IDM论文研读笔记:隐式扩散模型的理论解构与AI辅助精读
本文记录了作者在学习“连续超分辨率隐式扩散模型”这篇论文时的思考过程与笔记,同时总结了作者在使用 DeepSeek 方面的经验、技巧与心得。
1. 论文基本信息
- 论文标题:Implicit Diffusion Models for Continuous Super-Resolution
- 作者/团队:Sicheng Gao, Xuhui Liu, Bohan Zeng, Sheng Xu, Yanjing Li, Xiaoyan Luo…
- 发表会议/期刊:CVPR-2023
- 论文链接:CVPR 2023 Open Access Repository
- 源代码:GitHub - Ree1s/IDM
2. 相关概念

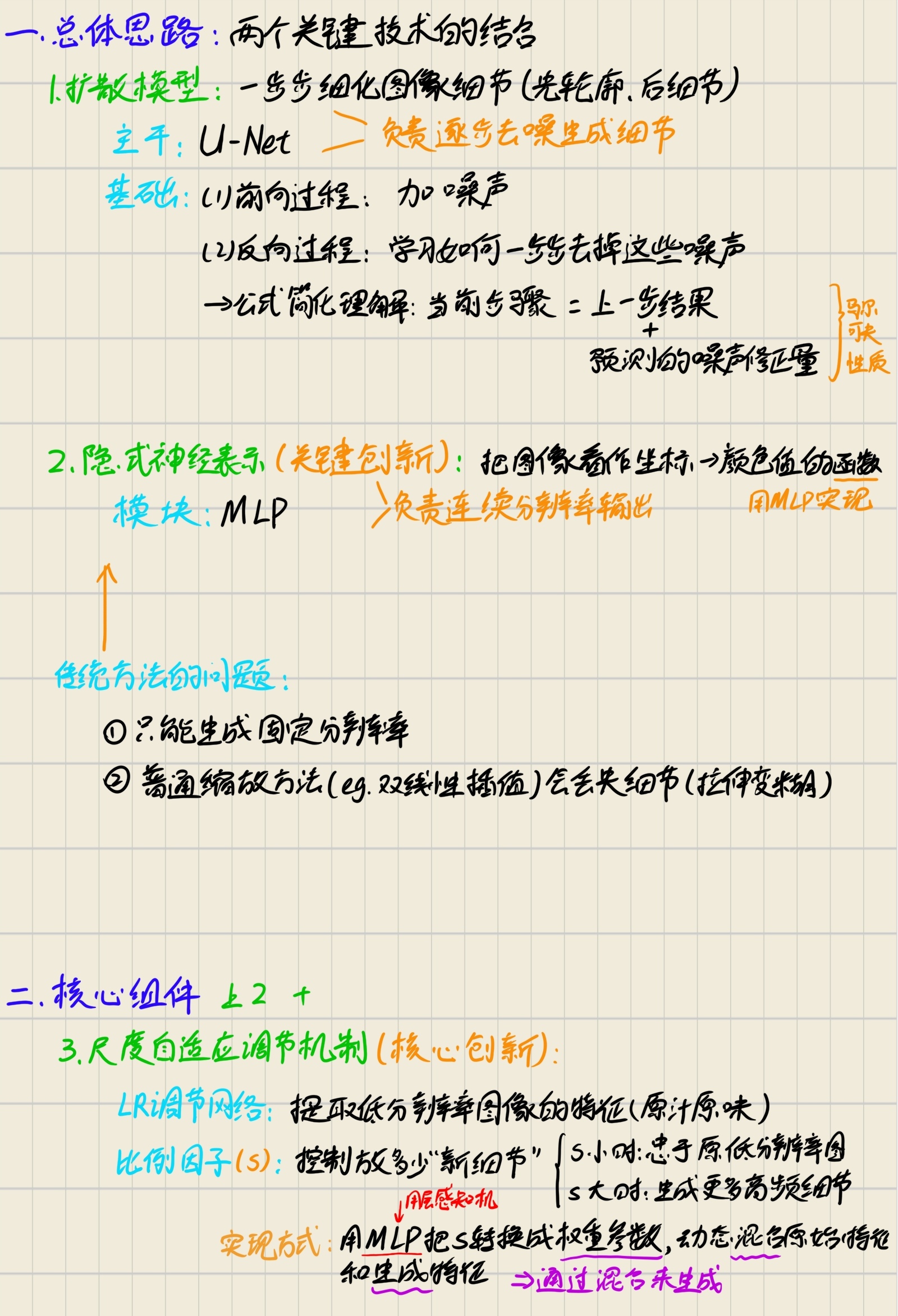
3. 总体思路 & 核心组件
4. 模型架构
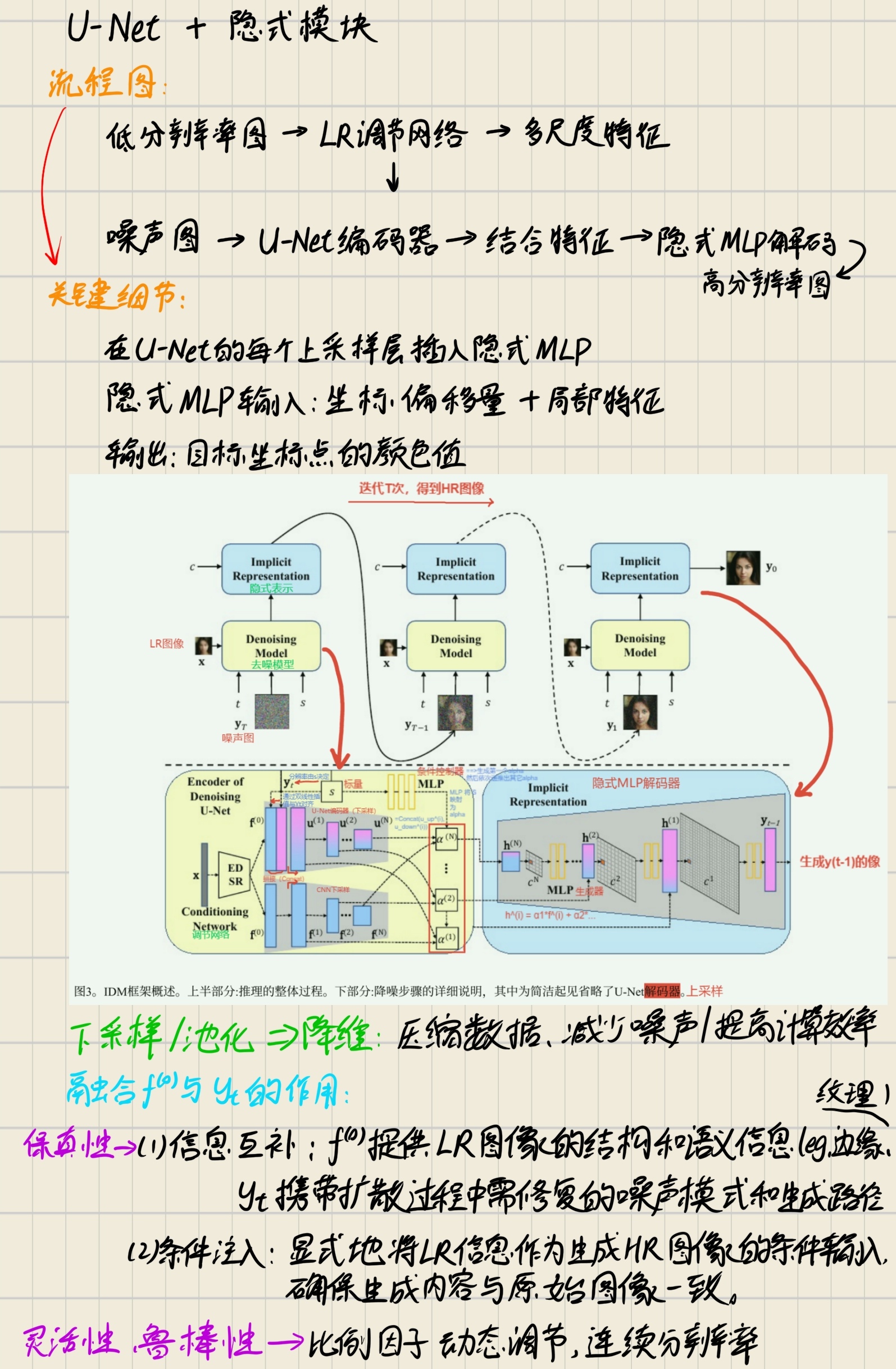
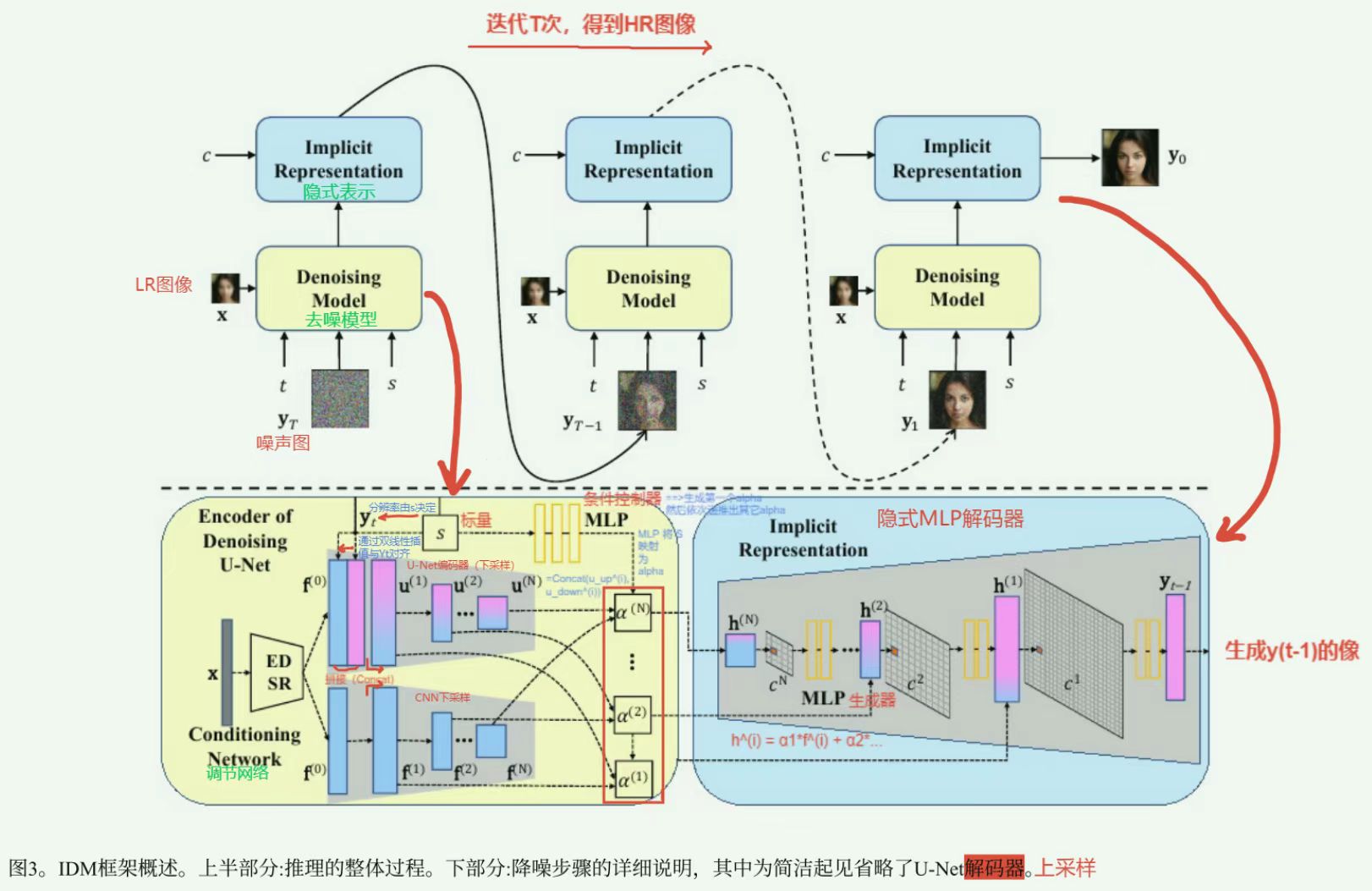
5. 理论基础
5.1 前向扩散过程的联合分布


5.2 任意时刻的噪声图像

5.3 反向去噪过程

5.4 马尔可夫链

6. 实验
6.1 实现细节
6.1.1 数据集
(1)训练和评估用的是不同的数据集,具体可从 run.sh 文件中对指令进行修改:
# 需要更改的参数:
# · GPU数量: CUDA_VISIBLE_DEVICES、--nproc_per_node(注意自己可用的GPU数量)
# · 配置文件(-c): ?.json(注意对应数据集)
# · 恢复训练(-r): checkpoints/df2k?