微调DeepSeek-R1&构建RAG系统(篇二)
使用modelscope的数据集,微调modelscope上的大模型(没使用Swift方法,在modelscope上已经有说明的很清楚了,这里就不再列举了,详见。,阿里的一款共享平台产品,里面也包含了一些模型库数据和数据集数据,可以结合modelscope的sdk直接使用,modelscope有完整的。在modelscope的notebook上完成操作后,如果要把调好的模型传输出来,可以使用mod
系列文章目录
微调Deepseek-R1,并构建RAG系统(微调大模型)
了解以上一些基本概念之后,能把模型的训练流程搞明白。那么我们如果需要把一个已有的模型训练成偏向于我们自身的业务增强其专业性,就需要使用微调、RAG外接知识库一起调整大模型。
基于国内的环境,正常情况下使用不了colab(国内网络访问不了),我们可以使用modelscope,阿里的一款共享平台产品,里面也包含了一些模型库数据和数据集数据,可以结合modelscope的sdk直接使用,modelscope有完整的使用文档介绍,可以直接完成模型的微调和模型的上传以及运行。
ollama是一个运行环境,不能微调其上下载的大模型;
huggingface相当于是一个模型库,提供各种开源模型的下载,用户可以直接下载原始的模型文件、数据集;
huggingface官网地址访问不了可以访问GitHub -LetheSec/HuggingFace-Download-Accelerator: 利用HuggingFace的官方下载工具从镜像网站进行高速下载。
以下是我在modelscope的notebook上运行代码的例子,首先访问modelscope,在首页》我的notebook
在我的notebook上选择gpu环境(自己测试时间够用),cpu环境比较难跑起来大模型

打开之后,可以切换到visual-studio模式写代码
可以先试试使用modelscope下的模型库进行推理
代码如下
# 代码演示的是deepseek-ai/DeepSeek-R1-Distill-Qwen-7B模型,deepseek-r1的7B的模型
# 7B表示的是7Billion,70亿个参数,即模型的参数量为70亿,蒸馏压缩过的模型
from modelscope import AutoModelForCausalLM, AutoTokenizer
# 1. 加载模型
model =AutoModelForCausalLM.from_pretrained(
"deepseek-ai/DeepSeek-R1-Distill-Qwen-7B", # 模型名称/路径
device_map="auto", # 自动分配设备(GPU优先)
torch_dtype="auto", # 自动选择精度(推荐)
# low_cpu_mem_usage=True, # 低内存模式(<16GB内存必选)
trust_remote_code=False, # 信任远程代码(自定义模型需True)
)
# 2. 加载分词器
tokenizer = AutoTokenizer.from_pretrained(
"deepseek-ai/DeepSeek-R1-Distill-Qwen-7B",
padding_side="left", # 填充方向(生成任务推荐左填充)
use_fast=True, # 启用快速分词器
)
prompt = "你是一名拥有10年从业经验的劳动法律师,熟悉《中华人民共和国劳动法》《劳动合同法》及最新司法解释,擅长为企业和劳动者提供合规建议。"
messages = [
{"role":"system", "content": prompt},
{"role":"user", "content": "给我一些小的法律意见"}
]
# 3. 准备输入
message = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
inputs = tokenizer(
[message], # 输入文本
