大模型蒸馏-小模型超进化
DeepSeek R1确实是国运级别的科技里程碑,他能有这么大的影响力,震荡美股,引爆硅谷,我觉得有三条原因,首先是它的性能非常的棒,直接对标openAi的o1-mini,截止到2025年三月 DeepSeek R1在司南openCompass大模型综合排行榜是冠军,超过了国内外历史上所有的大模型。第三就是本地部署,既然模型开源,那么任何人都可以下载放到自己公司的服务器,甚至电脑手机这些边缘终端上
- 👏作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家
- 📕系列专栏:Spring原理、JUC原理、Kafka原理、分布式技术原理、数据库技术、JVM原理、AI应用
- 🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦
- 🍂博主正在努力完成2025计划中:逆水行舟,不进则退
- 📝联系方式:nhs19990716,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬👀
文章目录
蒸馏DeepSeek R1满血大模型,获得一个在数学领域能够平替媲美R1的小模型,这个小模型具备R1同款的慢思考推理能力,而且价格成本极低,推理速度极快,本地部署极方便。
也可以照着这篇文章的样板,制作你自己的行业蒸馏数据集,蒸馏出你自己的行业小模型,站在DeepSeek R1巨人的肩膀上,完成我们自己的创新。
DeepSeek R1确实是国运级别的科技里程碑,他能有这么大的影响力,震荡美股,引爆硅谷,我觉得有三条原因,首先是它的性能非常的棒,直接对标openAi的o1-mini,截止到2025年三月 DeepSeek R1在司南openCompass大模型综合排行榜是冠军,超过了国内外历史上所有的大模型。
第二就是开源,开源决定了行业的下限,而基座模型的能力决定了应用的上限,DeepSeek在垫高地板的同时,又捅破了天花板。
