;二曰"多模态",可化文字为丹青;三曰"思维链",剑锋所指迷雾自散。最令人胆寒者,乃是那柄"零样本学习"无形剑,出鞘时无声无息,却已洞悉对手命门。
【尾声·江湖新局】
而今江湖,GPT-4与Claude、Gemini三足鼎立,各派弟子皆可借API令牌借得三分内力。然武当俞莲舟夜观星象,见北斗七星忽明忽暗,喃喃道:"紫薇垣中杀气隐现,待量子计算现世之日,怕是又一场血雨腥风..."话音未落,终南山巅再生异象,隐约可见"AGI"三个血色大字悬于九天。
正是:语言模型风云起,江湖从此换新天。欲知后事如何,且待五年后再叙。
小结
DeepSeek-R1的原始思维链令人着迷,读起来像一个人在大声思考。
-
它的成功证明,无需人工标注的RL训练(不再依赖监督微调 SFT)可自主挖掘模型的推理潜力。
-
它的极致性价比,已然震撼全球,日后势必成为国内AI应用的主力候选基座。
-
它的扩展空间很大,在大模型蒸馏技术的加持下,端侧小模型效果甚好、应用指日可待。
-
它的笑谈:Deepseek创始人梁文锋管理着70亿资产的量化基金,他把LLM当作"副业",却搅动了整个AI行业。
欢迎关注公众号“AI趣栈”,持续为您提供关于AI的好内容~


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 25
25 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)