从ChatGPT到DeepSeek AI:AI语言模型的全面分析——演变、偏差与未来影响
人工智能(AI)的快速发展重塑了自然语言处理(NLP)领域,其中以OpenAI的ChatGPT和DeepSeek AI为代表的模型尤为突出。尽管ChatGPT为对话式AI奠定了坚实的基础,但DeepSeek AI在架构、性能和伦理考量方面引入了显著改进。本文详细分析了从ChatGPT到DeepSeek AI的演变过程,重点探讨了它们的技术差异、实际应用及对AI发展的更广泛影响。为了评估这些模型的能
Simrandeep Singh 1{ }^{1}1, Shreya Bansal 2{ }^{2}2, Abdulmotaleb El Saddik 3{ }^{3}3, Mukesh Saini 2{ }^{2}2
1{ }^{1}1 昌迪加尔大学
2{ }^{2}2 印度理工学院罗帕尔分校
3{ }^{3}3 渥太华大学
摘要
人工智能(AI)的快速发展重塑了自然语言处理(NLP)领域,其中以OpenAI的ChatGPT和DeepSeek AI为代表的模型尤为突出。尽管ChatGPT为对话式AI奠定了坚实的基础,但DeepSeek AI在架构、性能和伦理考量方面引入了显著改进。本文详细分析了从ChatGPT到DeepSeek AI的演变过程,重点探讨了它们的技术差异、实际应用及对AI发展的更广泛影响。为了评估这些模型的能力,我们使用了一组预先定义的多选题进行了案例研究,涵盖了多个领域的测试,评估了每个模型的优势和局限性。通过这些分析,我们提供了关于AI未来发展方向、其对行业潜在变革以及改进AI驱动语言模型的关键研究方向的宝贵见解。
索引词-对话式AI,大语言模型(LLMs),自然语言处理(NLP)。
I. 引言
在当今时代,人工智能(AI)是技术领域最重要的发展成果之一;每个人都对AI津津乐道。其应用范围覆盖了各个领域,如医疗[1][2]、机器人[3][4]、金融[5][6]、工程[7][8]、网络安全[9][10]、农业[11][12]、零售[13]、聊天机器人(Siri, Alexa)[14][15]、制造[16][17]、娱乐[18][19]、商业与营销[20][21]、媒体[22][23]、交通运输[24][25]等众多领域。
AI正在帮助人类解决社会面临的挑战,开辟更先进的解决方案,并突破传统方法的界限以重新定义可能性。AI是由计算机科学工程师开发的一种工具,旨在应对传统上与人类智能相关的认知挑战。它为解决问题、学习、模式识别、摘要生成、情感分析、聊天机器人、机器翻译等提供了解决方案。AI的主要目标是使个人的日常生活更加愉快、轻松、高效、便捷和自动化。AI通过采用类似人类的智能并模仿人类行为进行自我训练,从而实现了这一目标。由于其能够帮助人类完成各种任务,AI已成为实践和娱乐场景中不可或缺的工具。
AI的一个备受关注的领域是自然语言处理(NLP)[26][27],自ChatGPT和其他类似工具问世以来,这一领域成为广泛讨论的话题。然而,NLP还拥有许多较早的工具,例如ELIZA(1966年)[28]、SHRDLU(1968-1970年)[29]、PARRY(1972年)[30]、基于LISP的NLP系统(1980年代)[31]、WordNet(1985年至今)[32]、隐马尔可夫模型(HMM)[33]、潜在语义分析(LSA)(1990年代)[34]、斯坦福NLP(2000年代至今),这些工具为现代基于深度学习的模型铺平了道路。人类语言是一种复杂的现象,包含数千种语言、数百万个单词和多种含义。NLP作为一个跨学科领域,结合了AI与语言学,允许更深入和真实的交流。NLP可以理解、沟通和解释语言,同时通过机器学习、深度学习或计算语言学进行训练,促进计算机与人类语言之间的互动。NLP包括许多步骤;在分词过程中,长句被分割成单独的标记,然后在标记化中分析每个标记的位置和上下文。词形还原和词干提取有助于消除词缀并确定完整单词的基本形式,确保其意义不会失去上下文特征。处理的最后一个阶段是组块分析,将不同的语言成分组合成更连贯、结构化和有意义的单元[35]。
Transformer模型[36][37]的引入彻底改变了NLP领域[38][39]。这些模型,例如GPT[40][41][42],显著提升了NLP系统的功能,使其更加高效和有效。如今,机器变得越来越友好,模型能够生成具有人类情感和表达能力的文本。Transformer模型的核心是注意力机制[43][44],该机制动态地赋予输入序列中的关键点更多关注,从而使模型能够处理序列到序列任务、问答、情感分析和语言建模等问题更加高效。因此,它们能够生成新文本、理解新的模式和单词之间的关系,最终增强系统的理解能力。
推动这一革命的主要参与者之一是OpenAI,这是一家成立于2015年的美国人工智能(AI)研究实验室,由一群工程师、研究人员和企业家共同创立。它有两个子公司——OpenAI Inc. 和 OpenAI Global LLC,分别服务于非营利和商业目的。该组织得到了微软公司、埃隆·马斯克、山姆·阿尔特曼、伊利亚·苏茨克弗和格雷格·布罗克曼等知名人士和公司的大力支持,他们也是联合创始人和主要投资者。OpenAI的愿景是开发超越人类能力的人工通用智能(AGI)[45],旨在造福全人类。几个机器学习工具,如DALL-E [46] 和 ChatGPT [40],作为OpenAI的产品已公开供公众使用。特别是ChatGPT,在发布后的一周内吸引了超过一百万用户,迅速获得了极大的关注。OpenAI于2022年11月30日推出了基于GPT-3.5 [47] 和 GPT-4 [40] 架构的ChatGPT。由于其连贯性和多样化的应用场景,ChatGPT已经成为一种广泛使用的创新工具。这是一个高级聊天机器人,能够处理多种应用,如回答问题、编写代码、创建内容、提供客户服务、协助教育、起草电子邮件和会议记录、生成创意、撰写项目报告、提供医疗协助、纠正语法、进行研究分析、翻译语言等。其简化的架构有助于高效解读用户输入并提供类似于真实人类语言的响应。然而,ChatGPT存在许多缺点,如高计算成本、不够聚焦以及较高的价格。为了解决这些问题,梁文峰提出了一个全新的视角来改进NLP模型,即Deepseek AI [48]。
