Transformer的解析---ChatGPT4o作答+飞天闪客:Transformer 其实是个简单到令人困惑的模型【白话DeepSeek06】
Transformer 是一种极具创新性的模型架构,其自注意力机制使其能够处理长程依赖问题,且具备高度的并行化能力。这使得 Transformer 在 NLP 任务中取得了巨大的成功,并推动了许多其他领域的应用。
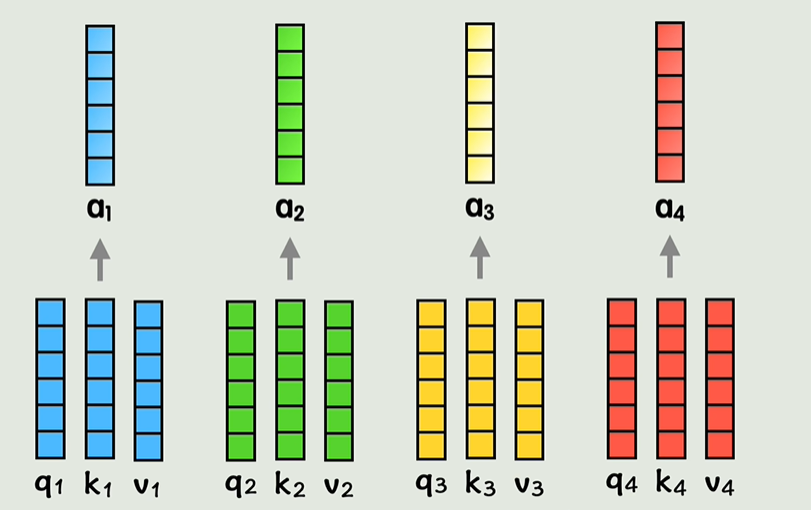
查询(query)、键(key)、值(value)
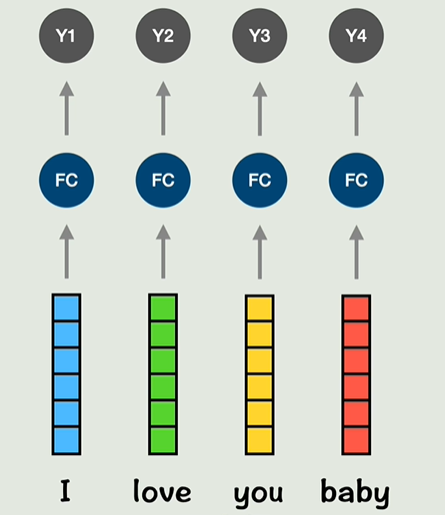
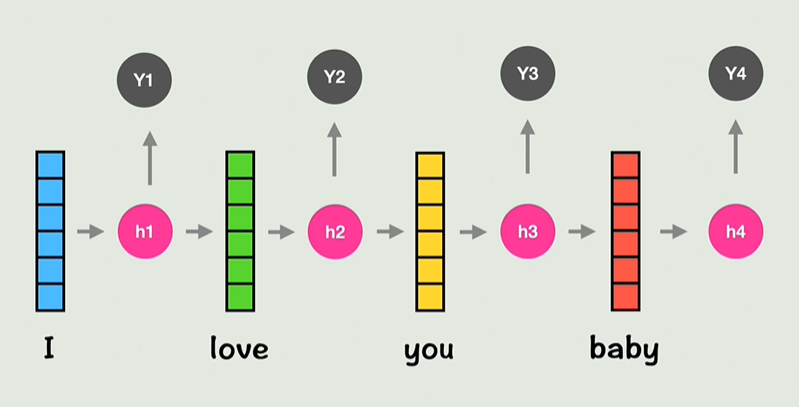
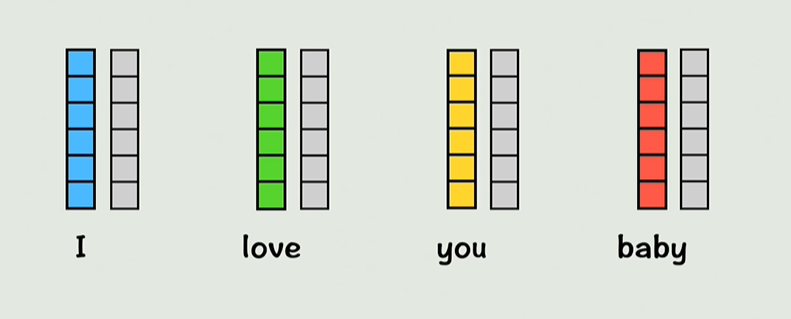
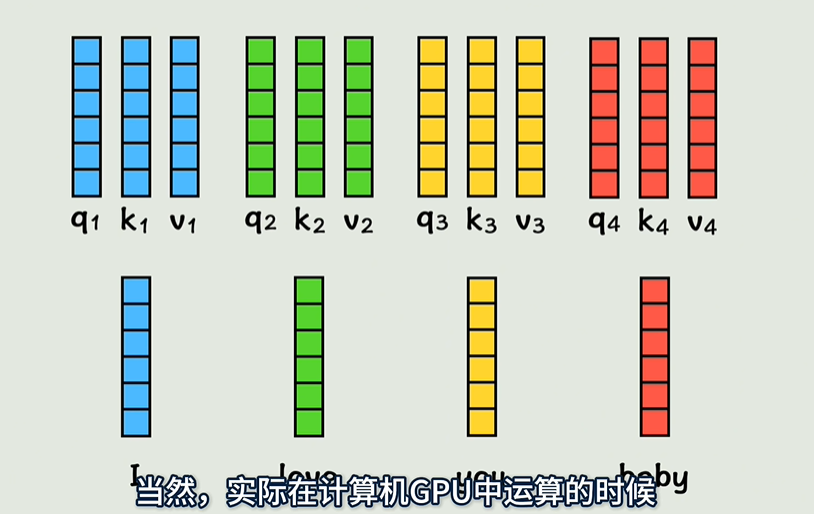
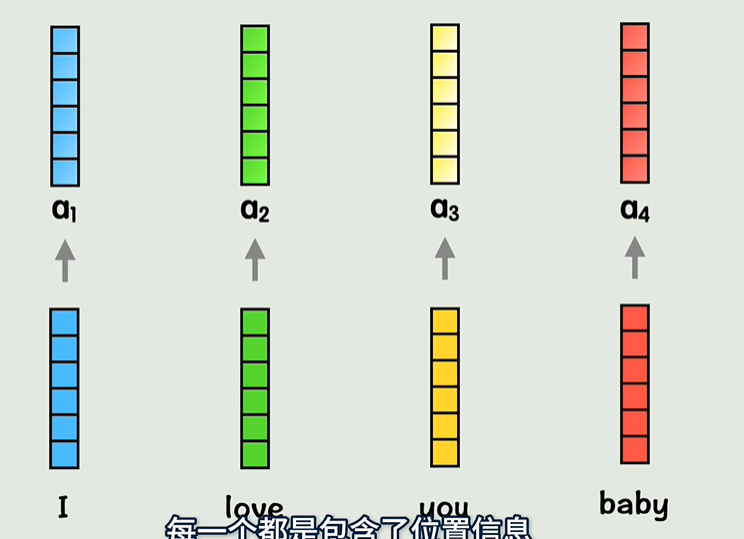
新的词向量包含了位置信息和上下文信息
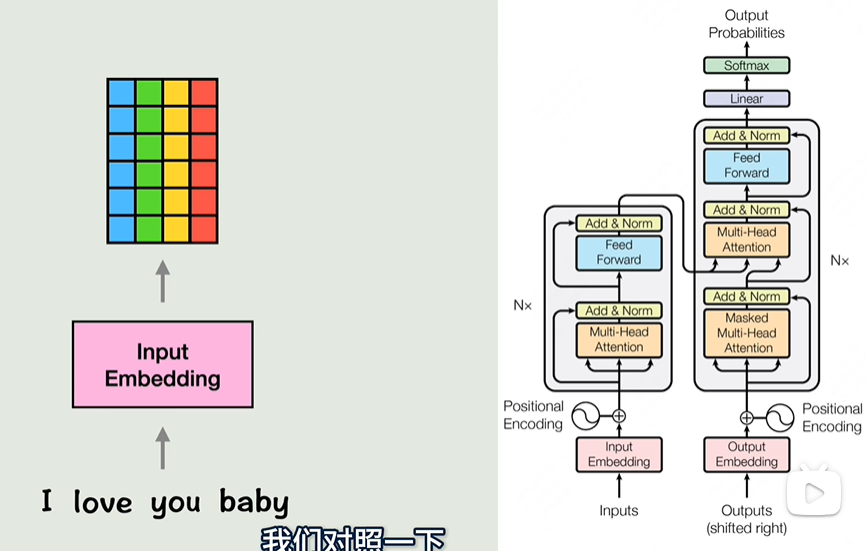