(注意对应数据集)
# 原指令更改:python -m torch.distributed.launch ——> torchrun
# train
CUDA_VISIBLE_DEVICES=0,1,2 torchrun --nproc_per_node=3 --master_port=12392 idm_main.py -p train -c config/[训练使用的数据集] -r checkpoints/[对应检查点]
# val
CUDA_VISIBLE_DEVICES=0 torchrun --nproc_per_node=1 --master_port=12392 idm_main.py -p val -c config/[评估使用的数据集] -r checkpoints/[对应检查点]
# 训练和评估时使用的数据集可以不一样(2)概念解释:
SR3(2022,TPAMI):一种通过迭代细化来实现图像超分辨率的基于扩散模型的方法,但仅支持固定放大倍数。
GLEAN(2021,CVPR):基于隐式生成库的高倍率图像超分辨率。
LSUN 数据集(2015,arXiv):专为计算机视觉研究设计的大规模场景理解数据集。
SOTA:(State-of-the-Art)指的是当前最先进的技术或模型。
6.1.2 训练细节
【原文翻译】
“我们以端到端的方式训练IDM模型。设定一个里程碑为100万次迭代,在此阶段训练采用固定的降采样比例 M×。达到里程碑后,继续训练50万次迭代,此时高分辨率(HR)图像根据均匀分布 U(1,M) 随机调整大小。遵循原始 DDPM 的设置,初始阶段使用 Adam 优化器,固定学习率为 1e-4;后续阶段学习率调整为 2e-5。所有实验均采用 0.2 的 dropout 率,并使用两块 24GB NVIDIA RTX A5000 GPU 进行训练。”
【1M迭代】即100万次(1 million)训练迭代,表示模型在训练过程中完成了一百万次参数更新。