II. 背景
本节回顾了ChatGPT的发展历程,重点介绍了其在不同版本中的发展和功能。同时,还介绍了DeepSeek AI,这是一种新的方法,旨在解决当前模型(如ChatGPT)的一些局限性,为NLP提供更高效和任务聚焦的范式。
A. ChatGPT:开创性的模型
ChatGPT是由OpenAI开发的公开可用的AI工具,标志着自然语言处理(NLP)和对话式AI的重大进步。ChatGPT的基本构建模块是一个大型语言模型(LLM)[49][50]架构,包括嵌入、编码器-解码器层[51]、位置编码、自注意力机制、前馈网络、添加和归一化层以及多头注意力。ChatGPT是一个高度复杂的聊天机器人,通过使用变压器框架的深度神经网络架构生成连贯且上下文相关的文本。它属于一组广泛使用的基于变压器的模型,包括双向编码器表示(BERT)和生成预训练变压器(GPT)。ChatGPT是一个语言模型,能够在各种应用中理解和生成类似人类的文本,例如句子补全、翻译和对话交互。它通过模拟与人类用户的对话并生成类似人类的输出来增强对话能力。其对话能力通过强化学习结合人类反馈(RLHF)[52]进行微调得到提升。该模型的功能通过使用从各种书籍、文章、网站和其他文本内容中提取的多样化数据集进行广泛的预训练而得到增强,利用高端GPU进行训练。
B. ChatGPT的演变
大型语言模型(LLMs)是自然语言处理(NLP)快速演进的基础。在LLMs取得重大进展之后,ChatGPT在短时间内经历了多次迭代。仅在两年内,ChatGPT迅速提升了其能力和性能参数。开创性的变压器模型为更先进的大型语言模型奠定了基础。这些变压器模型相较于传统的循环神经网络(RNN)和长短时记忆网络(LSTM)[53]显示出显著的改进。变压器的编码器-解码器架构在深度学习领域引发了一场地震般的转变。如图2所示,变压器模型展示了并行处理能力,并被训练用于理解和生成类似人类的文本。RNNs和LSTMs在处理长期依赖关系时面临诸如梯度消失[54]等挑战。然而,变压器在并行处理方面表现出色,因其依赖于“注意力机制”,这使它们能够捕捉长时间序列中的关系。第一个GPT-1模型[55]于2018年中期推出,采用了无监督预训练的自回归语言建模方法。这种方法为在大规模文本语料库上进行预训练然后进行微调奠定了基础,成为各种NLP任务的标准方法。在预训练阶段,GPT模型使用传统的语言建模目标,如公式1所示:
L1(u)=∑ilogP(ui∣ui−k,…,ui−1) L_{1}(u)=\sum_{i} \log P\left(u_{i} \mid u_{i-k}, \ldots, u_{i-1}\right) L1(u)=i∑logP(ui∣ui−k,…,ui−1)
其中uiu_{i}ui是当前标记,ui−1,ui−2…ui−ku_{i-1}, u_{i-2} \ldots u_{i-k}ui−1,ui−2…ui−k是前kkk个上下文标记,PPP是使用仅解码器变压器建模的概率函数。经过预训练后,模型通过监督学习针对特定任务进行微调,其中在相关数据集上进行输入转换训练。在推理阶段,GPT-1生成新序列,利用其训练过的1.17亿个参数。训练过程涉及处理大约7000本未出版的书籍。
OpenAI于2019年发布了GPT-2 [56],该模型包含一个15亿参数的变压器。该模型包括参数,如超过50,000的词汇量、12个注意力头、12层和512的批量大小。它在800万个网页或网页文本上进行训练,无需监督微调。GPT的一个显著特点是其零样本学习能力,使它能够处理未明确训练的任务。这种能力是通过利用训练期间获得的模式和知识来泛化到未见过的任务实现的。例如,该模型可以在没有特定任务相关示例的情况下分类情感或生成创意内容。语言建模在GPT 2中由公式2给出,该公式表示给定先前状态ui−1u_{i-1}ui−1的序列uiu_{i}ui的概率的概率框架,建模为条件概率的乘积。
p(x)=∏i=1nP(ui∣u1,…,un−1) p(x)=\prod_{i=1}^{n} P\left(u_{i} \mid u_{1}, \ldots, u_{n-1}\right) p(x)=i=1∏nP(ui∣u1,…,un−1)
GPT-3 [47]的架构与GPT-2相比变化不大,GPT-3的关键改进是在变压器框架内交替使用密集和局部带状稀疏注意力模式。这个庞大的数据集,包含约4100亿个标记,使自回归语言模型(GPT-3)能够发展出对语言模式和上下文关系的广泛理解,并于2020年推出。训练是在巨大的数据集上进行的,该数据集包含大约570GB的文本,来源于Common Crawl(占训练混合的60%)、WebText2(190亿,22%训练权重)、Books1(190亿,8%训练权重)、Books2(550亿,8%训练权重)和Wikipedia(30亿,2%训练权重)。GPT-3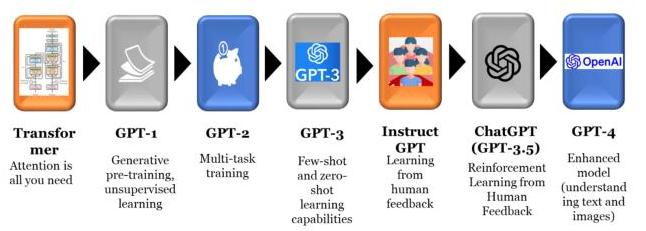
图1. GPT的演变:从版本1到4
