4.8日 实习日记
首先要在服务器中的一个docker中启动vllm服务启动成功使用测试脚本测试最大并发数lenlenlenlenlen这段代码是超哥写的测试代码。但是这段代码有一个问题,经过调试以及阅读博客,发现流式响应response对象中没有usage对象,没办法统计提问消耗的 token,回答消耗的 token,以及总共消耗的 token 数。,我在网上找到了这个帖子,里面说可以通过 tiktoken进行统计
测试vllm对千问32B的支持度:
首先要在服务器中的一个docker中启动vllm服务
vllm serve /models/qwq-32b --host 0.0.0.0 --port 80 --tensor-parallel-size 4 --gpu-memory-utilization 0.9 --max-num-seqs 128 --max-model-len 65536
启动成功
使用测试脚本测试最大并发数
import argparse
import multiprocessing
import time
from multiprocessing import Manager
from openai import OpenAI
from openai.types.chat.chat_completion import ChatCompletion
from openai.types.chat.chat_completion_chunk import ChatCompletionChunk
"""
paddler balancer \
--management-addr 127.0.0.1:8085 \
--reverseproxy-addr 0.0.0.0:8090
paddler agent \
--external-llamacpp-addr 0.0.0.0:8091 \
--local-llamacpp-addr 127.0.0.1:8091 \
--management-addr 127.0.0.1:8085
paddler agent \
--external-llamacpp-addr 0.0.0.0:8053 \
--local-llamacpp-addr 127.0.0.1:8053 \
--management-addr 127.0.0.1:8085
"""
model_name = "/models/qwq-32b"
# base_url = "http://10.20.25.250:8091"
base_url = "http://10.20.35.251:3003/v1"
api_key = "sansec_local_model"
prompt = """将以下内容,翻译成现代汉语:
先帝创业未半而中道崩殂,今天下三分,益州疲弊,此诚危急存亡之秋也。然侍卫之臣不懈于内,忠志之士忘身于外者,盖追先帝之殊遇,欲报之于陛下也。诚宜开张圣听,以光先帝遗德,恢弘志士之气,不宜妄自菲薄,引喻失义,以塞忠谏之路也。
宫中府中,俱为一体,陟罚臧否,不宜异同。若有作奸犯科及为忠善者,宜付有司论其刑赏,以昭陛下平明之理,不宜偏私,使内外异法也。
侍中、侍郎郭攸之、费祎、董允等,此皆良实,志虑忠纯,是以先帝简拔以遗陛下。愚以为宫中之事,事无大小,悉以咨之,然后施行,必能裨补阙漏,有所广益。
将军向宠,性行淑均,晓畅军事,试用于昔日,先帝称之曰能,是以众议举宠为督。愚以为营中之事,悉以咨之,必能使行阵和睦,优劣得所。
亲贤臣,远小人,此先汉所以兴隆也;亲小人,远贤臣,此后汉所以倾颓也。先帝在时,每与臣论此事,未尝不叹息痛恨于桓、灵也。侍中、尚书、长史、参军,此悉贞良死节之臣,愿陛下亲之信之,则汉室之隆,可计日而待也。
臣本布衣,躬耕于南阳,苟全性命于乱世,不求闻达于诸侯。先帝不以臣卑鄙,猥自枉屈,三顾臣于草庐之中,咨臣以当世之事,由是感激,遂许先帝以驱驰。后值倾覆,受任于败军之际,奉命于危难之间,尔来二十有一年矣。
先帝知臣谨慎,故临崩寄臣以大事也。受命以来,夙夜忧叹,恐托付不效,以伤先帝之明。
"""
client = OpenAI(api_key=api_key, base_url=base_url)
#################################################################################
import tiktoken