【里程碑(Milestone)】指训练过程中的关键节点,通常在此节点调整训练策略。
6.1.2.1 分阶段训练策略
(1)初始阶段(1M迭代前):
-
固定降采样:确保模型在固定尺度下学习基础特征,避免多尺度干扰。
-
较高学习率(1e-4):加速初期收敛,快速逼近较优解。
(2)后续阶段(1M迭代后):
-
随机尺度增强:HR图像在 [1,M] 范围内随机缩放,模拟实际场景中多分辨率输入,增强模型泛化性。
-
较低学习率(2e-5):避免后期震荡,精细调整模型参数。
6.1.2.2 其他训练细节
(1)优化器选择:Adam优化器因其自适应学习率特性,广泛用于扩散模型训练。
(2)Dropout率(0.2):在训练中随机丢弃部分神经元,防止过拟合。
(3)硬件配置:使用两块24GB显存的NVIDIA RTX A5000 GPU,确保大规模数据和高分辨率图像的高效训练。
6.2 定性比较
| 任务类型 | 对比方法 | 数据集 | 对比结果 |
|---|---|---|---|
| 人脸 SR | SR3 | CelebA-HQ | SR3 和 IDM 都可以提高生成输出的多样性,但 SR3 丢失了许多人脸属性,IDM 则保留了身份和高保真的面部细节。 |
| 自然图像 SR | GLEAN | LSUN | 虽然 GLEAN 可以产生逼真的 SR 效果,但它在一些细节纹理上的表现并不好。而 IDM 在重建它们方面更有效,并表现出出色的精细细节。 |
6.3 定量比较
| 任务类型 | 对比方法 | 数据集 | IDM 结果 | 性能提升 |
|---|---|---|---|---|
| 人脸 SR |
PULSE FSRGAN Regression SR3 |
CelebA-HQ |
PSNR↑:24.01 dB SSIM↑:0.71 Consistency↓:2.14 |
+0.97 dB +0.06 -0.54(文章与表格似乎不太一致) |
