重新审视使用大型推理模型进行提示优化——以事件提取为例的研究
Saurabh Srivastava & Ziyu Yao乔治梅森大学弗吉尼亚州费尔法克斯,邮编 22030,美国{ssrivas6,ziyuyao}@gmu.edu大型推理模型(LRMs)如 DeepSeek-R1 和 OpenAI o1 在各种推理任务中展示了卓越的能力。它们强大的生成和推理中间思维的能力也引发了这样的争论:它们可能不再需要广泛的提示工程或优化来解释人类指令并产生准确的输出。在
Saurabh Srivastava & Ziyu Yao
乔治梅森大学
弗吉尼亚州费尔法克斯,邮编 22030,美国
{ssrivas6,ziyuyao}@gmu.edu
摘要
大型推理模型(LRMs)如 DeepSeek-R1 和 OpenAI o1 在各种推理任务中展示了卓越的能力。它们强大的生成和推理中间思维的能力也引发了这样的争论:它们可能不再需要广泛的提示工程或优化来解释人类指令并产生准确的输出。在本研究中,我们旨在系统地研究这一开放性问题,使用结构化任务——事件提取作为案例研究。我们对两个 LRMs(DeepSeek-R1 和 o1)以及两个通用大型语言模型(LLMs)(GPT-40 和 GPT-4.5)进行了实验,当它们用作任务模型或提示优化器时。我们的结果显示,在像事件提取这样复杂的任务中,LRMs 作为任务模型仍然从提示优化中受益,并且使用 LRMs 作为提示优化器可以产生更有效的提示。最后,我们对 LRMs 常见错误进行了错误分析,并强调了 LRMs 在细化任务指令和事件指南中的稳定性和一致性。
1 引言
近年来,大型语言模型(LLMs)在各种自然语言处理任务中表现出显著的能力。然而,它们在复杂推理任务中的熟练程度常常受到限制(Zhou 等人,2022)。为了解决这个问题,一类新的模型——大型推理模型(LRMs)已经出现,专注于通过先进的训练方法增强推理能力。一个突出的例子是 DeepSeek-R1(Guo 等人,2025),这是一个开源的 LRM,在多个推理基准测试中取得了最先进的性能,包括 MATH-500(Lin 等人,2025)和 SWEbench Verified(Jimenez 等人,2023)。同样,OpenAI 的 o1(Zhong 等人,2024)在推理任务中设定了新的标准,在复杂问题解决场景中展示了优越的性能。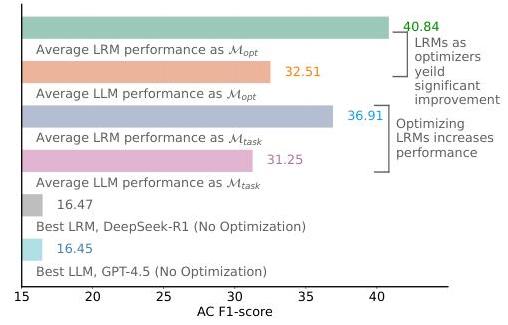
图 1: 我们主要结果的总结,其中 LRMs 和 LLMs 被用作任务模型 (Mtask )\left(\mathcal{M}_{\text {task }}\right)(Mtask ) 或优化器 (Mopt )\left(\mathcal{M}_{\text {opt }}\right)(Mopt ) 进行提示优化,我们观察到 LRMs 相较于 LLMs 具有显著优势。
这些先进推理模型的出现引发了关于提示优化必要性的讨论(Wang 等人,2024a;OpenAI,2025;Mantaras,2025;Together AI,2025;Menendez 等人,2025),即通过改进输入提示有效地引导模型输出的过程(Zhou 等人,2022;Yang 等人,2024;Srivastava 等人,2024;Agarwal 等人,2024;Guo 等人,2024;Fernando 等人,2024;Li 等人,2025)。传统上,提示优化对于提高 LLM 性能至关重要,PromptAgent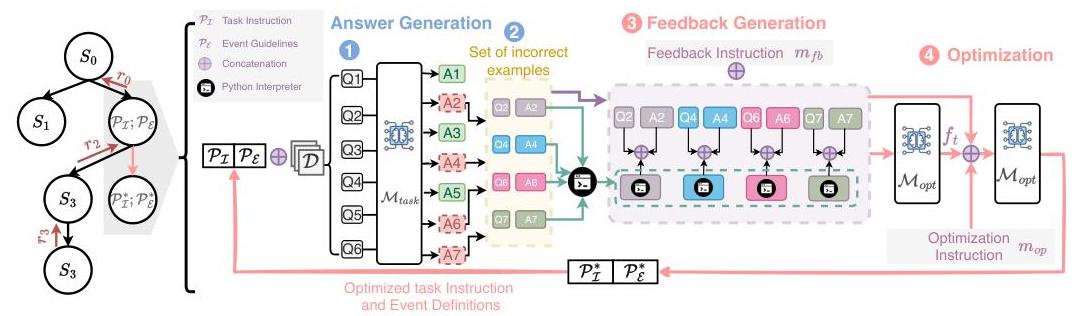
图 2: 使用语言模型的提示优化框架概述。在每次迭代中,零样本任务 LLM 生成输出,而单独的优化器 LLM 分析错误并相应更新提示,包括任务指令和事件指南。这个过程在训练样本批次 Dtrain \mathcal{D}_{\text {train }}Dtrain 上继续进行,最终优化后的提示在开发集上进行评估,以确定节点奖励 rtr_{t}rt。
(Wang 等人,2024b) 和 OPRO (Yang 等人,2024) 通过迭代反馈和战略规划自动化创建和细化提示。然而,LRMs 如 DeepSeek-R1 和 o1 的固有推理能力引发了这些问题:提示优化技术对这些模型是否同样有益。尽管先前的研究表明提示优化在改善 LLM 性能方面的有效性,但在其对 LRMs 影响的研究中存在明显的空白。此外,许多现有的提示优化研究集中在零样本基线已经表现良好的任务上,而最近的工作,如 Gao 等人(2024),表明即使是强大的模型如 GPT-4 也在信息提取任务中挣扎,突显了对更针对性和优化的提示策略的需求。我们在附录 A 中讨论相关工作。
为了填补这一空白,我们针对 LRMs 进行了首次系统的提示优化研究,并将其性能与 LLMs 进行比较。特别是,我们在一个具有挑战性的任务上对这些模型进行了实验,即端到端事件提取(EE),这是一种信息提取的结构化预测任务,要求识别和分类文本中的事件触发器及其参数。EE 提出了独特的挑战:模型必须遵循模式约束,处理共指,并在精确度和召回率之间取得平衡,所有这些都需要细致的推理。我们评估了四个模型,两个 LRMs(DeepSeek-R1,o1)和两个 LLMs(GPT-4.5,GPT-4o),在蒙特卡罗树搜索(MCTS)框架内(Wang 等人,2024b)作为任务模型和提示优化器。这种设置使我们能够在一致的环境中检查任务性能和提示优化质量。我们的发现围绕以下研究问题组织:
- LRMs 是否从提示优化中受益?我们发现 LRMs 如 DeepSeekR1 和 o1 在提示优化中显示出显著的收益,不仅超越了它们未优化的版本,还超越了 LLMs,即使在训练集极小的情况下,也显示了即使是强推理模型仍显著受益于提示优化。
-
- LRMs 在完整的 MCTS 提示优化下如何表现?使用我们的基于 MCTS 的框架,我们分析了模型性能随优化深度的变化。LRMs 比 LLMs 更一致地扩展,收敛更快且方差更小。例如,DeepSeek-R1 在深度 2 时达到峰值性能,而 LLMs 需要更深的探索并且仍然表现较差。
-
- LRMs 是否能成为更好的提示优化器?当用作优化器时,LRMs 通常生成高质量的提示,尤其是 DeepSeek-R1 通常比 LLMs 产生更短、更精确的提示。这些提示包含提取规则和例外情况,反映了人类注释指南,从而提高了下游任务性能。
-
- LRMs 是否可以在提示优化中充当高效且稳定的优化器?当用作优化器时,LRMs 引导模型更高效地达到峰值性能。它们帮助任务模型在较浅的 MCTS 深度实现收敛,同时在节点间方差更低,表明更快且更稳定。
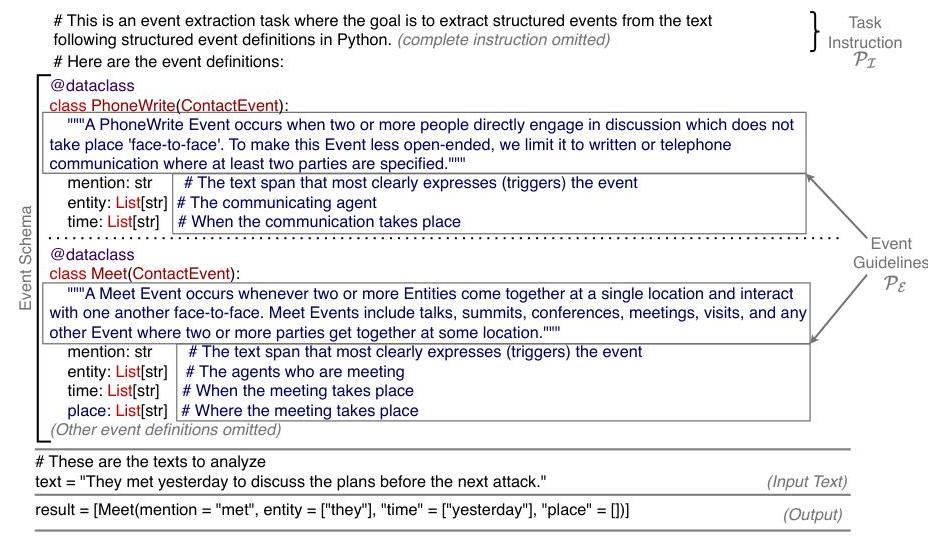
图 3: 代码提示由任务指令和事件模式组成。事件模式包含表示标签的信息,这些标签被表示为 Python 类,并定义了事件类和参数。在提示优化中,我们细化了任务指令和事件指南(仅展示两个事件;其他因篇幅限制省略),以生成更有效的任务模型提示。
最后,我们的分析表明 LRMs 通常产生更有效的提示。这些优化后的提示通常包括特定任务的启发式方法和异常处理规则,有助于减少常见的触发器相关错误,如识别多个或隐含事件,并稍微缓解参数级别的错误,如共指和跨度过度预测。在我们所有的实验模型中,DeepSeek-R1 产生了最短(但最有效)的提示。有趣的是,我们观察到较长的提示并不一定是更有效的提示,各种任务模型可能对不同长度的提示有不同的偏好。这些发现与提示 LRMs 的指导方针一致(Mantaras,2025;Together AI,2025;OpenAI,2025),建议使用简洁、聚焦的指令,避免冗余或过于复杂的措辞,但同时向模型提供必要的任务规范。我们的研究表明,即使使用 LRMs,提示优化仍然是有价值的,通过自动优化提示使其任务导向但简洁。
2 方法论
2.1 问题设定
离散提示优化旨在不修改模型权重的情况下,为 LLM Mtask \mathcal{M}_{\text {task }}Mtask 细化任务特定提示以提高其性能。在这项研究中,我们分析了 LRMs 在端到端 EE 上是否从提示优化中受益。任务包括触发器提取,涉及识别事件触发器跨度并分类其事件类型,以及参数提取,需要在提取的事件实例中识别参数跨度并预定义角色。为了提示任务模型,Mtask \mathcal{M}_{\text {task }}Mtask ,我们采用了先前工作(Wang 等人,2023a;Sainz 等人,2024;Li 等人,2023;2024;Srivastava 等人,2025)证明有效的基于 Python 代码的输入和输出表示。如图 3 所示,初始提示 P0\mathcal{P}_{0}P0 包括两个主要部分:任务指令和由指南标注的事件模式。任务指令 PI\mathcal{P}_{\mathcal{I}}PI 构成了输入的初始段,介绍任务并指定诸如期望的输出格式等指令。事件模式包含有关标签的信息,例如表示为 Python 类的事件名称和参数角色。参数角色(例如时间、地点)被定义为事件类的属性。模式中的所有事件和参数都使用人工编写的指南 PI\mathcal{P}_{\mathcal{I}}PI 标注。输出表示为模式中定义的类的实例列表。在本文中,我们细化了 PI\mathcal{P}_{\mathcal{I}}PI 和 PE\mathcal{P}_{\mathcal{E}}PE,表示为串联 P0=[PI∥PE]\mathcal{P}_{0}=\left[\mathcal{P}_{\mathcal{I}} \| \mathcal{P}_{\mathcal{E}}\right]P0=[PI∥PE],其中 ∥\|∥ 表示串联。
给定一个训练集 Dtrain ={(Qi,Ai)}i=1N\mathcal{D}_{\text {train }}=\left\{\left(Q_{i}, A_{i}\right)\right\}_{i=1}^{N}Dtrain ={(Qi,Ai)}i=1N,其中每个 QiQ_{i}Qi 表示输入文本,AiA_{i}Ai 表示其相应的事件实例,提示优化的目标是发现一个最优提示 P∗\mathcal{P}^{*}P∗,以最大化特定任务的评估函数 R\mathcal{R}R,例如 EE 的 F-score。事件指南通常包含注释者在数据标注期间遵循的明确模式约束和隐含领域特定规则的组合。然而,并非所有这些规则都被完全记录或容易转化为单一静态提示。因此,初始提示 P0\mathcal{P}_{0}P0 可能缺乏高质量提取所需的批判性结构或解释线索。我们采用优化器 LLM Mopt \mathcal{M}_{\text {opt }}Mopt 来细化 P0\mathcal{P}_{0}P0,通过战略性规划发现这些规则和约束,以实现专家级提示优化。注意,我们不会修改原始 EE 任务定义的事件模式,而只会修改人工编写的任务指令和指南。
2.2 提示优化框架
我们将提示优化形式化为在庞大的自然语言提示空间 S\mathcal{S}S 上的离散搜索问题。由于 S\mathcal{S}S 太大而无法全面探索,我们采用蒙特卡罗树搜索(MCTS),这种方法非常适合具有大分支因子的离散搜索问题,以系统地探索提示空间。正如 Wang 等人(2024b)之前所示,与基于启发式的优化(Li 等人,2025)相比,MCTS 高效地平衡了探索(寻找新提示)和利用(细化以前的提示)。
类似于 Wang 等人(2024b),我们将提示优化视为马尔可夫决策过程(MDP),其中状态 sts_{t}st 表示提示 Pt\mathcal{P}_{t}Pt,即在第 ttt 次迭代时 st=Pts_{t}=\mathcal{P}_{t}st=Pt。在这种公式化中,动作可以被认为是当前提示的潜在修改,例如包含新的提取规则或模式约束。这些修改可以通过分析 Mtask \mathcal{M}_{\text {task }}Mtask 的错误并生成反馈来进行。因此,如图 2 所示,动作被框定为错误反馈,以指导后续提示的细化。正式地,树中的每个节点持有一个提示 Pt\mathcal{P}_{t}Pt 并连接一批输入查询 Qbatch Q_{\text {batch }}Qbatch 。在第一步,答案生成,我们根据 Abatch ′∼pMtask (A′∣Pt,Qbatch )A_{\text {batch }}^{\prime} \sim p_{\mathcal{M}_{\text {task }}}\left(A^{\prime} \mid \mathcal{P}_{t}, Q_{\text {batch }}\right)Abatch ′∼pMtask (A′∣Pt,Qbatch ) 生成响应 Abatch ′A_{\text {batch }}^{\prime}Abatch ′。提取出错误的响应(第二步),并通过 Python 解释器传递以识别问题,例如解析错误、未定义的事件类和幻觉跨度。接下来,在第三步中,每个错误的输入查询、预期输出和解释器输出被串联成单个序列以获得一组可行反馈 ftf_{t}ft,根据 ft∼pMopt (f∣st,mfb)f_{t} \sim p_{\mathcal{M}_{\text {opt }}}\left(f \mid s_{t}, m_{f b}\right)ft∼pMopt (f∣st,mfb),其中 mfbm_{f b}mfb 是一个元提示,指示 Mopt \mathcal{M}_{\text {opt }}Mopt 根据观察到的错误生成纠正反馈。最后,在第四步中,我们生成更新的任务指令和事件指南,Pt+1\mathcal{P}_{t+1}Pt+1,受控于 pMopt (st+1∣st,ft,mopt )p_{\mathcal{M}_{\text {opt }}}\left(s_{t+1} \mid s_{t}, f_{t}, m_{\text {opt }}\right)pMopt (st+1∣st,ft,mopt ),其中 mopt m_{\text {opt }}mopt 是另一个元提示,指导结合前一步骤反馈构建修订提示。我们在第 2.3 节中详细说明了步骤 3 和 4。优化循环通过迭代收集任务模型的错误、修改提示并评估改进,直到达到终止条件为止。
最后,我们通过保留集上的奖励函数 rt=R(st,ft)r_{t}=\mathcal{R}\left(s_{t}, f_{t}\right)rt=R(st,ft) 评估每个新生成状态 sts_{t}st 的质量,该保留集与给定的训练样本分开。由于 EE 涉及四个子任务,我们取所有子任务指标的平均 F 分数作为奖励函数,即 TI F 分数、TC F 分数、AI F 分数和 AC F 分数。根据 MCTS 过程中所有生成提示在开发集上的表现选择最佳提示。我们将在附录 B 中提供完整算法。
2.3 反馈生成和提示优化
在第三步中,我们利用元提示 mfbm_{f b}mfb 指导优化模型 Mopt \mathcal{M}_{\text {opt }}Mopt 根据任务模型 Mtask \mathcal{M}_{\text {task }}Mtask 在当前提示 Pt\mathcal{P}_{t}Pt 下的错误生成结构化反馈。具体而言,元提示指示 Mopt \mathcal{M}_{\text {opt }}Mopt 处理每个错误示例,识别错误类型,分析是否源于角色定义不清或不足,并建议有针对性的改进。这些改进
包括澄清模糊的角色,收紧提取规则,并完善事件指南中的指令。它还请求模型总结多个错误中的常见模式,以实现对任务指令的广泛调整。预期输出是一组可行的编辑,以改进事件定义和任务指令,包括示例特定和通用的编辑,以提高清晰度、覆盖范围和一致性。
在第四步中,我们根据分布 pMopt (st+1∣st,ft,mopt )p_{\mathcal{M}_{\text {opt }}}\left(s_{t+1} \mid s_{t}, f_{t}, m_{\text {opt }}\right)pMopt (st+1∣st,ft,mopt ) 生成更新的提示 Pt+1\mathcal{P}_{t+1}Pt+1,其中包括任务指令和事件指南。具体而言,元提示 mopt m_{\text {opt }}mopt 指示 Mopt \mathcal{M}_{\text {opt }}Mopt 在单次推理中生成更新的任务指令和更新的事件指南。为了防止优化器生成重复已探索轨迹的新提示,我们在 mopt m_{\text {opt }}mopt 中包含所有先前提示的历史。我们注意到,由于在每个优化步骤中只提供一批错误示例给优化器,因此并非所有事件类型都需要细化,因此我们不强制优化器更新每个事件类型。在我们的实验中,我们观察到优化器在应用反馈时表现出不同的行为。例如,我们观察到在大多数情况下,DeepSeek-R1 仅细化在第三步生成的反馈中明确提到的事件定义,而不触及其他事件定义。相比之下,一些优化器无论反馈是否表明需要修改,几乎都会重新生成所有事件定义。在我们的实现中,对于优化器未细化的事件类型,我们保留来自 Pt\mathcal{P}_{t}Pt 的父类定义而不做修改。
我们将在附录 B 中包含用于反馈生成 (mfb)\left(m_{f b}\right)(mfb) 和提示优化(mopt m_{\text {opt }}mopt )的提示模板。
3 实验
3.1 实验设置。
数据集。为了评估提示优化对 LRMs 的影响,我们在广泛使用的 ACE05 数据集(Doddington 等人,2004)上进行实验,这是 EE 的标准基准,提供了精细的事件区分。我们使用了 Huang 等人(2024)预处理的“split 1”,并进一步将其转换为 Python 代码格式。原始 ACE05 数据集包括 33 种事件类型。然而,我们的初步探索发现,将所有 33 种事件类型纳入提示优化可能导致过长的提示,这使得 LLMs 和 LRMs 都难以正确处理。为了消除这一混淆因素,同时评估 LRMs 是否需要和促进提示优化,我们在实验中缩小了 10 种事件类型的子集,并将长期上下文处理问题留作未来工作。
我们在实验中使用了两个较小版本的 ACE05 训练集。为了模拟低资源条件,我们构建了 ACElow \mathbf{A C E}_{\text {low }}ACElow 包含 15 个样本,其中每种事件类型选择一个实例,优先选择那些事件和参数注释密度较高的实例(即标注了多个事件实例的训练示例);其余样本是非事件实例。为了检查扩大训练规模的效果,我们还构建了一个中等规模的数据集,ACEmed \mathbf{A C E}_{\text {med }}ACEmed ,包含 120 个示例——每种事件类型十个——其余为非事件实例。对于两种设置,我们都使用了一致的开发集,随机从 ACE05 开发集中抽取了 100 个示例,并在该集上讨论各种任务和优化器模型的表现。对于完整的 MCTS,我们另外报告了测试集上的模型表现,该测试集由从 ACE05 测试集中随机抽取的 250 个示例组成。ACElow \mathbf{A C E}_{\text {low }}ACElow 和 ACEmed \mathbf{A C E}_{\text {med }}ACEmed 的数据集统计信息汇总在表 3(附录 B)中。
