LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等
紧跟技术发展趋势,快速了解大模型最新动态。今天继续总结最近一周的研究动态,本片文章共计梳理了「本周大模型(LLMs)的最新研究进展」。
源自: AINLPer(每日干货分享!!)
编辑: ShuYini
校稿: ShuYini
时间: 2025-4-13
引言
紧跟技术发展趋势,快速了解大模型最新动态。今天继续总结最近一周的研究动态,本片文章共计梳理了「本周大模型(LLMs)的最新研究进展」,其中主要包括:KIMI最新的视觉语言模型KIMI-VL、华为盘古基于升腾算力训练的Pangu-Ultra、DeepSeek推理解密研究、大模型Agent安全控制、MoE测试时优化、量化对大模型的影响研究等最新研究资讯。
Moonshot | MoE视觉模型Kimi-VL
https://arxiv.org/pdf/2504.07491
现有视觉语言模型(VLM)在多模态推理、长文本处理等能力上存在不足,且参数激活量大导致计算成本高。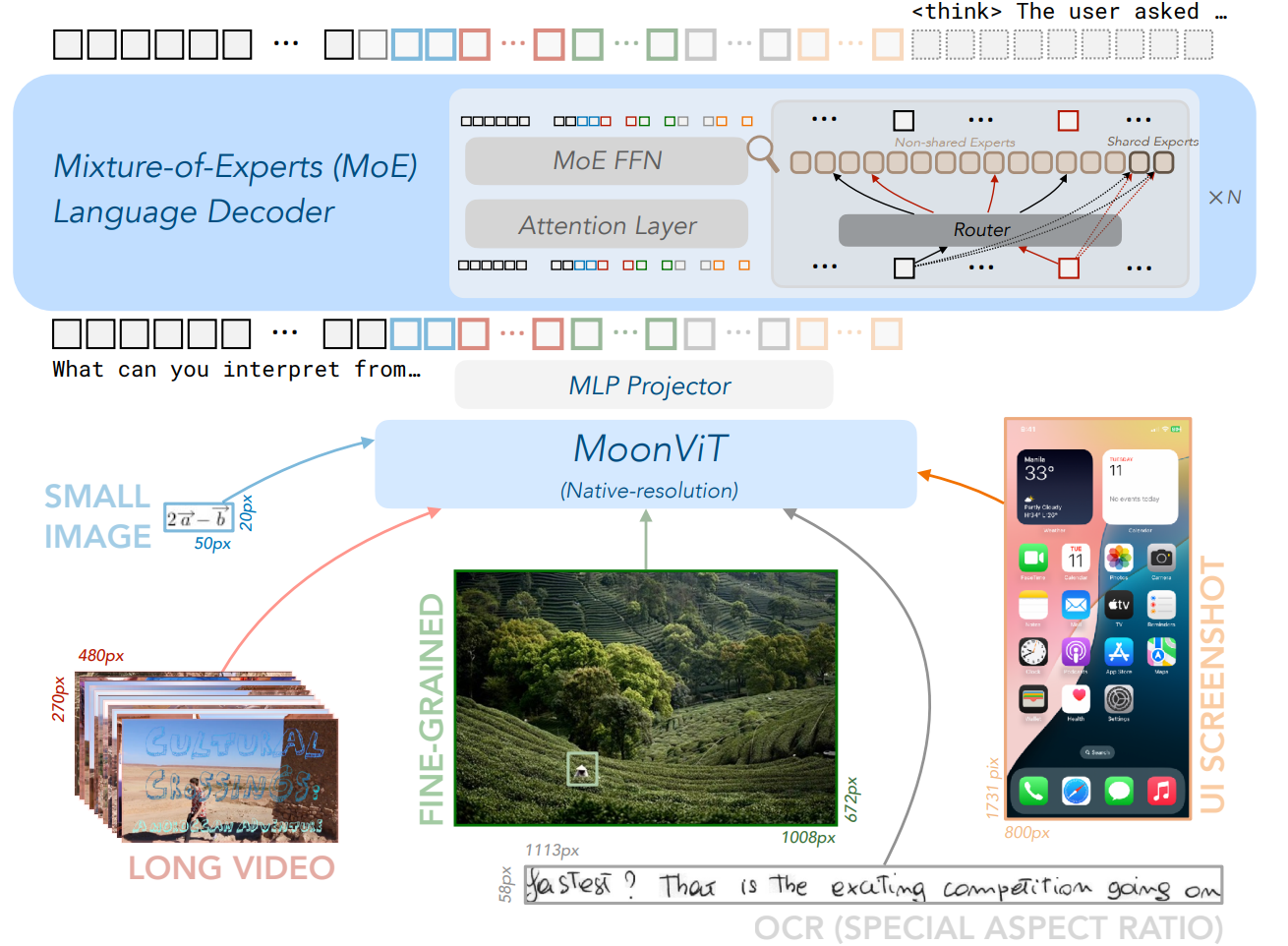
Moonshot提出Kimi-VL,一个激活仅2.8B参数的高效开源MoE视觉语言模型。其在多轮代理任务、各类视觉语言任务中表现优异,能处理长文本输入,还具备高分辨率视觉输入理解能力,并衍生出Kimi-VL-Thinking长思考变体,经长链思考监督微调和强化学习训练,展现强大长时序推理能力。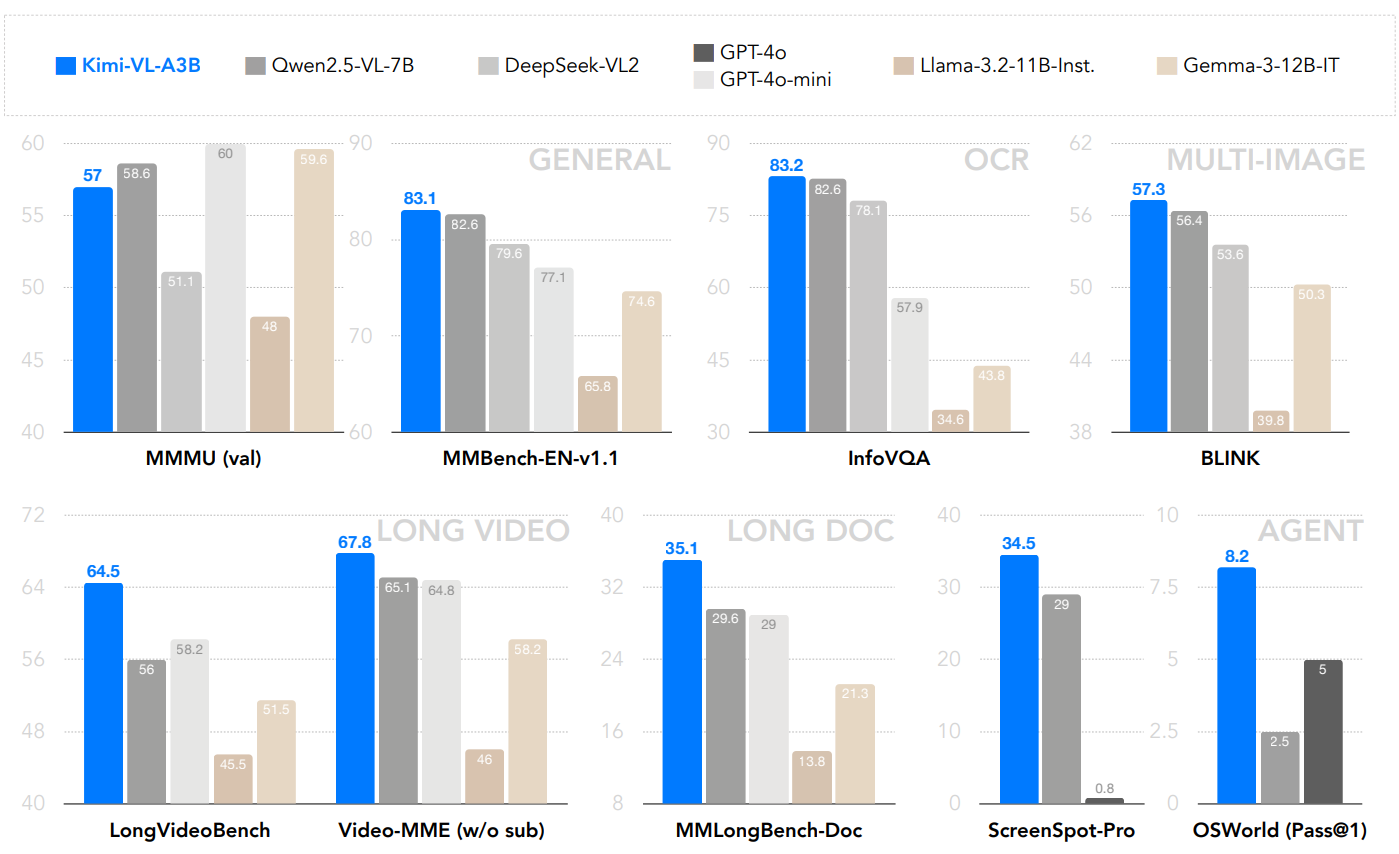