在不进行梯度更新或微调的情况下使用,基于任务和仅用文本交互指定的一小部分演示。GPT-3是一个少量样本和多任务模型,训练了8个不同大小的模型,其可训练参数范围在1.25亿到1750亿之间。GPT-3比以前的版本先进10倍,具有广泛的应用,如语言翻译、内容创作、文本分类、情感提取、创意写作、写作辅助、研究和分析、代码生成、业务指南等。GPT-3.5只是GPT-3的一个微调和迭代版本,于2022年推出。它能够生成比以前版本更逼真、相关和连贯的文本。GPT-3和GPT-3.5的参数显著增加,代表了对早期版本的重大改进。OpenAI于2023年推出了ChatGPT,其基础模型是GPT-3.5。GPT-3.5能够生成被称为人性化AI的类似人类的文本,展示出对文本语义和上下文的更深理解,从而在技术和报告写作方面表现更好。
GPT-4 [40]于2023年3月14日进入公共领域,其推理能力有所提高。它表现出多模态行为,即兼容文本和图像作为输入。这种行为使GPT-4能够理解视觉、口语和文本信息,增强了其应对复杂情境和理解长期上下文的能力。这一重大改进使GPT-4能够存储更长的数据版本,保存对话中的细节,并提供更符合伦理和公平的输出。所有这些发展都总结在表I中,该表突出了每次GPT迭代的关键差异和改进。
C. DeepSeek AI:范式的转变
DeepSeek AI由DeepSeek开发,建立在ChatGPT的基础上,但引入了重大创新。其目的是增强人工通用智能(AGI)并使其成为现实。它包括先进的微调技术、更深层次的上下文理解、图神经网络(GNNs)[57]、强化学习或记忆增强网络[58],并专注于合乎伦理的AI实践。DeepSeek AI已被宣布为更具领域针对性,并旨在克服ChatGPT的局限性。DeepSeek正在使用优化效率的模型,减少偏见,并提供更定制化的响应。其开发的明确议程似乎转向了更负责任和适应性强的AI系统。
III. 主要偏差与进步
中国AI研究实验室于2023年成立,开发了完全开源的DeepSeek R1模型,并于2025年向公众发布。由于其成本效益高的训练方式,它在全球范围内引起了广泛关注。它在推理和非推理能力方面与其同类产品有所不同,例如自我验证、反思和长对话。在架构层面,它用强化学习(RL)取代了监督微调,训练流程涉及两个RL阶段和两个监督微调(SFT)阶段。
DeepSeek-R1-Zero代表了LLM模型中的新方法,直接将RL应用于基础模型,绕过了传统的监督微调(SFT)阶段。这种创新方法使模型能够自主探索和发展解决复杂问题的思维链(CoT)推理策略。这种训练方法帮助DeepSeek-R1-Zero在AI方面取得了重大进展,如自我验证、反思和生成广泛的思维链。自我验证有助于评估和验证其自身的输出,而反思则呈现对其推理过程的内省分析。它展示了基于RL的训练培养更复杂和更自我意识的语言模型的能力。
此外,DeepSeek的性能通过模型蒸馏[59]得到了提升,使小型模型能够实现与大型模型相当的推理能力。其总训练成本显著低于Google和OpenAI等其他知名的LLM模型,这些模型在类似的基础模型上花费了更多的资金。每次推理的成本也低得多,使其成为可扩展部署的有吸引力的选择。
中国AI研究实验室利用H800芯片,采用专家混合和多头潜在注意等技术来弥补较低的计算能力。这一突破使模型在硬件限制下仍能有效运行。以下小节概述了其架构改进、性能指标、伦理考量和实际应用。
A. 架构改进
- 模型规模和效率:ChatGPT依赖于大量参数(例如GPT-3中的1750亿个参数),这导致了其高昂的计算成本。相比之下,DeepSeek AI采用更高效的架构,减少参数数量的同时保持甚至提高了性能。这是通过稀疏注意力机制和模型蒸馏等技术实现的。
- 微调和适应性:DeepSeek AI融入了先进的微调方法,如基于人类反馈的强化学习(RLHF)和领域特定的预训练。这使得模型能够更有效地适应专门任务,如医学诊断或法律文件分析。
- 群组相对策略优化(GRPO):为减少与强化学习(RL)相关的计算费用,DeepSeek采用群组相对策略优化(GRPO),这是一种由邵等人[60]于2024年提出的方法。GRPO是一种在线学习算法,通过消除对单独批评模型的需求,提供比传统方法更有效的替代方案。GRPO旨在最大化生成完成的优势,帮助模型通过比较不同动作并使用一组观察结果进行小而受控的更新来更好地学习。
不使用批评模型,GRPO采用基于群体的评估策略。对于每个给定的问题或提示,该算法从现有策略(πθold )\left(\pi_{\theta_{\text {old }}}\right)(πθold )生成多个输出。然后使用这些输出来建立性能评估的基准。策略模型(πθ)\left(\pi_{\theta}\right)(πθ)的优化过程涉及最大化一个目标函数,该函数比较每组内输出的相对性能。这种方法允许更简化和成本效益更高的训练过程,同时保持提高模型性能的能力。群组强化学习目标(GRPO)由公式3定义。
LGRPO(θ)=Lclip(θ)−w1DKL(πθ∥πorig ) L_{\mathrm{GRPO}}(\theta)=L_{\mathrm{clip}}(\theta)-w_{1} D_{\mathrm{KL}}\left(\pi_{\theta} \| \pi_{\text {orig }}\right) LGRPO(θ)=Lclip(θ)−w1DKL(πθ∥πorig )
其中:
- Lclip (θ)L_{\text {clip }}(\theta)Lclip (θ) 是剪切代理损失,类似于PPO。
- DKL(πθ∥πorig )D_{\mathrm{KL}}\left(\pi_{\theta} \| \pi_{\text {orig }}\right)DKL(πθ∥πorig ) 是KL散度项。
