
如何在AMD MI300X 服务器上部署 DeepSeek R1模型?
这些改进将进一步释放MI300X的潜力,为AI推理带来更强大的性能。目前,企业除了可以从AMD官方预定MI300X以外,还可以通过云平台来使用MI300X,例如DigitalOcean 最新推出的基于MI300X的GPU 裸金属服务器(具体详情可咨询。MI300X的高内存带宽和容量优势,使Chain of Thought(CoT)推理能更快速、高效地访问大内存,支持实际应用中更长序列的处理。用户通
DeepSeek-R1凭借其深度推理能力备受关注,在语言模型性能基准测试中可与顶级闭源模型匹敌。
AMD Instinct MI300X GPU可在单节点上高效运行新发布的DeepSeek-R1和V3模型。
用户通过SGLang优化,将MI300X的性能提升至初始版本的4倍,且更多优化将在未来几周内集成到开源代码中。
MI300X的高内存带宽和容量优势,使Chain of Thought(CoT)推理能更快速、高效地访问大内存,支持实际应用中更长序列的处理。
在本博文中,我们将探讨DeepSeek-R1如何在AMD Instinct™ MI300X GPU上实现卓越性能,并与H200进行性能对比。借助MI300X,用户可在单节点上高效部署DeepSeek-R1和V3模型。仅通过两周的SGLang优化,推理速度已提升高达4倍,确保了高效扩展、更低延迟及优化吞吐量。MI300X的高带宽内存(HBM)和强大算力可处理复杂AI任务,支持更长序列和高要求推理。AMD与SGLang社区持续推进优化,包括融合MoE内核、MLA内核融合及推测性解码,使MI300X的AI推理体验更加强大。
目前,企业除了可以从AMD官方预定MI300X以外,还可以通过云平台来使用MI300X,例如DigitalOcean 最新推出的基于MI300X的GPU 裸金属服务器(具体详情可咨询卓普云)。
DeepSeek模型部署挑战
尽管大规模部署需求日益迫切,但实现最优推理性能仍面临技术挑战。DeepSeek-R1是一个超大规模模型(参数量超640 GB),即使以FP8精度训练,也无法在8卡NVIDIA H100单节点中部署。此外,其多头潜在注意力(MLA)和专家混合(MoE)架构需要高度优化的内核以实现高效扩展和定制化优化。最后,适配支持块量化FP8 GEMM内核对最大化吞吐量和性能至关重要,因此内核调优是高效执行的关键。
在MI300X上使用SGLang
SGLang是面向LLM和VLM的高性能开源推理框架,提供高效运行时、广泛模型支持及活跃社区,正被行业广泛采用。AMD作为SGLang的核心贡献者,与社区紧密合作,优化AMD Instinct GPU上的LLM推理。为提供最佳MI300X开箱即用体验,SGLang已发布预构建Docker镜像和文件,既可用于生产部署,也可作为定制化用例的起点。
基准测试关键结论
以下是SGLang在Instinct MI300X上的推理基准测试要点:
- 仅两周内,通过优化FP8精度的6710亿参数DeepSeek-R1模型(非精简版),推理性能提升高达4倍,所有优化已集成到SGLang(图1)。
- DeepSeek-R1和V3模型在MI300X上经过高度优化,充分利用其强大算力和大容量HBM内存。
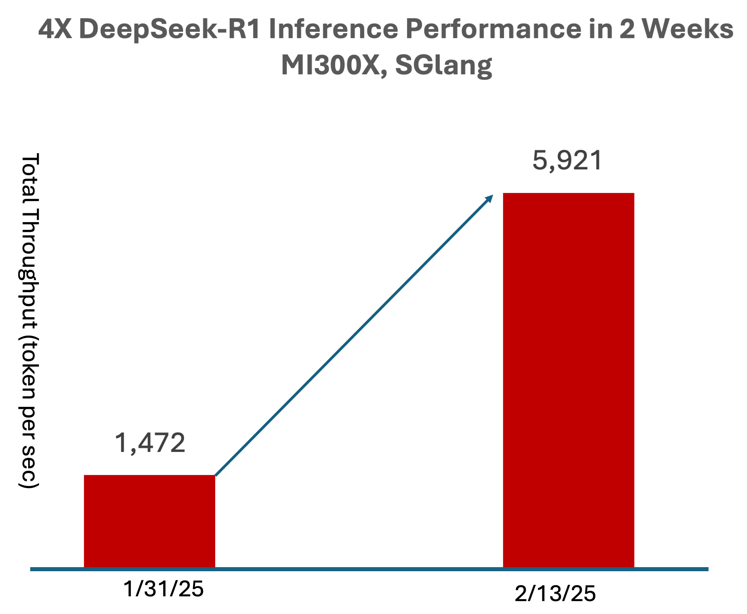
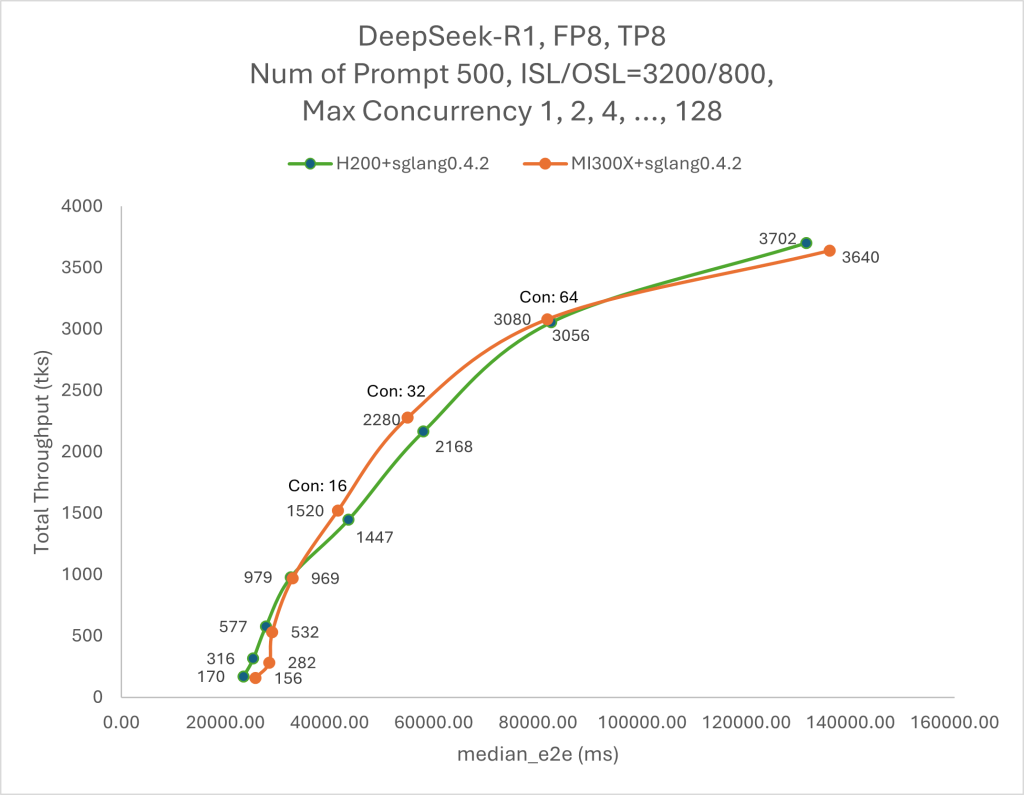
对于需低延迟的在线推理场景(如聊天应用),单节点8卡MI300X在32并发请求下仍可保持每输出token时间(TPOT)低于50ms。离线任务则可通过更大并发设置提升吞吐量。