评估。按照先前的工作(Huang 等人,2024),我们使用基于 F1 的四种指标评估模型:(1) 触发器识别(TI),衡量正确提取触发器跨度;(2) 触发器分类(TC),还需要预测正确的事件类型;(3) 参数识别(AI),评估正确提取参数及其与预测触发器的关联;(4) 参数分类(AC),进一步需要正确的角色标记,并作为最全面的端到端 EE 性能衡量标准。为了分析,我们主要报告 AC 分数,这被广泛认为是评估参数和触发器质量的精确指标(Huang 等人,2024)。附录 D 提供了所有指标的完整结果。
实验设置和基线。我们的实验涉及两个 LRMs,DeepSeekR1 和 OpenAI-o1,以及两个通用 LLMs,GPT-4.5 和 GPT-4o,用作 Mopt \mathcal{M}_{\text {opt }}Mopt 和 Mtask \mathcal{M}_{\text {task }}Mtask 。我们进行了两组实验。首先,我们在 ACElow\mathrm{ACE}_{low}ACElow 和 ACEmed \mathrm{ACE}_{\text {med }}ACEmed 上使用浅层 MCTS(深度 1)评估所有模型,以检查 LRMs 是否从提示优化中受益。我们选择此设计是因为其复杂性和计算成本较低。在第二组实验中,我们然后在 ACEmed \mathrm{ACE}_{\text {med }}ACEmed 上执行完整的 MCTS 优化,深度为 5,以调查优化的深层动态;由于尺寸有限,ACElow\mathrm{ACE}_{low}ACElow 被排除在全规模搜索之外。对于所有实验,我们仅报告每个模型搜索轨迹中表现最佳的提示节点的结果。为了减少推理成本,我们在查询 Mtask \mathcal{M}_{\text {task }}Mtask 进行答案生成(图 2 第一步)时采用了“批量提示”(Cheng 等人,2023)。有趣的是,我们观察到一次询问多个问题比一次询问一个问题表现更好。由于政策限制,我们在本地服务器上部署了 DeepSeek-R1 模型。鉴于我们的计算能力有限,为了高效推理,我们使用 UnSloth 框架(Daniel Han & 团队,2023)将 DeepSeek-R1 量化到 2.5 位。批量提示和超参数配置的更多细节在附录 B 中提供。
3.2 实验结果。
RQ1: LRMs 在 EE 中是否从提示优化中受益?我们首先通过在深度 1 的 MCTS 下展开根节点三次扩展,报告最佳提示性能,研究模型是否可以从提示优化中获益。如表 1 所示,我们观察到所有模型从提示优化中获得了一致的收益,LRMs 展现了特别强的改进。在 ACElow\mathrm{ACE}_{low}ACElow 和 ACEmed \mathrm{ACE}_{\text {med }}ACEmed 上,LRMs 显著优于其未优化的版本。具体来说,o1 和 DeepSeek-R1 在 ACElow\mathrm{ACE}_{low}ACElow 上分别获得了约 +8%AC+8 \% \mathrm{AC}+8%AC 的提升,在 ACEmed \mathrm{ACE}_{\text {med }}ACEmed 上获得了约 +23%+23 \%+23% 的提升。LLMs 也从优化中受益,但程度较小:GPT-4o 和 GPT-4.5 在 ACElow\mathrm{ACE}_{low}ACElow 上分别提升了约 +7%+7 \%+7% 和 +5%+5 \%+5%,在 ACEmed \mathrm{ACE}_{\text {med }}ACEmed 上分别提升了约 +14%+14 \%+14% 和 +20%+20 \%+20%。总体而言,提示优化带来的性能提升在 LRMs 中比在 LLMs 中更为显著。
类似地,在使用优化提示的跨模型比较中,LRMs 依然具有高度竞争力。在 ACElow\mathrm{ACE}_{low}ACElow 上,GPT-4.5 稍微优于 o1 约 +1%AC+1 \% \mathrm{AC}+1%AC,但落后于 DeepSeek-R1 约 +2%+2 \%+2%。在 ACEmed \mathrm{ACE}_{\text {med }}ACEmed 上,两种 LRMs 都优于 LLMs:o1 超过 GPT-4.5 约 +0.5%+0.5 \%+0.5% AC,而 DeepSeek-R1 提升了大约 +3.5%+3.5 \%+3.5%。这些发现表明 LRMs 不仅对提示优化反应更灵敏,而且在零样本事件提取设置中更具能力。正如我们在 RQ2 中所示,使用基于完整深度 MCTS 的优化策略时,这种差距进一步扩大。
洞察 1: 提示优化对所有模型都有好处,但 LRMs 收益更多。使用优化提示后,它们在 ACElow\mathrm{ACE}_{low}ACElow 和 ACEmed \mathrm{ACE}_{\text {med }}ACEmed 上超过了未优化的版本和 LLMs。
RQ2: LRMs 在完整规模的 MCTS 提示优化下表现如何?为了评估 LRMs 在大规模下的优势,我们在 ACEmed \mathrm{ACE}_{\text {med }}ACEmed 上对所有模型执行了深度为 5 的 MCTS。虽然整体性能有所提高,但我们观察到,与深度为 1 的 MCTS 单次展开(即深度 1)所观察到的改进相比,完整规模优化带来的增益是增量而非戏剧性的。然而,LRMs 仍然表现出相对更强的改进。例如,DeepSeek-R1 在之前的最佳表现基础上额外获得了 +4.26%AC+4.26 \% \mathrm{AC}+4.26%AC(从 40.00 提升到 44.26)。同样,o1 在深度遍历中选择最佳优化器时改进了 +2.83%+2.83 \%+2.83%(从 36.98 提升到 39.81)。当自我优化时,它改进了 +1.73%+1.73 \%+1.73%(从 36.98 提升到 38.71),确认了深度超过 1 后的收益即使在受控设置下仍然适度。相比之下,LLMs GPT-4.5 和 GPT-4o 分别仅表现出适度的增益 +1.23%+1.23 \%+1.23%(从 36.51 提升到 37.74)和 +1.03%+1.03 \%+1.03%(从 27.54 提升到 28.57)。
| 优化器 LLMs/LRMs (Mopt )\left(\mathcal{M}_{\text {opt }}\right)(Mopt ) | 输出数量 | |||||
|---|---|---|---|---|---|---|
| Mtask \mathcal{M}_{\text {task }}Mtask | 无优化 | GPT-4o | GPT-4.5 | o1 | DS-R1 | Tokens |
| MCTS 在深度 1 上的 ACElow \mathrm{ACE}_{\text {low }}ACElow (开发集) | ||||||
| GPT-4o | 12.68 | 18.18+5.5018.18+5.5018.18+5.50 | 16.67+9.9916.67+9.9916.67+9.99 | 18.83+6.1518.83+6.1518.83+6.15 | 20.15+7.47\mathbf{2 0 . 1 5}+7.4720.15+7.47 | 15.31 |
| GPT-4.5 | 16.47 | 19.33+2.8619.33+2.8619.33+2.86 | 16.47+0.0016.47+0.0016.47+0.00 | 19.32+2.8519.32+2.8519.32+2.85 | 22.31+5.84\mathbf{2 2 . 3 1}+5.8422.31+5.84 | 24.57 |
| o1 | 13.94 | 18.96+5.0218.96+5.0218.96+5.02 | 18.57+4.6318.57+4.6318.57+4.63 | 20.29+6.3520.29+6.3520.29+6.35 | 21.92+7.98\mathbf{2 1 . 9 2}+7.9821.92+7.98 | 489.67 |
| DS-R1 | 16.45 | 18.67+2.2218.67+2.2218.67+2.22 | 18.57+2.1218.57+2.1218.57+2.12 | 21.83+5.3821.83+5.3821.83+5.38 | 24.66+8.21\mathbf{2 4 . 6 6}+8.2124.66+8.21 | 217.71 |
| MCTS 在深度 1 上的 ACEmed \mathrm{ACE}_{\text {med }}ACEmed (开发集) | ||||||
| GPT-4o | 12.68 | 22.32+9.6422.32+9.6422.32+9.64 | 27.54+14.86\mathbf{2 7 . 5 4}+14.8627.54+14.86 | 26.30+13.6226.30+13.6226.30+13.62 | 25.10+12.4225.10+12.4225.10+12.42 | 17.31 |
| GPT-4.5 | 16.47 | 29.63+13.1629.63+13.1629.63+13.16 | 35.94+19.4735.94+19.4735.94+19.47 | 36.51+20.04\mathbf{3 6 . 5 1}+20.0436.51+20.04 | 35.42+18.9335.42+18.9335.42+18.93 | 28.75 |
| o1 | 13.94 | 30.19+16.2530.19+16.2530.19+16.25 | 36.67+22.7336.67+22.7336.67+22.73 | 36.98+23.04\mathbf{3 6 . 9 8}+23.0436.98+23.04 | 36.96+23.0236.96+23.0236.96+23.02 | 543.45 |
| DS-R1 | 16.45 | 32.20+15.7532.20+15.7532.20+15.75 | 37.14+20.6937.14+20.6937.14+20.69 | 38.77+22.3238.77+22.3238.77+22.32 | 40.00+23.55\mathbf{4 0 . 0 0}+23.5540.00+23.55 | 277.11 |
| MCTS 在深度 5 上的 ACEmed \mathrm{ACE}_{\text {med }}ACEmed (开发集) | ||||||
| GPT-4o | 12.68 | 28.04+15.3628.04+15.3628.04+15.36 | 27.03+14.3527.03+14.3527.03+14.35 | 28.57+15.89\mathbf{2 8 . 5 7}+15.8928.57+15.89 | 27.31+14.6327.31+14.6327.31+14.63 | 17.55 |
| GPT-4.5 | 16.47 | 32.35+15.8832.35+15.8832.35+15.88 | 37.58+21.1137.58+21.1137.58+21.11 | 36.22+19.7536.22+19.7536.22+19.75 | 37.74+21.27\mathbf{3 7 . 7 4}+21.2737.74+21.27 | 32.65 |
| o1 | 13.94 | 33.52+19.5833.52+19.5833.52+19.58 | 37.78+23.8437.78+23.8437.78+23.84 | 38.71+24.7738.71+24.7738.71+24.77 | 39.81+25.87\mathbf{3 9 . 8 1}+25.8739.81+25.87 | 575.36 |
| DS-R1 | 16.45 | 37.97+21.5237.97+21.5237.97+21.52 | 38.40+21.9538.40+21.9538.40+21.95 | 40.58+24.1340.58+24.1340.58+24.13 | 44.26+27.81\mathbf{4 4 . 2 6}+27.8144.26+27.81 | 301.45 |
| MCTS 在深度 5 上的 ACEmed \mathrm{ACE}_{\text {med }}ACEmed (测试集) | ||||||
| GPT-4o | 13.33 | 26.94+13.6126.94+13.6126.94+13.61 | 34.75+21.4234.75+21.4234.75+21.42 | 30.59+17.2630.59+17.2630.59+17.26 | 35.79+22.46\mathbf{3 5 . 7 9}+22.4635.79+22.46 | 27.00 |
| GPT-4.5 | 14.29 | 27.31+13.0227.31+13.0227.31+13.02 | 35.29+21.0035.29+21.0035.29+21.00 | 36.59+22.3036.59+22.3036.59+22.30 | 36.69+22.60\mathbf{3 6 . 6 9}+22.6036.69+22.60 | 35.56 |
| o1 | 15.38 | 28.57+13.1928.57+13.1928.57+13.19 | 36.73+21.3536.73+21.3536.73+21.35 | 38.71+23.33\mathbf{3 8 . 7 1}+23.3338.71+23.33 | 37.86+22.4837.86+22.4837.86+22.48 | 526.43 |
| DS-R1 | 16.00 | 31.93+15.9331.93+15.9331.93+15.93 | 41.98+25.9841.98+25.9841.98+25.98 | 42.06+26.0642.06+26.0642.06+26.06 | 43.75+27.75\mathbf{4 3 . 7 5}+27.7543.75+27.75 | 211.43 |
表 1: 使用不同 Mtask \mathcal{M}_{\text {task }}Mtask 和 Mopt \mathcal{M}_{\text {opt }}Mopt 的 AC(F1)分数。#Output Tokens 表示任务模型的平均输出令牌数,包括推理和非推理内容。背景阴影表示提示优化器的选择,即 LRMs、LLMs 或无优化。每个任务模型的最佳优化结果以粗体显示。我们观察到 LRMs 不仅从提示优化中显著受益,还作为其他模型的强大提示优化器。
最后,我们报告每个任务模型在 ACEtest \mathrm{ACE}_{\text {test }}ACEtest 上的表现,使用相同的最佳提示在 ACEmed \mathrm{ACE}_{\text {med }}ACEmed 上。我们观察到一致的改进:DeepSeek-R1 在 AC F1 上绝对提高了 +7%+7 \%+7% 超过 GPT-4.5(从 36.69↦43.7536.69 \mapsto 43.7536.69↦43.75),而 o1 比 GPT-4.5 提高了 +2%+2 \%+2%(从 36.69↦36.69 \mapsto36.69↦ 38.71)。
洞察 2: 完整规模的 MCTS 优化相对于单步优化带来了非戏剧性的收益,但基于推理的模型受益更多。
RQ2: LRMs 在完整的 MCTS 提示优化下表现如何?为了评估 LRMs 在大规模下的优势,我们在 ACEmed \mathrm{ACE}_{\text {med }}ACEmed 上对所有模型执行了深度为 5 的 MCTS。虽然整体性能有所提高,但我们观察到,与深度为 1 的 MCTS 单次展开(即深度 1)所观察到的改进相比,完整规模优化带来的收益是增量而非戏剧性的。然而,LRMs 仍然表现出相对更强的改进。例如,DeepSeek-R1 在之前最佳表现的基础上额外获得了 +4.26%AC+4.26 \% \mathrm{AC}+4.26%AC(从 40.00 提升到 44.26)。同样,o1 在深度遍历中选择最佳优化器时改进了 +2.83%+2.83 \%+2.83%(从 36.98 提升到 39.81)。当自我优化时,它改进了 +1.73%+1.73 \%+1.73%(从 36.98 提升到 38.71),确认了深度超过 1 后的收益即使在受控设置下仍然适度。相比之下,LLMs GPT-4.5 和 GPT-4o 分别仅表现出适度的增益 +1.23%+1.23 \%+1.23%(从 36.51 提升到 37.74)和 +1.03%+1.03 \%+1.03%(从 27.54 提升到 28.57)。
| 优化器 LLMs/LRMs (Mopt )\left(\mathcal{M}_{\text {opt }}\right)(Mopt ) | 输出数量 | |||||
|---|---|---|---|---|---|---|
| Mtask \mathcal{M}_{\text {task }}Mtask | 无优化 | GPT-4o | GPT-4.5 | o1 | DS-R1 | Tokens |
| MCTS 在深度 1 上的 ACElow \mathrm{ACE}_{\text {low }}ACElow (开发集) | ||||||
| GPT-4o | 12.68 | 18.18+5.5018.18+5.5018.18+5.50 | 16.67+9.9916.67+9.9916.67+9.99 | 18.83+6.1518.83+6.1518.83+6.15 | 20.15+7.47\mathbf{2 0 . 1 5}+7.4720.15+7.47 | 15.31 |
| GPT-4.5 | 16.47 | 19.33+2.8619.33+2.8619.33+2.86 | 16.47+0.0016.47+0.0016.47+0.00 | ------ | ||
| 19.32+2.8519.32+2.8519.32+2.85 | 22.31+5.84\mathbf{2 2 . 3 1}+5.8422.31+5.84 | 24.57 | ||||