Transformer 是一种深度学习模型架构,最初由 Vaswani 等人在 2017 年的论文《Attention is All You Need》中提出。Transformer 模型的核心创新是“自注意力机制”(Self-Attention),它克服了传统循环神经网络(RNN)和长短期记忆网络(LSTM)在处理长距离依赖时的不足。Transformer 在自然语言处理(NLP)任务中,尤其是机器翻译领域,取得了突破性的成功。之后,它被广泛应用于各种任务,包括文本生成、语音识别、图像处理等。
Transformer 的基本组成部分
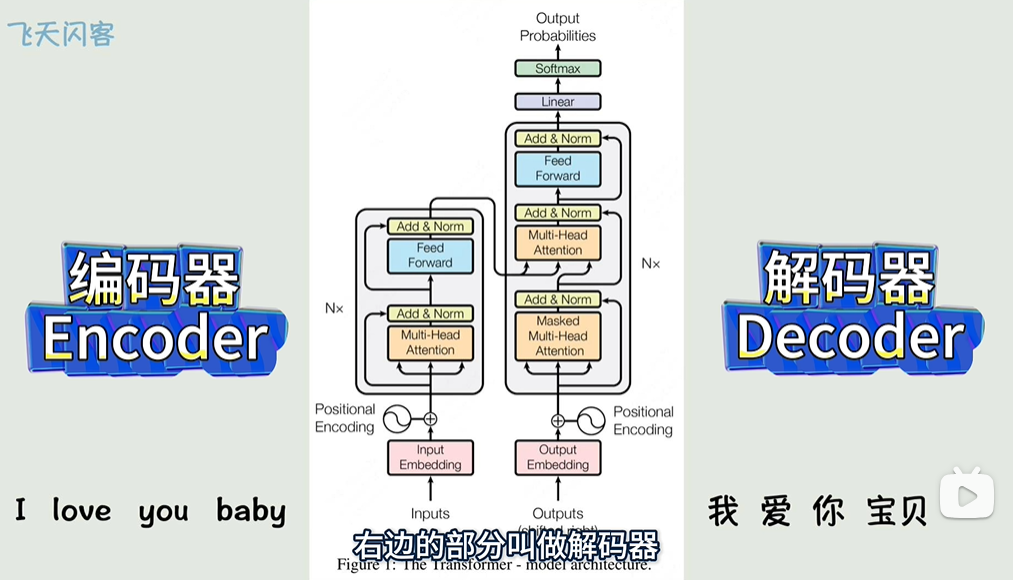
Transformer 模型可以分为两部分:
- 编码器(Encoder)
- 解码器(Decoder)
每个部分都是由多个相同结构的层堆叠而成。
1. 编码器(Encoder)
编码器的作用是将输入数据(例如一句话的单词序列)转换为一种固定长度的上下文向量,供解码器使用。每一层的编码器包含以下几个部分:
- 自注意力机制(Self-Attention):通过计算序列中每个单词与其他单词之间的关系来提取信息,使模型能够处理输入中各部分之间的依赖关系。
- 前馈神经网络(Feed-Forward Neural Network):对每个位置的表示进行非线性变换。
- 层归一化(Layer Normalization):提高训练速度和稳定性。
- 残差连接(Residual Connection):帮助避免梯度消失问题,使模型训练更加稳定。
每个编码器层的输入会先通过自注意力机制处理,再通过前馈神经网络处理,最后通过层归一化和残差连接得到输出。
2. 解码器(Decoder)
解码器的任务是根据编码器生成的上下文向量,逐步生成目标序列(例如翻译后的句子)。解码器也由多个相同结构的层堆叠而成,每一层包含:
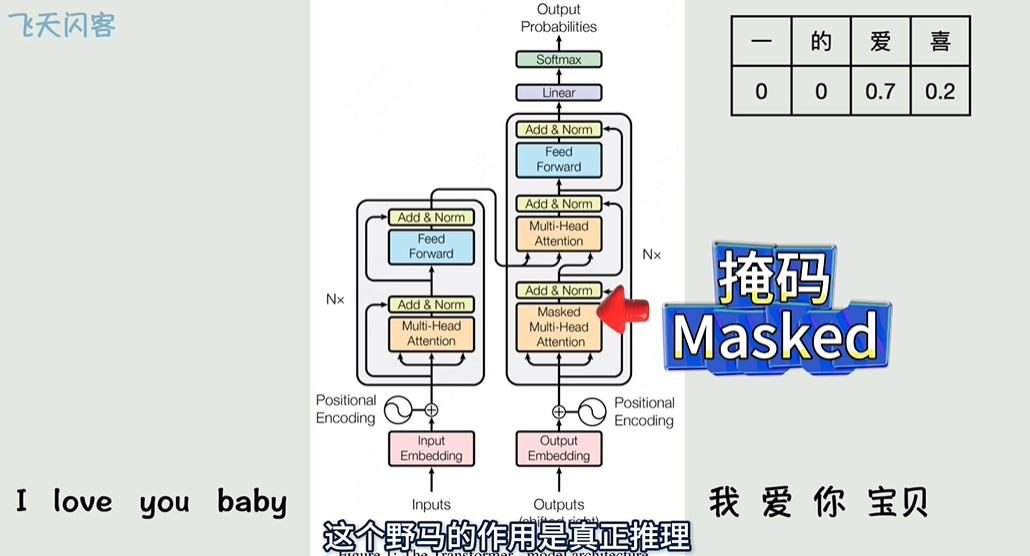
- 自注意力机制(Self-Attention):与编码器中的自注意力机制相似,但解码器中的自注意力机制有一个屏蔽机制(masking),确保模型只能看到已生成的部分。
- 编码器-解码器注意力(Encoder-Decoder Attention):解码器会通过这种注意力机制与编码器的输出进行交互,从而获得关于输入序列的信息。
