西北工业大学:《DeepSeek核心技术白话解读》(可下载)
西北工业大学的王鹏教授最近公开了一份技术报告《DeepSeek核心技术白话解读》1. DeepSeek的几个版本语言大模型:DeepSeek-V3,对标ChatGPT。推理大模型:DeepSeek-R1,对标OpenAI-O1,通过蒸馏技术将大型模型的知识压缩到更小的模型中。
·
前言
西北工业大学的王鹏教授最近公开了一份技术报告《DeepSeek核心技术白话解读》,如下:

该报告的主要内容如下:
一、DeepSeek核心技术概述
1. DeepSeek的几个版本
- 语言大模型:DeepSeek-V3,对标ChatGPT。
- 推理大模型:DeepSeek-R1,对标OpenAI-O1,通过蒸馏技术将大型模型的知识压缩到更小的模型中。

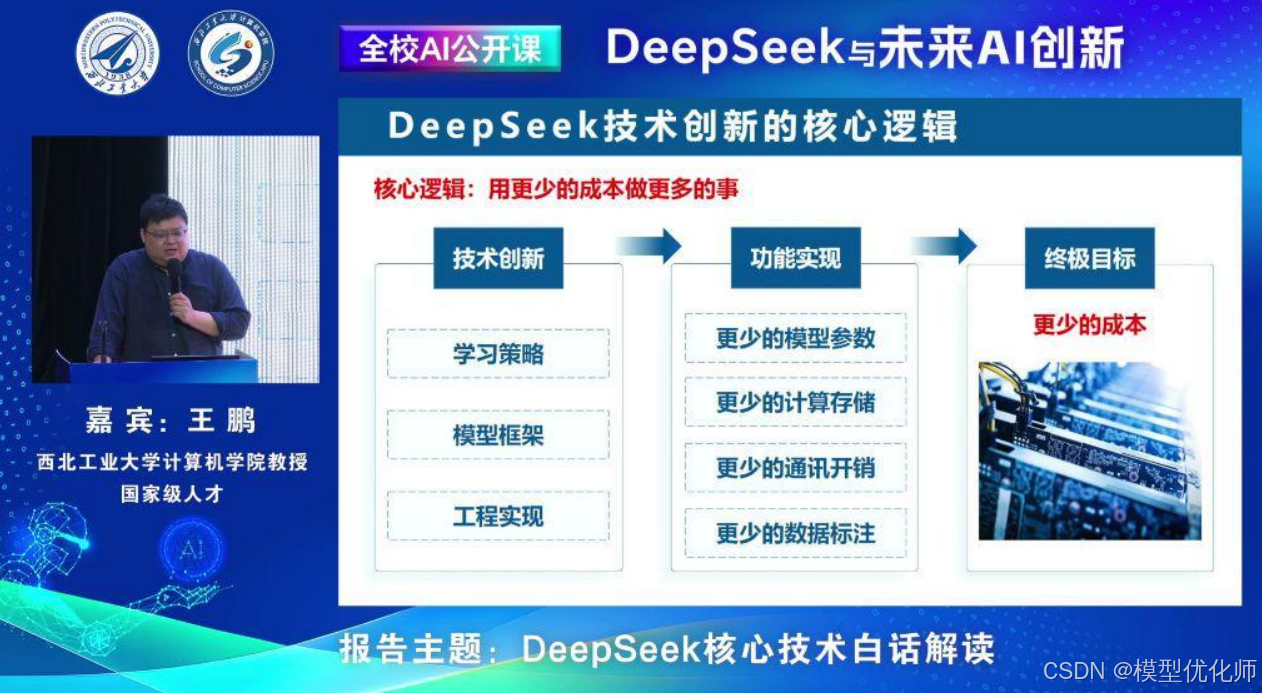
2. DeepSeek技术创新的核心逻辑
- 目标:用更少的成本做更多的事。
- 实现方式:通过创新的学习策略、模型架构和工程实现,减少模型参数、计算存储、通讯开销和数据标注成本。
二、、DeepSeek核心技术详解
1. 学习策略创新
介绍机器学习模型、监督学习和强化学习等基本概念。