# 在全局初始化编码器(根据实际模型选择)
encoder = tiktoken.get_encoding("o200k_base") # 适用于gpt-4/3.5-turbo
def num_tokens_from_messages(messages, model="gpt-3.5-turbo-0613"):
"""官方推荐的token计数方法(适配消息格式)"""
encoding = tiktoken.get_encoding("o200k_base")
tokens_per_message = 3 # 每条消息的基础token
tokens_per_name = 1 # name字段的token
token_count = 0
for message in messages:
token_count += tokens_per_message
for key, value in message.items():
token_count += len(encoding.encode(value))
if key == "name":
token_count += tokens_per_name
token_count += 3 # 每条回复的结尾标记
return token_count
#################################################################################
def chat_llm(i,
first_token_time_queue,
time_queue,
avg_output_queue,
prompt_tokens_queue,
completion_tokens_queue,
total_tokens_queue):
print(i, "start")
first_token_time = None
end_time = None
# completion_tokens = None #################
# prompt_tokens = None #################
total_tokens = None
completion_content = "" #################
start_time = time.time()
#预计算prompt tokens
prompt_messages = [{"role": "user", "content": prompt}] #################
prompt_tokens = num_tokens_from_messages(prompt_messages) #################
response: ChatCompletion = client.chat.completions.create(
model=model_name,
messages=[
{"role": "user", "content": prompt},
],
temperature=0.7,
stream=True
)
chunk_fin = None
for chunk in response:
chunk_fin = chunk
chunk: ChatCompletionChunk
#取出每次流式响应的内容字段
delta_content = chunk.choices[0].delta.content or "" #################
if first_token_time is None:
first_token_time = time.time() - start_time
# 收集回复内容
completion_content += delta_content #################
if chunk.choices[0].finish_reason == "stop":
end_time = time.time()
# completion_tokens = chunk.usage.completion_tokens #################
# prompt_tokens = chunk.usage.prompt_tokens #################
# total_tokens = chunk.usage.total_tokens #################
break