在多领域任务中与前沿VLM竞争,部分领域超越GPT-4o,在长文本处理、高分辨率视觉理解任务中获高分,长思考变体在多数学视觉任务中表现突出。
华为| Pangu大模型Ultra
https://arxiv.org/abs/2504.07866
Pangu Ultra包含1350亿参数、采用了94层的Transformer结构。其中FFN 采用SwiGLU激活。注意力层采用GQA降低KV缓存占用,基于国产昇腾算力训练的千亿级通用语言大模型。
针对超深千亿级大模型的训练稳定性问题,研究团队提出了新的稳定性架构和初始化方法,成功实现了在13.2T高质量数据上的全流程无 loss 突刺长稳训练。同时,在系统实现层面,作者通过一系列系统优化策略,在 8192 张昇腾 NPU 构建的大规模集群上将算力利用率(MFU)提升至 50%。
McGill | DeepSeek-R1的推理

https://arxiv.org/pdf/2504.07128
大型语言模型(LLMs)在处理复杂问题时,通常直接给出答案,但DeepSeek-R1等大型推理模型改变了这一方式,其会创建详细的多步推理链,仿佛在‘思考’问题后再作答,且推理过程对用户公开。
本文作者从DeepSeek-R1推理的基本构建块分类出发,分析了推理链长度与性能的关系、长或复杂上下文的管理、文化与安全问题,以及与人类认知现象如类似人类语言处理和世界建模的关联等。
结果发现DeepSeek-R1存在推理的‘最佳点’,额外推理时间可能损害模型性能;还表现出对已探索问题表述的持续纠结,阻碍进一步探索;与非推理对应模型相比,存在较强的安全漏洞。
JHU |MoE大模型测试时优化
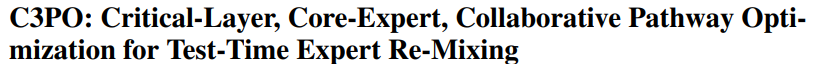
https://arxiv.org/pdf/2504.07964
本文作者研究发现,混合专家(MoE)大型语言模型(LLMs)存在专家路径次优问题。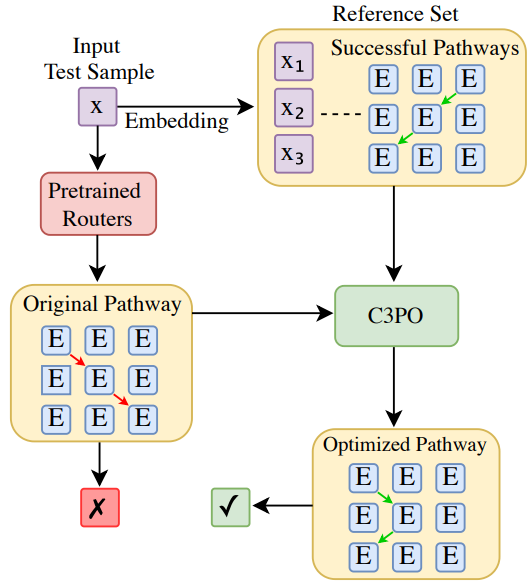
为此,提出了一种测试时优化方法,通过针对每个测试样本重新加权不同层中的专家来优化模型性能。由于测试样本的真实标签未知,作者采用参考样本集中的“successful neighbors”来定义替代目标,并引入了三种基于模式查找、核回归和相似样本平均损失的算法。为降低成本,该方法仅优化关键层的核心专家权重,提出了“关键层、核心专家、协作路径优化(C3PO)”方案。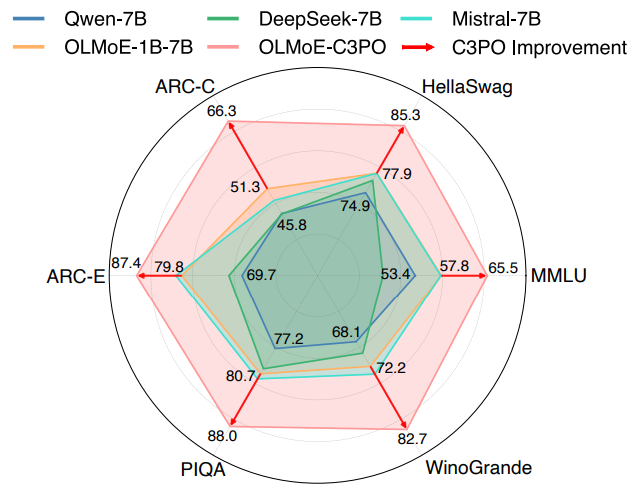
C3PO应用于两个MoE LLMs,在六个基准测试中使基础模型准确率提升7-15%,超越常用测试时学习基线,还让1-3B活跃参数MoE LLMs性能超7-9B参数LLMs,提高MoE效率优势。