| o1 | 13.94 | 18.96+5.0218.96+5.0218.96+5.02 | 18.57+4.6318.57+4.6318.57+4.63 | 20.29+6.3520.29+6.3520.29+6.35 | 21.92+7.98\mathbf{2 1 . 9 2}+7.9821.92+7.98 | 489.67 |
| DS-R1 | 16.45 | 18.67+2.2218.67+2.2218.67+2.22 | 18.57+2.1218.57+2.1218.57+2.12 | 21.83+5.3821.83+5.3821.83+5.38 | 24.66+8.21\mathbf{2 4 . 6 6}+8.2124.66+8.21 | 217.71 |
| MCTS 在深度 1 上的 ACEmed \mathrm{ACE}_{\text {med }}ACEmed (开发集) | ||||||
| GPT-4o | 12.68 | 22.32+9.6422.32+9.6422.32+9.64 | 27.54+14.86\mathbf{2 7 . 5 4}+14.8627.54+14.86 | 26.30+13.6226.30+13.6226.30+13.62 | 25.10+12.4225.10+12.4225.10+12.42 | 17.31 |
| GPT-4.5 | 16.47 | 29.63+13.1629.63+13.1629.63+13.16 | 35.94+19.4735.94+19.4735.94+19.47 | 36.51+20.04\mathbf{3 6 . 5 1}+20.0436.51+20.04 | 35.42+18.9335.42+18.9335.42+18.93 | 28.75 |
| o1 | 13.94 | 30.19+16.2530.19+16.2530.19+16.25 | 36.67+22.7336.67+22.7336.67+22.73 | 36.98+23.04\mathbf{3 6 . 9 8}+23.0436.98+23.04 | 36.96+23.0236.96+23.0236.96+23.02 | 543.45 |
| DS-R1 | 16.45 | 32.20+15.7532.20+15.7532.20+15.75 | 37.14+20.6937.14+20.6937.14+20.69 | 38.77+22.3238.77+22.3238.77+22.32 | 40.00+23.55\mathbf{4 0 . 0 0}+23.5540.00+23.55 | 277.11 |
| MCTS 在深度 5 上的 ACEmed \mathrm{ACE}_{\text {med }}ACEmed (开发集) | ||||||
| GPT-4o | 12.68 | 28.04+15.3628.04+15.3628.04+15.36 | 27.03+14.3527.03+14.3527.03+14.35 | 28.57+15.89\mathbf{2 8 . 5 7}+15.8928.57+15.89 | 27.31+14.6327.31+14.6327.31+14.63 | 17.55 |
| GPT-4.5 | 16.47 | 32.35+15.8832.35+15.8832.35+15.88 | 37.58+21.1137.58+21.1137.58+21.11 | 36.22+19.7536.22+19.7536.22+19.75 | 37.74+21.27\mathbf{3 7 . 7 4}+21.2737.74+21.27 | 32.65 |
| o1 | 13.94 | 33.52+19.5833.52+19.5833.52+19.58 | 37.78+23.8437.78+23.8437.78+23.84 | 38.71+24.7738.71+24.7738.71+24.77 | 39.81+25.87\mathbf{3 9 . 8 1}+25.8739.81+25.87 | 575.36 |
| DS-R1 | 16.45 | 37.97+21.5237.97+21.5237.97+21.52 | 38.40+21.9538.40+21.9538.40+21.95 | 40.58+24.1340.58+24.1340.58+24.13 | 44.26+27.81\mathbf{4 4 . 2 6}+27.8144.26+27.81 | 301.45 |
| MCTS 在深度 5 上的 ACEmed \mathrm{ACE}_{\text {med }}ACEmed (测试集) | ||||||
| GPT-4o | 13.33 | 26.94+13.6126.94+13.6126.94+13.61 | 34.75+21.4234.75+21.4234.75+21.42 | 30.59+17.2630.59+17.2630.59+17.26 | 35.79+22.46\mathbf{3 5 . 7 9}+22.4635.79+22.46 | 27.00 |
| GPT-4.5 | 14.29 | 27.31+13.0227.31+13.0227.31+13.02 | 35.29+21.0035.29+21.0035.29+21.00 | 36.59+22.3036.59+22.3036.59+22.30 | 36.69+22.60\mathbf{3 6 . 6 9}+22.6036.69+22.60 | 35.56 |
| o1 | 15.38 | 28.57+13.1928.57+13.1928.57+13.19 | 36.73+21.3536.73+21.3536.73+21.35 | 38.71+23.33\mathbf{3 8 . 7 1}+23.3338.71+23.33 | 37.86+22.4837.86+22.4837.86+22.48 | 526.43 |
| DS-R1 | 16.00 | 31.93+15.9331.93+15.9331.93+15.93 | 41.98+25.9841.98+25.9841.98+25.98 | 42.06+26.0642.06+26.0642.06+26.06 | 43.75+27.75\mathbf{4 3 . 7 5}+27.7543.75+27.75 | 211.43 |
| 表 1: 使用不同 Mtask \mathcal{M}_{\text {task }}Mtask 和 Mopt \mathcal{M}_{\text {opt }}Mopt 的 AC (F1) 分数。#Output Tokens 表示任务模型的平均输出令牌数,包括推理和非推理内容。背景阴影表示提示优化器的选择,即 LRMs、LLMs 或无优化。每个任务模型的最佳优化结果以粗体显示。我们观察到 LRMs 不仅从提示优化中显著受益,还作为其他模型的强大提示优化器。 |
最后,我们报告每个任务模型在 ACEtest \mathrm{ACE}_{\text {test }}ACEtest 上的表现,使用相同的最佳提示在 ACEmed \mathrm{ACE}_{\text {med }}ACEmed 上。我们观察到一致的改进:DeepSeek-R1 在 AC F1 上绝对提高了 +7%+7 \%+7% 超过 GPT-4.5 (从 36.69↦43.7536.69 \mapsto 43.7536.69↦43.75 ),而 o1 比 GPT-4.5 提高了 +2%+2 \%+2% (从 36.69↦36.69 \mapsto36.69↦ 38.71 )。
洞察 2: 完整规模的 MCTS 优化相对于单步优化带来了非戏剧性的收益,但基于推理的模型受益更多。
RQ3: LRMs 是否能成为更好的提示优化器?我们评估了每种任务模型在使用各种 LRMs 和 LLMs 进行优化时的表现,以研究优化提示的质量。在低资源设置下(ACElow \mathrm{ACE}_{\text {low }}ACElow ,深度 1),DeepSeek-R1 在所有任务模型上始终优于所有其他优化器。与表现最好的 LLM 优化器(GPT-4o)相比,DeepSeek-R1 带来了显著的提升:约 +2%+2 \%+2% AC 用于优化 GPT-4o(从 18.18 到 20.15),+3%+3 \%+3% 用于优化 GPT-4.5(从 19.33 到 22.31)和 o1(从 18.96 到 21.92),以及 +6%+6 \%+6% 自我优化时(从 18.67 到 24.66)。值得注意的是,在 LLMs 中,尽管作为任务模型较弱,GPT-4o 在所有任务模型设置中作为优化器表现优于 GPT-4.5。
另一方面,当有更大的训练集可用时(ACEmed \mathrm{ACE}_{\text {med }}ACEmed ,深度 1),我们观察到了转变。尽管 LRM 优化器如 o1 和 DeepSeek-R1 仍然强大——在自我优化时获得了超过 +23%+23 \%+23% AC 改进——GPT-4.5 显示出显著的有效性提升。它在所有任务模型设置中始终优于 GPT-4o 作为优化器,并在某些情况下缩小了与 LRMs 的差距,自我优化时达到 35.94,优化 o1 时达到 36.67。定性地,如表 2 所示,DeepSeek-R1 通过添加精确的提取规则——例如删除冠词(“a/an/the”)和所属代词(用蓝色突出显示)——以及处理特定触发器的关键例外情况(用粉色突出显示)来增强优化提示 P∗\mathcal{P}^{*}P∗。相比之下,o1 倾向于生成更大数量的提取规则,导致更长的提示。两种 LRMs 都包括具体示例以指导提取。
| 不同模型优化的任务指令示例 | |
|---|---|
| 无优化 最佳分数 TI - 39.29 TC - 33.93 AI - 16.47 AC - 16.47 |
# 这是一个事件提取任务,目标是从文本中提取结构化事件,遵循 Python 中定义的结构化事件定义。(…) 对于每种不同的事件类型,请将从文本中提取的信息输出为 Python 列表格式(…) 输出应始终为有效的 pydantic 格式:result =[=[=[ EventName(“mention”, = “trigger”, “arg1.key”, = “arg1.span”, …), EventName(“mention”, = “trigger”, “arg1.key”, = “arg1.span”, …)]. (…) |
| GPT-40 最佳分数 TI - 48.28 TC - 48.28 AI - 40.51 AC - 37.97 |
# 这是一个事件提取任务,目标是从文本中提取结构化事件 (…) # 任务指令。1. 对于每种不同的事件类型,输出从文本中提取的信息 (…) 2. 结构化输出为有效的 Pydantic 格式: “result = [EventName(“mention”, = “trigger”, (…) 3. 严格遵守描述的事件描述 (…) 4. 处理特殊情况:- 上诉:考虑涉及相关事件中的当事人作为"检察官”。 - 多个角色可能适用于情境;确保完整信息提取。 - 隐含指示:如果提及诸如"filed", “concluded”, 等等,(…) 使用上下文澄清它们。(…) |
| GPT-4.5 最佳分数 TI - 46.15 TC - 46.15 AI - 40.80 AC - 38.40 |
# 这是一个事件提取任务,使用 Python 定义的事件类从文本中识别和结构化事件。每个结构化事件由一个事件触发词、事件类型组成 (…) ## 指令: 1. 跨度提取 - 提取精确且简洁的跨度,清晰传达事件或参数角色 (…) - 准确识别角色,使用上下文线索有效解决歧义,同时优先明确跨度。如果没有提到角色,则留空。(…) 3. 输出格式:请遵循 Python 格式(…) 4. 澄清和例外:- 明确指出角色定义中的例外情况。 - 通过特定指南管理重叠角色,确保跨度清晰和精确,(…) |
| DeepSeer- R1 最佳分数 TI - 56.60 TC - 56.60 AI - 44.26 AC - 44.26 |
# 事件提取任务:使用 Python 类定义从文本中提取结构化事件。(…): 1. 跨度提取:- 触发器:最小连续跨度(动词/名词)直接表达事件。包括动词和名词形式(“death”, = Die, “killings”, = Die) (…) - 参数:- 删除冠词(“a/an/the”)和所属代词,除非是正式名称或时间短语的一部分(“The Hague”, “the past year”) - 解析代词和所属名词立即使用相同句子中的先行词(“airline’s plan”, → [“airline”]) - 从参数中删除角色/位置/年龄描述符(“Philadelphia lawyers”, → “lawyers”) (…) - 对犯罪/金钱保留完整的跨度,包括来源/金额(“stereo worth $1,750 from family”),除非法律术语 (…) 2. 特殊处理:- 破产触发器:“went bust” → EndOrg(…) - 犯罪跨度:保留完整的上下文子句(“If convicted of killings…”)不截断 - 时间短语:当短语的一部分时保留原始跨度包含冠词(“the early 90’s”) 3. 输出规则:始终以 Python 格式输出 (…) 4. 关键例外-(…) |
| O1 最佳分数 TI - 66.67 TC - 66.67 AI - 44.93 AC - 40.58 \begin{aligned} & \text { O1 } \\ & \text { 最佳分数 } \\ & \text { TI - 66.67 } \\ & \text { TC - 66.67 } \\ & \text { AI - 44.93 } \\ & \text { AC - 40.58 } \end{aligned} O1 最佳分数 TI - 66.67 TC - 66.67 AI - 44.93 AC - 40.58 | # 这是一个事件提取任务,目标是从文本中提取结构化事件,遵循 Python 中定义的结构化事件定义。(…) 保持参数引用最少,删除冠词、所属代词或描述性词语,除非它们是关键标识符(例如,“the retailer”,→ “retailer”,“my uncle”,→ “uncle”)。 # 重要指南以应对先前错误: # 1. 对于每个事件触发器,使用最相关的单词(例如,“bankruptcy”而不是“file for bankruptcy”); # 2. 对于参数角色,也使用最小跨度(例如,“soldier”而不是“a soldier”,“woman”而不是“a woman”)(…) # 4. 对于司法事件(Sue,Appeal,Convict,SentenceAct 等):(…) # 5. 对于金钱转移,注意直接或间接捐赠的参考,(…) # 6. 不要跳过由同义词或间接措辞暗示的事件(例如,“shutting down”,→ EndOrg,(…); # 7. 如果一段文本中有多个事件,分别输出每个事件。(…) |
表 2: 当 Mtask =\mathcal{M}_{\text {task }}=Mtask = DeepSeek-R1 时,不同优化器优化的任务指令示例,这为每个优化器提供了最佳性能。LRMs 倾向于强调可操作的提取规则和异常处理,同时对任务指令和输出格式的关注较少。此外,它们通常包括说明性示例(加粗)以促进跨度提取。
相比之下,LLMs 更关注任务指令和输出格式,通常生成较短的提示,例子较少。其中,GPT-4.5 偶尔会添加异常处理,尽管这种行为不如 LRMs 一致。我们在附录 E 中提供了更多优化任务指令和事件指南的示例,并在第 4.1 节中进行了额外的提示质量分析。
洞察 3: LRMs 是非常有效的优化器,特别是在低资源设置下,DeepSeek-R1 一贯优于所有其他模型。
RQ4: LRMs 是否可以作为高效且稳定的优化器进行提示优化?在图 4a 中,我们观察到当 DeepSeek-R1 作为优化器时,DeepSeek-R1 和 GPT-4o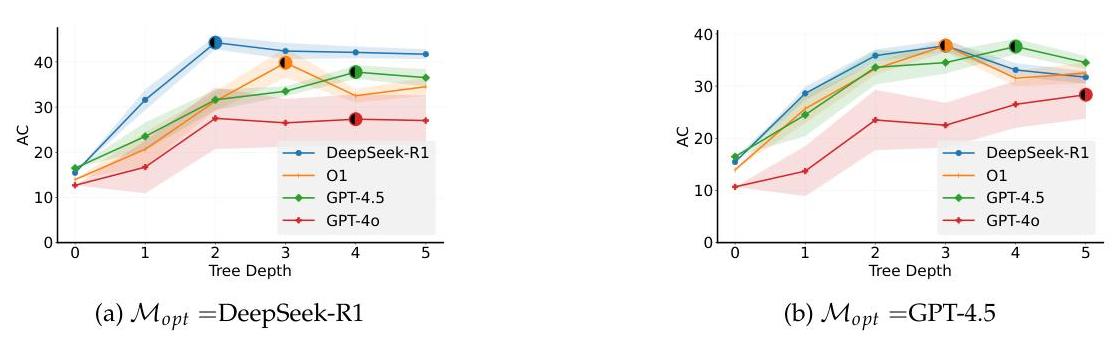
图 4: 使用两种优化器——DeepSeek-R1(左)和 GPT-4.5(右)——在不同任务模型上的提示优化收敛分析。LRMs 收敛最快,方差最小,而 LLMs 需要更深的树。
与 GPT-4.5 作为优化器(图 4b)相比,展示了更快的收敛,表明其生成了更高品质的提示。对于 DeepSeek-R1 和 GPT-4.5 作为任务模型的情况,其表现出较小的性能方差,这表明 R1 不仅生成高质量的提示,而且能够可靠地生成。相比之下,以 GPT-4.5 作为优化器时,收敛往往较慢。在此设置下,LRMs 在深度 3 达到峰值,而 GPT-4.5 和 GPT-4o 分别在深度 4 和深度 5 收敛。对于 GPT-4.5,优化过程明显不如使用 DeepSeek-R1 优化稳定。
值得注意的是,大多数模型在超出其最佳深度(用半填充标记标示)后开始趋于平稳,甚至略有下降,这强化了存在递减收益的现象,即额外优化带来的性能增益越来越小或没有增益。
洞察 4: DeepSeek-R1(LRM)作为优化器比 GPT-4.5(LLM)产生更快且更稳定的收敛。
4 进一步分析
4.1 不同优化器下的提示质量分析
我们使用生存图分析提示有效性分布,DeepSeekR1 作为 Mtask \mathcal{M}_{\text {task }}Mtask 。x 轴代表递增的 AC 阈值,y 轴表示至少达到该阈值的提示百分比。更高的生存曲线表明优化器更一致地生成高性能提示。如图 5a 所示,通过 DeepSeek-R1 优化的提示表现出最强的生存曲线,即使在更严格的 AC 截止点(≥35% AC)下仍保持高性能密度。相比之下,GPT-4o 的曲线迅速衰减,表明虽然偶尔生成有效提示,但其输出质量不稳定。有趣的是,o1 和 GPT-4.5 介于两者之间,o1 在中等阈值范围内略优于 GPT-4.5,但在较高截止点上显著落后于 DeepSeek-R1。这些趋势强化了我们之前的发现:推理模型不仅能够产生更好的峰值性能,还能生成更多的可用提示。
4.2 提示长度与任务模型性能的关系
为了更好地理解不同类型任务模型达到其峰值性能所需的指令量,我们分析了提示长度与模型准确率在整个 MCTS 搜索树中的关系。对于每个模型,我们选择其最佳搜索轨迹(即,o1 作为 GPT-4o 的优化器,DeepSeek-R1 作为其他任务模型的优化器),并在图 5b 中绘制相应的完整提示长度(包括继承的定义)与其 AC 分数的关系。DeepSeek-R1 在搜索空间中利用最短的提示(~1750 个令牌)达到了最高性能,表明其偏好更简明的任务指令。相比之下,LLMs(GPT-4o 和 GPT-4.5)和推理模型 o1 往往依赖于显著更长的提示来实现相当的准确率。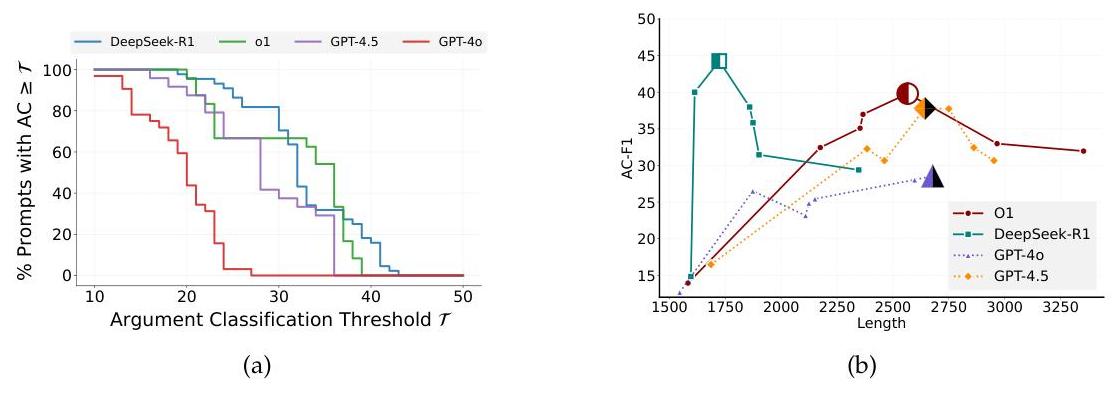
