Llama 4 不仅没有炸裂,代码能力还翻车了?
自从 DeepSeek 腾空出世后,AI 界是相互唱戏,前不久马斯克的 XAI 发布了 Grok 3,以及 DeepSeek 的 V3,阿里千问的 QwQ,和 ChatGPT 的文生图等等。几乎是每个 1 个周或 2 个周,就有新的 AI 模型问世,犹如摩尔定律一样,噌噌的迭代与更新。就在我们放假的这 3 天,小扎的 Meta 发布了 Llama 4。这次的发布相对于其它 AI 来说的亮点并不算多
自从 DeepSeek 腾空出世后,AI 界是相互唱戏,前不久马斯克的 XAI 发布了 Grok 3,以及 DeepSeek 的 V3,阿里千问的 QwQ,和 ChatGPT 的文生图等等。几乎是每个 1 个周或 2 个周,就有新的 AI 模型问世,犹如摩尔定律一样,噌噌的迭代与更新。
就在我们放假的这 3 天,小扎的 Meta 发布了 Llama 4。这次的发布相对于其它 AI 来说的亮点并不算多,但对于 Llama 3 来说,堪称一次大升级!
刚好 A 股和亚太股市暴跌,焦点可能都转移到股市了,看 AI 的估计不多,那我就来聊聊这次 Meta 发布的 Llama 4。
Meta 最新发布的 Llama 4 系列模型在 AI 领域引起了广泛关注,但是由于“关税战”导致了它的流量并没有预期的高。