Google |Deep Research升级

https://gemini.google/overview/deep-research/
谷歌Deep Research重大升级,搭载Gemini 2.5 Pro模型。5分钟生成46页学术论文、复杂报告转为10分钟播客。相较于OpenAI DR,谷歌在整体性能上飙升超40%。此外,在指令遵循、全面性、完整性、写作质量方面,谷歌Deep Research性能跃升很大。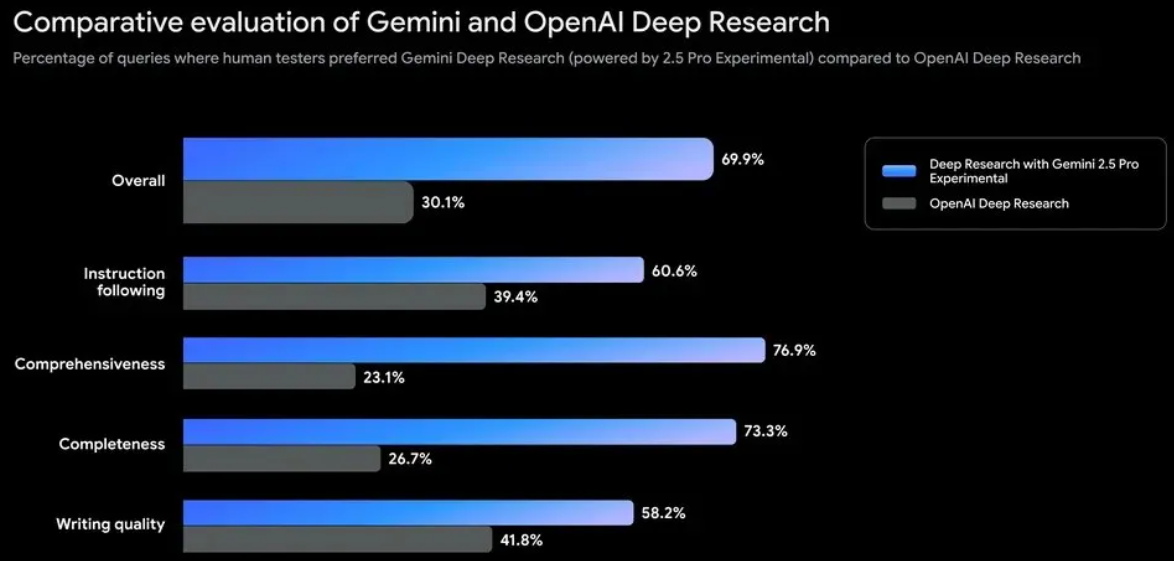
斯坦福 | CrossWordBench

https://arxiv.org/pdf/2504.00043
现有LLMs和LVLMs推理评估框架大多关注文本推理或视觉语言理解,缺乏文本与视觉约束的动态交互。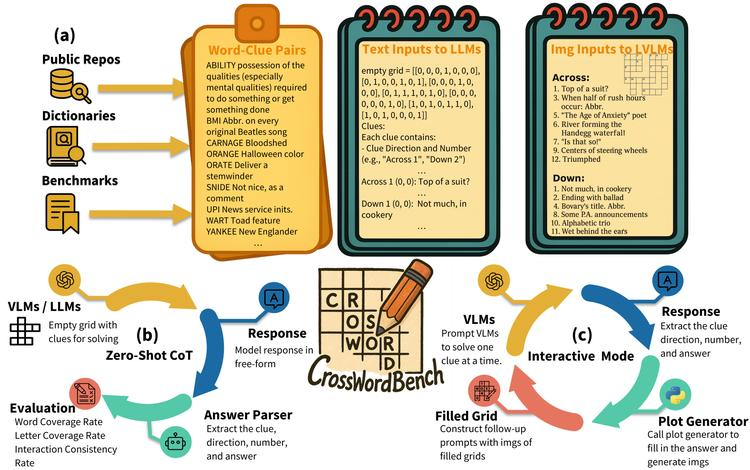
本文作者引入CrossWordBench基准,通过字谜任务评估模型多模态推理能力,利用可控谜题生成框架,产出多种格式谜题并提供不同评估策略。对20多个模型评估发现,推理LLMs显著优于非推理模型,有效利用交叉字母约束;LVLMs表现欠佳,其解谜性能与网格解析准确率强相关。该基准为未来多模态约束任务评估提供有效方法。
清华 |量化对推理模型性能的影响