- w1w_{1}w1 是权重参数。
每个群体中每个响应的优势由公式4计算:
Ai=Rϕ(ri)−mean(G)std(G) A_{i}=\frac{R_{\phi}\left(r_{i}\right)-\operatorname{mean}(G)}{\operatorname{std}(G)} Ai=std(G)Rϕ(ri)−mean(G)
其中:
- Rϕ(ri)R_{\phi}\left(r_{i}\right)Rϕ(ri) 是响应rir_{i}ri的奖励。
- GGG 是响应的群体。
- std\operatorname{std}std 是标准差。
B. 性能指标
- 上下文理解:ChatGPT的一个局限性是在长对话中容易丢失上下文。DeepSeek AI通过实施记忆增强架构解决了这个问题,使它能够在长时间的互动中保持连贯性。
- 偏见缓解:ChatGPT因训练数据中的偏见而受到批评,生成了有偏见或不适当的内容。DeepSeek AI通过去偏算法和精心策划的数据集最小化此类情况的发生,确保更公平和负责任的输出。
- 多语言能力:虽然ChatGPT支持多种语言,但DeepSeek AI通过纳入低资源语言和通过跨语言迁移学习改进翻译准确性,增强了这一能力。
C. 伦理考量
- 透明性和可解释性:DeepSeek AI优先考虑透明性,向用户提供有关如何生成响应的洞察以及随着时间推移改进响应质量的机制。这包括使用可解释AI(XAI)[61][62]技术,如SHAP(Shapley加法解释)[63]和LIME(本地可解释模型无关解释)[64],这些技术突出显示特定输出背后的推理。它不使用黑箱机制;相反,决策过程被追踪和审计。
- 用户隐私:DeepSeek AI结合了尖端的隐私保护措施,如差分隐私[65]和联邦学习[66],以确保用户交互保密。它通过向信号添加数学噪声来保护用户数据和未经授权的监视。联邦或协作学习确保在本地硬件上训练模型,并将权重和偏差传输到中央服务器以改进全局模型。
- 伦理一致性:DeepSeek AI在其训练过程中嵌入了公平性、问责制和包容性的伦理准则,减少了有害或不合伦理输出的风险。DeepSeek模型通过使用公平感知算法检测有害、成人、误导或冒犯性内容进行严格的偏差检测。模型通过基于人类反馈的强化学习(RLHF)改进伦理决策,随着时间推移逐步完善。
D. 实际应用
- 行业特定解决方案:DeepSeek AI为各个行业提供量身定制的解决方案。例如,在医疗保健领域,它可以协助进行医疗诊断和患者沟通,同时还能分析市场趋势、风险评估、投资决策、欺诈检测、客户服务和生成报告在金融领域。零售市场、教育和自动驾驶系统是其他DeepSeek正在改变传统技术的行业。
- 实时适应性:与主要以静态方式运行的ChatGPT不同,DeepSeek AI可以适应实时输入的变化,使其适合动态环境,如实时客户服务或互动教育。它最适合需要即时响应的应用,如交通自适应交通灯信号、检测金融领域的欺诈交易、根据学生的适性水平进行个性化辅导、生成MRI、CT和其他扫描报告、实时情感分析和市场趋势。
- 创意应用:DeepSeek AI增强的创造力和连贯性使其成为内容创作的宝贵工具,包括写作、音乐创作和图形设计。它在起草内容、头脑风暴、编写代码、做笔记、制作会议纪要、发现复杂的推理模式、互动故事讲述、复杂系统模拟、创意生成、设计优化等方面有着广泛的应用。
IV. 对比分析
DeepSeek也是开源的,促进了竞争并鼓励进一步的AI发展。这可能会在未来降低成本并产生更好的模型,使全球各地的公司和用户受益。本节提供了ChatGPT和DeepSeek AI在多个维度上的详细比较,包括模型架构、训练数据和方法、强化学习、计算效率、上下文、伦理和社会影响,以及汇总表II和III。这里对训练、能力和局限性进行了更深入的讨论和见解。
- 模型架构
- ChatGPT:它是一个基于OpenAI的GPT-3.5或GPT-4架构的通用语言模型,采用密集的Transformer模型,专注于大规模预训练和使用来自人类反馈的强化学习(RLHF)进行微调。它经历了大规模预训练,提供高计算成本和高延迟。
- DeepSeek AI:它采用优化和混合的Transformer架构,增强注意力和主动学习机制,改进上下文保留并减少令牌依赖以实现更好的长篇连贯性。它最适合潜在的领域特定或任务优化应用。
- 训练数据和方法
- ChatGPT:在多样化的数据集上训练,包括互联网文本、书籍和学术论文,并通过RLHF进行额外微调。
- DeepSeek AI:采用更动态的数据集整合方法,结合实时更新和领域特定数据集,以提高在专业化领域的适应性。
- 强化学习和优化
- ChatGPT:使用RLHF细化响应并改善用户对齐,专注于减少偏见和增强对话相关性。
- DeepSeek AI:通过动态强化机制推进RLHF,结合自适应奖励建模和改进的人工智能反馈循环,以实现更精细的响应。
- 计算效率和可扩展性
- ChatGPT:由于其密集架构和广泛的训练周期,需要大量的计算资源。
- DeepSeek AI:采用模型压缩技术,如知识蒸馏和量化,以优化性能并减少计算开销。
- 上下文窗口和记忆保留
- ChatGPT:支持较大的固定上下文窗口,限制其在一定令牌限制之外回忆先前交互的能力。
- DeepSeek AI:实施改进的上下文窗口管理系统,允许在更长时间的交互中更好地保留对话历史。
- 社会和伦理影响
- 偏见和公平性:两种模型在AI生成内容的偏见方面都面临挑战。DeepSeek AI在领域特定定制方面的重点提供了更大的公平性潜力,但也引入了过度拟合特定观点的风险。