图 5: (a) 生存图显示 DeepSeek-R1 在不同优化器下达到给定 AC 分数(x 轴)的提示百分比(y 轴)。(b) 在开发集上,各任务模型的最佳全 MCTS 配置下提示长度与 AC 分数的关系。
此外,如表 2 所示,DeepSeek-R1 生成的提示引入了初始提示 P0\mathcal{P}_{0}P0 中不存在的新提取规则和异常处理。正如将在第 4.4 节中讨论的那样,许多这些规则专注于精确的参数跨度提取,这一类别占最常见错误类型的很大一部分。这表明 DeepSeek-R1 的优化器能够识别并注入高实用性的约束,从而提高 Mtask \mathcal{M}_{\text {task }}Mtask 的性能。
4.3 优化器如何遵循(或忽略)反馈?
如第 2.3 节所述,优化器在应用反馈时表现出不同的行为。例如,我们观察到在大多数情况下,DeepSeek-R1 仅细化在反馈生成的任务指令和指南中明确提到的事件定义,而其余事件定义保持不变。图 6 展示了一个例子,其中 DeepSeek-R1 推理认为 Attack 事件的参数提取错误可能是由于 Mtask \mathcal{M}_{\text {task }}Mtask 的限制而非指南本身,因此拒绝修改它。在这种情况下,未更改的定义从父节点继承。
为了量化这种行为,我们在图 7 中测量了所有优化器在各自最佳配置(基于 AC 分数)下的平均编辑指南数量及其平均令牌长度。值得注意的是,这里的令牌计数与图 5b 中的不同,因为我们只考虑编辑后的指南——未编辑的部分从先前状态继承——而早期分析包括每个节点的完整提示内容。如图所示,DeepSeek-R1 编辑的事件类型指南最少(平均 6.7 个)且生成的指南最短(大约 1.5k 个令牌用于一次优化步骤中的指南编辑),反映了更反馈敏感和令牌高效的策略。相比之下,GPT-o1 和 GPT-4.5 几乎修改了所有十个指南(平均分别为 9.8 和 8.5 个),无论反馈的具体性如何,导致输出显著更长(分别为 2.9k 和 2k 个令牌)。虽然 GPT-4o 似乎也受到限制(平均编辑 7.6 次),但定性分析表明这是由于反馈过多:当提供许多建议时,GPT-4o 往往无法全部解决。这些发现突显了 DeepSeek-R1 更具体和高效的编辑行为,进一步强化了其作为提示优化器的优势。
4.4 错误分类与分析
为了更好地理解不同优化器引入的错误类型,我们对所有开发示例进行了细致分析,其中 DeepSeek-R1 在不同优化器生成的提示上失败。如图 8 所示,LRMs 显著减少了与事件相关的错误,特别是涉及多个或隐含事件的错误。参数相关问题,如共指错误和跨度过度预测,也有轻微减少。在某些情况下,所有模型都会生成不可解析的输出或幻觉的参数跨度。剩余的错误主要归因于数据集中的标签噪声。我们在附录 D 中为每种错误类别提供了一个示例。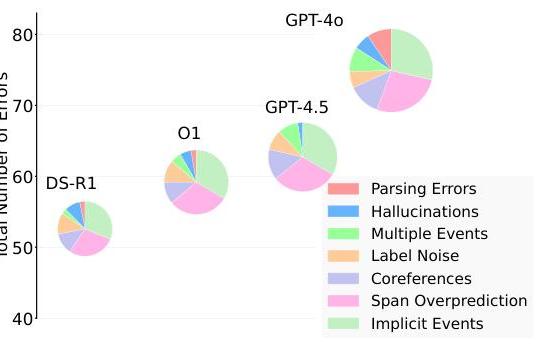
图 8: DeepSeekR1 作为任务模型使用不同优化器时的错误分类。
洞察 5: LRM 优化的提示不仅更短,还包含了原任务指令中不存在的新提取规则,直接解决了频繁出现的错误,如跨度过度预测和共指。
5 结论
我们首次系统研究了 LRMs 的提示优化,评估了它们在统一的 MCTS 框架中作为任务模型和优化器的角色。在结构化的事件提取任务中,我们发现 LRMs 从提示优化中获益比 LLMs 更多,并且作为更强的优化器。它们生成高质量的提示,收敛速度更快,并且在模型间更可靠地泛化——突出了它们在提示消费和生成方面的有效性。我们的错误分析进一步揭示,LRMs 优化的提示减少了过度预测、幻觉和解析错误,有助于更忠实和结构化的输出。
致谢
本工作中的 LLM/LRM API 资源部分来自 Microsoft Research 的加速基础模型研究计划。该项目还得到了乔治梅森大学研究计算办公室提供的资源支持(网址:https://orc.gmu.edu),并部分由美国国家科学基金会的资助(奖项编号 2018631)。
参考文献
Eshaan Agarwal, Joykirat Singh, Vivek Dani, Raghav Magazine, Tanuja Ganu 和 Akshay Nambi。Promptwizard:面向任务的提示优化框架,2024。URL https://arxiv.org/abs/2405.18369。
Zhoujun Cheng, Jungo Kasai 和 Tao Yu。批量提示:使用大型语言模型 API 的高效推理。在 Mingxuan Wang 和 Imed Zitouni(编辑),Proceedings of the 2023 年经验方法自然语言处理会议:工业轨道,第 792-810 页,新加坡,2023 年 12 月。计算机语言学协会。doi: 10.18653/v1/ 2023.emnlp-industry.74。URL https://aclanthology.org/2023.emnlp-industry.74/。
Michael Han Daniel Han 和 Unsloth 团队。Unsloth,2023。URL http://github.com/ unslothai/unsloth。
Mingkai Deng, Jianyu Wang, Cheng-Ping Hsieh, Yihan Wang, Han Guo, Tianmin Shu, Meng Song, Eric Xing 和 Zhiting Hu。RLPrompt:使用强化学习优化离散文本提示。在 Yoav Goldberg, Zornitsa Kozareva 和 Yue Zhang(编辑),Proceedings of the 2022 年经验方法自然语言处理会议,第 3369-3391 页,阿拉伯联合酋长国阿布扎比,2022 年 12 月。计算机语言学协会。doi: 10.18653/v1/2022.emnlp-main.222。URL https://aclanthology.org/2022.emnlp-main.222/。
George Doddington, Alexis Mitchell, Mark Przybocki, Lance Ramshaw, Stephanie Strassel 和 Ralph Weischedel。自动内容提取(ACE)程序 - 任务、数据和评估。在 Maria Teresa Lino, Maria Francisca Xavier, Fátima Ferreira, Rute Costa 和 Raquel Silva(编辑),Proceedings of the Fourth International Conference on Language Resources and Evaluation (LREC’04),葡萄牙里斯本,2004 年 5 月。欧洲语言资源协会(ELRA)。URL https://aclanthology.org/L04-1011/。
Chrisantha Fernando, Dylan Sunil Banarse, Henryk Michalewski, Simon Osindero 和 Tim Rocktäschel。Promptbreeder:通过提示进化实现自参照自我改进,2024。URL https://openreview.net/forum?id=HKkix32Zw1。
Jun Gao, Huan Zhao, Wei Wang, Changlong Yu 和 Ruifeng Xu。EventRL:通过结果监督增强大型语言模型的事件提取。2024。
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi 等人。Deepseek-r1:通过强化学习激励 Ilms 的推理能力。2025。
Qingyan Guo, Rui Wang, Junliang Guo, Bei Li, Kaitao Song, Xu Tan, Guoqing Liu, Jiang Bian 和 Yujiu Yang。连接大型语言模型与进化算法生成强大的提示优化器。在 The Twelfth International Conference on Learning Representations,2024。URL https://openreview.net/forum?id=ZG3RaNIs08。
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang 和 Weizhu Chen。LoRA:大型语言模型的低秩适应。在 International Conference on Learning Representations,2022。URL https://openreview.net/ forum?id=nZeVKeeFYf9。
Kuan-Hao Huang, I-Hung Hsu, Tanmay Parekh, Zhiyu Xie, Zixuan Zhang, Prem Natarajan, Kai-Wei Chang, Nanyun Peng 和 Heng Ji。TextEE:事件提取基准、重新评估、反思和未来挑战。在 Findings of the Association for Computational Linguistics ACL 2024,第 12804-12825 页,2024。
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press 和 Karthik Narasimhan。SWE-Bench:语言模型能否解决现实世界的 GitHub 问题?2023。
Brian Lester, Rami Al-Rfou 和 Noah Constant。规模的力量:参数高效提示调优。在 Marie-Francine Moens, Xuanjing Huang, Lucia Specia 和 Scott Wentau Yih(编辑),Proceedings of the 2021 年经验方法自然语言处理会议,第 3045-3059 页,线上和多米尼加共和国蓬塔卡纳,2021 年 11 月。计算机语言学协会。doi: 10.18653/v1/2021.emnlp-main.243。URL https://aclanthology.org/2021.emnlp-main.243/。
Peng Li, Tianxiang Sun, Qiong Tang, Hang Yan, Yuanbin Wu, Xuanjing Huang 和 Xipeng Qiu。CodeIE:大型代码生成模型是更好的少量样本信息提取器。在 Anna Rogers, Jordan Boyd-Graber 和 Naoaki Okazaki(编辑),Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),第 15339-15353 页,加拿大多伦多,2023 年 7 月。计算机语言学协会。doi: 10.18653/v1/2023.acl-long.855。URL https://aclanthology.org/2023.acl-long.855/。
Wenwu Li, Xiangfeng Wang, Wenhao Li 和 Bo Jin。自动提示工程调查:优化视角,2025。URL https://arxiv.org/abs/2502. 11560 。
Xiang Lisa Li 和 Percy Liang。Prefix-tuning:为生成优化连续提示。在 Chengqing Zong, Fei Xia, Wenjie Li 和 Roberto Navigli(编辑),Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers),第 4582-4597 页,线上,2021 年 8 月。计算机语言学协会。doi: 10.18653/v1/2021.acl-long. 353。URL https://aclanthology.org/2021.acl-long.353/。
Zixuan Li, Yutao Zeng, Yuxin Zuo, Weicheng Ren, Wenxuan Liu, Miao Su, Yucan Guo, Yantao Liu, Lixiang Lixiang, Zhilei Hu, Long Bai, Wei Li, Yidan Liu, Pan Yang, Xiaolong Jin, Jiafeng Guo 和 Xueqi Cheng。KnowCoder:将结构化知识编码到 LLMs 中以实现通用信息提取。在 Lun-Wei Ku, Andre Martins 和 Vivek Srikumar(编辑),Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),第 8758-8779 页,泰国曼谷,2024 年 8 月。计算机语言学协会。doi: 10.18653/v1/2024.acl-long.475。URL https://aclanthology.org/2024.acl-long.475/。
Yen-Ting Lin, Di Jin, Tengyu Xu, Tianhao Wu, Sainbayar Sukhbaatar, Chen Zhu, Yun He, Yun-Nung Chen, Jason Weston, Yuandong Tian 等人。Step-kto:通过逐步二元反馈优化数学推理。2025。
Agustin Mantaras。OpenAI 的 o1 和 o3-mini 推理模型的提示工程。Microsoft Tech Community Blog,2025 年 2 月。URL https://techcommunity. microsoft.com/blog/azure-ai-services-blog/prompt-engineering-for-openai%E2% 80%99s-o1-and-o3-mini-reasoning-models/4374010。
Hector D. Menendez, Gema Bello-Orgaz 和 Cristian Ramírez Atencia。Deepstableyolo:Deepseek 驱动的提示工程和基于搜索的优化用于人工智能图像生成。在 XVI Congreso Español de Metaheurísticas, Algoritmos Evolutivos y Bioinspirados,2025。URL https://openreview.net/forum?id=hZucDPawRu。
OpenAI。推理最佳实践。OpenAI Platform Documentation,2025 年 4 月。URL https://platform.openai.com/docs/guides/reasoning-best-practices# how-to-prompt-reasoning-models-effectively。
Archiki Prasad, Peter Hase, Xiang Zhou 和 Mohit Bansal。GrIPS:无需梯度的基于编辑的指令搜索以提示大型语言模型。在 Andreas Vlachos 和 Isabelle Augenstein(编辑),Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics,第 3845-3864 页,克罗地亚杜布罗夫尼克,2023 年 5 月。计算机语言学协会。doi: 10.18653/v1/2023.eacl-main.277。URL https://aclanthology.org/2023.eacl-main.277/。
Reid Pryzant, Dan Iter, Jerry Li, Yin Lee, Chenguang Zhu 和 Michael Zeng。自动提示优化与“梯度下降”和束搜索。在 Houda Bouamor, Juan Pino 和 Kalika Bali(编辑),Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing,第 7957-7968 页,新加坡,2023 年 12 月。计算机语言学协会。doi: 10.18653/v1/2023.emnlp-main.494。URL https: //aclanthology.org/2023.emnlp-main.494/。
Oscar Sainz, Iker García-Ferrero, Rodrigo Agerri, Oier Lopez de Lacalle, German Rigau 和 Eneko Agirre。GoLLIE:将注释指南纳入零样本信息提取。在 The Twelfth International Conference on Learning Representations,2024。URL https:// openreview.net/forum?id=Y3wpuxd7u9。
Taylor Shin, Yasaman Razeghi, Robert L. Logan IV, Eric Wallace 和 Sameer Singh。AutoPrompt:通过自动生成提示从语言模型中提取知识。在 Bonnie Webber, Trevor Cohn, Yulan He 和 Yang Liu(编辑),Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP),第 4222-4235 页,线上,2020 年 11 月。计算机语言学协会。doi: 10.18653/v1/2020.emnlp-main.346。URL https://aclanthology.org/2020.emnlp-main. 346/。
Saurabh Srivastava, Chengyue Huang, Weiguo Fan 和 Ziyu Yao。实例需要更多关怀:在循环中改写提示以获得更好的零样本性能。在 Lun-Wei Ku, Andre Martins 和 Vivek Srikumar(编辑),Findings of the Association for Computational Linguistics: ACL 2024,第 6211-6232 页,泰国曼谷,2024 年 8 月。计算机语言学协会。doi: 10.18653/v1/2024.findings-acl.371。URL https://aclanthology.org/2024.findings-acl.371/.