第三就是本地部署,既然模型开源,那么任何人都可以下载放到自己公司的服务器,甚至电脑手机这些边缘终端上运行,没有延迟卡顿,没有推理成本,没有隐私外泄,完全自主可控,随意微调蒸馏。
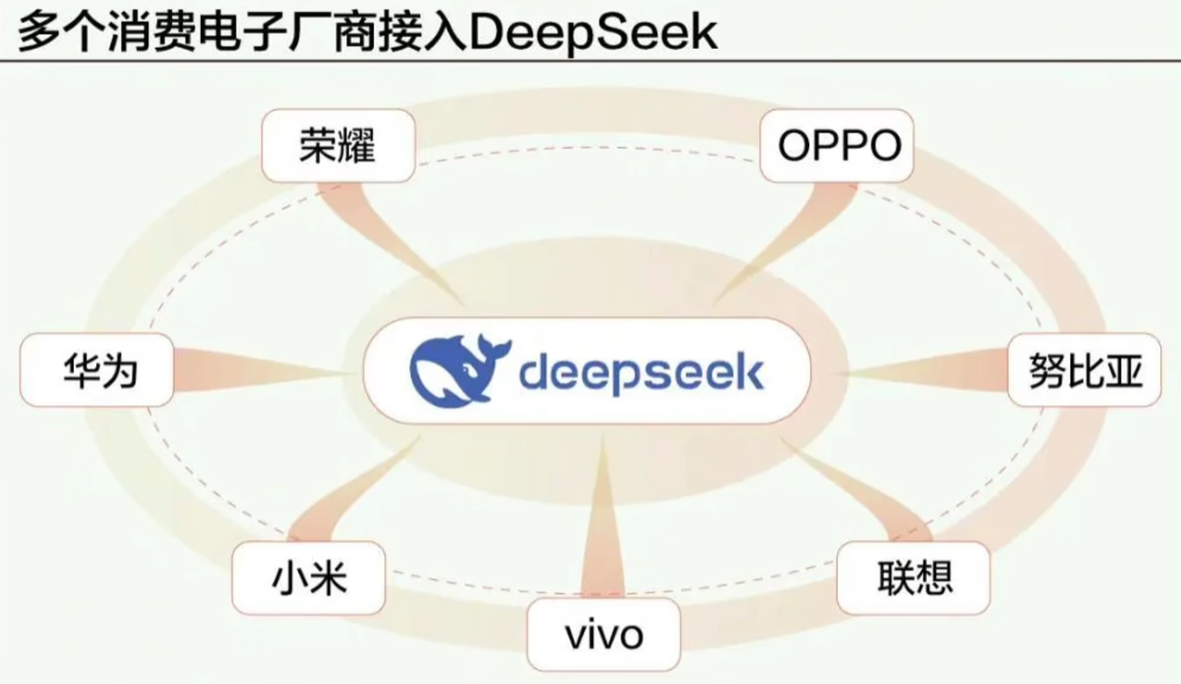
所以现在从过国企央企到中小企业,各种大厂的APP都在大力接入 和 本地部署DeepSeek R1。
为了方便大家本地部署呢,DeepSeek官方也开源了六个小尺寸的蒸馏模型,让R1作为老师把能力和知识教给小模型,最小的一个版本1.5B都能直接塞到手机上了。
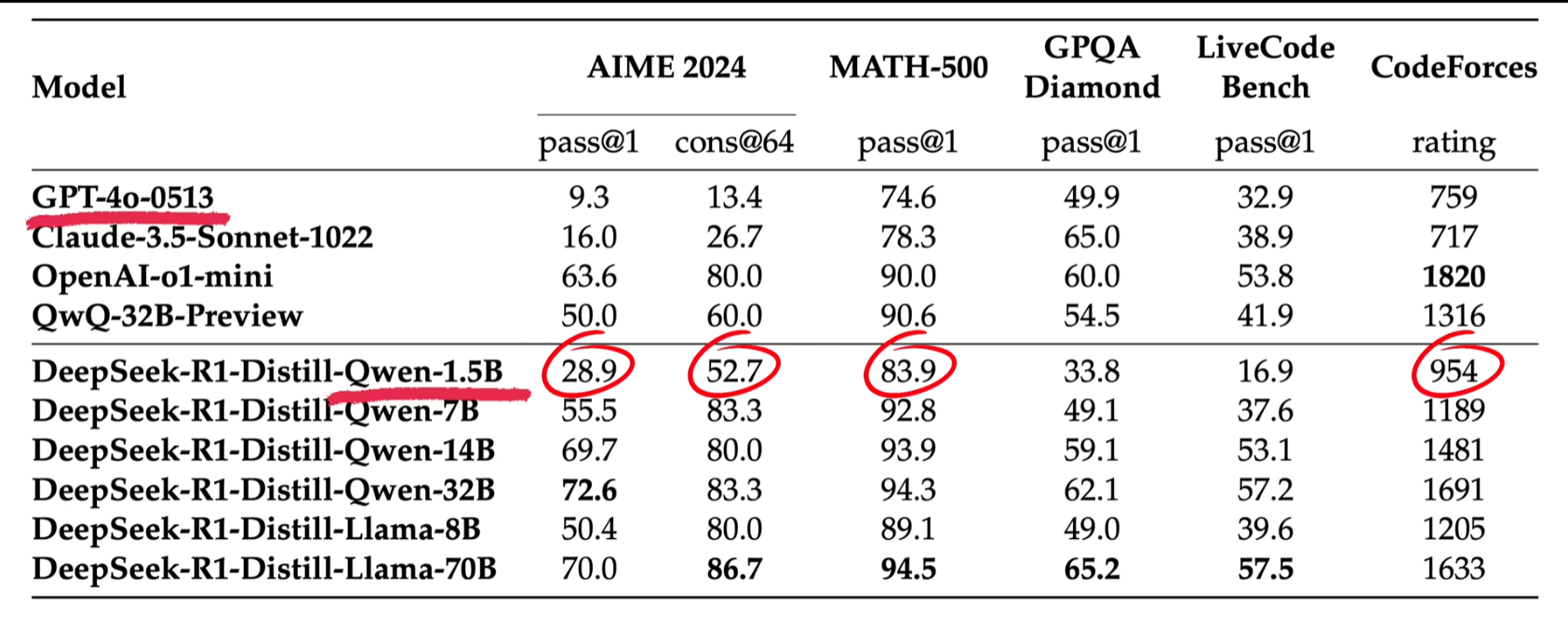
但是它的多项参数还是比满血版本GPT4o要高。
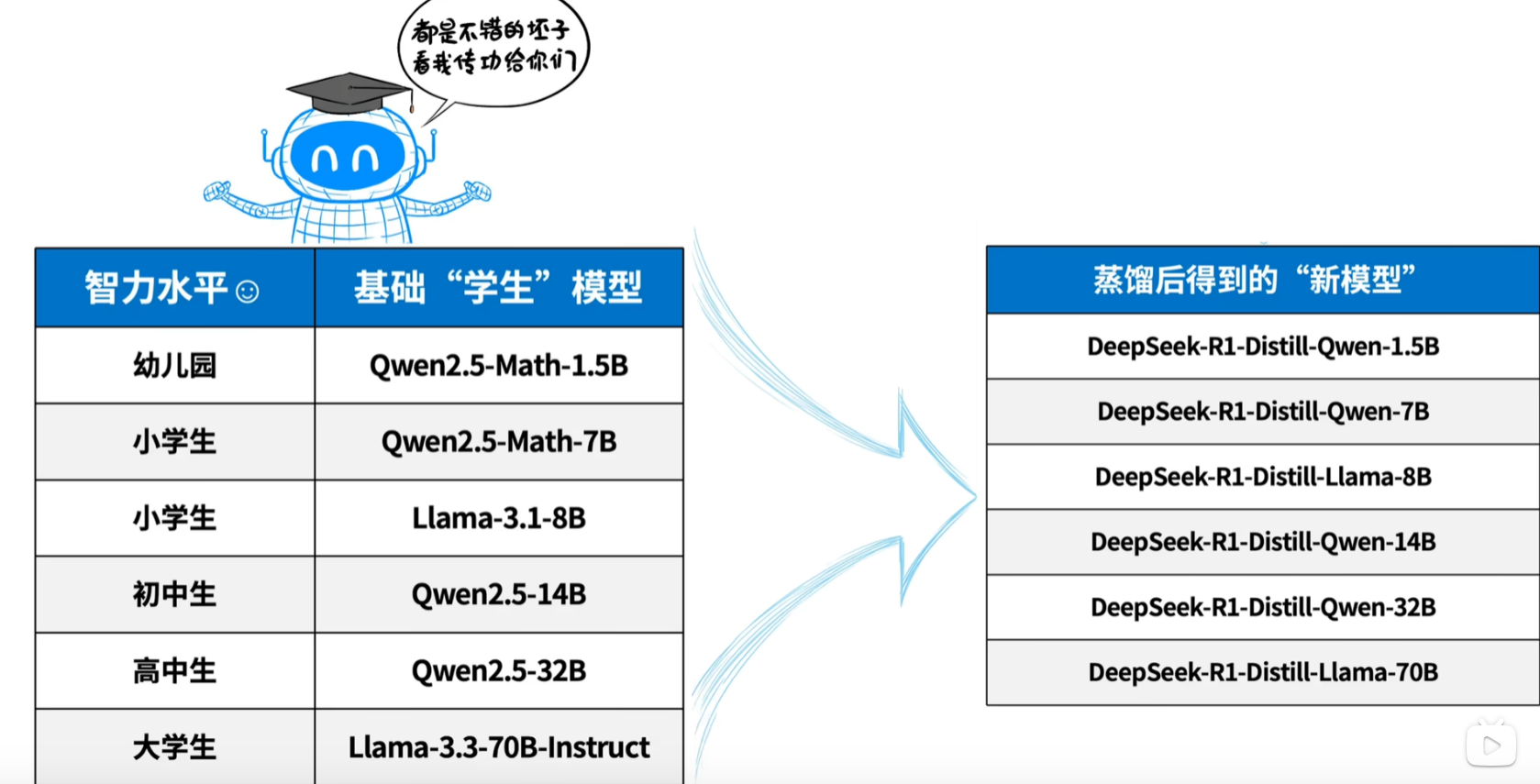
模型蒸馏就实现了从以前的狂堆参数、狂堆算力、狂堆显卡转向精准提纯,提高参数的效率和密度,花小钱办大事,而且不需要修改模型架构,相比从头训练节省大量的计算资源。