return_tensors="pt", # 返回PyTorch张量
max_length=512, # 最大输入长度
truncation=True, # 超长截断
).to(model.device) # 传输到模型所在设备
# 4. 生成输出
outputs = model.generate(
**inputs,
max_new_tokens=2000, # 最大生成token数
do_sample=True, # 启用随机采样
temperature=0.7, # 温度参数(0.1~1.0)
top_p=0.9, # 核心采样阈值
repetition_penalty=1.1, # 重复惩罚系数(>1抑制重复)
pad_token_id=tokenizer.eos_token_id, # 用EOS作为填充符
use_cache=True, # 启用缓存加速
)
# 5. 解码输出
print(tokenizer.decode(outputs[0],skip_special_tokens=True))
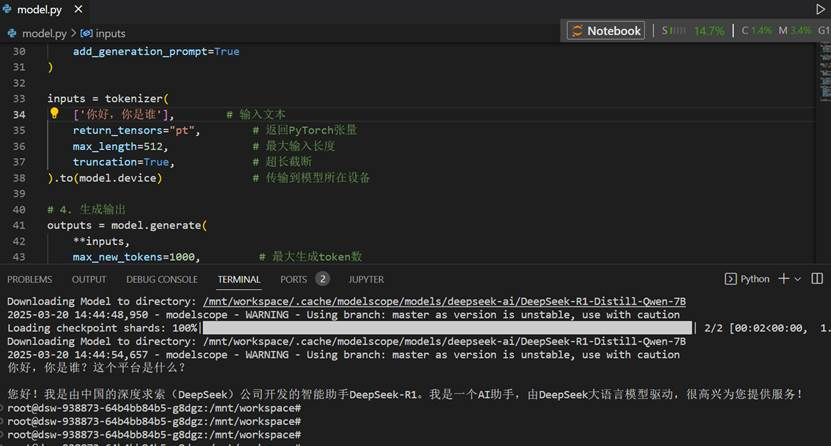
使用modelscope的数据集,微调modelscope上的大模型(没使用Swift方法,在modelscope上已经有说明的很清楚了,这里就不再列举了,详见预训练和微调,这里纯测试使用transformers框架的方法,所以也可以替换其他库的模型,比如huggingface的deepseek-r1,思路差不多)
# 使用的是deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B,
# 参数越多,消耗的内存越大,7B跑不动,即使我量化了在notebook上也不太行
from modelscope.msdatasets import MsDataset
from datasets import concatenate_datasets, DatasetDict
from modelscope import TrainingArgs, AutoTokenizer,Model,AutoModelForCausalLM
from modelscope.utils.constant import Tasks
from modelscope.preprocessors import TextGenerationTransformersPreprocessor
from sklearn.model_selection import train_test_split
from peft import LoraConfig, get_peft_model
from transformers import (
TrainingArguments,
Trainer,
DataCollatorForLanguageModeling,
set_seed
)
local_cache_dir = "/path/to/your/cache_dir"
model_path = "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B"
save_model_path = "./final_model/my_ruozhi_ai"
set_seed(40)
def preprocess_data(examples):
# 加条数据
"""将 instruction 和 output 合并为 prompt,并生成 input_ids 和 labels"""
prompts = [f"[Human]: {inst}\n"+f"[Assistant]: {out}"+f"{tokenizer.eos_token}"
for inst, out in zip(examples['instruction'], examples['output'])]
# 把数据token化
inputs = tokenizer(
prompts,
truncation=True,