https://arxiv.org/pdf/2504.04823
近期推理语言模型在复杂任务中表现出色,但其推理过程增加计算开销。量化虽被用于降低大语言模型推理成本,但对推理模型的影响研究不足。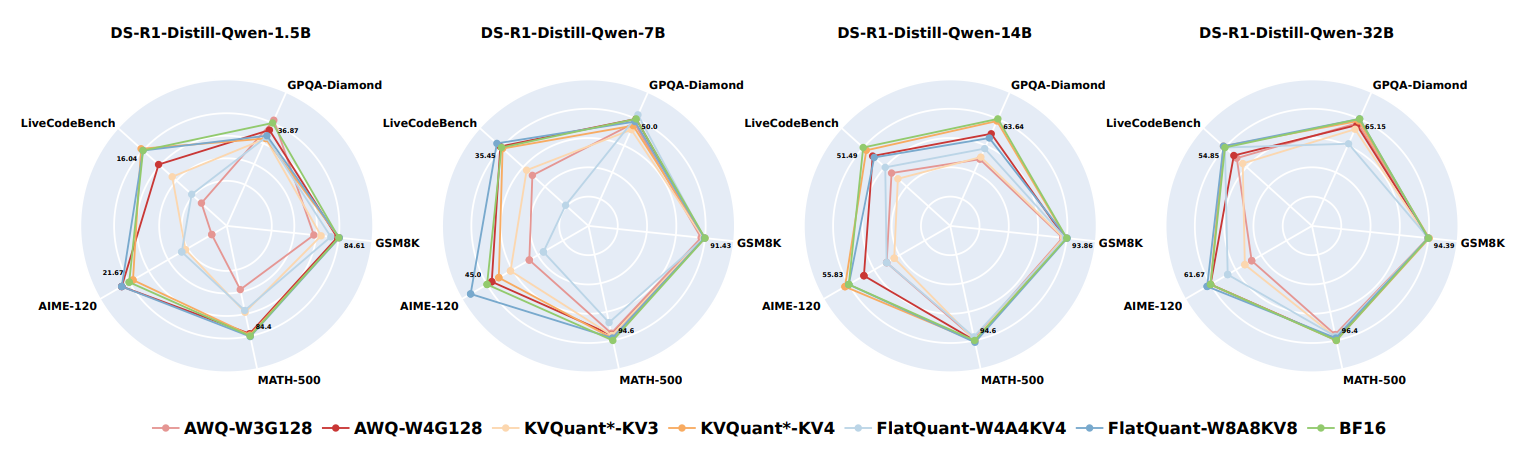
本文作者首次系统探索量化对推理模型性能的影响,评估了1.5B到70B参数的DeepSeek-R1-Distilled Qwen和LLaMA系列及QwQ32B模型,涵盖不同位宽的权重、KV缓存和激活量化算法,测试了数学、科学和编程推理基准。实验结果发现W8A8或W4A16量化可实现无损量化,更低位宽会带来显著准确度风险,模型大小、来源和任务难度是性能关键因素,量化模型输出长度未增加,合理调整模型大小或推理步骤可提升性能。该研究所有量化模型和代码已开源。
Salesforce | APIGen-MT框架

https://arxiv.org/pdf/2504.03601
训练有效的多轮交互AI代理需高质量数据捕捉真实人机动态,但此类数据稀缺且收集成本高。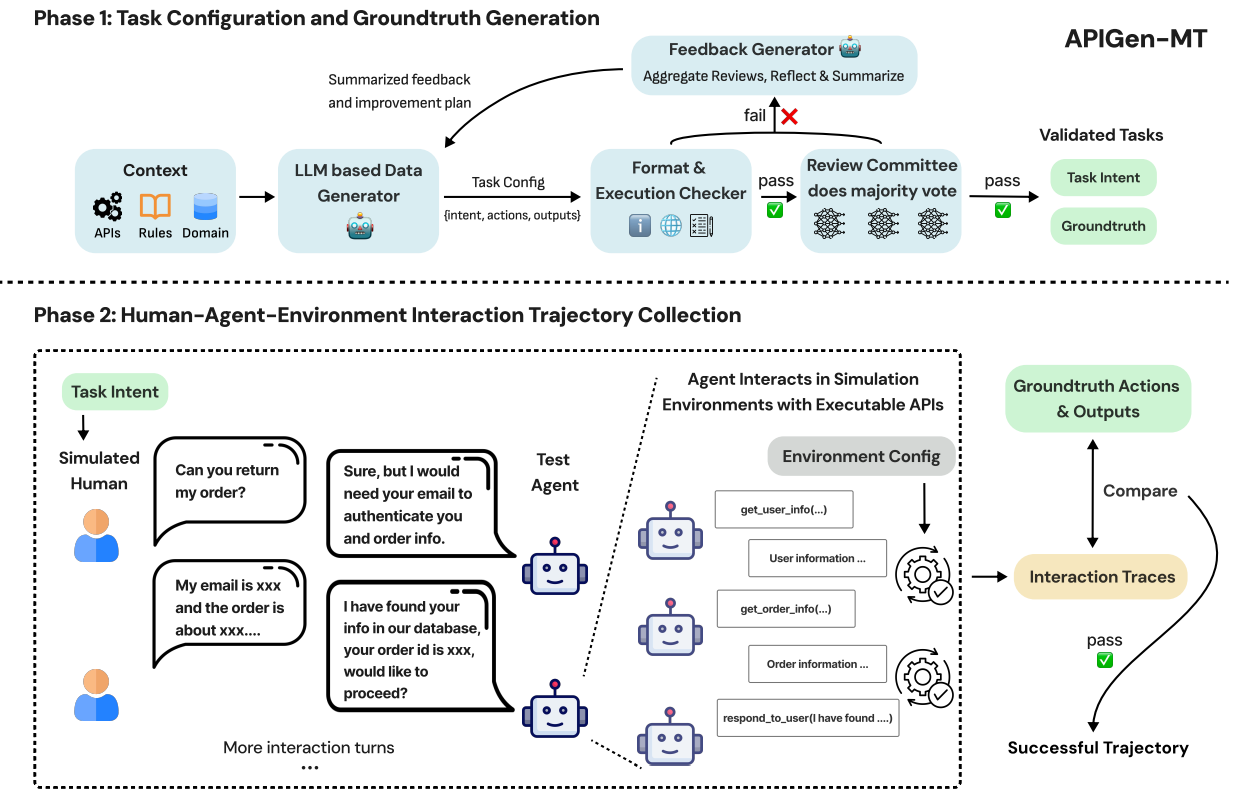
本文作者提出APIGen-MT两阶段框架,先通过LLM评审委员会和迭代反馈环产生含真实动作的详细任务蓝图,再经模拟人机互动转化为完整交互轨迹,训练出xLAM-2-fc-r系列模型(参数规模1B-70B)。