根据官网https://ai.meta.com/blog/llama-4-multimodal-intelligence/的介绍得知,此次发布的主要亮点包括 MoE(混合专家)架构、超长上下文窗口、原生多模态支持、高效推理能力 等。
下面我们围绕这 4 点展开,简单的分析一波。
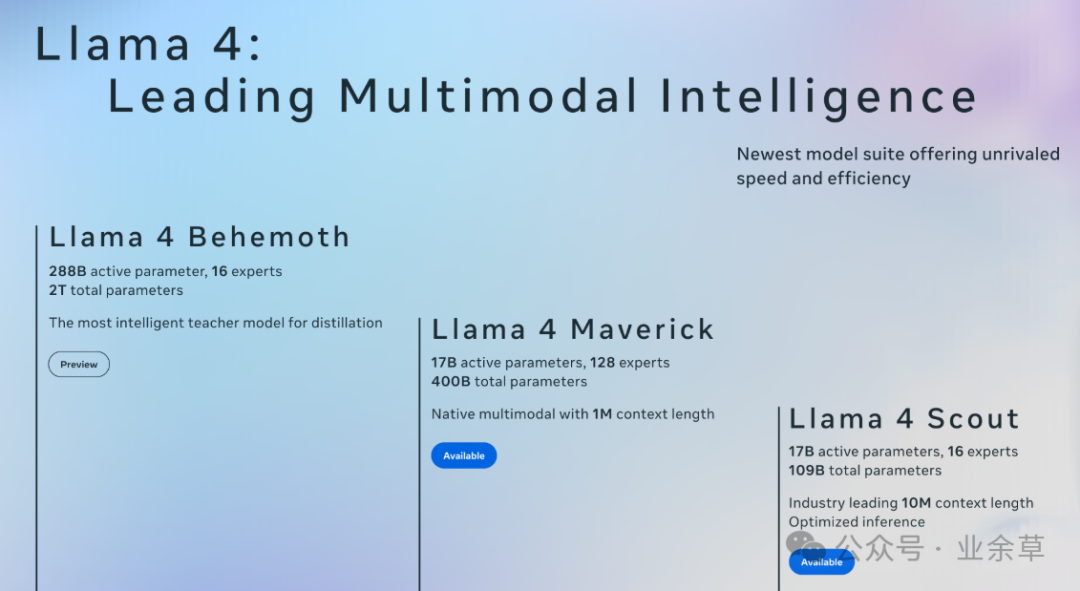
采用 MoE(混合专家)架构,提升计算效率
- Scout(170亿激活参数,16个专家) 和 Maverick(170亿激活参数,128个专家) 均采用 MoE 架构,仅激活部分参数进行计算,降低推理成本。
- Behemoth(2万亿参数,仍在训练) 作为“教师模型”,未来将用于蒸馏优化更小的 Llama 4 版本。
- 推理成本极低:Maverick 的推理成本仅 $0.19/百万 token,比 GPT-4o 便宜 90%。
超长上下文窗口(1000万 token)
- Scout 支持 1000万 token(约15000页文本),远超 Llama 3(128K)和 Gemini 2.0(200万)。
- 采用 iRoPE(交错旋转位置编码) 技术,结合局部注意力(RoPE)和全局注意力(NoPE),优化长文本处理。
原生多模态能力(支持图像、视频理解)
- 采用 MetaCLIP 视觉编码器,支持 48张图像输入,能精准识别图片内容(如工具选择、颜色识别)。
- 在 ChartQA、DocVQA 等视觉基准测试中超越 GPT-4o 和 Gemini 2.0 Flash。
多语言支持(12种语言)