- 对劳动力的影响:AI语言模型正越来越多地影响内容创作、客户服务和编程等行业。虽然它们提高了生产力,但也引发了对失业和新技能需求的担忧。
- 伦理考量和未来监管:随着AI变得更加普遍,监管框架将在减轻滥用方面发挥关键作用。培训方法的透明性和负责任的AI部署仍然是讨论的重点领域。
A. 案例研究
我们通过对ChatGPT和DeepSeek模型进行一系列涵盖多个领域的多选题综合评估,进行了详细的对比分析。比较案例研究的结果如表IV所示。它通过多选题评估了ChatGPT和DeepSeek在24个领域的性能能力。表格报告了向每个模型提出的总问题数,以及ChatGPT和DeepSeek的正确答案总数和相应的准确率(%)。
总体而言,DeepSeek AI在大多数领域的准确率上优于ChatGPT。例如,在旅游领域,DeepSeek AI正确回答了100个问题中的85个,准确率为85%,而ChatGPT正确回答了100个问题中的53个,准确率为53%。同样,在物理领域,DeepSeek AI达到了92%的准确率,正确回答了50个问题中的46个,而ChatGPT回答了50个问题中的43个,准确率为86%。
然而,在某些领域,ChatGPT的表现与DeepSeek AI相同或更好。例如,在心理学和经济学领域,两种模型都达到了完美准确率,正确回答了所有问题(100%)。在机械工程、植物学和商业等领域,两种模型的表现更为接近。例如,在机械工程领域,ChatGPT和DeepSeek AI都正确回答了50个问题中的39个,准确率为78%。
在数学领域,DeepSeek AI表现更好,正确回答了所有53个问题,达到100%的准确率,而ChatGPT回答了53个问题中的43个,准确率为81%。这表明DeepSeek AI在数学领域通过更高的准确率优于ChatGPT。同样,在商业领域,DeepSeek AI也优于ChatGPT,正确回答了50个问题中的49个(98%准确率),而ChatGPT正确回答了50个问题中的42个(84%准确率)。
表格底部提供了两种模型整体性能的综合总结。在总共测试的1429个问题中,DeepSeek AI正确回答了1245个问题,总体准确率为87%。相比之下,ChatGPT正确回答了1140个问题,总体准确率为79%。这一整体表现再次证明了DeepSeek AI在大多数领域中通常比ChatGPT具有更高的准确率。
总之,尽管ChatGPT在许多领域表现良好,但DeepSeek AI在大多数情况下始终提供更高的准确率,心理学和经济学领域是例外,两者表现相同。DeepSeek AI在数学领域表现出特别强的实力,达到了完美的准确率,而ChatGPT的准确率较低。
V. 对未来研究的影响
从ChatGPT到DeepSeek AI的转变为研究人员探索AI的进步提供了新的机会,特别是在效率、准确性和伦理考量方面。DeepSeek AI通过优化的训练技术和更好的资源管理,在多个领域表现出改进的性能。虽然ChatGPT在多个应用中表现出强大的能力,但DeepSeek AI在技术领域(如数学)中持续实现更高的准确率。然而,生成能力和推理准确性仍然是关键的研究领域,因为这两种模型在复杂问题解决和创造性生成方面各有优势和局限性。
这一转变突显了未来研究的几个关键领域。一个至关重要的方面是开发高效的训练算法,使大型模型能够在减少计算资源的情况下进行训练,从而使AI更加可持续和普及。此外,多模态集成也是一个重要的方向,允许AI系统处理和结合文本、音频和视觉输入以实现更全面的理解和互动。另一个值得关注的领域是持续学习,使AI模型能够基于用户互动不断适应和改进,从而实现更个性化和动态的响应。生成AI的准确性也需要进一步提升,以确保AI生成的内容保持连贯、上下文相关和事实准确。此外,必须加强推理能力,使AI模型在复杂情境中提供更可靠和逻辑合理的响应。
此外,对合乎伦理的AI发展的需求仍然
表III
ChatGPT与DeepSeek AI的比较
| 维度 | ChatGPT | DeepSeek AI |
|---|---|---|
| 架构 | 基于Transformer,参数量大 | 优化架构,参数量较少 |
| 微调 | 通用微调 | 领域特定微调 |
| 上下文理解 | 在长对话中有限 | 通过记忆增强系统提升 |
| 偏见缓解 | 去偏技术有限 | 高级去偏算法 |
| 伦理对齐 | 基本伦理准则 | 内置伦理框架 |
| 计算效率 | 高计算成本 | 优化以提高效率 |
| 实时适应性 | 有限 | 高 |
表IV
案例研究:ChatGPT和DeepSeek在多个领域中的多项选择题性能比较
| 领域 | 总问题数 | ChatGPT | DeepSeek | ||
|---|---|---|---|---|---|
| 正确总数 | 准确率(%) | 正确总数 | 准确率(%) | ||
| 旅游 | 100 | 53 | 53% | 85 | 85% |
| 心理学 | 50 | 50 | 100% | 50 | 100% |
| 物理 | 50 | 43 | 86% | 46 | 92% |
| 机械 | 50 | 39 | 78% | 39 | 78% |
| 数学 | 53 | 43 | 81% | 53 | 100% |
| 英语 | 101 | 64 | 63% | 78 | 77% |
| 计算机科学与工程 | 50 | 49 | 98% | 48 | 96% |
| 电子与通信工程 | 55 | 48 | 87% | 50 | 90% |