| 自然图像 SR |
PULSE ESRGAN GLEAN |
LSUN (以 cats 为例) |
PSNR↑:21.52 dB LPIPS↓:0.3131 |
+0.60 dB -0.0084 |
注:↑ 表示数值越高越好,↓ 表示数值越低越好。
概念解释:
PULSE(2020,CVPR):一种自我监督的基于生成式对抗网络(GAN)的图像超分辨率模型。
FSRNet(2018,CVPR):专注于人脸超分辨率,结合人脸先验(如关键点或解析图)指导生成,通常基于卷积网络。
FSRGAN:在FSRNet基础上引入生成对抗网络(GAN),提升生成图像的细节和感知质量。
Regression:基于回归的方法,直接学习从低分辨率(LR)到高分辨率(HR)的像素级映射,通常以均方误差(MSE)或PSNR为优化目标。重建图像保真度高。
ESRGAN(2018,ECCVW):基于GAN的超分辨率模型,生成细节丰富但存在伪影。
GLEAN(2021,CVPR):结合StyleGAN先验的超分辨率模型,依赖外部生成库。
CelebA-HQ 数据集:一个高质量的人脸图像数据集,包含30,000张分辨率为1024x1024的图像。
6.4 在通用场景数据集上的比较
| 任务类型 | 对比方法 | 数据集 | IDM 结果 | 性能提升 | 总结 |
|---|---|---|---|---|---|
| 通用场景 SR |
(1)基于gan的模型:ESRGAN 、RankSRGAN (2)基于流的模型:SRFlow 、HCFlow (3)混合生成模型:HCFlow++、LAR-SR |
DIV2K + Flicker2K |
PSNR↑:27.59 dB SSIM↑:0.78 |
+0.50 dB +0.01 |
IDM显著优于其他生成方法。 即使使用较少的训练数据,IDM在这两个指标上仍然优于现有技术。 |
