大模型部署工具 Ollama 使用指南:技巧与问题解决全攻略
硬件规划7B 模型需 8GB 内存,70B 模型需 32GB+。显存不足时优先选择低精度版本。安全第一避免将 Ollama 端口暴露公网,定期更新版本。模型选择根据需求选择(如DeepSeek适合代码生成,Qwen适合多语言)。
Ollama 是一个开源的本地大模型部署工具,旨在简化大型语言模型(LLM)的运行和管理。通过简单命令,用户可以在消费级设备上快速启动和运行开源模型(如 Llama、DeepSeek 等),无需复杂配置。
一、Ollama 是什么?
Ollama 是一个开源的本地大模型部署工具,旨在简化大型语言模型(LLM)的运行和管理。通过简单命令,用户可以在消费级设备上快速启动和运行开源模型(如 Llama、DeepSeek 等),无需复杂配置。它提供 OpenAI 兼容的 API,支持 GPU 加速,并允许自定义模型开发。
二、核心命令速查表
运行 ollama help 可查看所有命令,以下是高频命令总结:
|
命令 |
作用描述 |
|
|
启动 Ollama 服务(后台运行) |
|
|
通过 |
|
|
运行指定模型(如 |
|
|
列出所有已下载模型 |
|
|
查看正在运行的模型 |
|
|
删除指定模型(如 |
|
|
从注册表拉取模型(如 |
|
|
停止正在运行的模型 |
|
|
显示模型详细信息(如 |
三、模型存储路径优化
默认路径问题
- Windows:
C:\Users\<用户名>\.ollama - Linux/macOS:
~/.ollama - 问题:可能占用系统盘空间,尤其对小容量 SSD 用户不友好。
路径迁移方案
Windows
- 右键「此电脑」→ 属性 → 高级系统设置 → 环境变量。
- 新建系统变量
OLLAMA_MODELS,路径设为D:\ollama\models。
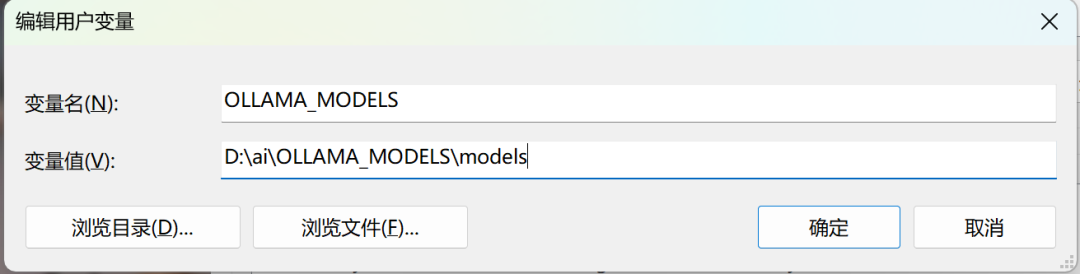
设置环境变量
- 重启电脑或终端后生效。
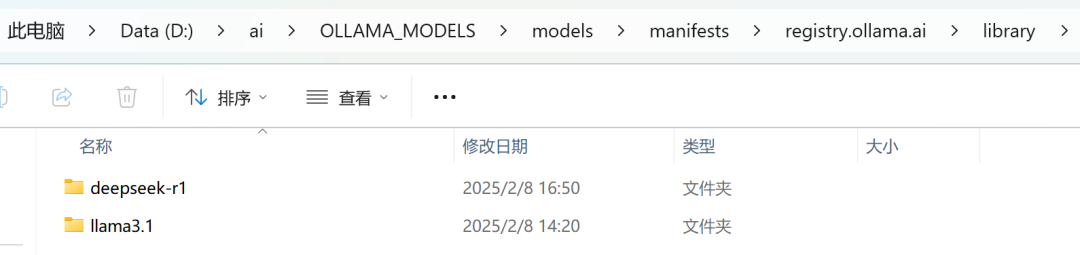
模型文件存放路径
Linux/macOS
echo 'export OLLAMA_MODELS=/path/to/your/models' >> ~/.bashrc # 或 ~/.zshrc
