python本地部署deepseek-R1-distill-Qwen-1.5B无脑教程
使用python+transformers本地部署deepsek-r1-distill-1.5b模型
·
自从deepseek火了之后,各种公司(凡是半点与互联网相关)都想尝个鲜,想做自己领域的对话模型,微调,RAG,部署这些。又不愿意用在线的工具,这里出一篇关于部署的无脑教程,记录下部署过程,部署的模型如题(硬件水平限制)
1. 环境及硬件准备
python==3.10
torch==2.0.0
transformers==4.49.0
测试的硬件为8GB 3060ti, cuda 11.7
2.代码
本身模型加载及推理很简单,就是transformers包的使用
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# 加载已经微调的模型
final_save_path = './deepseekr1-1.5b'
model = AutoModelForCausalLM.from_pretrained(final_save_path).to('cuda:0')
tokenizer = AutoTokenizer.from_pretrained(final_save_path)
# 用户输入
user_input = '你好,你是谁创造的'
# 添加模板
formated_prompt = f'User:{user_input}\n\nAssistant:'
# 分词
inputs = tokenizer(
formated_prompt,
return_tensors='pt',
add_special_tokens=True
).to('cuda:0')
outputs = model.generate(**inputs, max_new_tokens=512, temperature=0.7,
top_p=0.95, do_sample=True, repetition_penalty=1.1,
eos_token_id=tokenizer.eos_token_id, pad_token_id=tokenizer.eos_token_id)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_text)如果是加载原模型,这里需要注意模板的使用,如果直接用输入的文字分词,这样的输出会很奇怪,它会把输入当作上下文来处理,一定要按照模板重新处理输入
3.fastapi调用
fastapi==0.115.11
这里使用html调用并接收返回值
后端
from fastapi import FastAPI, Body
from fastapi.middleware.cors import CORSMiddleware
from transformers import AutoTokenizer, AutoModelForCausalLM
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # 或者指定具体的域名
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
def generation(massage):
# 加载已经微调的模型
final_save_path = './final_save_path'
model = AutoModelForCausalLM.from_pretrained(final_save_path).to('cuda:0')
tokenizer = AutoTokenizer.from_pretrained(final_save_path)
formated_prompt = f'User:{massage}\n\nAssistant:'
inputs = tokenizer(
formated_prompt, return_tensors='pt', add_special_tokens=True
).to('cuda:0')
outputs = model.generate(
**inputs, max_new_tokens=512, temperature=0.7,
top_p=0.95, do_sample=True, repetition_penalty=1.1,
eos_token_id=tokenizer.eos_token_id, pad_token_id=tokenizer.eos_token_id
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