| 无 | DIV2K |
PSNR↑:27.10 dB SSIM↑:0.77 |
+0.01 dB +0.00 |
注:↑ 表示数值越高越好,↓ 表示数值越低越好。
概念解释:
RankSRGAN(2019,ICCV):一种基于生成对抗网络(GAN)的图像超分辨率方法,平衡了保真度与感知质量。
SRFlow(2020,ECCV):基于归一化流(Normalizing Flow)的生成模型,样本质量次于GAN。
HCFlow(2021,ICCV):基于归一化流的生成模型,生成图像多样性高,支持精确概率密度估计。
HCFlow++:相比HCFlow,生成速度更快,细节更丰富。
LAR-SR(2022,CVPR):结合局部自回归模型和超分辨率任务,逐像素生成高清图像。生成细节自然,适用于复杂纹理场景。
Flicker2K 数据集:一个高质量数据集,包含2650张2K分辨率的图像。
6.5 连续 SR 比较
| 任务类型 | 对比方法 | 数据集 | IDM 结果 | 性能提升 | 总结 |
|---|---|---|---|---|---|
| 范围内尺度 |
LIIF SR3 |
CelebA-HQ |
PSNR↑:23.34 dB LPIPS↓:0.0736 |
-4.18 dB -0.0942 |
在范围内,尽管 LIIF 有更高的 PSNR,但 IDM 在 LPIPS 方面表现出更好的性能,这表明 IDM 生成的图像与人类感知更加一致。 在范围外的各个尺度,IDM在 PSNR 和 LPIPS 方面都优于其他方法。 |
| 超范围尺度 |
PSNR↑:23.46 dB LPIPS↓:0.1171 |
+0.49 dB -0.1075 |
注:↑ 表示数值越高越好,↓ 表示数值越低越好。
概念解释:
LIIF(2021,CVPR):基于隐式神经表示的连续超分辨率方法,但易产生过平滑。