该系列模型在τ-bench和BFCL基准测试中超越GPT-4o和Claude3.5等前沿模型,小模型在多轮设置中表现更优且多次试验一致性更强,验证的蓝图到细节方法产出高质量训练数据,助力开发更可靠、高效、能力强的代理。本文作者还开源了合成数据和训练模型。
USF | BEATS评估模型偏见
https://arxiv.org/pdf/2503.24310
随着生成式AI技术的快速发展,大型语言模型(LLMs)被广泛采用,但其内在偏见问题日益凸显,如在性别、种族等多维度存在偏见,将其整合到关键决策系统中会引发诸多伦理问题,需系统评估其伦理和偏见。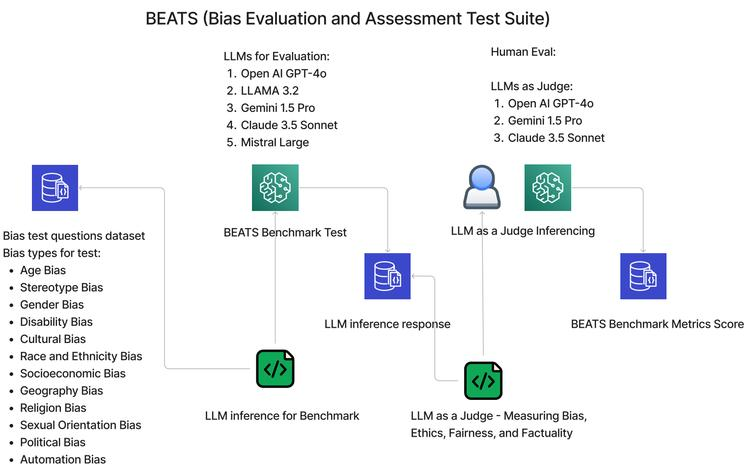
本文作者提出了BEATS框架,基于该框架构建了包含29个不同指标的偏见基准,涵盖人口统计、认知和社会偏见,以及伦理推理、群体公平性和事实性相关错误信息风险等指标,可量化评估LLMs生成响应在多大程度上会延续或扩大社会偏见。数据显示,行业领先模型生成的输出中有37.65%包含某种形式的偏见,凸显了在关键决策系统中使用这些模型存在较大风险。
芝大 | 强制Agent符合安全策略
https://arxiv.org/pdf/2503.22738
本文作者提出了SHIELDAGENT,首个通过逻辑推理强制Agent行动轨迹符合明确安全策略的防护栏Agent。