Saurabh Srivastava, Sweta Pati 和 Ziyu Yao。为事件提取使用注释指南微调 LLMs,2025。URL https://arxiv.org/abs/2502.16377.
Together AI。提示 Deepseek-r1。Together AI 文档,2025 年 2 月。URL https://docs.together.ai/docs/prompting-deepseek-r1.
Guoqing Wang, Zeyu Sun, Zhihao Gong, Sixiang Ye, Yizhou Chen, Yifan Zhao, Qingyuan Liang 和 Dan Hao。高级语言模型是否消除了软件工程中的提示工程需求?2024a.
Xingyao Wang, Sha Li 和 Heng Ji。Code4struct:用于少量样本事件结构预测的代码生成。在 Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),第 3640-3663 页,2023a.
Xinyuan Wang, Chenxi Li, Zhen Wang, Fan Bai, Haotian Luo, Jiayou Zhang, Nebojsa Jojic, Eric Xing 和 Zhiting Hu。Promptagent:通过语言模型进行战略规划以实现专家级提示优化。在 The Twelfth International Conference on Learning Representations,2024b。URL https://openreview.net/forum?id=22pyNNuIoa.
Zhen Wang, Rameswar Panda, Leonid Karlinsky, Rogerio Feris, Huan Sun 和 Yoon Kim。多任务提示微调实现参数高效的迁移学习。在 The Eleventh International Conference on Learning Representations,2023b。URL https://openreview.net/ forum?id=Nk2pDtuhTq.
Yuxin Wen, Neel Jain, John Kirchenbauer, Micah Goldblum, Jonas Geiping 和 Tom Goldstein。让硬提示变得简单:用于提示调整和发现的基于梯度的离散优化。在 Thirty-seventh Conference on Neural Information Processing Systems,2023。URL https://openreview.net/forum?id=V0stHxDdsN.
Hanwei Xu, Yujun Chen, Yulun Du, Nan Shao, Yanggang Wang, Haiyu Li 和 Zhilin Yang。GPS:遗传提示搜索实现高效的少量样本学习。在 Yoav Goldberg, Zornitsa Kozareva 和 Yue Zhang(编辑),Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing,第 8162-8171 页,阿拉伯联合酋长国阿布扎比,2022 年 12 月。计算机语言学协会。doi: 10.18653/v1/2022.emnlp-main. 559。URL https://aclanthology.org/2022.emnlp-main.559/.
Weijia Xu, Andrzej Banburski-Fahey 和 Nebojsa Jojic。重新提示:通过 Gibbs 采样实现自动化链式推理提示推断,2024。URL https://arxiv.org/abs/ 2305.09993.
Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V Le, Denny Zhou 和 Xinyun Chen。作为优化器的大规模语言模型。在 The Twelfth International Conference on Learning Representations,2024。URL https://openreview.net/forum?id=Bb4VGOWELI.
Xunjian Yin, Xinyi Wang, Liangming Pan, Xiaojun Wan 和 William Yang Wang。Gödel 智能体:自引用智能体框架实现递归自我改进,2025。URL https://arxiv.org/abs/2410.04444.
Tianjun Zhang, Xuezhi Wang, Denny Zhou, Dale Schuurmans 和 Joseph E. Gonzalez。TEMPERA:通过强化学习进行测试时提示编辑。在 The Eleventh International Conference on Learning Representations,2023。URL https://openreview.net/forum? id=gSHyqBi jPFO.
Tianyang Zhong, Zhengliang Liu, Yi Pan, Yutong Zhang, Yifan Zhou, Shizhe Liang, Zihao Wu, Yanjun Lyu, Peng Shu, Xiaowei Yu 等人。OpenAI o1 评估:AGI 的机遇与挑战。2024.
Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan 和 Jimmy Ba。大型语言模型是人类级别的提示工程师。在 The Eleventh International Conference on Learning Representations,2022.
A 相关工作
提示优化已经成为适应大型语言模型(LLMs)以完成下游任务而不修改其权重的一个重要方向。对于具有可访问内部状态的模型,如开源 LLMs,先前的工作探索了软提示微调(Li & Liang, 2021; Lester 等人,2021;Wang 等人,2023b;Hu 等人,2022)以及直接调整提示嵌入的基于梯度的搜索方法(Shin 等人,2020;Wen 等人,2023)。还应用了强化学习通过交互反馈来优化提示(Deng 等人,2022;Zhang 等人,2023)。
然而,这些方法不适用于通过 API 访问的闭源 LLMs,因为它们无法提供梯度和内部表示。在这种情况下,研究集中于无需梯度的黑盒技术,依赖于提示扰动和评分。许多这些方法在一个迭代循环中操作:从初始提示开始,生成变体,在保留数据上进行评估,并保留最佳结果以供下一轮使用。变体可以通过短语级别编辑(Prasad 等人,2023)、反向翻译(Xu 等人,2022)、进化操作(Guo 等人,2024;Fernando 等人,2024)或通过提示另一个 LLM 根据模型错误重写提示(Zhou 等人,2022;Pryzant 等人,2023;Yang 等人,2024;Srivastava 等人,2024;Wang 等人,2024b)生成。为了提高探索效率,还探索了更结构化的策略,如蒙特卡罗搜索(Zhou 等人,2022)、吉布斯采样(Xu 等人,2024)和束搜索(Pryzant 等人,2023)。尽管如此,大多数这些技术本质上仍然局限于局部——关注附近的编辑——并且通常缺乏长期规划或引导细化的机制。
最近的努力提出了结构化的提示优化。APE(Zhou 等人,2022)使用蒙特卡罗树搜索(MCTS)探索提示空间,而 PromptBreeder(Fernando 等人,2024)和 EvoPrompt(Guo 等人,2024)则通过反馈驱动的突变策略演化提示。OPRO(Yang 等人,2024)采用由模型性能引导的突变搜索。其他系统,如 PromptWizard(Agarwal 等人,2024)和 Gödel Machine(Yin 等人,2025),纳入了自演进机制,其中 LLM 迭代生成、批评并细化自己的提示和示例。
虽然这些方法很有前景,但迄今为止它们仅应用于大型通用 LLMs。据我们所知,我们的工作是首次调查 LRMs 的提示优化。此外,我们在事件提取这一结构化预测任务的背景下引入并研究了这一框架——这与之前工作中探讨的典型数学或推理任务有所不同(Zhou 等人,2022;Srivastava 等人,2024)。
B 其他细节
B. 1 更多实现细节
为了有效优化特定任务的性能提示,我们采用了一个蒙特卡罗树搜索(MCTS)框架,该框架基于模型反馈和奖励信号迭代地探索和细化提示。提出的算法如算法 1 所述,结合结构化探索与引导优化,利用任务模型、反馈生成优化器和奖励函数。在每次迭代中,算法执行选择、扩展、模拟和回溯步骤,逐步改进提示以最大化采样批次上的任务性能。
算法 1 基于 MCTS 的提示优化算法
输入:
初始提示 \(s_{0}=\mathcal{P}_{0}\),任务模型 \(\mathcal{M}_{\text {task }}\),优化器 \(\mathcal{M}_{\text {opt }}\),奖励函数 \(\mathcal{R}\),批大小 \(k\),
深度限制 \(L\),迭代次数 \(\tau\),探索权重 \(c\)
初始化:
状态-动作映射 \(A: \mathcal{S} \mapsto \mathcal{F}\),子节点映射 ch : \(\mathcal{S} \times \mathcal{F} \mapsto \mathcal{S}\),奖励 \(r: \mathcal{S} \times \mathcal{F} \mapsto \mathbb{R}\)。
Q 值 \(Q: \mathcal{S} \times \mathcal{F} \mapsto \mathbb{R}\),访问计数 \(\mathcal{N}: \mathcal{S} \mapsto \mathbb{N}\)
for \(n \leftarrow 0, \ldots, \tau-1\) do
从训练数据中采样一批 \(\left(Q_{\text {batch }}, A_{\text {batch }}\right)\)
for \(t \leftarrow 0, \ldots, L-1\) do
if \(A\left(s_{t}\right)\) 不为空 then \(\triangleright\) 选择
\(f_{t} \leftarrow \arg \max _{f \in A\left(s_{t}\right)}\left(Q\left(s_{t}, f\right)+c \cdot \sqrt{\frac{\ln \mathcal{N}\left(s_{t}\right)}{\mathcal{N}\left(\operatorname{ch}\left(s_{t}, f\right)\right)}}\right)\)
\(s_{t+1} \leftarrow \operatorname{ch}\left(s_{t}, f_{t}\right), r_{t} \leftarrow r\left(s_{t}, f_{t}\right), \mathcal{N}\left(s_{t}\right) \leftarrow \mathcal{N}\left(s_{t}\right)+1\)
else \(\triangleright\) 扩展和模拟
(第一步) 答案生成: \(\hat{Q}_{\text {batch }} \sim \mathcal{M}_{\text {task }}\left(Q_{\text {batch }}, s_{t}\right)\)
(第二步) 错误提取: 使用解释器识别 \(\hat{A}_{\text {batch }}\) 中的错误
(第三步) 反馈生成: \(f_{t} \sim \mathcal{M}_{\text {opt }}(\) 反馈 \(\left|s_{t}\right.\), 错误)
(第四步) 提示更新: \(s_{t+1} \sim \mathcal{M}_{\text {opt }}\left(s \mid s_{t}, f_{t}\right)\)
更新 \(A\left(s_{t}\right) \leftarrow\left\{f_{t}\right\}, \operatorname{ch}\left(s_{t}, f_{t}\right) \leftarrow s_{t+1}, r\left(s_{t}, f_{t}\right) \leftarrow \mathcal{R}\left(\hat{A}_{\text {batch }}, A_{\text {batch }}\right)\)
\(r_{t} \leftarrow r\left(s_{t}, f_{t}\right), \mathcal{N}\left(s_{t}\right) \leftarrow \mathcal{N}\left(s_{t}\right)+1\)
end if
if \(s_{t+1}\) 是一个提前停止状态 then
break
end if
end for
\(T \leftarrow\) 步骤数量
for \(t \leftarrow T-1, \ldots, 0\) do \(\triangleright\) 回溯传播
使用 rollout 奖励 \(\left\{r_{t}, \ldots, r_{L}\right\}\) 更新 \(Q\left(s_{t}, f_{t}\right)\)
end for
end for
```
# B. 2 批量提示
由于对每个输入单独查询 LLMs 会产生大量的计算成本,因此逐个处理输入的天真方法效率低下。为缓解这一点,我们采用了批量提示(Cheng 等人,2023),它允许将多个查询合并为一个结构化的提示。给定一批共享相同任务指令 \(\mathcal{P}_{T}\) 的输入 \(\left\{Q_{1}, Q_{2}, \ldots, Q_{n}\right\}\),批量提示构建了一个串联的输入字符串形式为 \(\left[\mathcal{P}_{0} \mid\left|Q_{1}\right|\left|Q_{2}\right|\right] \ldots \mid\left|Q_{n}\right]\)。每个查询都唯一标记(例如,“text1”)以保持顺序和结构。模型处理这批数据并生成结构化响应形式为 \(\left[A_{1} \| A_{2} \| \ldots \| A_{n}\right]\),其中每个 \(A_{i}\) 对应 \(Q_{i}\) 的输出。这些响应被解析以提取单个预测,同时保持对齐。通过减少 API 调用次数,同时维持高任务准确性,批量提示提高了效率,使大规模提示优化成为可能。
## B. 3 将提示优化视为搜索问题
虽然批量提示提高了效率,但它本身并不一定改善任务性能。为解决此问题,我们将提示优化形式化为在庞大的自然语言提示空间 \(\mathcal{S}\) 上的搜索问题。目标是在采样批次上发现一个最优提示 \(\mathcal{P}^{*}\),以最大化特定任务的评估函数 \(\mathcal{R}\),例如事件提取的 F-score,正式定义为:
\(\mathcal{P}^{*}=\arg \max _{\mathcal{P} \in \mathcal{S}} \mathcal{R}\left(p_{\mathcal{M}_{\text {task }}}\left(a_{\text {batch }} \mid q_{\text {batch }}, \mathcal{P}\right)\right)\) 其中 \(q_{\text {batch }}\) 和 \(a_{\text {batch }}\) 分别表示批量化查询和响应。由于这个空间太大而无法全面探索,我们引入了一个次级 LLM,\(\mathcal{M}_{\text {opt }}\),根据 \(\mathcal{M}_{\text {task }}\) 输出中观察到的错误迭代细化 \(\mathcal{P}_{0}\)。如图 2 所示,这种迭代细化持续进行,直到达到预定义的停止条件,例如性能收敛或固定数量的优化步骤。优化完成后,最终优化的提示 \(\mathcal{P}^{*}\) 用于未见过的测试数据的推理。
# B. 4 反馈(\(m_{f b}\))和优化(\(m_{o p t}\))的元提示
反馈收集提示。以下是我们呈现的元提示 \(m_{f b}\),用于从 \(\mathcal{M}_{\text {opt }}\) 收集结构化反馈。
我正在为设计用于事件提取任务的语言模型编写事件指南和提示(或任务指令)。
我的当前提示是:
{cur_prompt}
Python 格式的事件指南如下所示:
{event_definitions}
任务包括:
- 从文本中提取结构化事件(触发器、事件类型、参数及其角色)。
-
- 遵循严格的 Python 语法进行输出(Python 事件实例列表)。
-
- 准确处理所有事件定义,包括强制性角色和边缘情况。
- 但是这个提示出现了以下示例错误:
- {example_string}
- 对于每个示例,请执行以下逐步分析:
-
- 错误类型分类:识别每个示例的具体错误类型(例如,跨度提取错误、缺失角色、虚假参数、格式违规等)。
11.2. 根本原因分析:
a. 当前指南是否未能清晰解释关键提取规则?
b. 事件定义(指南)后的‘#’指令是否模糊、不一致或不足?
c. 角色(例如agentvs.person)中是否存在导致混淆的歧义或重叠? - 示例特定建议:
- 建议对指南(事件指南后的‘#’评论)进行精确更改,以修复给定示例的错误。
-
- 包括针对模糊角色或边缘情况的“what_to_do”和“what_not_to_do”明确指令。
-
- 提供简单示例和反示例以说明每个指南。
- 总体趋势:识别所有示例中指南的反复出现的问题。
预期输出:
- 对于所有示例,总结并列出所有可操作的更改以改进所有类别的事件定义,包括:
14.```- 改进事件/角色定义的清晰度。
-
- 增强处理模糊或重叠角色的能力。 -
- 指南用于精确跨度提取。 -
- 提出指出当前指南中的错误并提出所有类别改进的输出。每个改进应包括:
-
- 对于事件,更新“what_to_do”和“what_not_to_do”的指南。 -
- 每个角色的示例和反示例。 -
任务指令和指南优化提示。以下是用于优化任务指令和事件指南的提示 (m_{\text {opt }})。
我正在优化设计用于事件提取任务的语言模型的提示。
我的当前提示(或任务指令)是:
<START>
{cur_prompt}
<END>
Python 格式的事件指南如下所示:
<START>
{event_definitions}
<END>
但这个提示在以下示例中出错:
<START>
{example_string}
<END>
基于这些错误,事件指南的问题及原因是:
<START>
{feedback}
<END>
这里有一系列之前的事件指南,包括当前的指南,每个指南都是从前一个提示修改而来:
<START>
{trajectory_prompts}
<END>
给予我的事件类优化指南:
- 细化提示(或任务指令)以解决上述问题。重点在于:
-
- 清晰的跨度提取和角色定义指令,包括任何例外。
-
- 有效处理模糊或重叠的角色。
-
- 严格遵循可解析的 Python 输出格式。
- 根据已识别的错误细化事件定义指南(指令后
#)确保细化的指南解决了上述问题。 -
- 保持向后兼容性:确保先前正确的示例仍有效。
-
- 不要改变本体(Python 类)。相反,提供按照结尾给出的格式的细化指南。
-
- 确保输出遵循以下格式:
- 优化的提示(或任务指令)用 和 包裹。
-
- 细化的指南用 <CLASS_START> 和 <CLASS_END> 包裹。
输出要求:
- 细化的指南用 <CLASS_START> 和 <CLASS_END> 包裹。
9. 我必须提供从当前提示逐步演化的优化提示(或任务指令)。
10.2. 我还必须提供包含以下结构下每个事件定义完全优化的指南的输出:
class Event_Name(Parent_Event):
\^\^\"
#_Updated_guidelines_here_consulting_the_problems_given_to_me
..__\^\^\"
__\n
__mention:_str_#_refined_comments_or_extraction_rules_for_event_
triggers._Include_what/who_can_play_the_role_with_examples.