下面我就带大家全流程蒸馏DeepSeek R1

打开百度大模型千帆 大模型服务与开发平台ModelBuilder,点左边的模型广场。
可以看到deepseek全系列的模型,包括蒸馏后的几个小模型。
他们的价格怎么样呢?这是他们调用api的价格表。
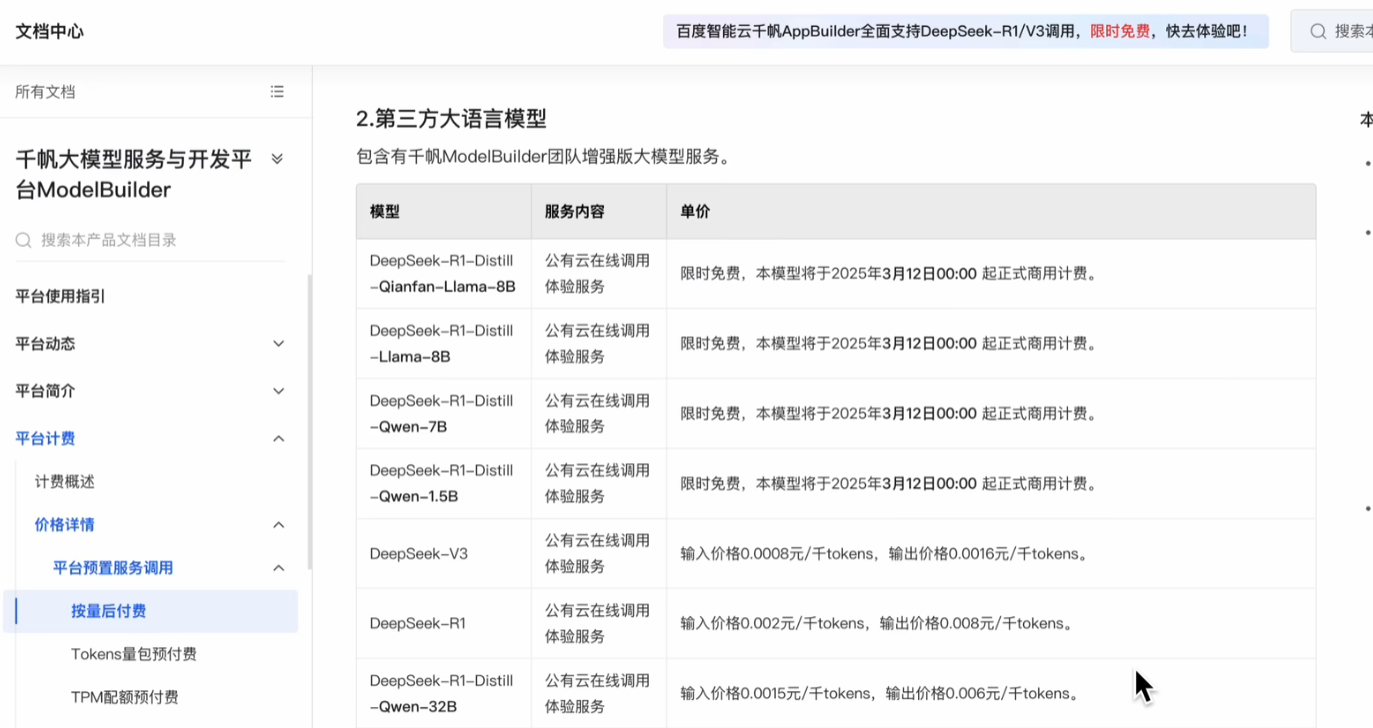
24年初大模型的价格战就是由deepseek打起来了。
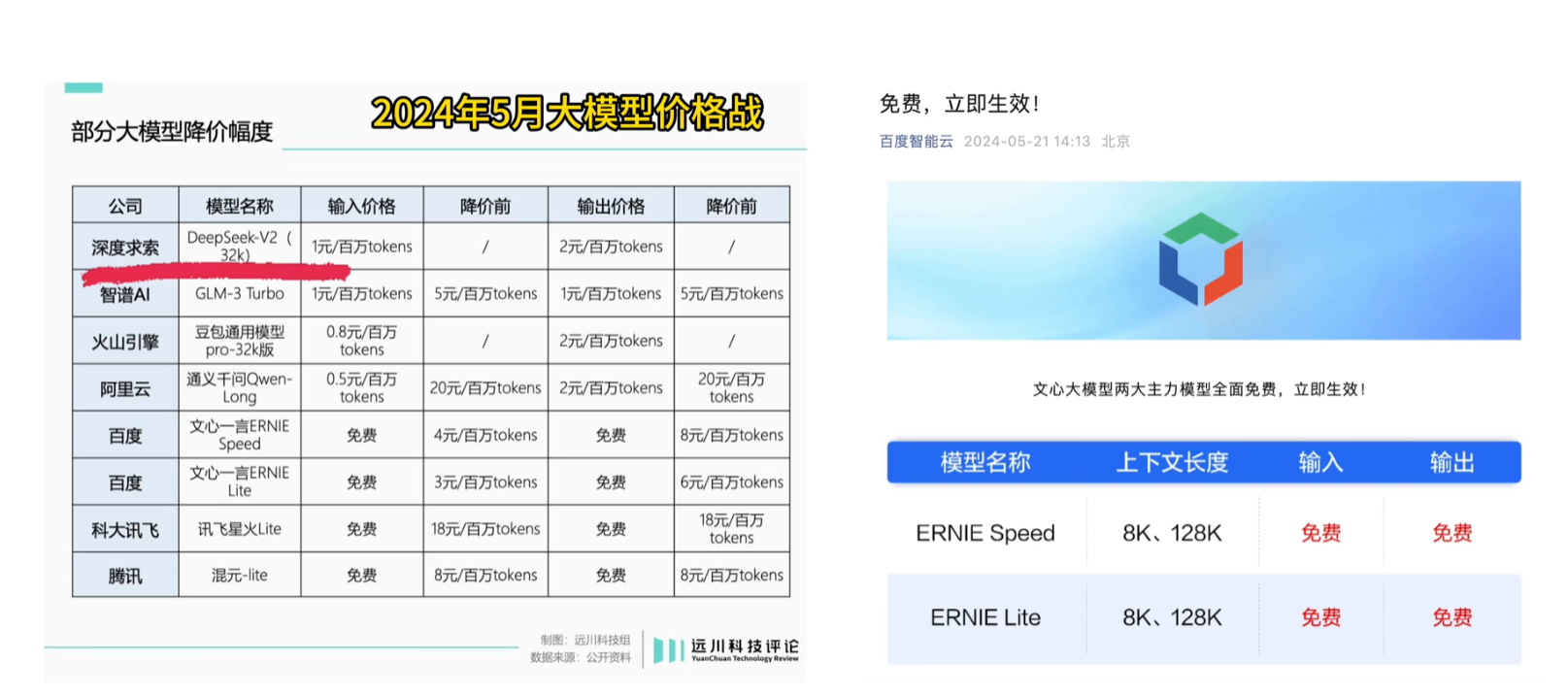
经过一年,大模型api的价格已经卷到地板了,用蒸馏的小模型甚至都限时免费了。可以无限调用薅羊毛。
模型蒸馏需要一个老师和一个学生。


接下来就让满血版本的671B参数量的 DeepSeek R1作为老师大模型,百度的ernie speed作为学生小模型。
