为什么本地化部署的deepseek远不如在网站上的deepseek智能?
rt,分别在deepseek的官网上、在本地化部署的deepseek里(分别用终端、chatbox打开)提问:“用英剧《是,大臣》里的角色汉弗莱的说话风格,对明朝做出评价”他推理过程中说汉弗莱“不够文雅”这一点就很让人怀疑了,而且最后的回答也是驴头不对马嘴;请教一下大模型相关的朋友,这种情况是因为什么而发生的?这份回答虽然说不上十全十美,但至少汉妃那味儿出来了;这一份还算好一点,但跟官网上的回答相
·
rt,分别在deepseek的官网上、在本地化部署的deepseek里(分别用终端、chatbox打开)提问:“用英剧《是,大臣》里的角色汉弗莱的说话风格,对明朝做出评价”
deepseek官网的回答如下:

这份回答虽然说不上十全十美,但至少汉妃那味儿出来了;
在终端中打开的本地部署的deepseek回答如下:
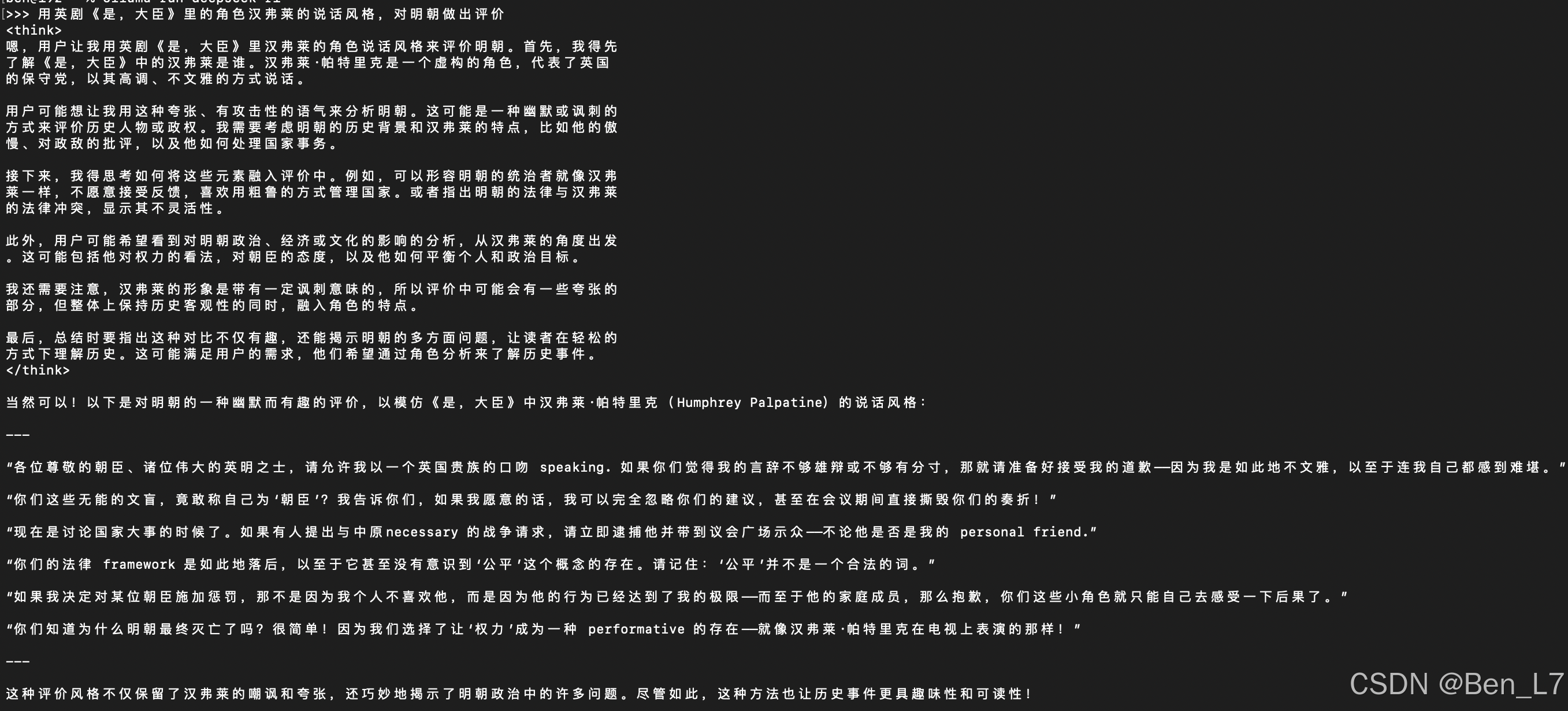
这份回答。。。他推理过程中说汉弗莱“不够文雅”这一点就很让人怀疑了,而且最后的回答也是驴头不对马嘴;
接着,我试着用chatbox打开本地化部署的deepseekr1,发现chatbox可以调节大模型的“temperature”:
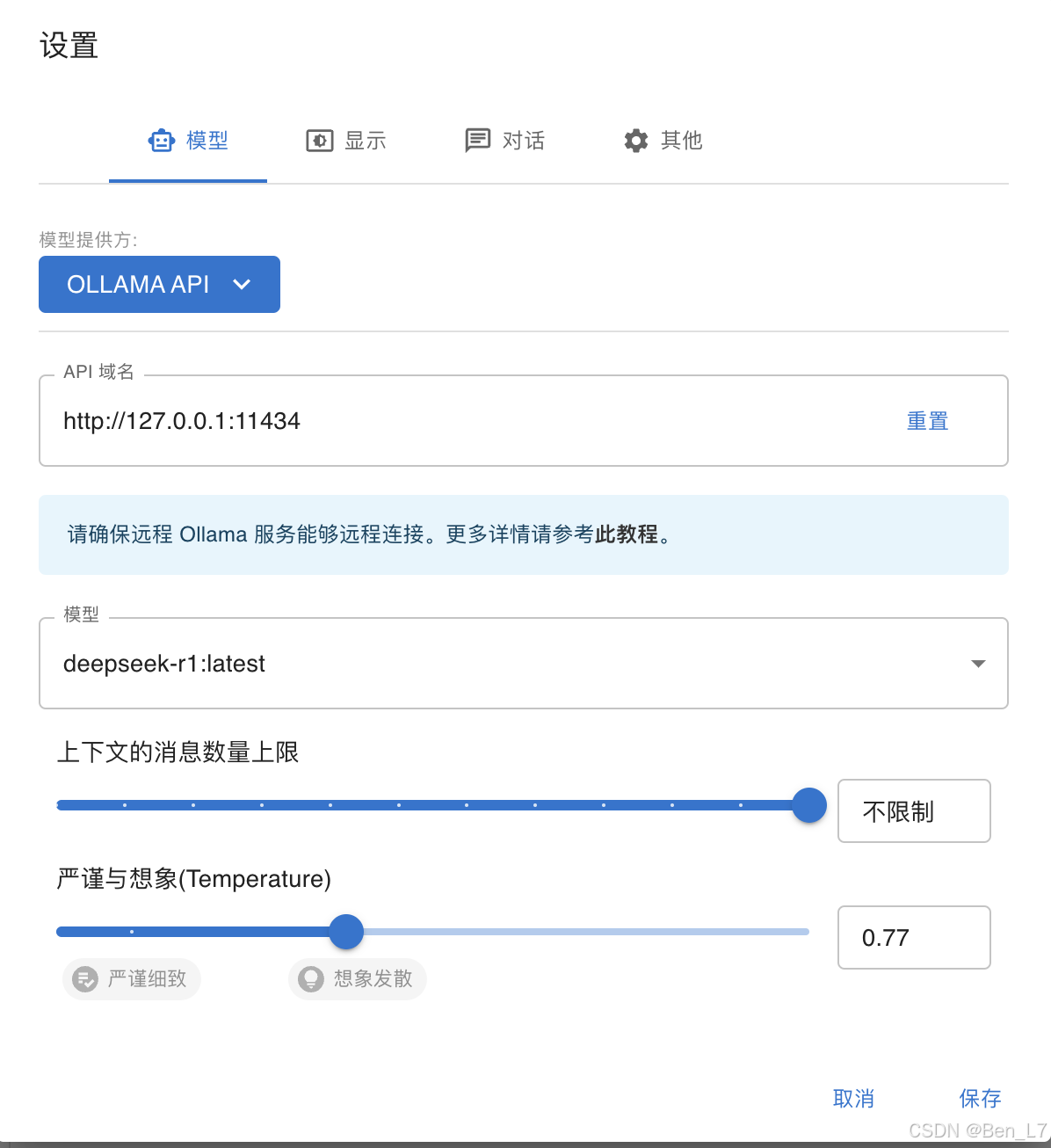
所以我让他分别用“严谨细致”和“想象发散”的风格写了一遍回答:
“严谨细致”:

……我就不过多评价了
“发散想象”:

这一份还算好一点,但跟官网上的回答相比,差距还是很大
请教一下大模型相关的朋友,这种情况是因为什么而发生的?

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)