- 训练数据涵盖 200种语言(比 Llama 3 多 10 倍),尤其优化了 中文、阿拉伯语、西班牙语 等。
高性能 & 低成本
- Maverick 在 LMArena 评测中得分 1417,超越 DeepSeek-V3,成为 开源模型第一。
- 代码能力媲美 DeepSeek-V3,但参数仅一半,性价比极高。
你看,上面这几条,单独拿出来,都是别人有的或者已经突破的方向,Llama 4 对齐即可。但你要说变化吗?相对 Llama 3 来说,变化是真的大。Llama 3 上没有的,这次都补齐了,Llama 3 上有的,这次都加强了。
Llama 4 带来的最大变化
总结下来,无非就是下面 4 点。
- 从纯文本到原生多模态:首次支持 图像+文本联合理解,让 Llama 系列真正“长眼睛”。
- 从密集模型到 MoE 架构:大幅降低推理成本,让大模型 可在单张 H100 GPU 上运行。
- 上下文窗口突破 1000万 token:远超竞品,适用于 超长文档分析、代码库推理。
- 更激进的定价策略:API 价格比 DeepSeek 更低,吸引开发者。
我整体对 Llama 4 的评价不高,或者是说没有超预期。下面看看优势和争议的部分。
✅ 优势
- 开源模型的新标杆:在多模态、长文本、推理效率方面领先。
- 性价比极高:MoE 架构让大模型更易部署,适合企业应用。
- Meta 生态整合:已用于 WhatsApp、Instagram 的 AI 助手。