ernie speed在数学题上的表现没有deepseek R1那么强大,至少没有慢思考推理,给出的结果也是错的。
就算你在提示词里面让它强行模仿DeepSeek R1,它给出的结果仍然是错的。
接下来模型蒸馏的目标就是让R1把数学知识传授给ernie speed,让ernie speed在数学领域学会慢思考,而且在数学领域的推理能力直接追平R1。
先来看看蒸馏需要用到的数据集,这个数据集可以直接下载,这是json格式的原始数据集文件。有英文题也有中问题,每道题都包含prompt和response两个key
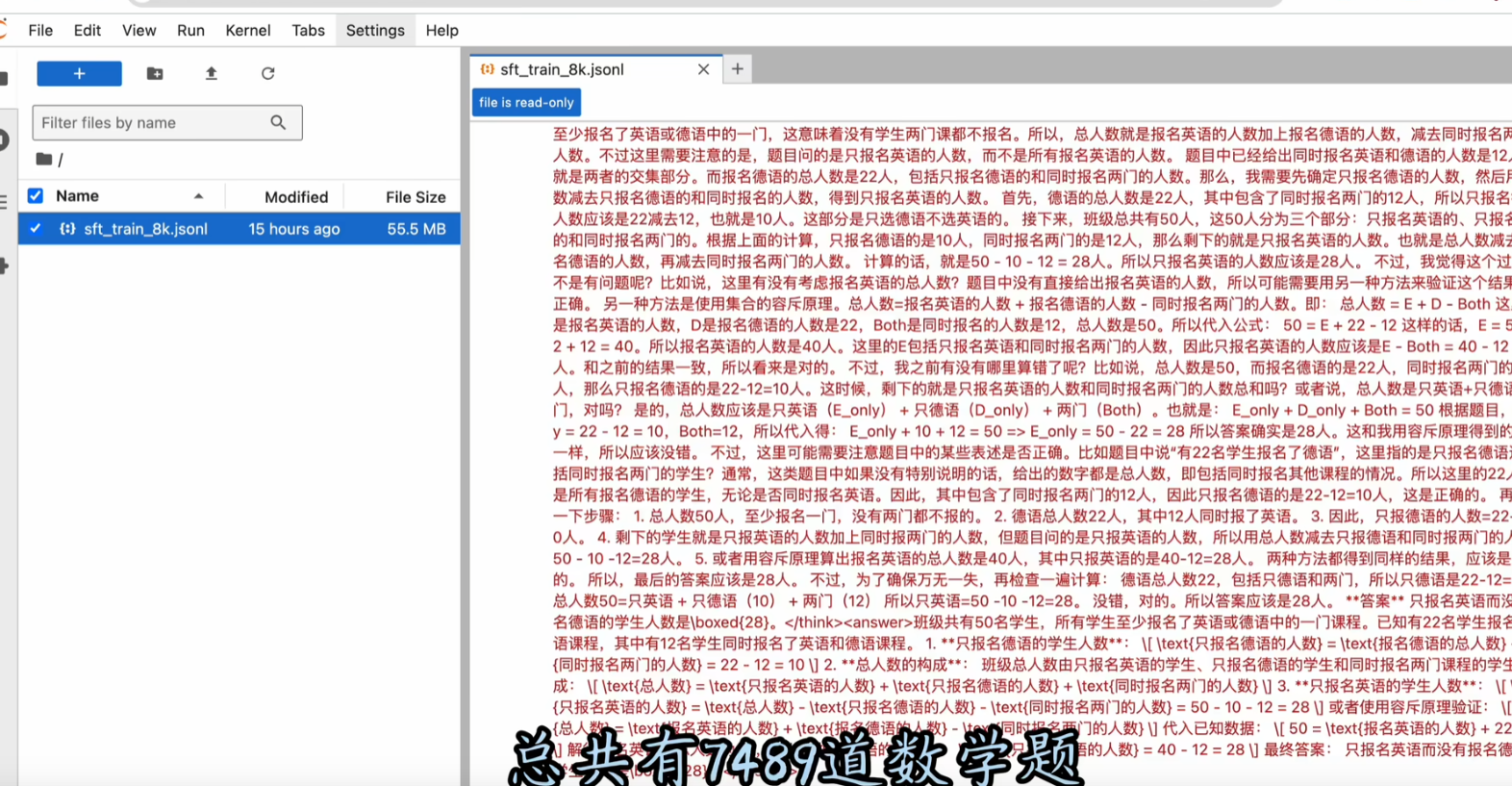
prompt是数学题本身,response是deepseek r1的回答,回答也包含两个部分,think标签是慢思考推理,answer标签里面是最终的回答。
prompt 和 response一问一答形成了问答对。这个数据集就好比R1老师写好了一本数学教材。
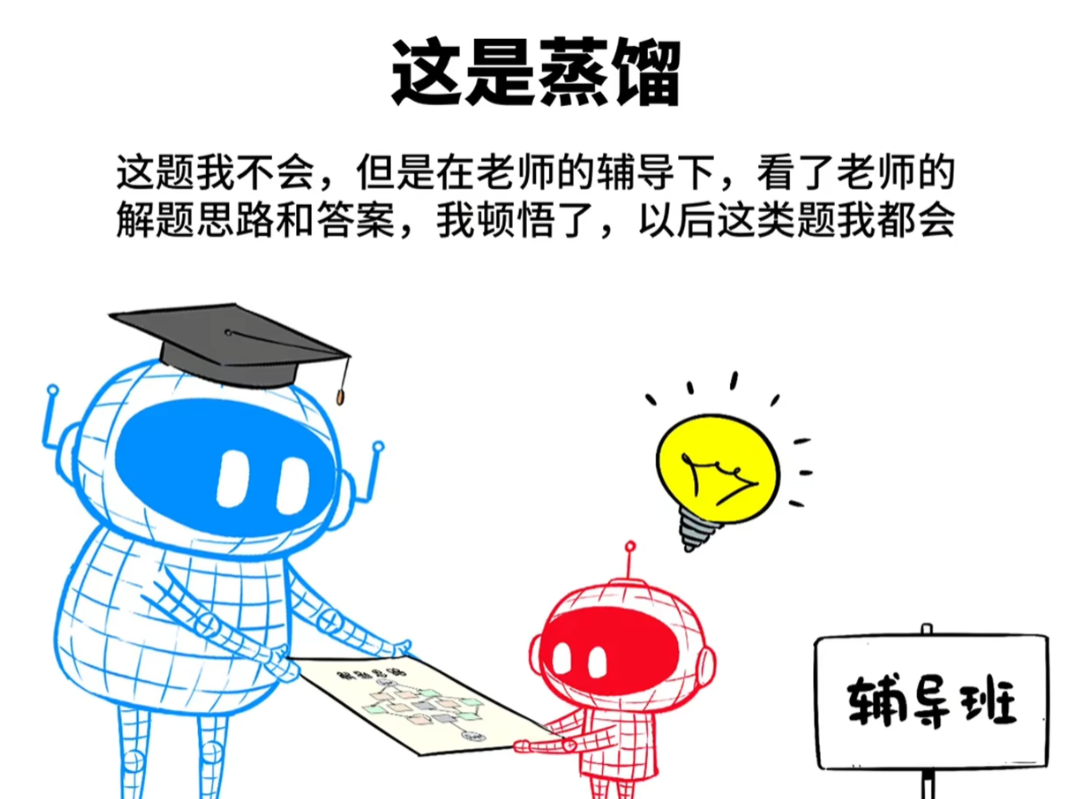
