DeepSeek-R1-14B再次被微调(代码生成):DeepCoder-14B-Preview
DeepCoder-14B-Preview 是一种专为代码推理设计的大型语言模型,它基于 DeepSeek-R1-Distilled-Qwen-14B 进行了微调,并利用分布式强化学习(RL)扩展到长上下文长度。该模型在 LiveCodeBench v5(2024 年 8 月 1 日至 2025 年 2 月 1 日)上实现了 60.6% 的 Pass@1 准确率,相较于基础模型(53%)提高了 8
DeepCoder-14B-Preview:代码推理大型语言模型
引言
在代码生成和推理领域,大型语言模型(LLM)的应用越来越广泛。一个名为 DeepCoder-14B-Preview 的模型,它在代码推理方面表现出色,并且在长上下文处理方面有显著的提升。
模型概述
DeepCoder-14B-Preview 是一种专为代码推理设计的大型语言模型,它基于 DeepSeek-R1-Distilled-Qwen-14B 进行了微调,并利用分布式强化学习(RL)扩展到长上下文长度。该模型在 LiveCodeBench v5(2024 年 8 月 1 日至 2025 年 2 月 1 日)上实现了 60.6% 的 Pass@1 准确率,相较于基础模型(53%)提高了 8%,并且在仅有 14B 参数的情况下,性能与 OpenAI 的 o3-mini 相当。
训练数据
训练数据集由大约 24,000 个独特的编程问题-测试对组成,这些数据来源于:
-
Taco-Verified
-
PrimeIntellect SYNTHETIC-1
-
LiveCodeBench v5(2023 年 5 月 1 日至 2024 年 7 月 31 日)
训练方法
训练方法基于改进版的 GRPO(GRPO+)和迭代上下文长度扩展,这些方法在 DeepScaleR 中首次引入。他们对原始 GRPO 算法进行了以下增强:
-
离线难度过滤:与 DAPO 的在线动态采样不同,他们对一部分编程问题进行离线难度过滤,以确保训练数据集的难度范围合适。
-
无熵损失:他们发现包含熵损失项会导致训练不稳定,因此完全移除了熵损失。
-
无 KL 损失:移除 KL 损失可以防止 LLM 停留在原始监督微调(SFT)模型的信任区域内,同时避免计算参考策略的对数概率,从而加速训练。
-
过长过滤(来自 DAPO):为了保持长上下文推理能力,他们对截断序列的损失进行掩蔽。这使得 DeepCoder 能够泛化到 64K 上下文推理,尽管它是在 32K 上下文中训练的。
-
提高上限(来自 DAPO):通过增加 GRPO/PPO 代理损失的上限,鼓励更多的探索并使熵更加稳定。
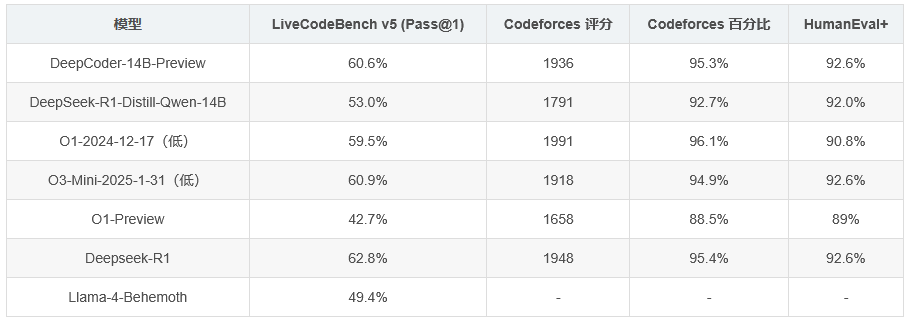
性能评估
他们在多个编程基准测试中评估了 DeepCoder-14B-Preview,包括 LiveCodeBench(LCBv5)、Codeforces 和 HumanEval+。以下是该模型与其他模型的性能对比:
| 模型 | LiveCodeBench v5 (Pass@1) | Codeforces 评分 | Codeforces 百分比 | HumanEval+ |
|---|---|---|---|---|
| DeepCoder-14B-Preview | 60.6% | 1936 | 95.3% | 92.6% |
| DeepSeek-R1-Distill-Qwen-14B | 53.0% | 1791 | 92.7% | 92.0% |
| O1-2024-12-17(低) | 59.5% | 1991 | 96.1% | 90.8% |
| O3-Mini-2025-1-31(低) | 60.9% | 1918 | 94.9% | 92.6% |
| O1-Preview | 42.7% | 1658 | 88.5% | 89% |
| Deepseek-R1 | 62.8% | 1948 | 95.4% | 92.6% |
| Llama-4-Behemoth | 49.4% | - | - | - |
服务与使用建议
DeepCoder-14B-Preview 可以使用以下高性能推理系统进行服务:
-
vLLM
-
Hugging Face Text Generation Inference (TGI)
-
SGLang
-
TensorRT-LLM
所有这些系统都支持 OpenAI Chat Completions API 格式。他们的使用建议如下:
-
避免添加系统提示;所有指令都应包含在用户提示中。
-
设置
temperature = 0.6。 -
设置
top_p = 0.95。 -
为了获得最佳性能,将
max_tokens设置为至少 64000。
# 示例代码:如何使用 DeepCoder-14B-Preview
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "agentica-org/DeepCoder-14B-Preview"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
prompt = "请生成一个计算斐波那契数列的 Python 函数。"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(
inputs.input_ids,
temperature=0.6,
top_p=0.95,
max_length=64000
)
print(tokenizer.decode(outputs[0]))
许可
本项目在 MIT 许可证 下发布,反映了他们对开放和可访问的 AI 开发的承诺。
最后
他们的训练实验由他们大幅修改的 Verl 开源后训练库提供支持。他们的模型是在 DeepSeek-R1-Distill-Qwen-14B 的基础上训练的。他们的工作是在加州大学伯克利分校的 Sky Computing Lab 和 Berkeley AI Research 进行的。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 23
23 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)