- 前馈神经网络(Feed-Forward Neural Network):同样是对解码器中的每个位置进行非线性变换。
- 层归一化(Layer Normalization):与编码器相同。
解码器的输出通过一个线性层和 Softmax 激活函数转换成词汇表中每个单词的概率分布,用于生成下一个单词。
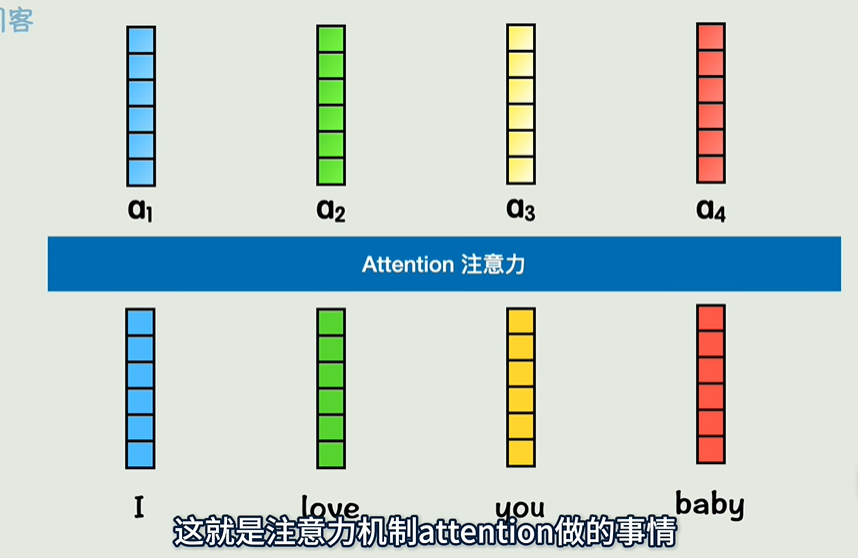
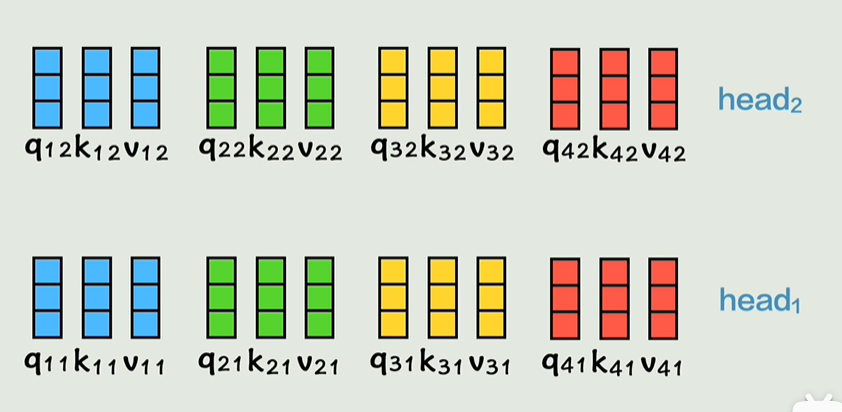
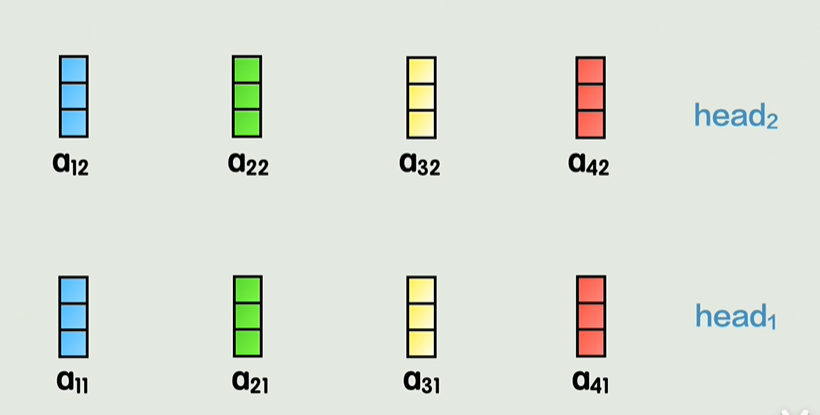
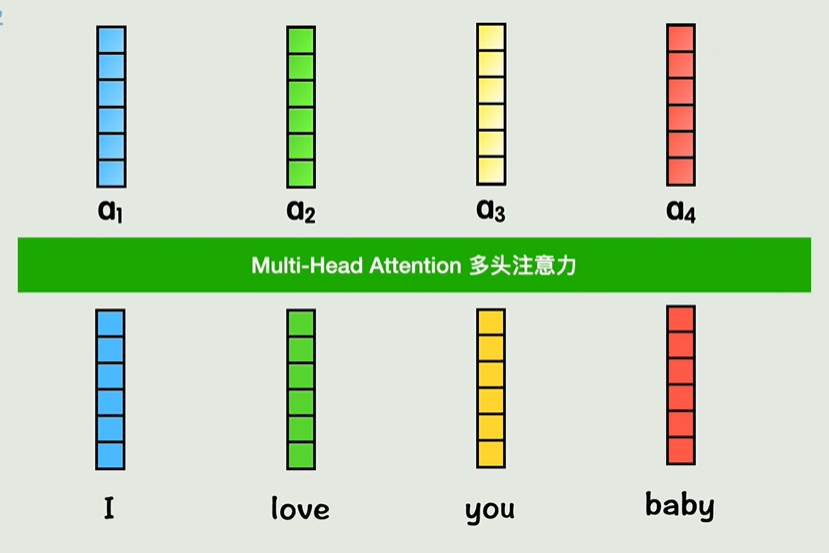
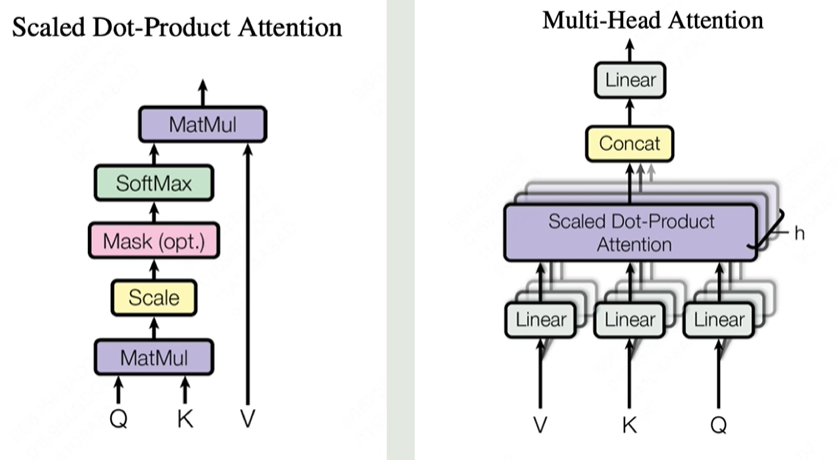
自注意力机制(Self-Attention)
自注意力机制是 Transformer 中的核心,它的目的是通过衡量一个序列中各个位置之间的关系来重新表示每个位置。具体步骤如下:
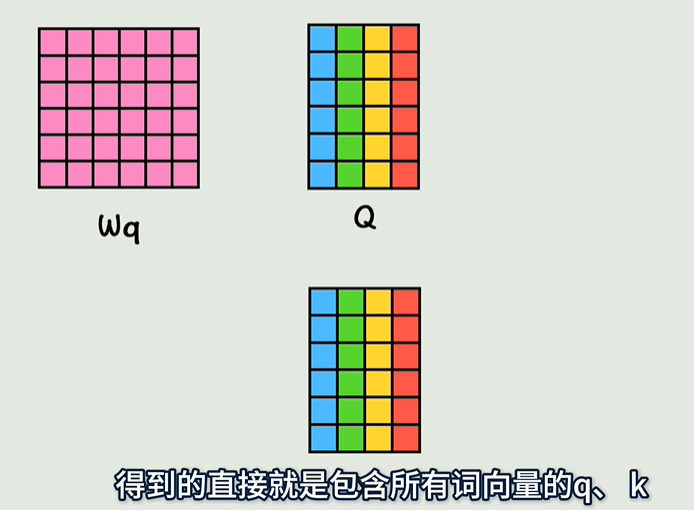
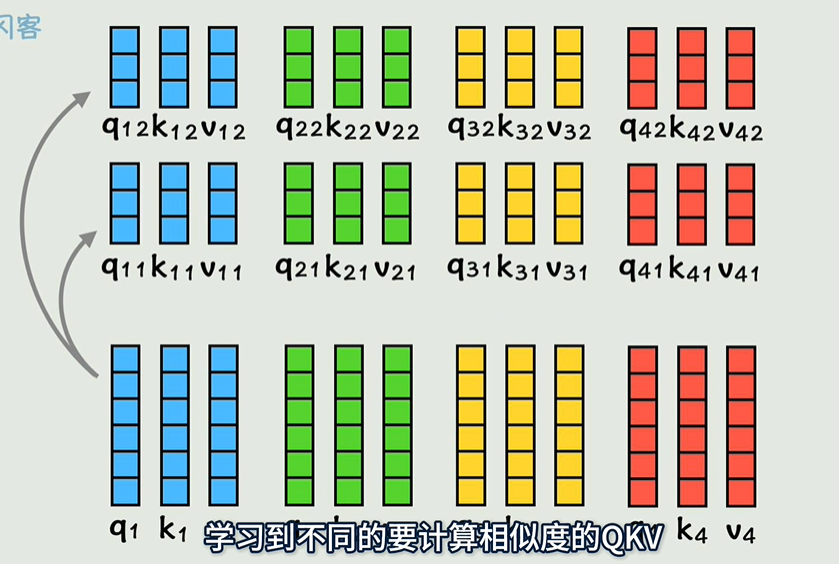
- 查询、键、值(Query, Key, Value):每个输入单词会映射成三个向量,分别是查询(Q)、键(K)和值(V)。这些向量是通过对输入进行线性变换得到的。
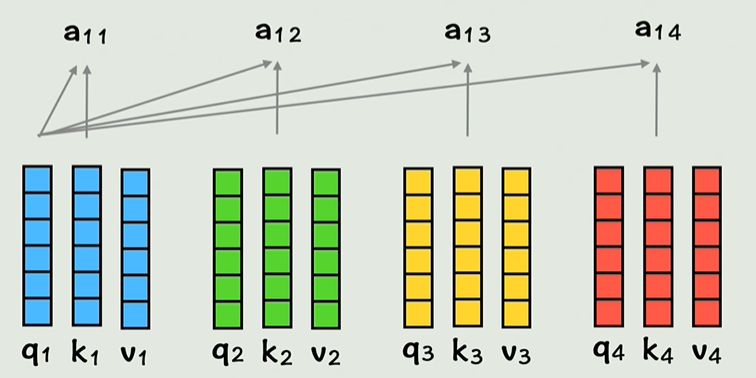
- 注意力权重计算:通过计算查询向量与所有键向量的点积,得到每对位置之间的相关性(即注意力权重)。然后对这些权重进行归一化(通常使用 Softmax 函数),以得到加权系数。
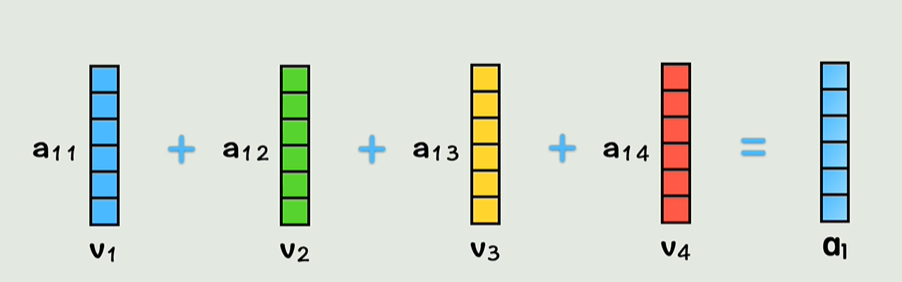
- 加权求和:每个位置的表示是所有值向量的加权和,权重由之前计算的注意力权重决定。
这种机制允许模型在处理输入时根据单词之间的相互关系进行加权,从而有效地捕捉序列中的长程依赖关系。
位置编码(Positional Encoding)
Transformer 模型不依赖于序列的顺序,因此需要通过位置编码来提供序列中单词的位置信息。位置编码会被加到输入的词向量中,使模型能够感知单词在序列中的顺序。常用的位置编码方式是基于正弦和余弦函数生成的位置编码,公式如下:
[
PE_{(pos, 2i)} = \sin \left( \frac{pos}{10000^{2i/d}} \right), \quad PE_{(pos, 2i+1)} = \cos \left( \frac{pos}{10000^{2i/d}} \right)
]
其中,pos 是单词的位置,i 是维度的索引,d 是词向量的维度。
Transformer 的优势
- 并行化处理:由于没有循环结构,Transformer 可以对输入序列进行并行处理,这大大提高了训练和推理的速度。
- 长距离依赖捕捉:自注意力机制能够直接捕捉序列中任意两个位置之间的关系,而不依赖于像 RNN 或 LSTM 那样的逐步传递信息,这使得 Transformer 在处理长程依赖时表现更好。
- 可扩展性:Transformer 的结构非常灵活,能够扩展到更大规模的模型(例如 GPT、BERT、T5 等),这使得它在各种任务中都能取得优异的表现。
Transformer 的变种
Transformer 自提出以来,已经衍生出许多变种,以下是一些典型的例子:
- BERT(Bidirectional Encoder Representations from Transformers):只使用 Transformer 编码器,通过双向训练来获得上下文信息,广泛用于分类、问答等任务。
- GPT(Generative Pre-trained Transformer):使用 Transformer 解码器,基于生成的方式进行预训练,主要用于文本生成任务。
- T5(Text-to-Text Transfer Transformer):将所有任务都转换为文本到文本的格式,具有更广泛的应用场景。
总结
Transformer 是一种极具创新性的模型架构,其自注意力机制使其能够处理长程依赖问题,且具备高度的并行化能力。这使得 Transformer 在 NLP 任务中取得了巨大的成功,并推动了许多其他领域的应用。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 9
9 0
0- 0



 已为社区贡献107条内容
已为社区贡献107条内容

所有评论(0)