start_pos = generated_text.find('Assistant:')
generated_text = generated_text[start_pos + 10:]
return generated_text
@app.post("/text2text")
async def predict(prompt: dict= Body(...)):
generated_text = generation(prompt.get('massage'))
return {"generated_text": generated_text, 'code':200}中间件一定要加,否则服务端会报405,method not allowed
前端
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link rel="icon" href="./2988036.ico">
<title>deepseek-R1-1.5b-distill-test</title>
<script src="./jquery-3.6.3.min.js"></script>
<script src="./jquery-3.6.3.js"></script>
<link rel="stylesheet" href="./register.css">
</style> -->
</head>
<body>
<div id="header">
<span>
欢迎访问 |
</span>
<a href="index.html">
<img id="logo" src="./logo.png" alt="">
</a>
</div>
<div id="container">
<div>
<span>user:</span>
<input id="user" type="text" name="user" placeholder="请输入对话">
</div>
<div class="button">
<button id="register">提交</button>
</div>
<textarea id="myTextarea" readonly></textarea>
</div>
<div id="bootom">
开发者:wlm 3/14/2025
</div>
<script>
//验证
function checkUname(){
return $('#user').val().length<1||$('#user').val().length>512
}
var baseUrl = "http://192.168.1.134:8000/"
$('#register').click(function () {
//验证结果结合]
if(!checkUname()){
$.ajax({
type: "POST",
url: baseUrl +"text2text",
contentType:'application/json',
dataType: "json",
data: JSON.stringify({
'massage': $('#user').val()
}),
success: function (responseData) { //成功的回调函数
console.log('succeed');
console.log(responseData);
if (responseData.code == 200) {
console.log("succeed");
var generatedText = responseData.generated_text;
//console.log(generatedText);
var textareaElement = document.getElementById('myTextarea');
textareaElement.value = generatedText;
}else {
alert('error');
}
},
});
}else{
alert('请按照要求填写信息')
}
})
</script>
</body>
</html>前端页面中加载的css样式,js, 图片和链接到的其他页面自行准备
后端部署使用了uvicron,前端ngix
4.总体效果
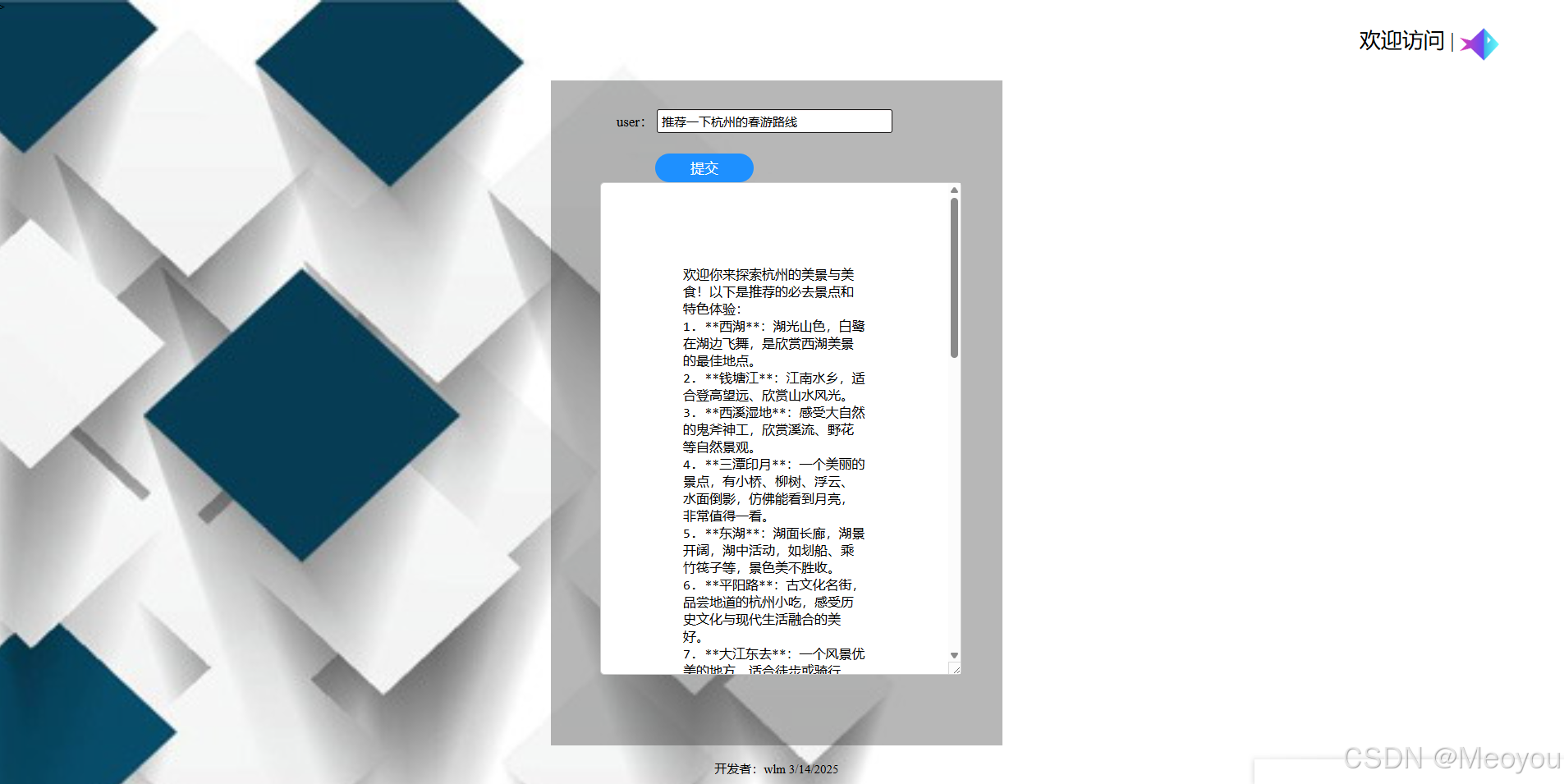
测试了下,如果加载使用transformers lora微调后的模型对话也是可以的

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)