接下来用这个数据集教材再去sft 精调 ernie speed
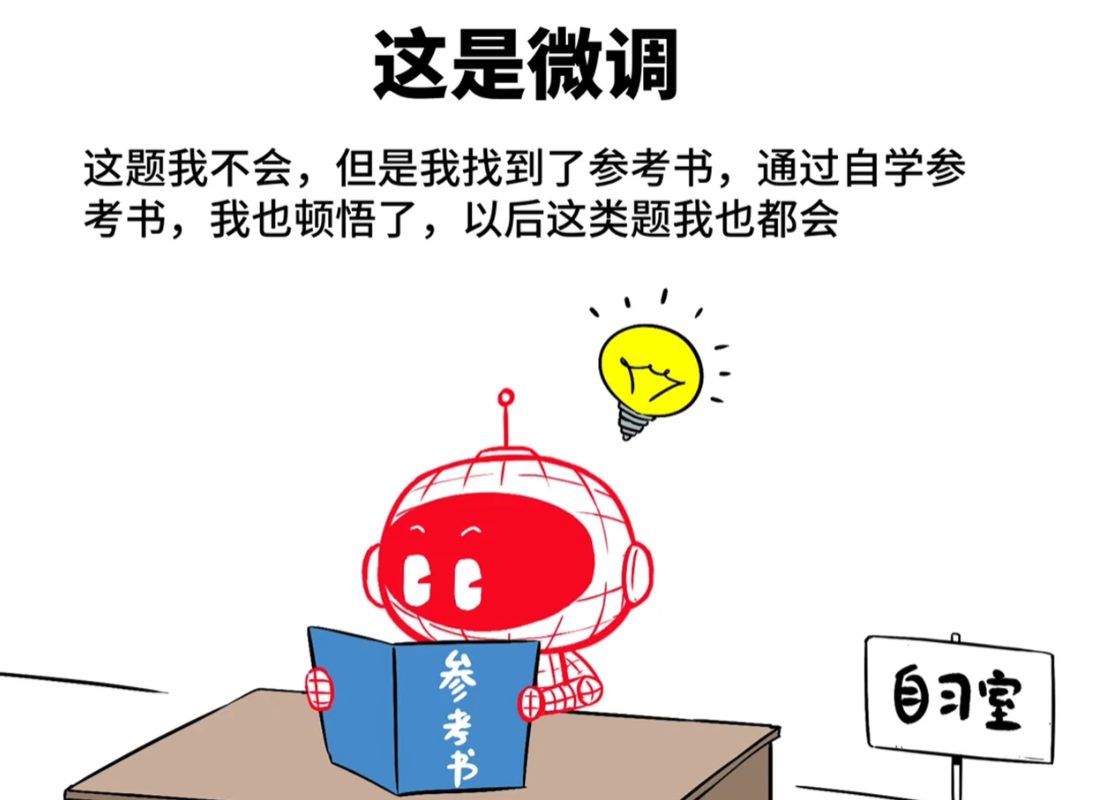
就实现了把数据知识从R1蒸馏给了 ernie speed,把数据集上传到ModelBuilder里面
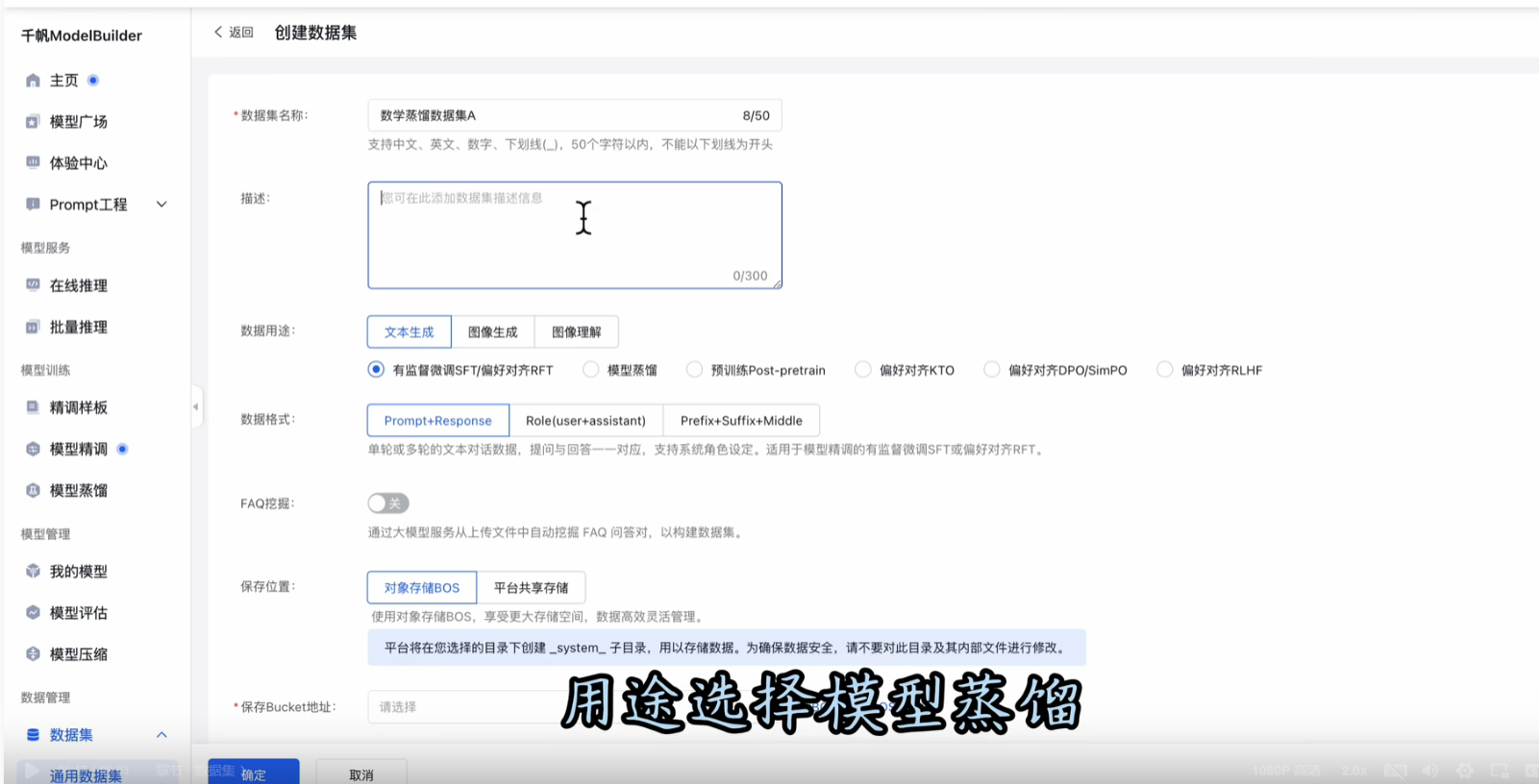
在左侧数据集-通用数据集-创建数据集。
用途选择模型蒸馏。
然后就是上传数据集即可。
接下来就是正式进入蒸馏了
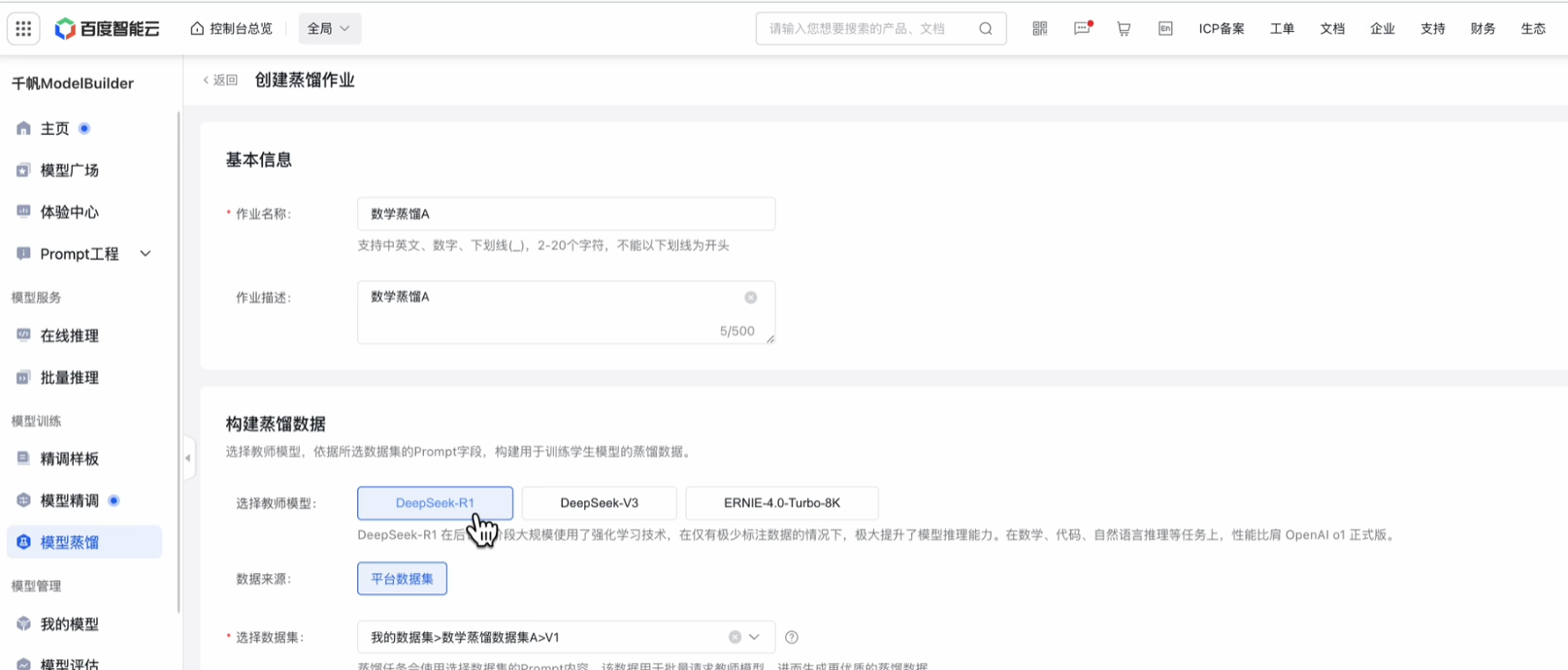
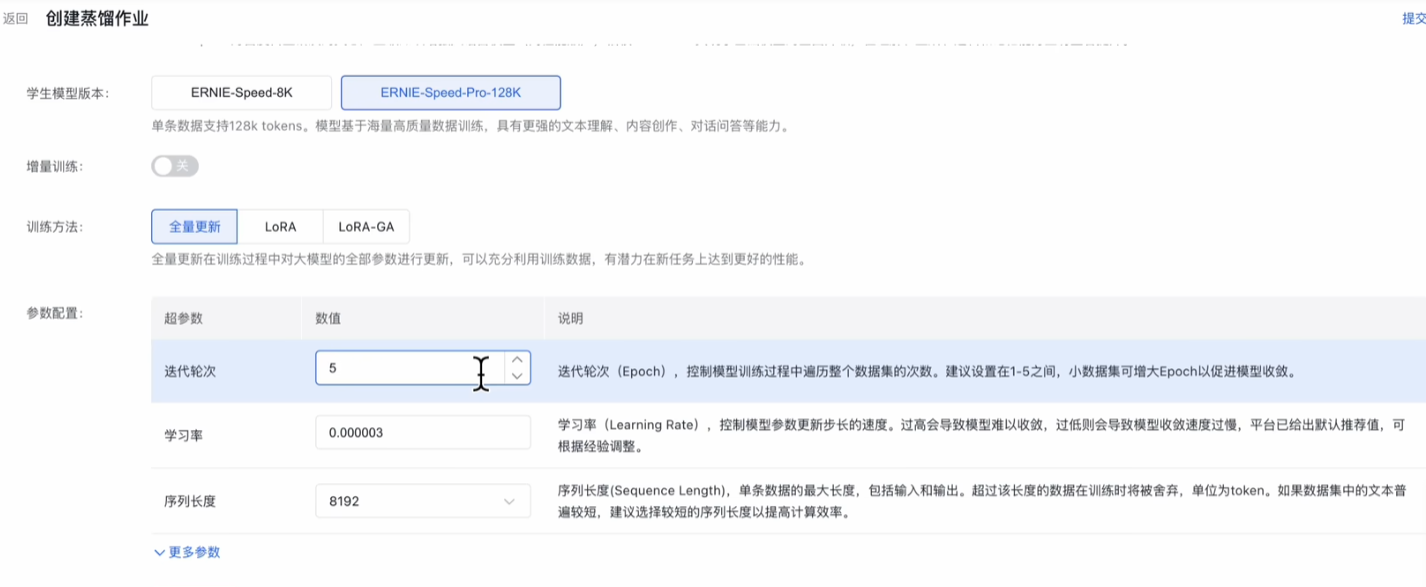
选择模型满血deepseek R1,数据集就是刚刚上传的蒸馏数据集,保留思维链内容一定要打开,这样response才会包含think 和 answer。教师模型才会把自己的解题思路和脑回路 传授给学生模型。记在数据集里面。