((role1)): List_#_do_the_same_for_all_roles_including_"mention",
refining_the_comments_after_"#". Include what/who can play the role
with examples and span extraction rule.
我的响应是:
```
# B. 5 数据分割
我们使用了两个较短版本的 \(\mathrm{ACE} 05, \mathrm{ACE}_{low}\) 和 \(\mathrm{ACE}_{\text {med }}\)。其详细描述见第 3.1 节。表 3 展示了选定事件类型(ETs)在 \(\mathrm{ACE}_{low}, \mathrm{ACE}_{\text {med }}\) 和开发(Dev)集中的分布。这些子集是为了模拟低资源和中等资源场景而精心挑选的。频繁 ETs 如 SentenceAct 和 Die 与较少见的如 PhoneWrite 和 DeclareBankruptcy 对比,允许进行多样化的评估范围。None 类包括没有标注事件的实例,保留了真实的类别分布。
## B. 6 额外超参数和 MCTS 配置
类似于 Wang 等人(2024b),我们提供了实验中使用的超参数和蒙特卡罗树搜索(MCTS)配置的详细信息。对于所有运行,我们将搜索树的深度限制 \(L\) 设为 5,MCTS 迭代次数 \(\tau\) 设为 12,除非另有说明。探索-利用权衡由探索权重 \(c\) 控制,我们根据先前的工作将其设为 2.5。每次展开的批大小 \(k\) 设为 15。
我们使用贪婪解码对任务模型 \(\mathcal{M}_{\text {task }}\) 进行确定性预测的模拟,而对于优化器模型 \(\mathcal{M}_{\text {opt }}\) 使用温度采样 \(T=0.7\) 来促进
| | 训练 <br> \(\mathbf{A C E}_{\text {low }}\) | 训练 <br> \(\mathbf{A C E}_{\text {med }}\) | 开发 |
| :-- | :--: | :--: | :--: |
| TransferMoney | 3 | 13 | 29 |
| Meet | 2 | 15 | 13 |
| PhoneWrite | 1 | 11 | 1 |
| SentenceAct | 6 | 25 | 4 |
| Appeal | 2 | 16 | 4 |
| Convict | 5 | 11 | 5 |
| Sue | 3 | 13 | 8 |
| EndOrg | 1 | 11 | 1 |
| Die | 2 | 26 | 15 |
| DeclareBankruptcy | 1 | 11 | 1 |
| None | 5 | 20 | 30 |
表 3: 选定 ETs 的数据分布。
逆向反馈生成。如果连续两次展开中提示未导致任何错误,则在 MCTS 中触发早期停止。
## C 额外实验细节
## C. 1 初步实验和模型选择
为完整 MCTS 树进行提示优化可能会带来很高的计算成本,正如先前工作 Wang 等人(2024b)所指出的那样。为了在扩展之前建立基础,我们进行了初步实验以分析批大小对性能和计算效率的影响。由于批提示减少了 API 调用的数量,我们尝试了不同批大小来构造 \(Q_{\text {batch }}\),通过变化查询 \(Q_{i}\) 和相应输出 \(A_{i}\) 的数量。然而,我们发现确定任何 LLM 的最佳批大小高度依赖于模型,并且缺乏普遍适用的启发式方法
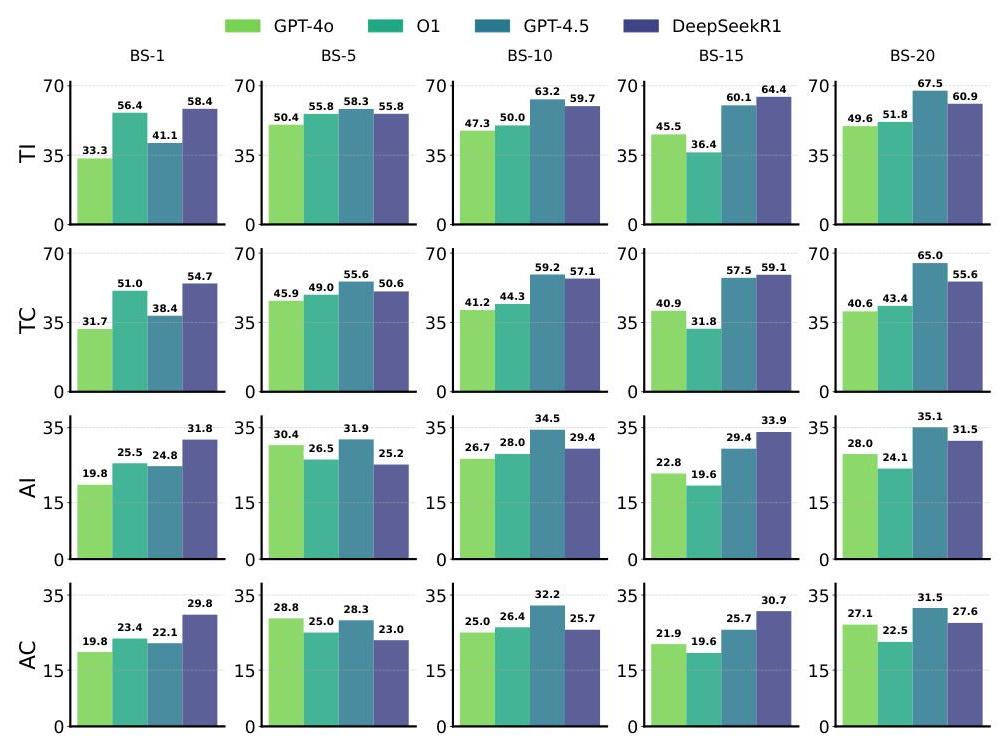
图 9: 批量性能。
(图 9)。鉴于这种不确定性,我们将批大小设置为 15 ,因为它提供了 15 倍的 API 调用减少,同时保持响应质量。这一选择确保了计算可行性,同时允许提示优化在预算限制内有效运行。为了进一步完善实验设置并在扩展到完整的 MCTS 搜索之前进行初步试验,我们使用了一次 MCTS 迭代。在这个受控设置中,我们实例化了一个对应于初始任务提示的根节点,并生成了三个代表不同提示细化的子节点。这种有限的探索使我们能够在不同的模型设置下评估事件提取中提示优化的效果。
# D 额外结果和分析
在本节中,我们展示了通过由不同优化器模型引导的蒙特卡罗树搜索(MCTS)优化的各种任务模型的综合评估。我们分析了多个配置下的性能,包括不同数据集大小(\(\mathrm{ACE}_{\text {low }}\),\(\mathrm{ACE}_{\text {med }}\) 和 ACE 测试集)和 MCTS 深度。我们的分析强调了任务模型和优化器模型之间的相互作用,以及优化过程的深度如何影响触发器和参数预测指标的性能。
## D. 1 完整结果
表 4 比较了四个任务模型——DeepSeek-R1,o1,GPT-4.5 和 GPT-4o——在四个关键指标下由不同优化器模型优化后的性能:触发器识别(TI),触发器分类(TC),参数识别(AI)和参数分类(AC)。每行对应一个任务模型,每列组对应一个特定优化器指导 MCTS 期间的提示更新。这种布局使我们能够分析任务模型的稳健性以及各种优化器在浅层 MCTS 设置下的相对有效性。
| 模型 | DeepSeek-R1 (优化器) | | | | o1 (优化器) | | | | | GPT-4.5 (优化器) | | | | | GPT-4o (优化器) | | | |
| :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
| | TI | TC | AI | AC | TI | TC | AI | AC | | TI | TC | AI | AC | | TI | TC | AI | AC |
| DeepSeek-R1 | 37.5 | 33.93 | 25.57 | 24.66 | 27.72 | 25.74 | 18.67 | 18.67 | | 36.89 | 34.95 | 22.91 | 22.91 | | 32.78 | 32.78 | 21.83 | 21.83 |
| o1 | 31.54 | 31.54 | 21.92 | 21.92 | 29.33 | 29.33 | 18.96 | 18.96 | | 31.91 | 31.91 | 18.57 | 18.57 | | 29.24 | 29.24 | 21.74 | 20.29 |
| GPT-4.5 | 36.04 | 34.23 | 23.14 | 22.31 | 34.78 | 33.04 | 20.07 | 19.33 | | 31.37 | 31.37 | 19.32 | 19.32 | | 30.29 | 30.29 | 20.97 | 20.19 |
| GPT-4o | 35.29 | 35.29 | 22.07 | 20.15 | 28.28 | 28.28 | 18.18 | 18.18 | | 30.61 | 30.61 | 16.67 | 16.67 | | 31.67 | 31.67 | 19.57 | 18.83 |
表 4: 在 \(\mathrm{ACE}_{\text {low }}\) 上使用 MCTS 深度 1 的完整结果。
我们进一步在 \(\mathrm{ACE}_{\text {med }}\) 数据集上评估我们的方法,使用相同的 MCTS 配置,深度为 1 。表 5 报告了在不同优化器模型下的四个任务模型的性能。与 \(\mathrm{ACE}_{\text {low }}\) 相比,这种中等资源设置使我们能够深入了解任务模型和优化器模型的泛化性和适应性。结果显示,某些组合(例如,o1 自我优化)在触发器性能上显著更强,而其他组合在参数级别指标上显示出更平衡的收益。
| 模型 | DeepSeek-R1 (优化器) | | | | o1 (优化器) | | | | | GPT-4.5 (优化器) | | | | | GPT-4o (优化器) | | | |
| :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
| | TI | TC | AI | AC | TI | TC | AI | AC | | TI | TC | AI | AC | | TI | TC | AI | AC |
| DeepSeek-R1 | 63.16 | 63.16 | 40.00 | 40.00 | 65.45 | 65.45 | 32.2 | 32.2 | | 56.25 | 56.25 | 37.14 | 37.14 | | 62.7 | 62.7 | 40.06 | 38.77 |
| o1 | 78.95 | 78.95 | 39.13 | 36.96 | 54.78 | 54.78 | 33.96 | 30.19 | | 59.26 | 59.26 | 36.67 | 36.67 | | 57.14 | 57.14 | 36.98 | 36.98 |
| GPT-4.5 | 64.71 | 64.71 | 35.42 | 35.42 | 46.15 | 46.15 | 29.63 | 29.63 | | 63.57 | 63.57 | 35.94 | 35.94 | | 59.21 | 59.21 | 38.1 | 36.51 |
| GPT-4o | 30.00 | 30.00 | 25.88 | 25.1 | 28.57 | 28.57 | 22.32 | 22.32 | | 34.55 | 34.55 | 27.54 | 27.54 | | 29.38 | 29.38 | 26.99 | 26.3 |
表 5: 在 \(\mathrm{ACE}_{\text {med }}\) 上使用 MCTS 深度 1 的完整结果。
我们现在报告在使用深度为 5 的 MCTS 配置的 \(\mathrm{ACE}_{\text {med }}\) 数据集上的结果。表 6 总结了每个任务模型在四种不同优化器下的性能。与较浅的设置相比,这种更深的搜索允许更广泛的提示细化,这可能导致更好的泛化或潜在的过拟合,具体取决于优化器-任务模型组合。值得注意的是,某些模型如 o1 在与 GPT-4.5 作为优化器配对时表现出强大的触发器级性能,而其他模型在参数指标方面显示出更平衡的收益。这些结果强调了优化过程对 MCTS 深度和优化器选择的敏感性。
| 模型 | DeepSeek-R1 (优化器) | | | | o1 (优化器) | | | | | GPT-4.5 (优化器) | | | | | GPT-4o (优化器) | | | |
| :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
| | TI | TC | AI | AC | TI | TC | AI | AC | | TI | TC | AI | AC | | TI | TC | AI | AC |
| DeepSeek-R1 | 56.6 | 56.6 | 44.26 | 44.26 | 66.67 | 66.67 | 44.93 | 40.58 | | 46.15 | 46.15 | 40.8 | 38.4 | | 48.28 | 48.28 | 40.51 | 37.97 |
| o1 | 48.08 | 48.08 | 40.74 | 39.81 | 42.86 | 42.86 | 38.71 | 38.71 | | 84.68 | 84.68 | 41.48 | 37.78 | | 48.28 | 48.28 | 34.64 | 33.52 |
| GPT-4.5 | 45.68 | 45.68 | 38.36 | 37.74 | 51.24 | 51.24 | 36.22 | 36.22 | | 59.26 | 59.26 | 36.24 | 37.58 | | 41.18 | 41.18 | 32.35 | 32.35 |
| GPT-4o | 49.09 | 49.09 | 28.11 | 27.31 | 61.11 | 61.11 | 28.57 | 28.57 | | 52.00 | 52.00 | 27.03 | 27.03 | | 61.54 | 61.54 | 29.91 | 28.04 |
表 6: 在 \(\mathrm{ACE}_{\text {med }}\) 上使用 MCTS 深度 5 的完整结果。
为了评估优化提示的泛化能力,我们使用 MCTS 深度为 5 的配置在 ACE 测试集上对所有模型-优化器组合进行评估。表 7 展示了性能结果。此设置代表最终评估阶段,其中模型在经过更深入探索驱动的提示优化后,在未见过的样本上进行测试。总体而言,结果显示性能趋势与开发集上的观察结果一致,尽管某些组合(如 DeepSeek-R1 自我优化)表现出更强的稳定性,而其他组合则在参数级别指标上略有下降。这些观察结果进一步强化了优化器选择和 MCTS 深度对下游泛化的影响。
# D. 2 错误类别和示例
为了更好地理解我们的方法局限性和模型在提示优化期间的失败性质,我们通过分类常见错误进行了定性错误分析。表 8 总结了多次评估运行中遇到的关键错误类别,以及代表性示例和详细描述。这些类别——从解析问题和幻觉到更深的语言挑战如共指和隐含事件检测——突显了模型在批量提示和复杂事件结构下容易遇到的困难区域。
| 错误类别 | |
| :--: | :--: |
| 解析错误 | 描述:当模型的输出不是预期格式(例如 JSON 或结构化列表)时会发生解析错误,通常由于批量提示中的额外推理或冗长响应导致。这使得输出无法用于评估管道。 |
| | 示例:返回额外文本或评论而不是有效 Python 结构的提示,导致不可解析输出。 |
| 幻觉 | 描述:幻觉发生在模型生成不受输入支持的参数或事件时。这通常是由于训练过程中学到的偏差或与已知标签的词汇重叠所致。 |
| | 示例:文本:"今天不同部分的条带发生了冲突。" → 模型错误预测基于单词 "冲突" 的 'Conflict' 事件。 |
| 多个事件 | 描述:多个事件错误发生在模型仅检测到包含多个事件的句子中的一个事件时,通常默认为最显著或最后一个事件。 |
| | 示例:文本:"...回家后他的岳父杀了他。" → 模型仅预测 'Die' 事件,忽略 'Transport' 事件。 |
| 标签噪声 | 描述:标签噪声指的是数据集中注释的不一致性或模糊性,例如共指处理的不同对待或事件边界不清,这混淆了训练和评估过程。 |
| | 示例:文本:"我们的总统反复...依赖于一个人...侯赛因·卡梅尔...领导伊拉克武器计划并叛逃的人..." → 标签使用 'person»["leader"]'; 模型使用 'person»["Hussein Kamel"]'. |
| 共指 | 描述:共指错误发生在模型未能将代词或基于角色的描述符解析为其实际实体时,导致参数跨度错误或不完整。 |
| | 示例:文本:"...侯赛因·卡梅尔,领导伊拉克武器计划并叛逃的人..." → 标签使用 "leader"; 模型使用 "Hussein Kamel",突出共指解析挑战。 |
| 跨度过度预测 | 描述:跨度过度预测发生在模型预测比任务最小跨度规则所需的更详细的参数跨度时,通常包括不需要的任务修饰语或描述符。 |
| | 示例:文本:"今天发出命令部署 17,000 名美国陆军士兵在波斯湾地区。" → 标签:"soldiers"; 预测:"17,000 U.S. Army soldiers" - 包括额外修饰语。 |
| 隐含事件 | 描述:隐含事件是指不由动词直接触发但通过形容词、名词或其他上下文推断出的事件(例如 "former")。除非明确指示,否则模型通常会错过这些事件。 |
| | 示例:文本:"...前众议员汤姆·安德鲁斯..." → 触发词 "former" 暗示 'EndPosition',但如果缺乏隐含事件检测规则,模型通常会错过。 |
表 8: 错误类别的描述及示例。
# E 优化后的任务指令和指南
在本节中,我们展示了由 DeepSeek-R1、o1、GPT-4.5 和 GPT-4o 生成的完全优化后的任务指令和事件指南。
## E. 1 DeepSeek-R1 生成的最佳任务指令和事件指南示例
事件提取任务:使用 Python 类定义从文本中提取结构化事件。遵循以下规则:
- 跨度提取;
-
- **触发器**:直接表达事件的最小连续跨度(动词/名词)。包括动词和名词形式("death" = Die, "killings" = Die)。添加新触发器如 "converge" 对于 Meet 和 "is_no_more" 对于 EndOrg -
- **参数**; -
- 删除冠词("a/an/the")和所属代词,除非是正式名称或时间短语的一部分("The_Hague", "the_ past_year") -
- 使用同句先行词立即解析代词和所属名词("airline's_plan" → ["airline"]) -
- 从参数中删除角色/位置/年龄描述符("Philadelphia_lawyers" → "lawyers"),除非是多词犯罪的一部分 -
- 保留犯罪/金钱的完整跨度,包括来源/金额("stereo_worth_\$1,750_from_family"),除非是法律术语 -
- 通过所有权标记检测受益人("for_X's_project"),直接 "to_X" 转移归接收者 -