source ~/.bashrc # 重新加载配置
四、模型管理:从下载到优化
1. 模型下载
- 官方模型:
复制
ollama pull llama3 # 下载 Llama3 模型- 自定义模型:
准备模型文件(如 GGUF 格式,从 Hugging Face 下载)。。
图片
创建 Modelfile 配置模板(示例):
复制
name: mymodel
template: qwen
path: /path/to/your/model.q4_K_M.gguf构建模型:
复制
ollama create mymodel -f Modelfile2. 运行与交互
- 终端交互:
复制
ollama run --gpu mymodel # 启动 GPU 加速输入问题后按 Ctrl+D 提交,等待模型响应。
- API 调用:Ollama 内置 OpenAI 兼容 API,通过
http://localhost:11434访问:
复制
curl http://localhost:11434/v1/models # 查看模型列表
curl -X POST "http://localhost:11434/v1/completions" -H "Content-Type: application/json" -d '{"model":"llama3", "prompt":"你好"}'3. 性能监控与优化
- 显存不足:
选择轻量模型(如 deepseek:1.5b)。
尝试低精度版本(如 q4_K_M 或 q3_K_L)。
- 内存不足:
确保至少 8GB 内存(小模型)或 32GB+(大模型)。
使用 --verbose 参数监控资源消耗:
复制
ollama run deepseek-r1:70b --verbose- 输出示例:
复制
total duration: 12m1.056s # 总耗时
load duration: 1.810s # 模型加载时间
eval rate: 2.09 tokens/s # 生成速度五、常见问题与解决方案
1. 模型下载卡在 99%?
- 现象:下载进度停滞在最后阶段。
- 解决:
复制
Ctrl+C 取消下载 → 再次运行 `ollama pull <model>`
# 进度保留,后续速度可能恢复正常2. 模型无响应或崩溃
- 可能原因:
Modelfile 配置错误(如路径或模板参数)。