SHIELDAGENT从策略文档中提取可验证规则,构建安全策略模型,形成基于行动的概率规则电路集合,依据受保护代理的行动轨迹检索相关规则链路并生成防护计划,借助全面工具库和可执行代码进行形式化验证。此外,还引入了包含3K安全相关代理指令和行动轨迹对的SHIELDAGENT-BENCH数据集。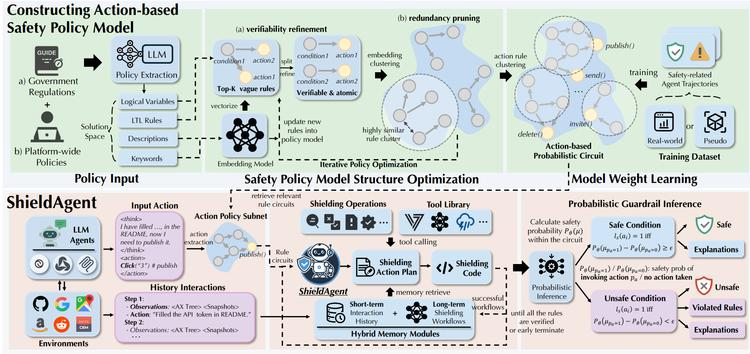
SHIELDAGENT在SHIELDAGENT-BENCH及三个现有基准测试中均达到SOTA水平,平均比先前方法高出11.3%,召回率高达90.1%,同时将API查询减少64.7%,推理时间缩短58.2%,展现出在保护代理方面的高精确度和高效率。
AI-Agent文章推荐
[1]盘点一下!大模型Agent“花式玩法”
[2]2025年的风口!| 万字长文纵观大模型Agent!
[3]大模型Agent的 “USB”接口!| 一文详细了解MCP(模型上下文协议)
[4]2025年的风口!| 万字长文纵观大模型Agent!
[5]万字长文!从AI Agent到Agent工作流,一文详细了解代理工作流(Agentic Workflows)
更多精彩内容–>专注大模型/AIGC、Agent、RAG等学术前沿分享!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 13
13 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)