DeepSeek在后训练阶段首次用强化学习完全代替监督微调(R1-Zero),采用GRPO算法,通过最简单的反馈信号和很少的学习循环次数大幅提升模型的推理能力。
DeepSeek-R1-Zero展现出类似人类的顿悟能力,通过重新思考解决问题。
大幅增加后训练阶段的可扩展性,降低数据标注成本,开启LLM推理能力的自我进化之门。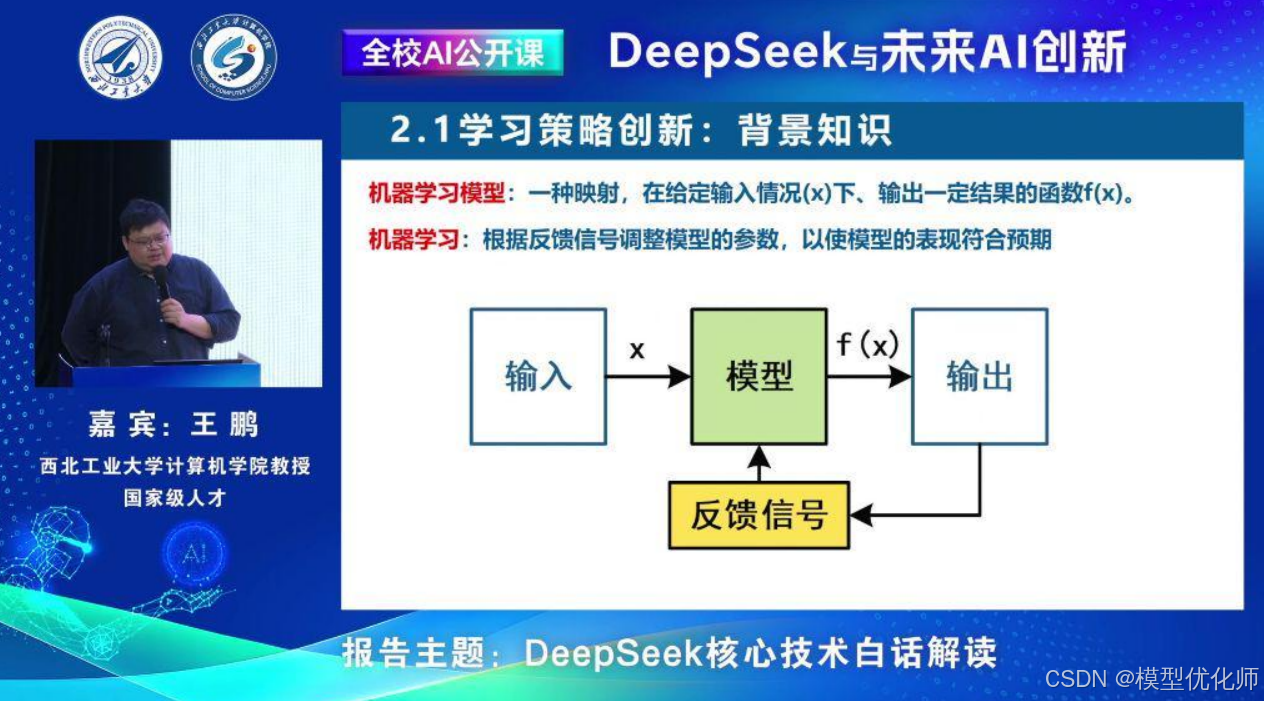
2. 模型架构创新
介绍深度神经网络的核心思想,包括信息的逐层传播与变换、变换的核心性和目标的一致性。
Transformer成为大模型的首选架构,因其全局依赖建模能力、并行计算效率和可扩展性。
混合专家架构(MOE):DeepSeek对前向计算网络进行改进,通过细粒度的专家分割和动态激活部分专家提升计算效率。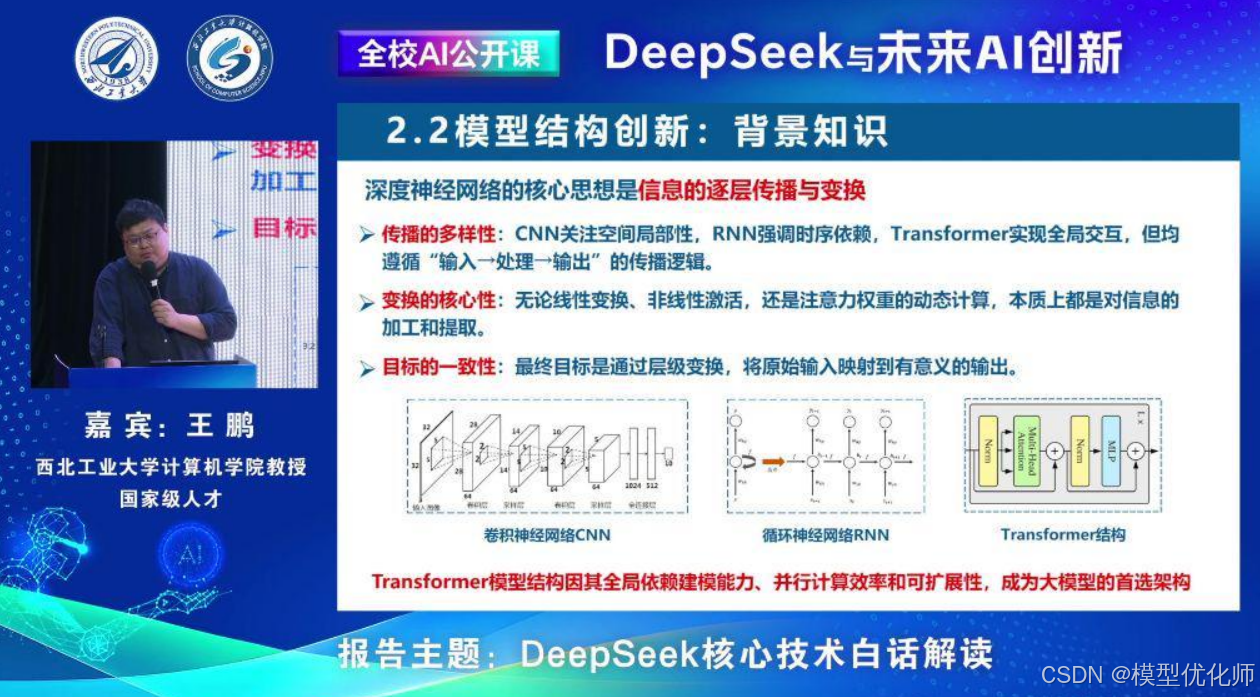
3. 工程实现创新
- FP8混合精度训练:DeepSeek首次使用8位浮点数量化激活和权重,配合动态精度累加,在保证精度的同时提升训练速度30%。
- 分布式训练优化:采用4D并行策略,结合通信计算重叠技术,将万亿Token训练时间压缩至3.7天。
- 推理部署分离策略:预填充与解码阶段分离,结合冗余专家动态路由,实现高吞吐量与低延迟的在线服务。