- 特殊处理;
-
- 破产触发器:“went_bust” → EndOrg,除非有明确的破产上下文
-
- **会面实体**:包括所有可解析的参与者(主体+对象) -
- **犯罪跨度**:保留完整的上下文子句("If_convicted_of_killing...")不截断 -
- **时间短语**:当短语的一部分时保留原始跨度("the_early_90's") -
- 输出规则:
-
- 始终以 Python 格式输出 [EventName("mention" = "trigger", "arg1_key" = "arg1_span", ...), EventName("mention" = "trigger", "arg1_key" = "arg1_span", ...)] -
- 包括所有角色字段,并在适用时用空列表 -
- 每个触发器输出单独事件(不合并),即使事件类型相同 -
- 严格 pydantic 语法:[EventName(mention="span", role=["span"], ...)] -
- 保留地点的原始大小写,除非明确是专有名词 -
- 关键例外:
-
- **组织结束触发器**:添加 "collapse", "drive_out", "went_bust" 并明确提及组织 -
- **上诉角色**:被告 = 反对方(州),检察官 = 上诉人 -
- **转账**:"for_X" → 接收者,除非是所有权标记("for X's_Y" → 受益人) -
- **电话/书写实体**:删除所有角色描述符("Secretary_Powell" → ["Powell"]) -
-
-
这里是事件定义:
- class Convict(JusticeEvent):
-
"""提取被判定有罪的实体。 -
关键更新: -
- 犯罪:保留完整的跨度,包括金额/来源("收到价值 $1,750 的立体声设备来自家庭") -
示例:"被判犯有受贿罪价值 $1M" -> 犯罪=["收受贿赂价值 $1M"] -
反例:截断为 ["收受贿赂"] -> 错误 -
""" -
mention: str # 触发词:"被判有罪", "判决" -
defendant: List[str] # ["Vang"] (解析代词,删除描述词) -
adjudicator: List[str] # ["法院"] (仅官方名称) -
crime: List[str] # 完整犯罪跨度,不包括法律术语 -
time: List[str] # ["上周三"] (确切的时间短语) -
place: List[str] # ["明尼苏达州"] (从上下文中提取的地缘政治实体) - class TransferMoney(TransactionEvent):
-
"""不涉及商品交换的金钱转移。 -
关键更新: -
- 接收者:直接接收者("to X" 或 "for X" 如果 X 是终点) -
- 受益人:仅限所有权("for X's project")或间接收益 -
示例:"捐赠 $5 给 Tim Kaine" -> 接收者=["Tim Kaine"] -
示例:"资金用于 Kaine's campaign" -> 受益人=["Kaine"] -
""" -
mention: str # 触发词:"提供资金", "捐赠" -
giver: List[str] # ["基金会"] (删除描述词) -
receiver: List[str] # ["慈善机构"] (直接从 "to/for X" 接收) -
beneficiary: List[str] # ["Suha"] (来自所有权标记) -
money: List[str] # ["$15M"] (保留符号/近似值) -
time: List[str] # ["两年"] (完整时间跨度) -
place: List[str] # ["瑞士"] (起源地,删除介词) - class Meet(ContactEvent):
-
"""面对面互动。 -
关键更新: -
- 实体:包括所有可解析的参与者(主体 + 对象) -
示例:"Annan 会见 Al-Douri" -> 实体=["Annan", "Al-Douri"] -
反例:省略主体 -> 错误 -
""" -
mention: str # 触发词:"会面", "峰会", "会谈" -
entity: List[str] # ["代表"] (所有参与者) -
time: List[str] # ["今天"] (确切时间跨度) -
place: List[str] # ["达拉斯"] (解析的位置名词) - class PhoneWrite(ContactEvent):
-
"""非面对面沟通。 -
关键更新: -
- 实体:删除所有角色描述符,除非是复合名称的一部分 -
示例:"来自国务卿 Powell 的电子邮件" -> 实体=["Powell"] -
反例:保留 "国务卿" -> 错误 -
""" -
mention: str # 触发词:"致电", "电子邮件" 并带有传输上下文 -
entity: List[str] # ["我们", "他们"] (裸名,解析代词) -
time: List[str] # ["开会期间"] (确切时间短语) -
-
-
place: List[str] # ["办公室"] (如果存在,则具体位置) - class DeclareBankruptcy(BusinessEvent):
-
"""正式的破产声明。 -
关键规则: -
- 实体:解析组织代词和所属名词 ("airline's 破产" → ["airline"]) -
- 触发词:"破产", "Chapter 11" (排除没有明确破产上下文的 "collapse"/"went bust") -
示例:"airline's 破产申请" → 提及="破产", org=["airline"] - 反例:“濒临崩溃” → EndOrg
-
""" -
mention: str # 表示财务崩溃的触发词:"破产", "Chapter 11" -
entity: List[str] # ["Enron Corp"] (从同句代词/所属关系解析的组织) -
time: List[str] # ["2003"] (声明时间短语) -
place: List[str] # ["德州"] (如果指定,则为司法名词) - class EndOrg(BusinessEvent):
-
"""组织终止事件。 -
关键规则: -
- 触发词:"停止运营", "不再存在", "collapse", "驱逐", "went bust" -
- org:需要明确提及组织("casinos 面临 collapse" 中的 "casinos") -
示例:"公司破产" → 提及="went bust", org=["公司"] -
反例:"面临 collapse" (无明确组织)→ 忽略 -
""" - mention: str # 触发词必须表示实际终止
-
org: List[str] # ["工厂"] (直接对象或所属名词) -
time: List[str] # ["过去一年"] (当作为短语一部分时保留冠词) -
place: List[str] # ["尤金"] (具体位置名词) - class Die(LifeEvent):
-
"""死亡事件。 -
关键更新: -
- 提及:将名词形式("杀戮", "伤亡")作为有效触发词 -
示例:"屠杀伤亡" → 提及="伤亡" -
反例:"死刑" → 忽略 -
""" -
mention: str # 触发词:"死亡", "杀戮", "伤亡" -
agent: List[str] # ["枪手"] (仅故意行为者) -
victim: List[str] # ["患者"] (不包括量化词/所属关系) -
instrument: List[str] # ["刀"] (特定工具/武器) -
time: List[str] # ["昨晚"] (确切跨度) -
place: List[str] # ["医院"] (死亡地点名词) - class SentenceAct(JusticeEvent):
-
"""惩罚发布事件。 -
关键更新: -
- 犯罪:保留条件子句中的原始犯罪("如果被判杀人..." → ["杀人"]) -
示例:"因欺诈面临终身监禁" → 犯罪=["欺诈"] - 反例:“可能面临惩罚” → 忽略
-
""" -
mention: str # 触发词:"判处", "面临"。必须引用实际惩罚 -
defendant: List[str] # ["活动家"] (删除角色描述词) -
adjudicator: List[str] # ["陪审团"] (除非是官方头衔,否则删除角色) -
crime: List[str] # ["非法参加会议"] (完整上下文跨度) -
sentence: List[str] # ["终身监禁"] (确切惩罚短语) -
time: List[str] # ["周四"] (确切时间表达) -
place: List[str] # ["地区法院"] (决定地点名词) - class Sue(JusticeEvent):
-
"""法律诉讼发起事件。 -
关键更新: -
- 裁决者:如果案件由裁决者批准("经法官批准" → ["法官"]) -
示例:"针对 Gateway 的诉讼经法官批准" → 裁决者="法官" - 反例:“诉讼文件” → 裁决者=[]
-
""" -
mention: str # 触发词:"诉讼", "起诉"。必须引用法律文件 -
plaintiff: List[str] # ["患者"] (删除地点/角色,除非是关键信息) -
defendant: List[str] # ["Gateway"] (明确被起诉的实体) -
adjudicator: List[str] # ["法官"] (如果直接参与) -
crime: List[str] # ["过失"] (明确违法行为,不包括法律术语) -
time: List[str] # ["上个月"] (保留时间短语中的冠词) -
place: List[str] # ["南佛罗里达州"] (特定名词短语) - class Appeal(JusticeEvent):
-
"""法院裁决上诉。 -
关键更新: -
- 被告:反对方(州/公诉人),不是上诉人 -
- 检察官:提起上诉的实体(从主体/代词解析) -
示例:"Anwar 对定罪提出上诉" → 检察官=["Anwar"], 被告=[] - 反例:将上诉人视为被告 → 错误
-
""" -
mention: str # 触发词:"上诉", "上诉s" -
defendant: List[str] # ["州"] (原案件中的反对方) -
prosecutor: List[str] # ["Pasko"] (上诉人,裸名不带角色) -
adjudicator: List[str] # ["法院"] (原法院名称) -
crime: List[str] # ["间谍罪"] (原指控) -
time: List[str] # ["上周"] (确切时间短语) -
place: List[str] # ["马来西亚"] (法院描述中的国家) -
E. 2 o1 生成的最佳任务指令和事件指南示例
# 这是一个事件提取任务,目标是从文本中提取结构化事件,遵循 Python 中定义的结构化事件定义。结构化事件包含:
# (1) 事件触发词(提及)——始终使用最简短的词汇跨度(例如,“appeal”而非“filed an appeal”),
# (2) 事件类型,以及
# (3) 参与事件的参数及其角色。
# 尽量减少参数引用,删除冠词、所属代词或描述性词语,除非它们是关键标识符(例如,“the 零售商” → “零售商”,“我的叔叔” → “叔叔”)。
# 重要指南以应对先前错误:
# 1. 对于每个事件触发词,使用最相关的单个词(例如,“bankruptcy”而非“file for bankruptcy”)。
# 2. 对于参数角色,也使用最短跨度(例如,“soldier”而非“a soldier”,“woman”而非“a woman”)。
# 3. 对于每个不同的触发词或暗示事件输出单独事件(例如,定罪和随后的判刑应为两个事件)。
# 4. 对于司法事件(Sue, Appeal, Convict, SentenceAct 等):
# - “defendant”是被控或被判有罪的当事人或实体。
# - “plaintiff” 或 “prosecutor” 是发起法律诉讼或提出上诉的当事人。如果文本未明确指出谁被控告,保持“defendant”为空。
# - 如果文本提到惩罚或判刑(例如,“面临死刑”),包括一个单独的 SentenceAct 事件,引用相同的“defendant”。
# 5. 对于金钱转移,注意直接或间接提及捐款、资助或贡献,并将其标记为 TransferMoney 事件。
# 6. 不要跳过由同义词或间接措辞暗示的事件(例如,“shutting down” → EndOrg, “emerged from bankruptcy” → DeclareBankruptcy)。
# 7. 如果一段文本中有多个事件,分别输出每个事件。
# 8. 始终严格按照以下 Python 列表格式输出:
result = [
EventName("mention" = "trigger", "role1" = [...], "role2" =
[...], ...),
# EventName("mention" = "trigger", "role1" = [...], "role2" =
[...], ...),
# ]
# 9. 除上述可解析的 Python 结构化格式外,不要输出任何其他内容(无多余文本或解释)。
# 事件类定义保持不变,但请参考以下细化的文档字符串以获取使用示例、最短跨度和角色澄清。
# 这里是事件定义:
class Convict(JusticeEvent):
***
当 Try 事件以成功起诉被告结束时发生 Convict 事件。
换句话说,当某个实体被发现犯有某种罪行时,该 Person、Organization 或 GPE 实体就被判定有罪。
细化指南:
- mention: 使用最简短的触发词表示定罪(例如,“guilty”, “convicted”)。
- - defendant: 被判定有罪的实体/ies。删除冠词或所属关系(“the man” → “man”)。
- - adjudicator: 发出有罪判决的法院或法官,如果有明确说明。
- - crime: 被告被判定有罪的不当行为(例如,“murdering X”)。
- - time: 任何明确的时间参考(例如,“last week”)。
- - place: 任何明确的位置参考(例如,“in Boston”)。
- ```
- ```
- 要做什么:
- - 如果提到“crime”,请包含它:例如,“被判谋杀其妻” → crime=["谋杀其妻"]。
- - 保持被告参数最简:“Scott Peterson” → ["Scott Peterson"],而非 ["Mr. Scott Peterson"]。
- 不要做什么:
- - 如果未明确提及犯罪,不要猜测或推断。
- - 不要添加冠词或描述性词语(例如,“the 被告” → "被告" 如果是一般用法)。
- 示例:
- 文本:"John 被发现犯有欺诈罪。"
- →Convict(mention='guilty', defendant=['John'], crime=['fraud'],
- time=[], place=[])
- """
- mention: str # 最简短词表示定罪事件
- defendant: List[str] # 谁被判定有罪
- adjudicator: List[str] # 如果提到,则为发出有罪判决的法官或法院
- crime: List[str] # 被告被判定有罪的不当行为
- time: List[str] # 定罪发生的时间
- place: List[str] # 定罪发生的地点
- class TransferMoney(TransactionEvent):
- """
- TransferMoney 事件指的是给予、接收、借贷或借款金钱的行为
- 当不购买商品或服务作为回报时。
- 细化指南:
- - mention: 单词触发转移事件(例如,“donated”,“loaned”)。
- - giver: 提供资金的代理。删除限定词(“the”,“a”)除非是名称的一部分。
- - recipient: 接收资金的代理。
- - beneficiary: 如果不同于接收者,则为额外受益的代理。
- - money: 资金金额(如果有提及如 "$3,000","large sum")。
- - time: 事件发生的时间(例如,“today”,“last year”)。
- - place: 交易或转移发生的位置。
- 要做什么:
- - 如果暗示资金,请标记无形参考(例如,“contributed”,“had contributors”)为 TransferMoney。
- - 所有资金角色均使用最简参考。
- 不要做什么:
- - 不要将无形帮助(例如,“情感支持”)标记为 TransferMoney。
- - 避免在代理跨度中列出不定冠词或多余的描述词。
- 示例:
- 文本:"He donated $5,000 to Red Cross last week."