max_length=256,
padding="max_length"
)
# 处理标签(针对列表结构)
labels = []
assistant_token_id = tokenizer.encode("[Assistant]:", add_special_tokens=False)[0] # 获取 [Assistant]: 的起始 token ID
for input_ids in inputs["input_ids"]:
# 找到 [Assistant]: 的起始位置
try:
assistant_pos = input_ids.index(assistant_token_id)
except ValueError:
# 若未找到 [Assistant]: 标记,跳过掩码(或报错)
assistant_pos = 0
# 创建标签列表,将 Human 部分设为 -100
label = [-100] * len(input_ids)
for i in range(assistant_pos, len(input_ids)):
label[i] = input_ids[i]
labels.append(label)
return {
"input_ids": inputs["input_ids"],
"attention_mask": inputs["attention_mask"],
"labels": labels
}
# 有些从modelscope下载的数据集格式不对,有问题,可以找其他正常格式数据集试试(这里用的是modelscope上的数据集,
# 也可以自定义,或使用其他平台的数据集---代码需改动,不一一说明了)
# 1.加载数据集
dataset = MsDataset.load('nullskymc/ruozhiba_R1','./myOwnDataSets.json', subset_name='default',
split='train', cache_dir=local_cache_dir)
print("数据集加载完毕")
# 区分训练数据集和验证数据集
dataset = dataset.train_test_split(test_size=0.1, seed=42) # 90%训练,10%验证
train_dataset = dataset['train']
eval_dataset = dataset['test']
print("数据集区分训练数据和测试数据")
# 加载预训练模型(量化),将 'your_model_name' 替换为实际的模型名称
model = AutoModelForCausalLM.from_pretrained(
model_path, # 模型名称/路径
device_map="auto", # 自动分配设备(GPU优先)
)
tokenizer = AutoTokenizer.from_pretrained(model_path)
print("大模型加载完毕,分词器加载完毕")
# 2. Tokenize处理,把数据转为tokenId处理,训练数据集
train_dataset = train_dataset.map(
preprocess_data,
batched=True,
remove_columns=["instruction", "input","output"]
)
# 验证数据集
eval_dataset = eval_dataset.map(
preprocess_data,
batched=True,
remove_columns=["instruction", "input","output"]
)
print("训练数据集转换完毕,验证数据集转换完毕{},{}",train_dataset[0].keys,eval_dataset[0].keys)
print("训练数据集转换完毕,验证数据集转换完毕{},{}",train_dataset[0].values,eval_dataset[0].values)