| 植物学 | 50 | 50 | 100% | 48 | 96% |
| 生物技术 | 100 | 74 | 74% | 90 | 90% |
| 计算机应用 | 50 | 40 | 80% | 44 | 88% |
| 电气工程 | 55 | 46 | 84% | 49 | 89% |
| 法律 | 50 | 45 | 90% | 42 | 84% |
| 土木工程 | 51 | 46 | 90% | 45 | 88% |
| 商业 | 50 | 42 | 84% | 49 | 98% |
| 大众传播 | 50 | 47 | 94% | 40 | 80% |
| 化学 | 50 | 27 | 54% | 37 | 74% |
| 经济学 | 50 | 50 | 100% | 50 | 100% |
| 物理治疗 | 64 | 63 | 98% | 63 | 98% |
| 视光学 | 50 | 45 | 90% | 49 | 98% |
| 药学科学 | 50 | 36 | 72% | 32 | 64% |
| 教育 | 100 | 57 | 57% | 75 | 75% |
| 商业管理 | 50 | 41 | 82% | 42 | 84% |
| 营养与饮食 | 50 | 42 | 84% | 41 | 82% |
| 总计 | 1429 | 1140 | 79% | 1245 | 87% |
至关重要的是,强调建立全球标准以实现公平、透明和减少偏见。最后,人机协作是一个新兴领域,探索增强人类与AI之间协同的方法,特别是在创造性和决策过程中。这些研究方向将塑造AI的未来,使系统更加高效、准确、互动和伦理负责。
VI. 结论
从ChatGPT到DeepSeek AI的演变代表了对话式AI发展的重要里程碑。通过解决ChatGPT的局限性并引入创新功能,DeepSeek AI设定了性能、效率和伦理责任的新标准。我们的比较评估还突出了DeepSeek AI在多个领域的卓越表现。随着AI的不断发展,保持对透明性、公平性和负责任发展的关注是最大化其社会利益的关键。未来该领域的研究人员和开发者应探索提高上下文理解、减少偏见和优化AI效率以适应实际应用的技术。此外,可解释性和人机协作的进步将是使AI系统更可靠和有益的关键。本文探讨的改进和创新为未来的人工智能研究和进步指明了明确的方向。
参考文献
[1] Pranav Rajpurkar, Emma Chen, Oishi Banerjee, and Eric J Topol. Ai in health and medicine. Nature medicine, 28(1):31-38, 2022.
[2] Kevin B Johnson, Wei-Qi Wei, Dilhan Weeraratne, Mark E Frisse, Karl Misulis, Kyu Rhee, Juan Zhao, and Jane L Snowdon. Precision medicine, ai, and the future of personalized health care. Clinical and translational science, 14(1):86-93, 2021.
[3] Mohsen Soori, Behrooz Arezoo, and Roza Dastres. Artificial intelligence, machine learning and deep learning in advanced robotics, a review. Cognitive Robotics, 3:54-70, 2023.
[4] Hongmei He, John Gray, Angelo Cangelosi, Qinggang Meng, T Martin McGinnity, and Jörn Mehnen. The challenges and opportunities of human-centered ai for trustworthy robots and autonomous systems. IEEE Transactions on Cognitive and Developmental Systems, 14(4):1398-1412, 2021.
[5] Longbing Cao. Ai in finance: challenges, techniques, and opportunities. ACM Computing Surveys (CSUR), 55(3):1-38, 2022.
[6] Arash Bahramnirzaee. A comparative survey of artificial intelligence applications in finance: artificial neural networks, expert system and hybrid intelligent systems. Neural Computing and Applications, 19(8):1165-1195, 2010.
[7] MZ Naser and Amir H Alavi. Error metrics and performance fitness indicators for artificial intelligence and machine learning in engineering and sciences. Architecture, Structures and Construction, 3(4):499-517, 2023.