系统资源不足(内存/显存)。
- 排查步骤:
检查 Modelfile 中的 TEMPLATE 和 stop 参数是否正确。
降低模型复杂度或增加硬件资源。
使用 --verbose 日志定位问题。
3. 删除无用模型释放空间
- 命令:
复制
ollama rm modelname # 删除指定模型六、安全加固指南
1. 限制网络访问
- 默认风险:Ollama 默认监听
0.0.0.0:11434,可能暴露公网。 - 解决方案:
复制
# 仅允许本地访问
export OLLAMA_HOST=127.0.0.1:11434
# 或通过环境变量设置
OLLAMA_HOST=127.0.0.1:11434 ollama serve2. 关闭危险端口
- 若仅本地使用,可通过防火墙屏蔽
11434端口的外部访问。
3. 定期更新版本
- Ollama 定期修复安全漏洞,建议升级到最新版:
七、总结与建议
- 硬件规划:
7B 模型需 8GB 内存,70B 模型需 32GB+。
显存不足时优先选择低精度版本。
- 安全第一:
避免将 Ollama 端口暴露公网,定期更新版本。
- 模型选择:
根据需求选择(如 DeepSeek 适合代码生成,Qwen 适合多语言)。
零基础入门AI大模型
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
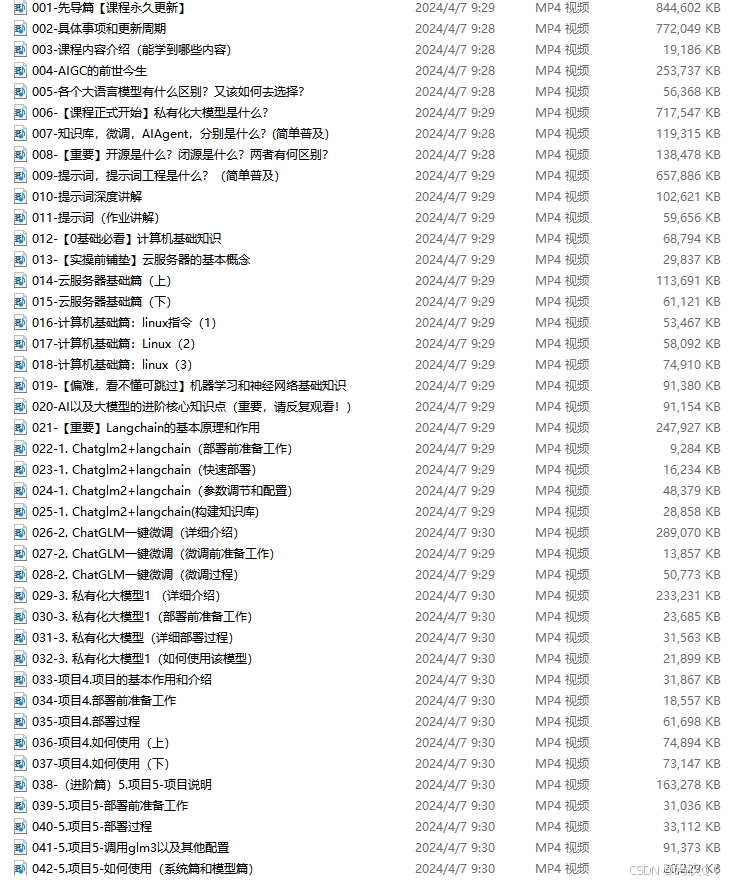
(都打包成一块的了,不能一一展开,总共300多集)
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。
4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。
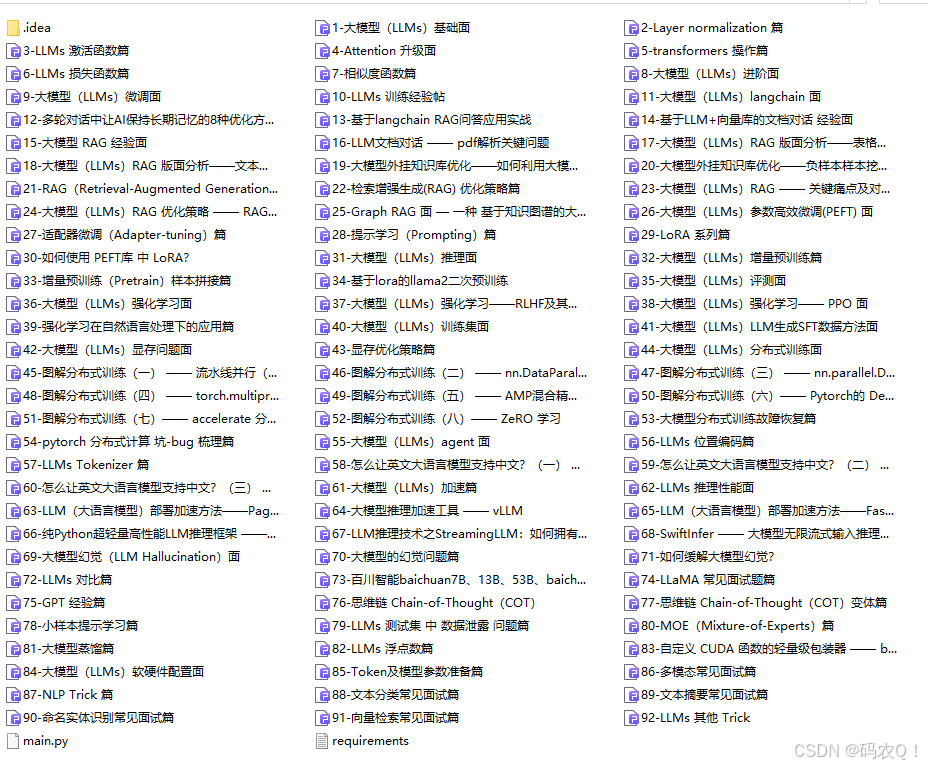
👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
5.免费获取(扫下方二v码即可100%领取)

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 23
23 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)