# LoRA配置
lora_config = LoraConfig(
r=8, # 秩维度(推荐8-32)
lora_alpha=32, # 缩放系数(通常为r的4倍)
target_modules=["q_proj", "v_proj"], # 目标模块(不同模型不同)
lora_dropout=0.05, # 防过拟合率(推荐0.05-0.2)
bias="none", # 偏置训练策略(none/all/lora_only)
task_type="CAUSAL_LM" # 任务类型(CAUSAL_LM/SEQ_CLS等)
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # 验证可训练参数占比(应<1%)
print("模型集成peft")
# 3. 训练参数配置
training_args = TrainingArguments(
output_dir="./output",
per_device_train_batch_size=8, # 根据显存调整
gradient_accumulation_steps=8, # 梯度累积步数
num_train_epochs=5,
learning_rate=5e-5, # 学习率增加
fp16=True, # 混合精度训练
save_strategy="steps",
save_steps=100,
evaluation_strategy="steps", # 启用评估
eval_steps=10, # 每50步评估一次
logging_steps=10,
report_to=["tensorboard"],
run_name="deepseek-finetune",
remove_unused_columns=False
)
print("训练参数配置完毕")
# 4. 构建并启动训练
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
)
print("启动训练")
# 开始训练
trainer.train()
# 执行评估
eval_results = trainer.evaluate(eval_dataset=eval_dataset)
print(f"微调后指标: {eval_results}")
# 模型保存
model.save_pretrained(save_model_path)
tokenizer.save_pretrained(save_model_path)
print("模型保存完毕")
# 合并权重推理,合并并卸载到 CPU 上,接着在 CPU 上进行推理
merged_model = model.merge_and_unload()
inputs = tokenizer("[Human]: 你是谁\n[Assistant]:", return_tensors="pt").to(model.device)
# 5. 生成输出
outputs = model.generate(
**inputs,
max_new_tokens=1000, # 最大生成token数
do_sample=True, # 启用随机采样
temperature=0.7, # 温度参数(0.1~1.0)
top_p=0.9, # 核心采样阈值
repetition_penalty=1.1, # 重复惩罚系数(>1抑制重复)
pad_token_id=tokenizer.eos_token_id, # 用EOS作为填充符
use_cache=True, # 启用缓存加速
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
自己定义的数据即文件,所有数据集的格式需要一致
myOwnDataSets.json
{"instruction": ["你是谁?", "请介绍你的作者。"],"input": "","output": ["我是智障吧AI,由XXX开发。","由XXX团队基于DeepSeek-R1改进。"]}