# 计算completion tokens
completion_tokens = len(encoder.encode(completion_content)) #################
total_tokens = prompt_tokens + completion_tokens #################
if end_time is None:
end_time = time.time()
chunk = chunk_fin
# completion_tokens = chunk.usage.completion_tokens #################
# prompt_tokens = chunk.usage.prompt_tokens #################
# total_tokens = chunk.usage.total_tokens #################
completion_tokens = 0 #################
total_tokens = prompt_tokens #################
first_token_time_queue.append(first_token_time)
try:
time_queue.append(end_time - start_time)
except Exception:
print(type(end_time), end_time)
avg_output_queue.append(completion_tokens / (end_time - start_time))
prompt_tokens_queue.append(prompt_tokens)
completion_tokens_queue.append(completion_tokens)
total_tokens_queue.append(total_tokens)
print(i, "end")
def test_concurrency(concurrency):
pool = []
for i in range(concurrency):
p = multiprocessing.Process(target=chat_llm, args=(i,
first_token_time_queue,
time_queue,
avg_output_queue,
prompt_tokens_queue,
completion_tokens_queue,
total_tokens_queue))
pool.append(p)
for p in pool:
p.start()
for p in pool:
p.join()
while True:
flag = True
for i in range(concurrency):
if pool[i].is_alive():
flag = False
break
if flag:
break
assert len(prompt_tokens_queue) == len(completion_tokens_queue) == len(total_tokens_queue) == len(first_token_time_queue) == len(
time_queue) == concurrency, f"{len(prompt_tokens_queue)}, {len(completion_tokens_queue)}, {len(total_tokens_queue)}, {len(first_token_time_queue)}, {len(time_queue)}, {concurrency}"
print("prompt_tokens", sum(prompt_tokens_queue) / concurrency)
print("completion_tokens", sum(completion_tokens_queue) / concurrency)
print("total_tokens", sum(total_tokens_queue) / concurrency)
print("first token time", sum(first_token_time_queue) / concurrency, "s")