[8] Nurullah Yüksel, Hüseyin Rıza Börklü, Hüseyin Kürşad Sezer, and Olcay Ersel Canyurt. Review of artificial intelligence applications in engineering design perspective. Engineering Applications of Artificial Intelligence, 118:105697, 2023.
[9] Ramanpreet Kaur, Dušan Gabrijelčić, and Tomaž Klobučar. Artificial intelligence for cybersecurity: Literature review and future research directions. Information Fusion, 97:101804, 2023.
[10] Haru Hong Khanh and Alex Khang. The role of artificial intelligence in blockchain applications. In Reinventing Manufacturing and Business Processes through Artificial Intelligence, pages 19-38. CRC Press, 2021.
[11] A Subeesh and CR Mehta. Automation and digitization of agriculture using artificial intelligence and internet of things. Artificial Intelligence in Agriculture, 5:278-291, 2021.
[12] Kirtan Jha, Aalep Doshi, Poojan Patel, and Manan Shah. A comprehensive review on automation in agriculture using artificial intelligence. Artificial Intelligence in Agriculture, 2:1-12, 2019.
[13] Abhijit Guha, Dhruv Grewal, Prave K Kopalle, Michael Haenlein, Matthew J Schneider, Hyunseok Jung, Rida Moustafa, Dinesh R Hegde, and Gary Hawkins. How artificial intelligence will affect the future of retailing. Journal of Retailing, 97(1):28-41, 2021.
[14] Lasha Labadze, Maya Grigolia, and Lela Machaidze. Role of ai chatbots in education: systematic literature review. International Journal of Educational Technology in Higher Education, 20(1):56, 2023.
[15] Brady D Lund, Ting Wang, Nishith Reddy Mannuru, Bing Nie, Somipam Shimray, and Ziang Wang. Chatgpt and a new academic reality: Artificial intelligence-written research papers and the ethics of the large language models in scholarly publishing. Journal of the Association for Information Science and Technology, 74(5):570-581, 2023.
[16] Chandan K Sahu, Crystal Young, and Rahul Rai. Artificial intelligence (ai) in augmented reality (ar)-assisted manufacturing applications: a review. International journal of production research, 59(16):4903-4959, 2021.
[17] Bo-hu Li, Bao-cun Hou, Wen-tao Yu, Xiao-bing Lu, and Chun-wei Yang. Applications of artificial intelligence in intelligent manufacturing: a review. Frontiers of Information Technology & Electronic Engineering, 18(1):86-96, 2017.
[18] Giri Gandu Hallur, Sandeep Prabhu, and Avinash Aslekar. Entertainment in era of ai, big data & iot. Digital Entertainment: The Next Evolution in Service Sector, pages 87-109, 2021.
[19] Yen Li, Feng Yuan, and Jianye Liu. Smart city vr landscape planning and user virtual entertainment experience based on artificial intelligence. Entertainment Computing, 51:100743, 2024.
[20] Ida Merete Enbolm, Emmanuelil Papagiannidis, Patrick Mikalef, and John Krogstie. Artificial intelligence and business value: A literature review. Information Systems Frontiers, 24(5):1709-1734, 2022.
[21] Ming-Hui Huang and Roland T Rust. A strategic framework for artificial intelligence in marketing. Journal of the academy of marketing science, 49:30−50,202149: 30-50,202149:30−50,2021.
[22] Mathias-Felipe de Lima-Santos and Wilson Ceron. Artificial intelligence in news media: current perceptions and future outlook. Journalism and media, 3(1):13-26, 2021.
[23] Fabia Joscote, Adriana Gonçalves, and Claudia Quadros. Artificial intelligence in journalism: A ten-year retrospective of scientific articles (2014-2023). Journalism and Media, 5(3):873-891, 2024.
[24] Fei-Yue Wang, Yilun Lin, Petros A Ioannou, Ljubo Vlacic, Xiaoming Liu, Azim Eskandarian, Yisheng Lv, Xiaoxiang Na, David Cebon, Jiaqi Ma, et al. Transportation 5.0: The dao to safe, secure, and sustainable intelligent transportation systems. IEEE Transactions on Intelligent Transportation Systems, 24(10):10262-10278, 2023.
[25] Rusul Abduljabbar, Hussein Dia, Sohani Liyanage, and Saeed Asadi Bagloee. Applications of artificial intelligence in transport: An overview. Sustainability, 11(1):189, 2019.
[26] Daniel W Otter, Julian R Medina, and Jugal K Kalita. A survey of the usages of deep learning for natural language processing. IEEE transactions on neural networks and learning systems, 32(2):604-624, 2020.
[27] Hobson Lane and Maria Dyshel. Natural language processing in action. Simon and Schuster, 2025.
[28] Joseph Weizenbaum. Eliza-a computer program for the study of natural language communication between man and machine. Communications of the ACM, 9(1):36-45, 1966.
[29] Terry Winograd. Procedures as a representation for data in a computer program for understanding natural language. Technical Report AIM-235, MIT Artificial Intelligence Laboratory, 1971.
[30] Güven Güzeldere and Stefano Franchi. Dialogues with colorful “personalities” of early ai. Stanford Humanities Review, 4(2):161-169, 1995.
[31] John Foderaro. Lisp: introduction. Communications of the ACM, 34(9):27, 1991.
[32] Christiane Fellbaum. WordNet: An electronic lexical database. MIT press, 1998.
[33] Lawrence Rabiner and Biinghwang Juang. An introduction to hidden markov models. IEEE ASSP Magazine, 3(1):4-16, 1986.