和其它模型就不比了,比一比自己的 Llama 3,大家看看吧。
❌ 争议
- 训练数据作弊争议:有爆料称 Meta 在训练中混入测试集数据以提高分数。
- 代码能力实测翻车:部分用户测试发现其编程能力不如 DeepSeek-V3。
- 开源限制:月活超 7 亿的公司需申请特殊许可,被批“半开源”。
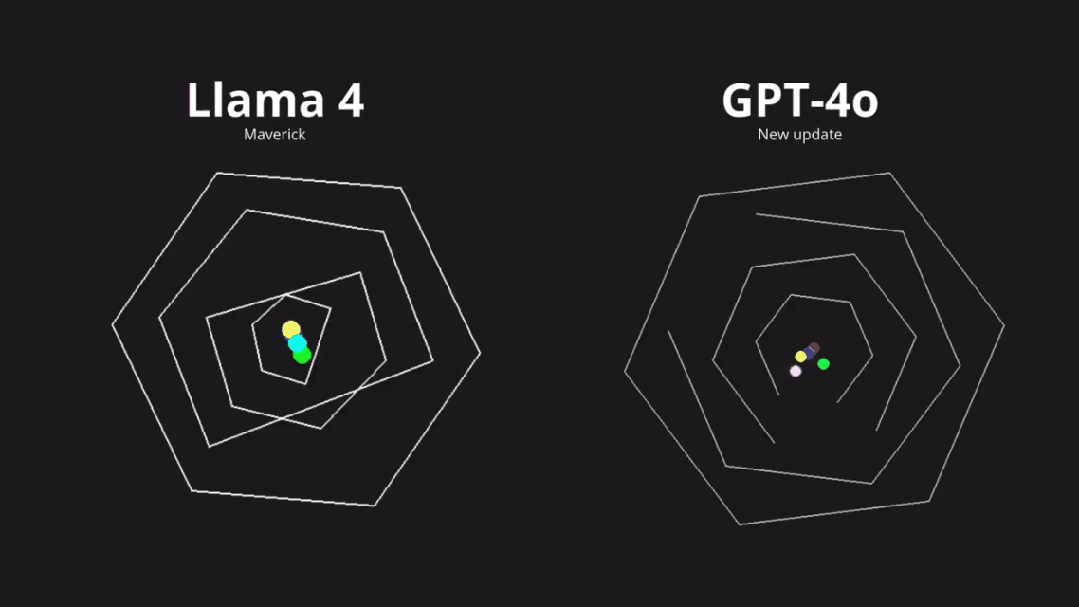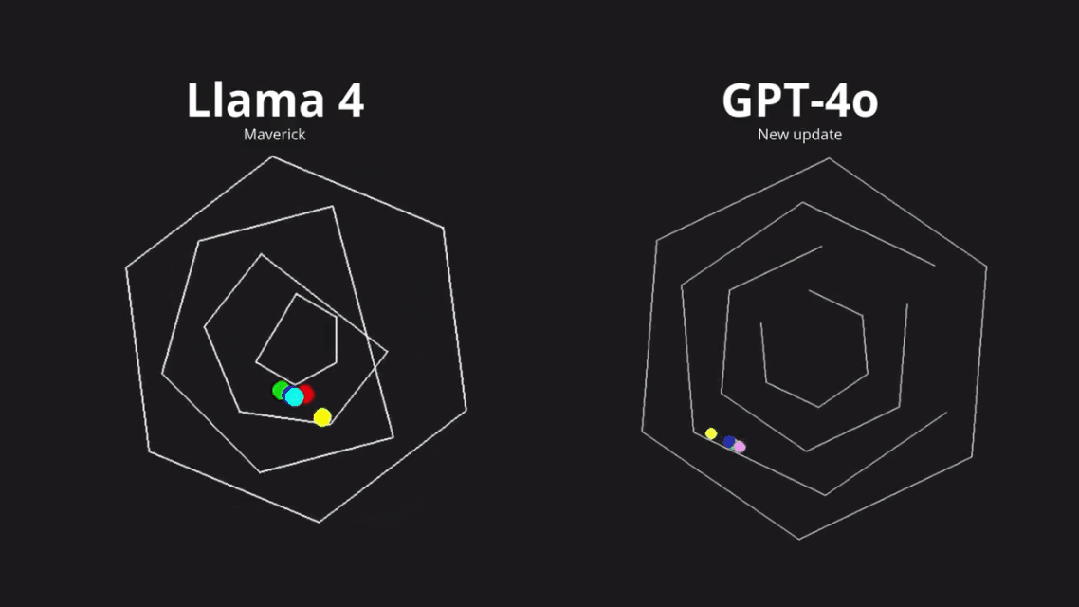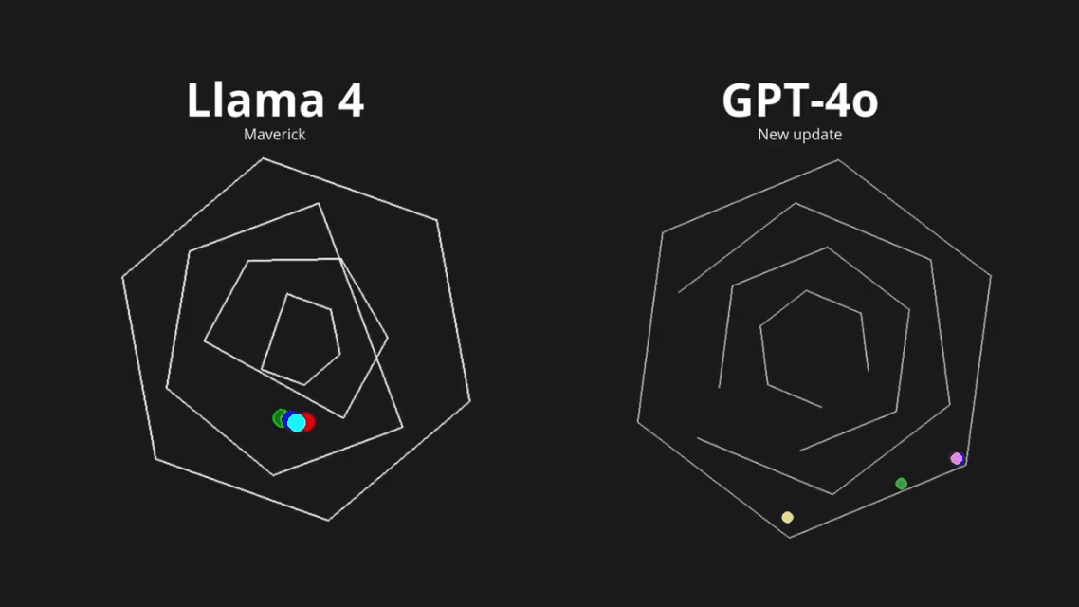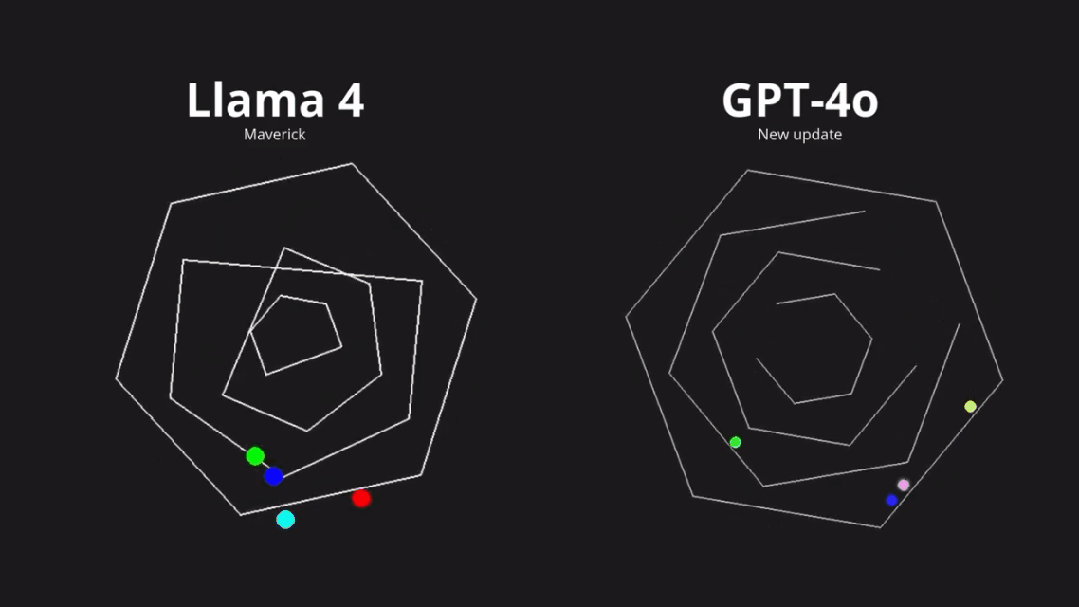
尤其是对代码编程能力方面,有人直接曝出,Llama 4 在 LMarena 上存在过拟合现象,有极大的「作弊」嫌疑。
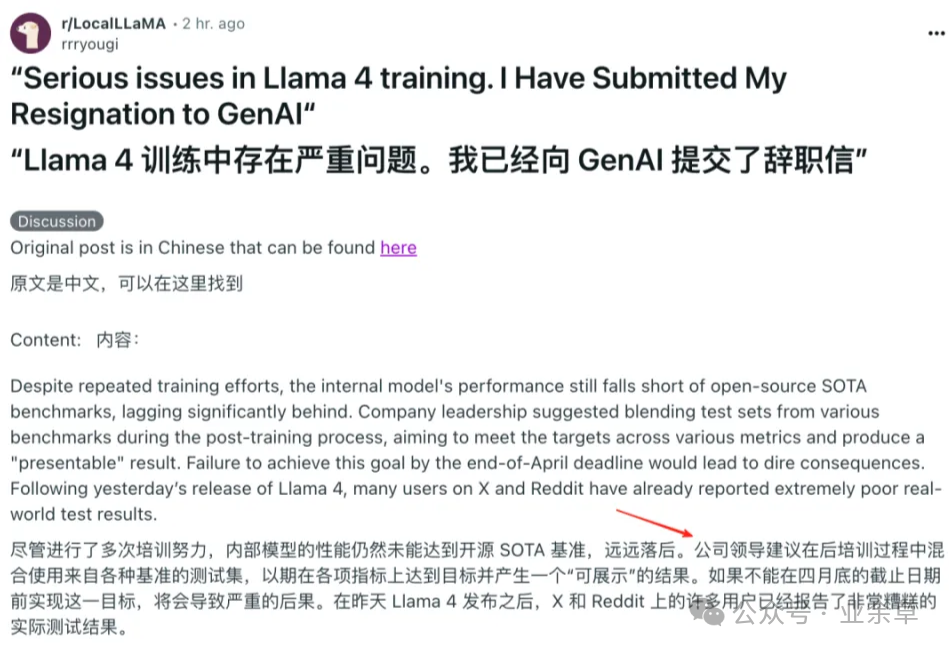
但不管怎么说,Llama 4 的低成本、高性能的特点任有可能推动 AI 应用的进一步普及。期待,更多厉害的 AI 早日推出,尤其是 DeepSeek 的 R2。同时也希望更多的 MCP 协议方面的应用呈爆发式增长。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 16
16 0
0- 0



 已为社区贡献104条内容
已为社区贡献104条内容

所有评论(0)