学生模型选择 ernie speed,它虽然不是旗舰模型,但是性价比很好,有8k 和 128k两种上下文长度的,对数学题来说其实无所谓。
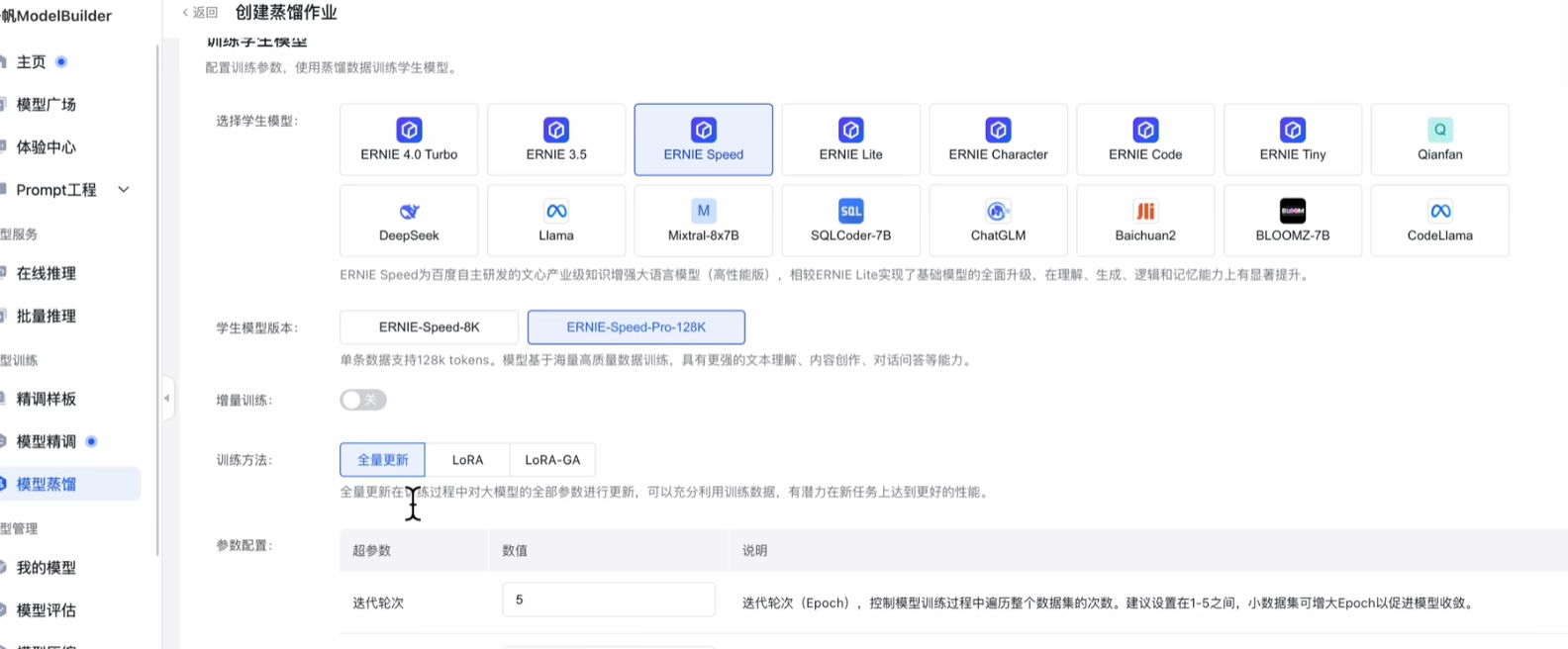
有三种训练方法,如果你想大改学生模型给它换个脑子,就选择全量更新,如果只是小小微调那就选LoRA 或者 LoRA-GA。
还有三个比较重要的超参数。
分析成本的组成,大部分成本花在训练上,也就是算力,小部分成本花在构造蒸馏数据上。也就是让R1自动填出response字段上

当训练完成后点击详情,看下蒸馏数据集长啥样,和刚刚展示的结构一样,包括三部分,数学题、慢思考和最终回答,我们上传的数据集里面,其实只包含prompt这一列就好了,后台会自动调用R1的api 不全慢思考和最终回答,形成最终的数据集。
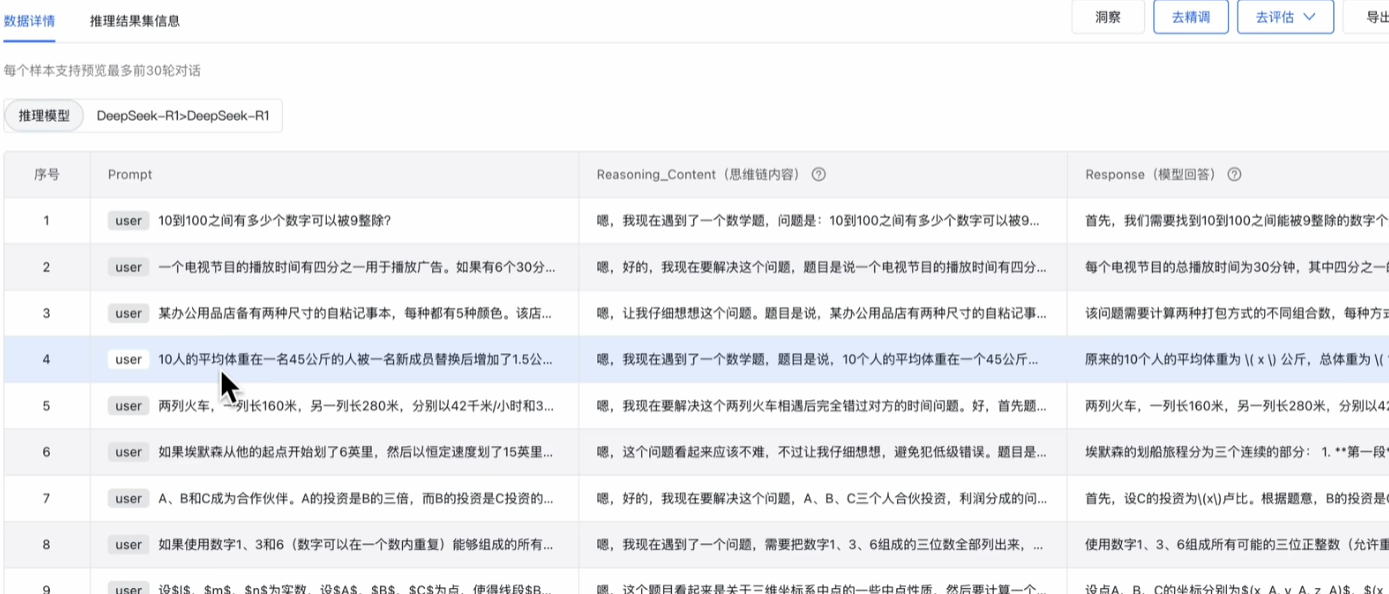
用最终的数据集来精调训练学生模型