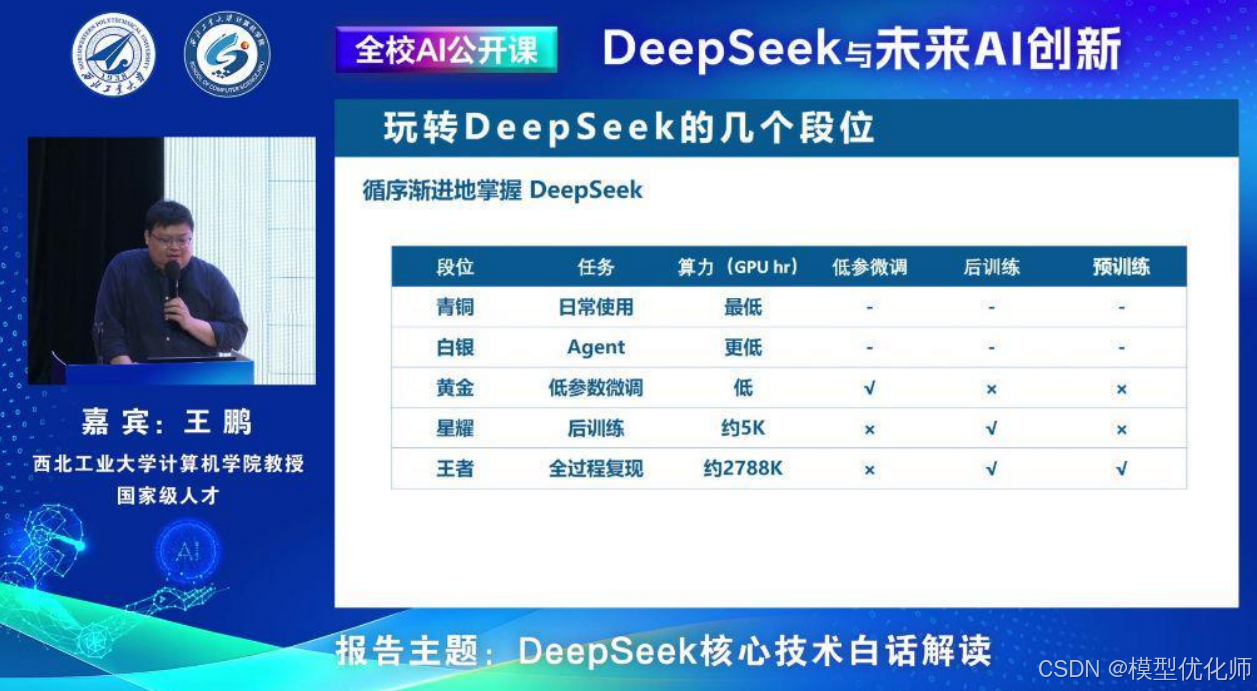
三、玩转DeepSeek的几个段位
- 青铜:掌握基础应用,利用现有的问答能力和构建简单的提示工程。
- 白银:将LLM作为Agent,与其他软件系统进行连接和功能扩展。
- 黄金:进行低参数微调。
- 星耀:进入后训练阶段,对已经训练的模型进行进一步的训练与调整。
- 王者:掌握预训练与后训练的全过程,精通模型全流程训练的每个环节。
四、思考与展望
- 现象思考:分析英伟达股价大起大落的原因,以及DeepSeek部署热潮的反思。
- 现有问题:幻觉消除和模型压缩等挑战。
- 未来展望:多模态大模型与具身智能的发展趋势。

有需要完整报告的朋友,可以扫描下方二维码免费领取👇👇👇


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 5
5 0
0- 0



 已为社区贡献103条内容
已为社区贡献103条内容

所有评论(0)