[34] Thomas K Landauer, Peter W Foltz, and Darrell Laham. An introduction to latent semantic analysis. Discourse processes, 25(2-3):259-284, 1998.
[35] Dan Jurafsky. Speech & language processing. Pearson Education India, 2000.
[36] Kai Han, An Xiao, Enhua Wu, Jianyuan Guo, Chunjing Xu, and Yunhe Wang. Transformer in transformer. Advances in Neural Information Processing Systems, 34:15908-15919, 2021.
[37] Salman Khan, Muzammal Naszer, Munawar Hayat, Syed Waqas Zamir, Fahad Shahbaz Khan, and Mubarak Shah. Transformers in vision: A survey. ACM computing surveys (CSUR), 54(10s):1-41, 2022.
[38] Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rauh, Rémi Louf, Morgan Funtowicz, et al. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations, pages 38-45, 2020.
[39] Anthony Gillioz, Jacky Casas, Elena Mugellini, and Omar Abou Khaled. Overview of the transformer-based models for nlp tasks. In 2020 15th Conference on computer science and information systems (FedCSIS), pages 179-183. IEEE, 2020.
[40] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Alernan, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
[41] Luciano Floridi and Massimo Chiriatti. Gpt-3: Its nature, scope, limits, and consequences. Minds and Machines, 30:681-694, 2020.
[42] Xiao Liu, Yanan Zheng, Zhengxiao Du, Ming Ding, Yujie Qian, Zhilin Yang, and Jie Tang. Gpt understands, too. AI Open, 5:208-215, 2024.
[43] A Vaswani. Attention is all you need. Advances in Neural Information Processing Systems, 2017.
[44] Sneha Chaudhari, Varun Mithal, Gungor Polatkan, and Rohan Ramanath. An attentive survey of attention models. ACM Transactions on Intelligent Systems and Technology (TIST), 12(5):1-32, 2021.
[45] Nanyi Fei, Zhiwu Lu, Yizhao Gao, Guoxing Yang, Yuqi Huo, Jingyuan Wen, Haoyu Lu, Ruihua Song, Xin Gao, Tao Xiang, et al. Towards artificial general intelligence via a multimodal foundation model. Nature Communications, 13(1):3094, 2022.
[46] Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 1(2):3, 2022.
[47] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877-1901, 2020.
[48] Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437, 2024.
[49] Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, et al. A survey on evaluation of large language models. ACM transactions on intelligent systems and technology, 15(3):1-45, 2024.
[50] Zijing Liang, Yanjie Xu, Yifan Hong, Penghui Shang, Qi Wang, Qiang Fu, and Ke Liu. A survey of multimodel large language models. In Proceedings of the 3rd International Conference on Computer, Artificial Intelligence and Control Engineering, pages 405-409, 2024.
[51] Vijay Badrinarayanan, Alex Kendall, and Roberto Cipolla. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE transactions on pattern analysis and machine intelligence, 39(12):2481-2495, 2017.
[52] Shane Griffith, Kaushik Subramanian, Jonathan Scholz, Charles L Isbell, and Andrea L Thomaz. Policy shaping: Integrating human feedback with reinforcement learning. Advances in neural information processing systems, 26, 2013.
[53] Alex Sherstinsky. Fundamentals of recurrent neural network (rnn) and long short-term memory (lstm) network. Physica D: Nonlinear Phenomena, 404:132306, 2020.
[54] Sepp Hochreiter. The vanishing gradient problem during learning recurrent neural nets and problem solutions. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 6(02):107-116, 1998.
[55] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre-training. Technical report, OpenAI, San Francisco, CA, USA, 2018.
[56] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
[57] Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and S Yu Philip. A comprehensive survey on graph neural networks. IEEE transactions on neural networks and learning systems, 32(1):4-24, 2020.
[58] Adam Santoro, Sergey Bartunov, Matthew Botvinick, Daan Wierstra, and Timothy Lillicrap. Meta-learning with memory-augmented neural networks. In International conference on machine learning, pages 18421850. PMLR, 2016.
[59] Jianping Gou, Baosheng Yu, Stephen J Maybank, and Dacheng Tao. Knowledge distillation: A survey. International Journal of Computer Vision, 129(6):1789-1819, 2021.
[60] Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024.
[61] Sajid Ali, Tamer Abahmed, Shaker El-Sappagh, Khan Muhammad, Jose M Alonso-Moral, Roberto Confalonieri, Riccardo Guidotti, Javier Del Ser, Natalia Díaz-Rodríguez, and Francisco Herrera. Explainable artificial intelligence (xai): What we know and what is left to attain trustworthy artificial intelligence. Information fusion, 99:101805, 2023.
[62] Rudresh Dwivedi, Devam Dave, Het Naik, Smiti Singhal, Rana Omer, Pankesh Patel, Bin Qian, Zhenyu Wen, Tejal Shah, Graham Morgan, et al. Explainable ai (xai): Core ideas, techniques, and solutions. ACM Computing Surveys, 55(9):1-33, 2023.
[63] Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions. Advances in neural information processing systems, 30, 2017.
[64] Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. “Why should i trust you?” explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pages 1135-1144, 2016.
[65] Martin Abadi, Andy Chu, Ian Goodfellow, H Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang. Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC conference on computer and communications security, pages 308-318, 2016.
[66] Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication-efficient learning of deep networks from decentralized data. In Artificial intelligence and statistics, pages 1273-1282. PMLR, 2017.
参考论文:https://arxiv.org/pdf/2504.03219

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 29
29 0
0- 0



 已为社区贡献79条内容
已为社区贡献79条内容

所有评论(0)