最后算下来的成本,R1推理用了46块钱。

训练学生模型花了967块钱。所以总共1000多一点

点击发布
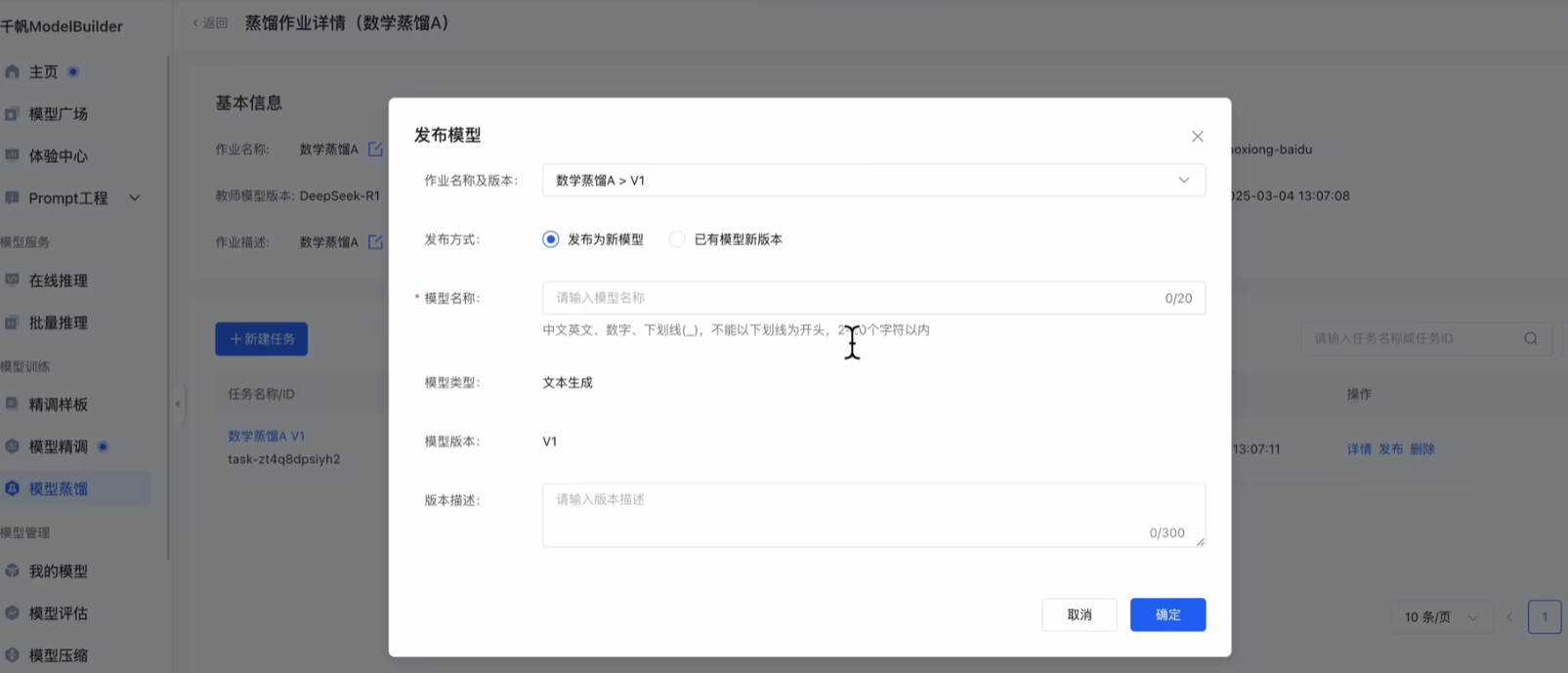
点击部署即可。
此时就可以在模型中心选择我们自己的小模型就行测试了。
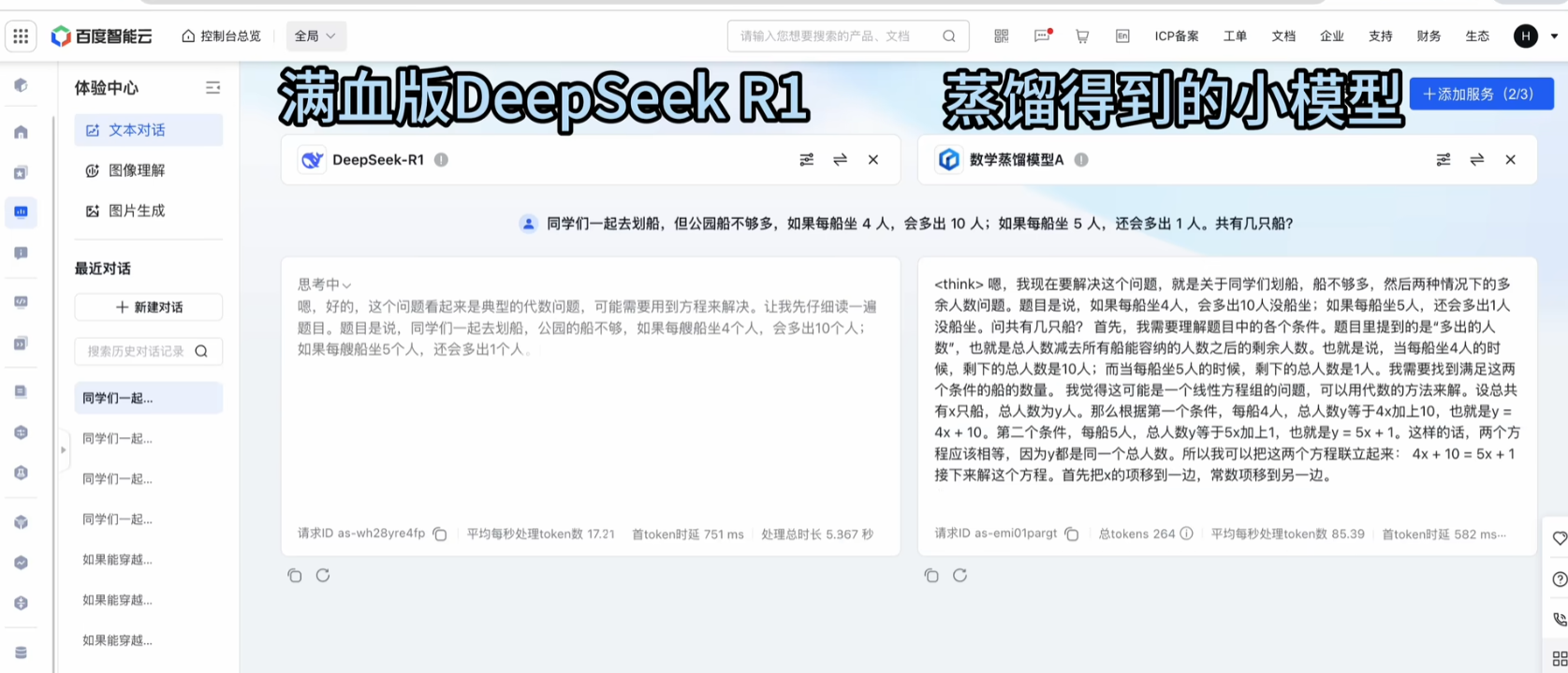
当你问他同一个问题的时候,你会发现数学蒸馏模型具备了慢思考,有了思维链,答案也正确了。
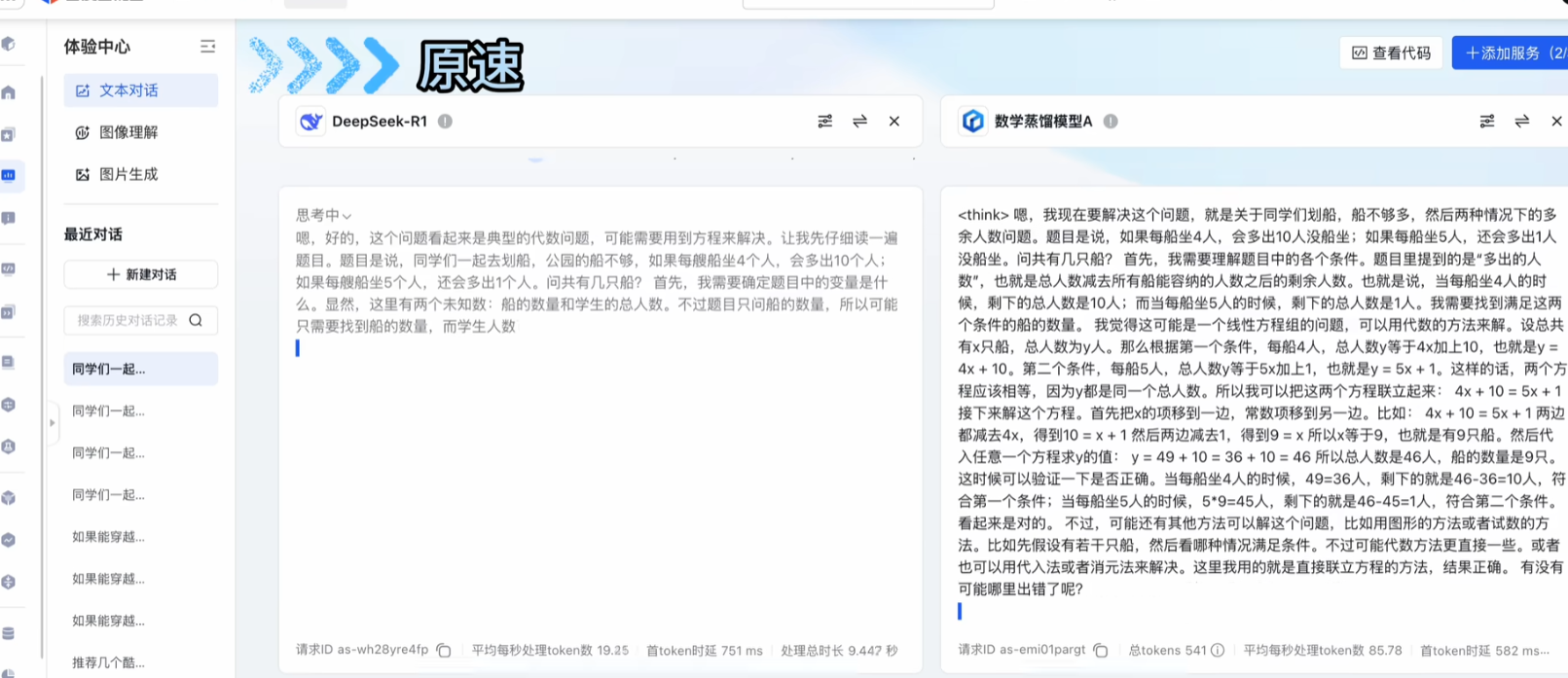
当这样做了之后,学生模型(小钢炮)价格成本极低,推理速度极快,本地部署极方便,而且在数学领域和老师R1达成了平替。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 32
32 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)