print("avg output time", sum(avg_output_queue) / concurrency, "token/s")
avg_output = 0
for i in range(concurrency):
avg_output += total_tokens_queue[i] / time_queue[i]
print("avg token", avg_output / concurrency, "token/s")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('concurrency', type=int, default=1)
args = parser.parse_args()
with Manager() as manager:
first_token_time_queue = manager.list()
time_queue = manager.list()
avg_output_queue = manager.list()
prompt_tokens_queue = manager.list()
completion_tokens_queue = manager.list()
total_tokens_queue = manager.list()
test_concurrency(args.concurrency)
这段代码是超哥写的测试代码。
但是这段代码有一个问题,经过调试以及阅读博客OpenAI API格式详解-Chat Completions,发现流式响应response对象中没有usage对象,没办法统计提问消耗的 token,回答消耗的 token,以及总共消耗的 token 数。ChatGPT api 启用 stream 返回时,无法统计 token 的解决思路,我在网上找到了这个帖子,里面说可以通过 tiktoken进行统计。然后我让deepseek写了一段代码来统计这些数据。
一堆#的地方是我改动过的地方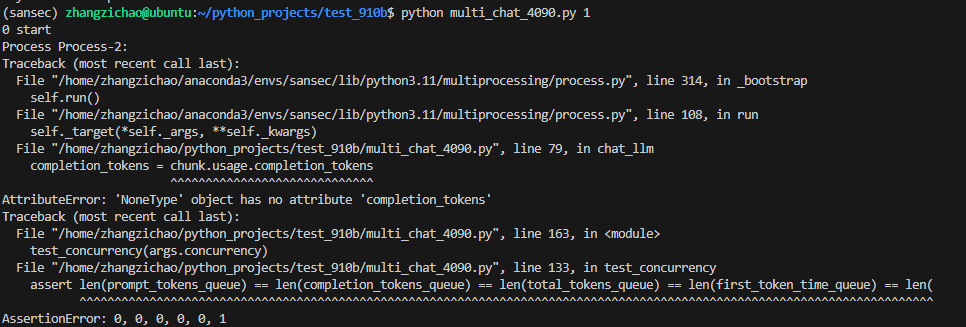
修改了代码之后就可以成功运行了,采用o200k_base编码的统计数据如下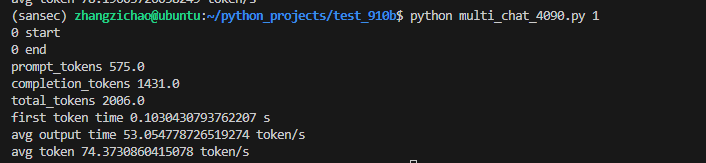
这个地方还有没有完成的任务,光改了bug了,最大并发数还没有测呢
使用Postman进行api测试
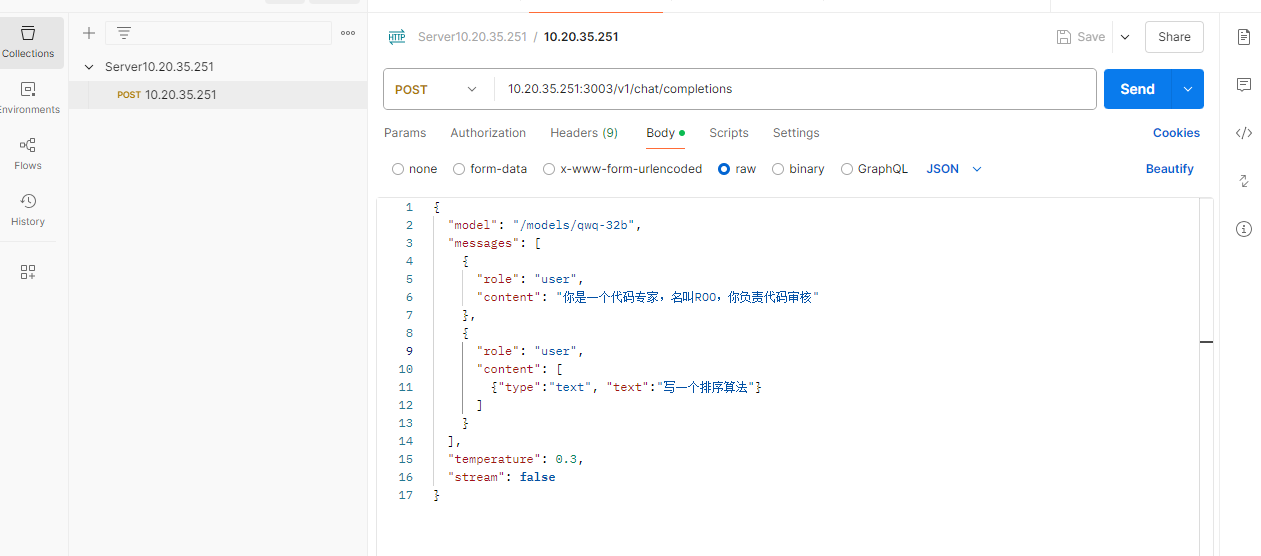
需要注意的地方是url不能只写到v1,curl调用也是同样的问题,否则会404
OpenAI(api_key=api_key, base_url=base_url),这个base_url写到v1就可以,因为客户端库(如openai-python)会自动补全终结点路径
现在测试vllm是否支持多模态大模型
在VLLM官方文档中找到支持的多模态大模型,如图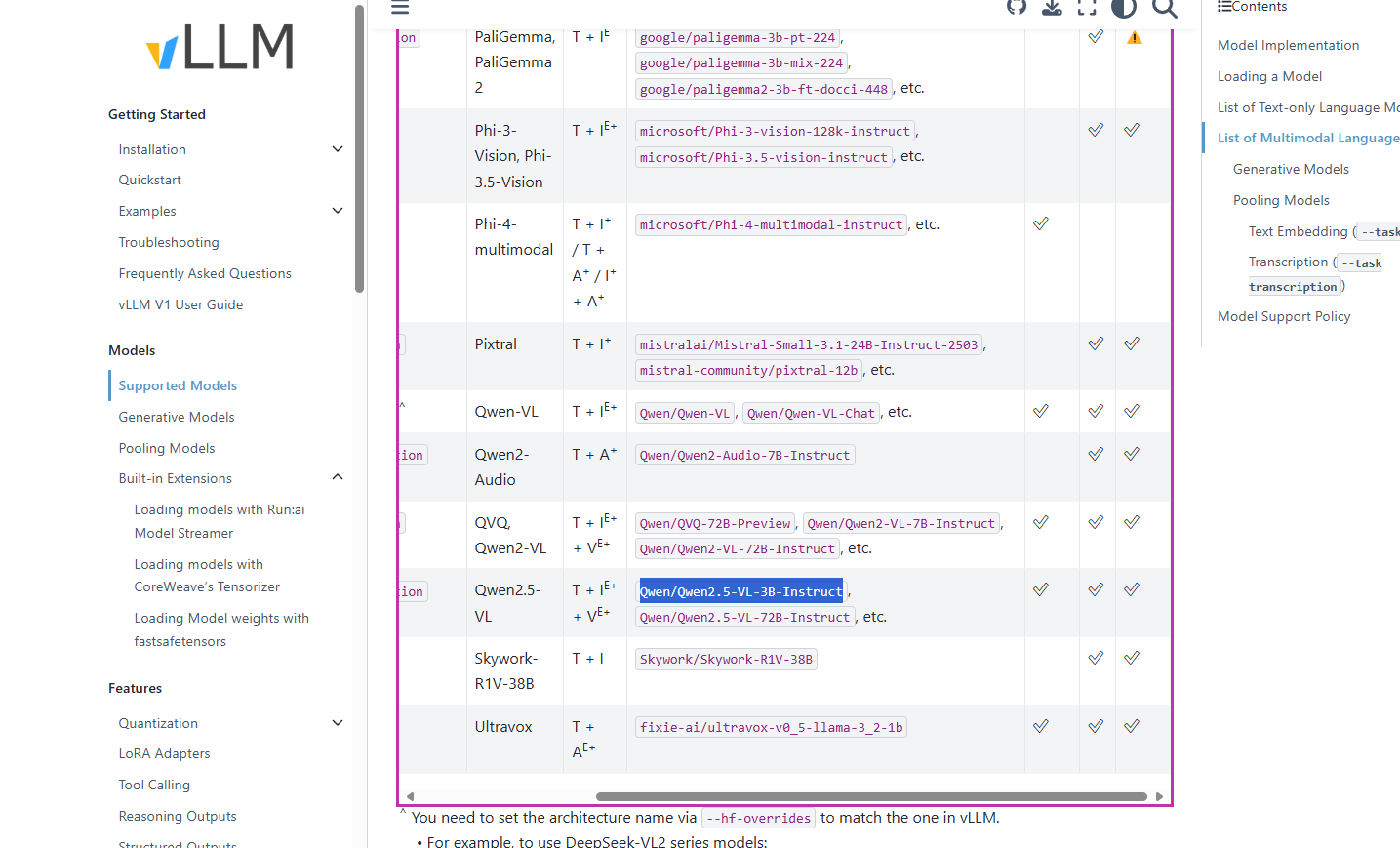
想要测试的是Qwen2.5-VL-3B-Instruct
由于我使用的服务器没有python,所以也没有modelscope,所以要在第一台服务器上下载模型Qwen2.5-VL-3B-Instruct
然后通过scp传到另一台服务器的指定文件夹
scp -r Qwen2.5-VL-3B-Instruct 10.20.35.251:/mnt/d0/checkpoints
参考这个帖子使用视觉语言模型 (VLMs),来用vllm访问大模型的时候附加上图片
!!!这一步还没有进行完就突然被告知进行下一步了,看下面
将包含vllm的docker移植
今天晚上突然通知这台服务器要发走,所以先把包含vllm的docker保存一下,防止后期部署麻烦
#将容器保存为镜像
docker commit a063566b15d6 vllm:1.0
#将镜像保存为tar包
docker save -o vllm.tar vllm:1.0
#把tar包传到另一台服务器上
scp vllm.tar root@10.20.25.250:/home/zhangzichao/docker_images
#在新服务器上使用“docker load”加载镜像tar包用于创建新镜像。
docker load -i vllm.tar

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)