图2显示,当最大并发从1增至32时,性能主要受限于内存;而32至64并发区间则转为计算瓶颈。
如何复现基准测试
以下是MI300X和H200的测试步骤(假设模型已下载):
在MI300X上
1、下载Docker镜像:
docker pull rocm/sglang-staging:20250212
2、运行容器:
docker run -d -it --ipc=host --network=host --privileged --device=/dev/kfd --device=/dev/dri --device=/dev/mem --group-add render --security-opt seccomp=unconfined -v /home:/workspace rocm/sglang-staging:20250212
docker exec -it <container_id> bash
3、启动推理服务:
HSA_NO_SCRATCH_RECLAIM=1 python3 -m sglang.launch_server --model /workspace/models/DeepSeek-R1/ --tp 8 --trust-remote-code
4、运行客户端请求:
concurrency_values=(128 64 32 16 8 4 2 1)
for concurrency in "${concurrency_values[@]}";do
python3 -m sglang.bench_serving \
--dataset-name random \
--random-range-ratio 1 \
--num-prompt 500 \
--random-input 3200 \
--random-output 800 \
--max-concurrency "${concurrency}"
done
在H200上
1、下载Docker镜像:
docker pull lmsysorg/sglang:v0.4.2.post3-cu125
2、运行容器:
docker run -d -it --rm --gpus all --shm-size 32g -p 30000:30000 -v /home:/workspace --ipc=host lmsysorg/sglang:v0.4.2.post4-cu125
docker exec -it <container_id> bash
3、使用与MI300X相同的命令运行基准测试:
HSA_NO_SCRATCH_RECLAIM=1 python3 -m sglang.launch_server --model /workspace/models/DeepSeek-R1/ --tp 8 --trust-remote-code
完成以上步骤后,就可以在MI300X服务器上实时运行DeepSeek-R1的聊天应用了。
未来方向
未来AMD与SGLang将推出更多优化,包括:
- 融合MoE内核优化
- MLA内核融合
- 集群通信增强
- 数据并行(DP)与专家并行(EP)
- 前向计算与解码分离
- 投机性解码
这些改进将进一步释放MI300X的潜力,为AI推理带来更强大的性能。另外,如果希望机遇MI300X部署进行AI产品开发,欢迎了解DigitalOcean GPU Droplet服务器,具体详情可咨询DigitalOcean中国区独家战略合作伙伴卓普云。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 35
35 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)