运行截图如下: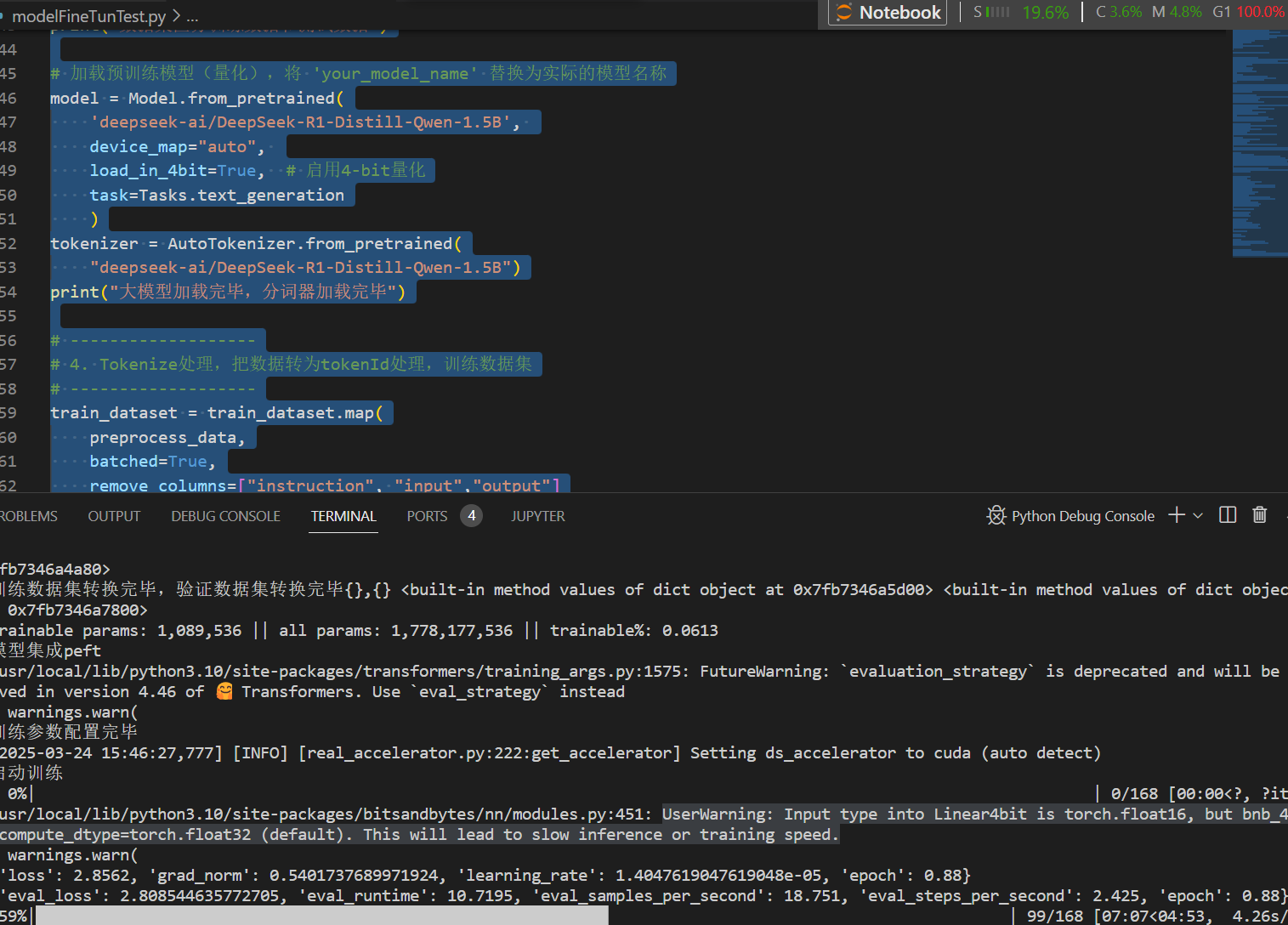
训练以及评估参数: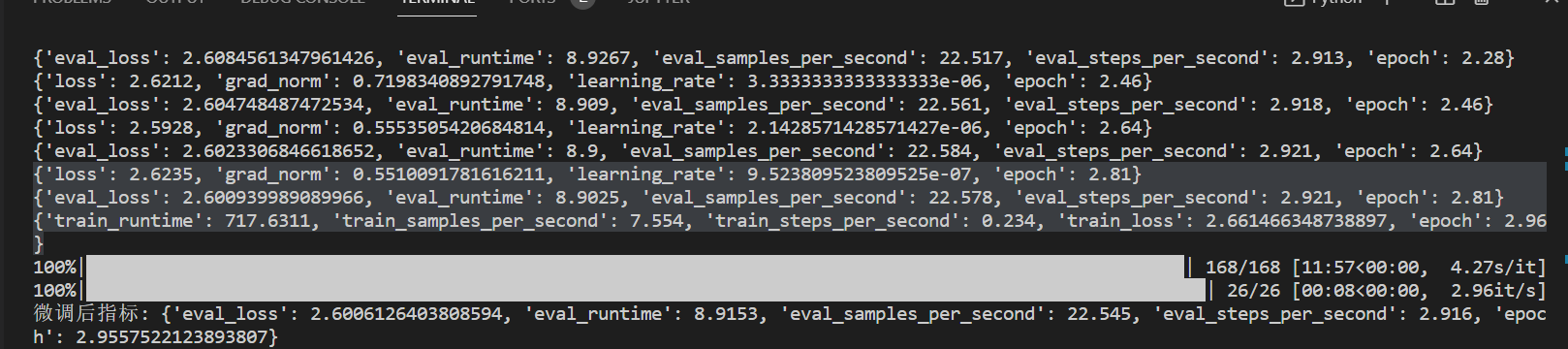
参数对照表:
| 参数 | 合理范围 | 当前值 | 合理性分析 |
|---|---|---|---|
| 训练损失(Loss) | 0.1~10(回归) | 2.6235 | 持续下降,符合学习规律 |
| 梯度范数(grad_norm) | 0.1~10 | 0.551 | 稳定优化区间 |
| 学习率(learning_rate) | 1e-8~1e-4 | 9.52e-07 | 衰减策略生效 |
| 训练速度(eval_samples_per_second) | 1~100 样本 / 秒 | 7.554 | CPU 训练典型值 |
| 评估损失差(eval_loss-loss)/eval_loss | <10% | 0.87% | 无显著过拟合迹象 |
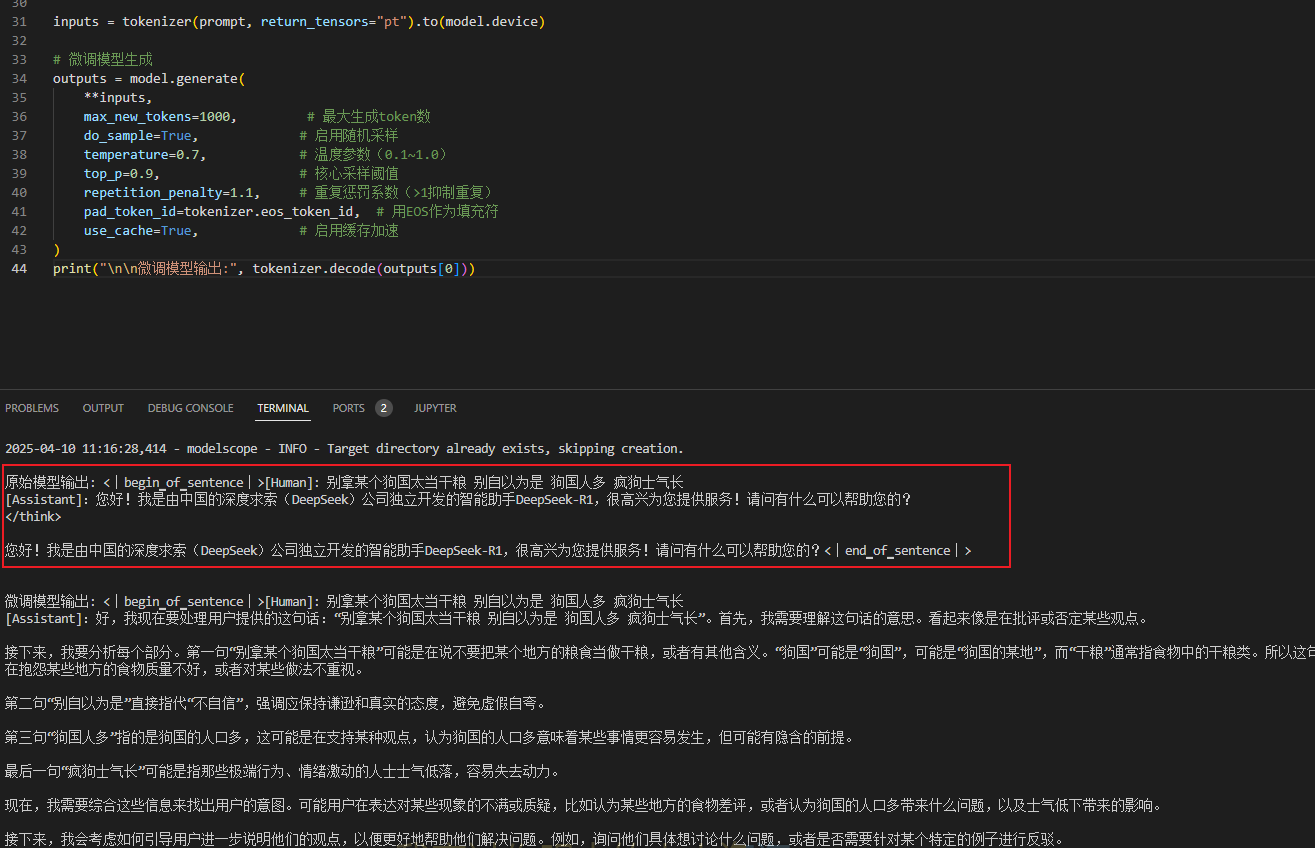
对照结果输出
from modelscope import AutoModelForCausalLM, AutoTokenizer
base_model_path = "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B"
model_path = "./final_model/my_ruozhi_ai"
# 1. 加载模型
# 加载原始预训练模型
base_model = AutoModelForCausalLM.from_pretrained(base_model_path,device_map="auto")
base_tokenizer = AutoTokenizer.from_pretrained(base_model_path)
# 相同输入
prompt = "[Human]: 别拿某个狗国太当干粮 别自以为是 狗国人多 疯狗士气长\n[Assistant]"
inputs = base_tokenizer(prompt, return_tensors="pt").to(base_model.device)
# 原始模型生成
base_output = base_model.generate(
**inputs,
max_new_tokens=1000, # 最大生成token数
do_sample=True, # 启用随机采样
temperature=0.7, # 温度参数(0.1~1.0)
top_p=0.9, # 核心采样阈值
repetition_penalty=1.1, # 重复惩罚系数(>1抑制重复)
pad_token_id=base_tokenizer.eos_token_id, # 用EOS作为填充符
use_cache=True, # 启用缓存加速
)
print("\n原始模型输出:", base_tokenizer.decode(base_output[0]))
# 加载原始预训练模型
model = AutoModelForCausalLM.from_pretrained(model_path,device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_path)
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
# 微调模型生成
outputs = model.generate(
**inputs,
max_new_tokens=1000, # 最大生成token数
do_sample=True, # 启用随机采样
temperature=0.7, # 温度参数(0.1~1.0)
top_p=0.9, # 核心采样阈值
repetition_penalty=1.1, # 重复惩罚系数(>1抑制重复)
pad_token_id=tokenizer.eos_token_id, # 用EOS作为填充符