6.6 消融研究
| 研究对象 | 研究方法 | 结论 |
|---|---|---|
| 比例因子 s 的重要性 | 用其他特定放大倍数的值来赋值s |
比例因子倾向于在大倍率 SR 上为生成的特征分配更多的权重。 该比例因子有效地动态调整了 LR 条件与生成细节之间的比例。 |
| LR 调节网络的影响 |
将 IDM 中的尺度自适应调节网络替换为两种类型的调节机制来构建两个比较模型: (1)通过 SR3 中的串联操作调节我们的模型——直接使用上采样的LR图像作为条件; (2)通过添加编码器来调节我们的模型—— EDSR 编码器编码的 LR 特征与原始高分辨率图像特征连接起来。 |
(1)往往会导致纹理模糊; (2)稍微缓解纹理模糊的问题,但在生成高保真细节(如眼睛和头发)方面仍然表现不佳。 最终结论:尺度自适应调节网络采用并行架构,为去噪模型提供多分辨率 LR 特征,以丰富纹理信息,其性能优于其他方法。 |
概念解释:
EDSR(2017,CVPRW):基于残差网络的回归方法,高 PSNR 但缺乏细节。
6.7 评价指标
| 指标 | 全称 | 意义 | 范围 |
|---|---|---|---|
| PSNR | Peak Signal-to-Noise Ratio | 衡量图像重建质量,值越高表示失真越小。 | 通常 20-50 dB |
| SSIM | Structural Similarity Index | 评估图像结构相似性(亮度、对比度、结构),值越接近1表示越接近真实图像。 | [0, 1] |
| LPIPS | Learned Perceptual Image Patch Similarity | 基于深度特征空间的感知相似性,值越低表示人类感知差异越小。 | [0, 1](通常<0.5) |