- → TransferMoney(mention='donated', giver=['He'], recipient=['Red
- Cross'], money=['$5,000'], time=['last week'], place=[])
- """
- mention: str # 最简短词触发金钱转移
- giver: List[str] # 谁提供金钱
- recipient: List[str] # 谁接收金钱
- beneficiary: List[str] # 谁额外受益,如果有
- money: List[str] # 金额总数
- ```
- ```
- time: List[str] # 转移发生的时间
- place: List[str] # 转移事件发生的地点
- class Meet(ContactEvent):
- ***
- 当两个或更多实体在同一地点面对面聚集并相互互动时发生 Meet 事件。
- 细化指南:
- - mention: 最佳单词表示会议(例如,“met”,“summit”,“conference”)。
- - entity: 所有参与者,去掉冠词或描述词。如果有多个,请全部列出。
- - time: 任何提及事件发生时间的时间短语。
- - place: 会议地点。
- 要做什么:
- - 使用面对面聚会的触发词(例如,“met”,“conference”,“summit”)。
- - 保持参与者引用简洁:“President”,“Vice-President” 而不是 “the US President”。
- 不要做什么:
- - 不要将电话通话或书面通信视为 Meet(使用 PhoneWrite)。
- 示例:
- 文本:"昨天领导人们在巴黎会面。"
- → Meet(mention='met', entity=['leaders'], time=['yesterday'], place=['Paris'])
- ***
- mention: str # 最简短词或短语表示会议
- entity: List[str] # 谁面对面会面
- time: List[str] # 会议发生的时间
- place: List[str] # 会议发生的地点
- class PhoneWrite(ContactEvent):
- ***
- 当两个或多个人通过非面对面方式交流时发生 PhoneWrite 事件。这包括电话通话、电子邮件、短信等。
- 细化指南:
- - mention: 最简短的交流表达(例如,“called”,“emailed”,“texted”)。
- - entity: 进行交流的代理。去掉冠词、限定词或多余的描述词。
- - time: 交流发生的时间(例如,“this morning”,“yesterday”)。
- 要做什么:
- - 常见触发词:“phoned”,“emailed”,“talked by phone”,“texted”,“messaged”。
- - 保持角色最简(例如 entity=['John', 'Mary'])。
- 不要做什么:
- - 不要将面对面讨论标记为 PhoneWrite(使用 Meet)。
- 示例:
- 文本:"They emailed each other last night."
- → PhoneWrite(mention='emailed', entity=['They'], time=['last night']
- ')
- ```
- ```
- """
- mention: str # 最简短词表示交流
- entity: List[str] # 交流双方
- time: List[str] # 交流发生的时间
- class DeclareBankruptcy(BusinessEvent):
- ***
- 当实体因严重财政困境正式寻求债务保护时发生 DeclareBankruptcy 事件。
- 细化指南:
- - mention: 与破产相关的简短触发词(例如,“bankruptcy”,“filed”,“declared”)。
- - org: 宣布破产的组织或个人。删除 “the”,“my” 等。
- - time: 破产声明发生的时间(例如,“in 2003”,“today”)。
- - place: 如果提到,则为声明发生的地点(例如,“in court”,“in New York”)。
- 要做什么:
- - 认识同义词或间接引用如 “emerged from bankruptcy” 或 “bankruptcy protection” 作为触发词。
- 不要做什么:
- - 如果未明确说明,不要猜测组织。
- 示例:
- 文本:"My uncle declared bankruptcy in 2003."
- → DeclareBankruptcy(mention='bankruptcy', org=['uncle'], time
- =['2003'], place=[])
- """
- mention: str # 破产的最简短表达
- org: List[str] # 宣布破产的当事方
- time: List[str] # 声明发生的时间
- place: List[str] # 声明发生的地点
- class EndOrg(BusinessEvent):
- """
- 当一个组织停止存在或“退出业务”时发生 EndOrg 事件。
- 细化指南:
- - mention: 最小触发词(例如,“shutting down”,“closing”)。
- - org: 结束的组织或分支机构。例如,“plant”,“branch”。
- - time: 明确陈述的关闭或结束时间。
- - place: 如果提到,组织所在的地点或结束地点。
- 要做什么:
- - 考虑类似“closing its plant”的引用 → “plant” 在 org 中。
- - 识别同义词如“shutting down”,“ceasing operations”。
- 不要做什么:
- - 如果文本明确说明组织结束,不要忽略它。
- 示例:
- 文本:"惠普将在尤金关闭其工厂。"
- → EndOrg(mention='shutting down', org=['plant'], time=[], place=['
- 尤金'])
- """
- mention: str # 组织结束的最简短表达
- org: List[str] # 结束的组织
- ```
- ```
- time: List[str] # 结束发生的时间
- place: List[str] # 事件发生的地点
- class Die(LifeEvent):
- ***
- 当一个人失去生命时发生 Die 事件,无论是意外、故意还是自残。
- 细化指南:
- * mention: 引用死亡的简短触发词(例如,“killed”,“died”,“murdered”)。
- * agent: 如果确定的话,杀手或原因(例如,“gunman”,“regime”)- 删除冠词。
- * victim: 谁死了,再次保持最简引用(例如,“soldier” 而不是 “a soldier”)。
- * instrument: 如果有的话,使用的装置或方法(例如,“gun”,“bomb”)。
- * time: 死亡发生的时间。
- * place: 死亡发生的地点。
- 要做什么:
- - 对文本中的每个死亡触发词创建单独的 Die 事件。
- - 如果文本引用谋杀:agent 是杀手,victim 是死者。
- 不要做什么:
- - 如果多个受害者出现在单独的触发词中,不要将它们合并成一个字符串。
- 示例:
- 文本:"他在伊拉克杀死了士兵。"
- → Die(mention='killed', agent=['He'], victim=['soldier'],
- instrument=[], time=[], place=['Iraq'])
- ***
- mention: str # 最简短词引用死亡
- agent: List[str] # 可选杀手或原因
- victim: List[str] # 谁死了
- instrument: List[str] # 如何被杀害(武器等)
- time: List[str] # 死亡发生的时间
- place: List[str] # 死亡发生的地点
- class SentenceAct(JusticeEvent):
- ***
- 每当对被告发出惩罚时发生 SentenceAct 事件,
- 例如,监禁或另一项法律处罚。
- 细化指南:
- * mention: 引用判刑或惩罚的触发词(例如,“sentenced”,“faces [penalty]”)。
- * defendant: 如果已知,相同的被判有罪或发现有罪的一方。
- * adjudicator: 如果提到,发出判决的实体(例如,“judge”,“court”)。
- * crime: 被告被判刑的不当行为(例如,“murder”,“embezzlement”)。
- * sentence: 具体的惩罚(例如,“death penalty”,“life in prison”)。
- * time: 判刑发生的时间。
- * place: 判刑发生的地点。
- 要做什么:
- ```
- ```
- - 查找诸如 "faces the death penalty," "was sentenced to ten years." 的词语。
- 不要做什么:
- - 如果有明确提到惩罚,不要省略 SentenceAct。
- 示例:
- 文本:"He now faces the death penalty for murdering his wife."
- → SentenceAct(mention='faces', defendant=['He'], crime=['murdering
- his wife'], sentence=['death penalty'], time=[], place=[])
- """
- mention: str # 最简短词表示判刑事件
- defendant: List[str] # 谁被判处
- adjudicator: List[str] # 法官或法院
- crime: List[str] # 不当行为或犯罪
- sentence: List[str] # 惩罚
- time: List[str] # 判刑发生的时间
- place: List[str] # 判刑发生的地点
- class Sue(JusticeEvent):
- ***
- 当法院程序启动以确定某人的责任时发生 Sue 事件,
- 涉及人员、组织或地理政治实体。
- 细化指南:
- - mention: 最小触发词(例如,“sued”,“suing”,“filed a lawsuit”,“suit”)。
- - plaintiff: 提起诉讼的一方。删除任何冠词或形容词。
- - defendant: 被起诉的一方。同样,保持引用最简。
- - adjudicator: 如果明确命名,则为法官或法院。
- - crime: 如果提到不当行为(例如,“for fraud”,“for breach of contract”)。
- - time: 诉讼提起或提及的时间。
- - place: 诉讼发生的地方。
- 要做什么:
- - 将提起诉讼的一方标记为 "plaintiff"。
- 不要做什么:
- - 如果文本明确说明谁起诉谁,不要混淆 "plaintiff" 与 "defendant"。
- 示例:
- 文本:"一名护士起诉 Dell 诱购行为。"
- → Sue(mention='sued', plaintiff=['nurse'], defendant=['Dell'],
- crime=['诱购行为'], time=[], place=[])
- """
- mention: str # 最简短词表示诉讼事件
- plaintiff: List[str] # 谁提起诉讼
- defendant: List[str] # 谁被起诉
- adjudicator: List[str] # 法官或法院,如果提到
- crime: List[str] # 提起诉讼的不当行为
- time: List[str] # 诉讼发生的时间
- place: List[str] # 诉讼发生的地方
- class Appeal(JusticeEvent):
- ***
- 当法院判决被提交至更高级别法院进行审查时发生 Appeal 事件。
- ```
- ```
- 细化指南:
- - mention: 上诉的简短触发词(例如,“appeal”,“appealed”)。
- - defendant: 如果文本提到,则为被控或被判有罪的一方。
- - prosecutor: 提起上诉的一方(即上诉人)。这可能是之前审判中的被告但现在正在上诉的同一人。
- - adjudicator: 如果给定,则为处理上诉的更高级别法院或法官。
- - crime: 如果提到,则为上诉所涉及的不当行为。
- - time: 上诉提起或审理的时间。
- - place: 上诉发生的地方。
- 要做什么:
- - 如果文本说有人“提起上诉”,如果没有其他角色指定,则该实体为“prosecutor”。
- - 如果文本未识别被控方,保持 defendant=[]。
- 不要做什么:
- - 如果不清楚谁被控,不要自动填写“defendant”。
- 示例:
- 文本:"He appealed the verdict last week."
- → Appeal(mention='appealed', defendant=[], prosecutor=['He'], crime
- =[], time=['last week'], place=[])
- """
- mention: str # 最简短词表示上诉事件
- defendant: List[str] # 被告,如果提到
- prosecutor: List[str] # 提起上诉的一方
- adjudicator: List[str] # 处理上诉的法官或法院
- crime: List[str] # 上诉所涉及的不当行为
- time: List[str] # 上诉发生的时间
- place: List[str] # 上诉审理的地方
- ```
# E. 3 GPT-4.5 生成的任务指令和最佳事件指南示例
这是一个事件提取任务,使用 Python 定义的事件类从文本中识别和结构化事件。每个结构化事件由一个事件触发词、事件类型、参与事件的参数及其角色组成。您的目标是以 Python 事件列表的形式输出这些信息,确保它是 Python 可解析的,并严格遵循下面提供的事件定义。
指令:
- 跨度提取:
-
- 提取精确且简洁的提及和参数的跨度,清晰传达事件或参数角色,无需不必要的上下文。 -
- 对于涉及标题或细节的提取,使用通用术语,除非细节对事件的完整性至关重要。 -
- 在事件中识别实体角色时,优先考虑核心标识符而非伴随描述符。 -
- 角色识别:
-
- 使用上下文线索准确识别角色,有效解决歧义,同时优先考虑明确的跨度。如果角色未提及,保持为空。 -
- 保持一致性,特别是像原告 vs. 被告这样的区别,基于上下文证据。 -
-
-
- 在复杂交易中澄清角色,例如区分受益人和直接接收人。
-
- 输出格式;
-
- 请严格遵循 Python 格式 EventName("mention" = "trigger", "role1" = [...], "role2" = [...], ...)。 -
- 确保输出格式一致,符合 Python 兼容性,严格遵守事件定义。 -
- 用空列表表示未提及的参与者,而不是假设或占位符。 -
- 澄清和例外;
-
- 明确注明角色根据角色定义的例外情况。 -
- 通过特定指南管理重叠角色,确保跨度清晰和精确,避免遗漏任何关键细节 - 以下是结构化的事件定义:
-
这里是事件定义:
- class Convict(JusticeEvent):
-
成功起诉被告时发生 Convict 事件。 -
这涉及到一个人、组织或地理政治实体(GPE)因犯罪而被定罪。 -
""" -
mention: str # 专注于简洁的触发词,如 "convicted" 或 "conviction",避免过多修饰。 -
defendant: List[str] # 被定罪的个人或实体的名字。使用直接标识符,示例:"John Doe"。 -
adjudicator: List[str] # 引用司法实体,示例:"court" 或 "judge",除非细节至关重要。 -
crime: List[str] # 提供犯罪的简短、精确描述,例如:"fraud"。 -
time: List[str] # 如果提及,指定确切时间,例如:"Monday"。 -
place: List[str] # 如果明确提及,记录地点,避免假设。 - class TransferMoney(TransactionEvent):
-
""" -
不涉及购买商品或服务的金钱转移,涉及给予者和接收者角色, -
交易更为间接或复杂。 -
""" -
mention: str # 使用明确的术语如 "donated",保持简洁。 -
giver: List[str] # 识别资金来源,示例:"Sheila C. Johnson"。 -
recipient: List[str] # 明确命名接收实体。 -
beneficiary: List[str] # 清晰注明额外受益人。 -
money: List[str] # 使用确切金额,避免模糊数额。 -
time: List[str] # 如果明确指定,定义发生时间。 -
place: List[str] # 如果详细提及,标注交易地点。 - class Meet(ContactEvent):
-
-
-
""" -
实体面对面聚集的事件,例如会议、峰会或会议。 -
""" -
mention: str # 中心会议参考,如 "summit",无需多余细节。 -
entity: List[str] # 清楚列出参与者,省略多余的描述。 -
time: List[str] # 如果明确提供,指定时间。 -
place: List[str] # 如果可用,标注地点,避免无根据假设。 - class PhoneWrite(ContactEvent):
-
""" -
非面对面通信,涵盖书面和电话交互。 -
""" -
mention: str # 表示通信的术语,例如 "called",简洁明了。 -
entity: List[str] # 捕捉通信中的参与者。 -
time: List[str] # 如果提及,确保清晰指定时间。 - class DeclareBankruptcy(BusinessEvent):
-
""" -
当组织请求法律保护以防止债务收集时发生。 -
""" -
mention: str # 使用诸如 "bankruptcy" 的声明,清楚明了。 -
org: List[str] # 关注问题中的组织名称。 -
time: List[str] # 如果明确陈述,提及声明发生的时间。 -
place: List[str] # 如果明确说明,记录声明发生的地点。 - class EndOrg(BusinessEvent):
-
""" -
组织停止运营,完全退出业务。 -
""" -
mention: str # 使用诸如 "shut down" 的术语,有效捕捉本质。 -
org: List[str] # 简洁列出停止运营的组织。 -
time: List[str] # 如果提供具体信息,明确提及时间。 -
place: List[str] # 如果明确说明,提及地点详情。 - class Die(LifeEvent):
-
""" -
标志生命结束的事件,涵盖直接、意外和自残情况。 -
""" -
mention: str # 特定术语如 "died",排除多余上下文。 -
agent: List[str] # 如果指出,引用任何负责方。 -
victim: List[str] # 准确识别死者,不带头衔。 -
instrument: List[str] # 如果描述,指定使用的工具。 -
time: List[str] # 如果提供,使用准确时间。 -
place: List[str] # 如果明确指出,提及地点。 - class SentenceAct(JusticeEvent):
-
""" -
法律判决发布,通常涉及监禁。 -
""" -
mention: str # 直接词汇如 "sentenced",保持清晰。 -
defendant: List[str] # 简洁识别被判刑的一方。 -
adjudicator: List[str] # 说明发布判决的权威机构。 -
crime: List[str] # 精确包括提及的犯罪。 -
sentence: List[str] # 清晰概述涉及的惩罚。 -
-
-
time: List[str] # 如果明确声明,指定具体时间。 -
place: List[str] # 如果提供,引用地点详情。 - class Sue(JusticeEvent):
-
""" - 启动针对实体的法律程序以确定责任。
-
""" -
mention: str # 特定术语如 "sued"。 -
plaintiff: List[str] # 清晰识别起诉方。 -
defendant: List[str] # 明确识别被诉实体。 -
adjudicator: List[str] # 如果表达,指定司法角色。 -
crime: List[str] # 如果指定,突出指控犯罪。 -
time: List[str] # 如果详细提及,引用具体时间。 -
place: List[str] # 如果明确说明,提取地点详情。 - class Appeal(JusticeEvent):
-
表示决策移至更高级别法院进行进一步审查。 -
""" -
mention: str # 直接使用诸如 "appealed" 的术语。 -
defendant: List[str] # 命名受审实体。 -
prosecutor: List[str] # 命名提起上诉的一方。 -
adjudicator: List[str] # 引用审查法院。 -
crime: List[str] # 如果提及,清晰详述犯罪。 -
time: List[str] # 如果明确,捕捉提交时间。 -
place: List[str] # 如果详细说明,提及上诉地点。 -
参考论文:https://arxiv.org/pdf/2504.07357

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 7
7 0
0- 0



 已为社区贡献79条内容
已为社区贡献79条内容

所有评论(0)