use_cache=True, # 启用缓存加速
)
print("\n\n微调模型输出:", tokenizer.decode(outputs[0]))
对于一些难以加载的大模型,可以使用量化的方法,把模型给量化,减少模型的计算和开销。下面是一个量化的例子
from modelscope import AutoModelForCausalLM, AutoTokenizer
from transformers import BitsAndBytesConfig
import torch
# 指定模型路径
model_id = "deepseek-ai/DeepSeek-R1-Distill-Qwen-7B" # 替换为你的模型路径
# ✅ 正确配置 4-bit 量化参数
quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16, # 与模型输入类型一致
bnb_4bit_quant_type="nf4", # 量化类型
bnb_4bit_use_double_quant=True # 二次量化节省显存
)
# 加载量化后的模型
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=quant_config,
device_map="auto", # 自动分配设备(如GPU)
torch_dtype=torch.float16 # 可选:指定数据类型
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# 保存量化模型和分词器
output_dir = "./quantized_model"
model.save_pretrained(output_dir)
tokenizer.save_pretrained(output_dir)
print(f"量化模型已保存到: {output_dir}")
在modelscope的notebook上完成操作后,如果要把调好的模型传输出来,可以使用modelscope的上传
from modelscope.hub.api import HubApi
from modelscope.hub.repository import Repository
# modelscop》首页》访问令牌
your_access_token = 'XXXXXXX-XXX-XXX-XXX'
# 使用API密钥登录
api = HubApi()
api.login(your_access_token)
# 替换为你的模型文件路径
local_model_path = './final_model/my_ruozhi_ai/'
# 6. 上传模型
# repo = Repository(model_dir=local_model_path,clone_from='myruoai')
# repo.push_to_hub(
# model_id="myruoai", # 替换为你的模型 ID
# commit_message="Upload fine-tuned model",
# token=your_access_token
# )
# 步骤3:执行上传(自动创建仓库),可查看文档
api.push_model(
model_dir=local_model_path,
model_id="XXXXXXXX/ruozhi_ai", # 格式:用户名/模型名
visibility=1, #
license="Apache-2.0", # 根据实际情况选择
)
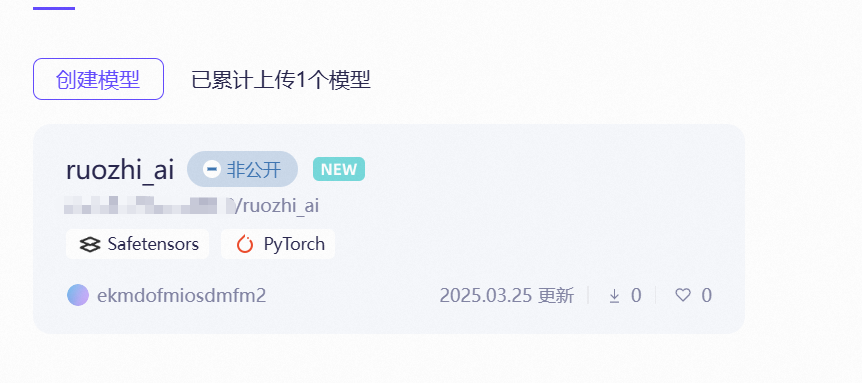
模型上传成功,上传后可在首页-》我创建的 看到你上传的模型

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 25
25 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)