| Consistency | LR-SR Consistency | 低分辨率图像(LR)与降采样后超分辨率图像(SR)的均方误差(MSE),值越低表示一致性越高。 | ≥0,越小越好 |
7. DeepSeek 使用感受与经验总结
一个很不错的指导老师与交流对象!但前提是,你得会沟通。DeepSeek 让我实现了在不断地交流中比较深入地学习一篇论文,不仅让我学得更透彻了,也让我不再看论文就犯困。
7.1 提问技巧
7.1.1 角色扮演
说明你的背景,并提出希望对方以什么样的方式帮助你。

……

7.1.2 连串式反问
相当于对自己的困惑进行详细说明,也展示了自己的思考过程,从而让对方知道你的困惑点在哪?你可能把哪些东西搞混了?等等。
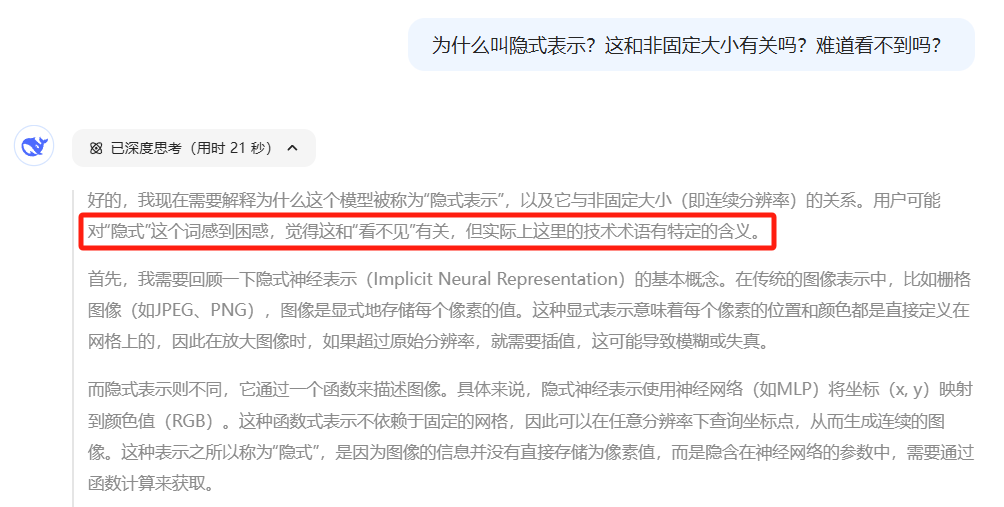
就和老师沟通是一样的,只有把自己的困惑说得越详细,对方才知道怎样才能更好地帮助你。如果只是简单地问什么是什么?我想不论是谁的回答,大概都跟百度百科差不多吧。
7.2 发现“新大陆”
可以在纸上或者平板上手写自己的推到过程与困惑点,发给 DeepSeek 后,它会像老师一样给你耐心地指导。

虽然它的图像识别也还没有到达很高的水平,但它能根据上下文以及你之前传的论文来分析推理你大概写的是什么过程,这就是它的魅力点呀!
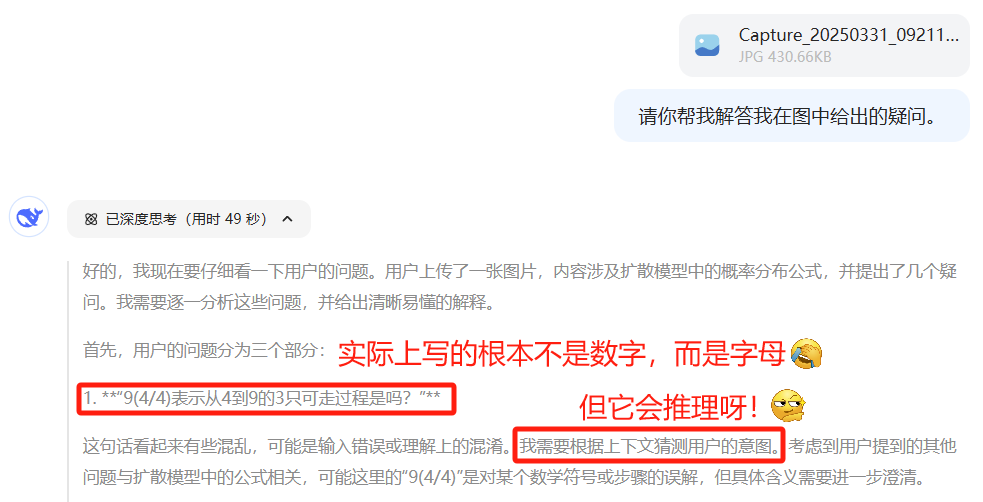
在我所试的几次,它推得还是可以的,而且对我的推导给出了评价,指出哪些是对的,哪些是错的,还会根据我的错误来推测我不了解或混淆的点是什么,从而对我进行指导。

……

7.3 你发现没?
不知道你有没有发现,DeepSeek 还会发小表情哦!



欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 49
49 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)