Windows环境简易部署Deepseek-r1蒸馏模型方法
Windows系统环境下,使用Lm Studio简易部署DeepSeek模型。也可以加载其他可用gguf模型
文章目录
DeepSeek近期非常火热,而且好多平台都有本地部署的视频介绍,像我这样的普通ai爱好者也是风风火火的去跟风了,想想自己电脑搞个好像挺牛的。
为了给像我这样啥也不懂的,又想自己部署Deepseek尝试的同志一份参考,所以把我在用了十年的办公老PC上部署Deepseek的过程记录下来了。
系统版本与使用的工具
PC配置: Intel® Core™ i3-4160 CPU @ 3.60GHz 3.60 GHz 16.0 GB 无独显GPU
系统版本: Windows 10 IoT 企业版 LTSC为例,版本号:21H2,内部版本号:19044.5608
使用工具: LM Studio
大模型的运行主要就是三样:CPU+GPU+内存,在尝试的时候其实不需要纠结,正常目前标配的个人PC都能跑起来(反正我十年前的i3四代是可以的),内存必须16GB以上,不然模型都加载不了。
具体操作步骤
1.进入LM Studio官网下载安装程序:https://lmstudio.ai/download
打开官方网站,下载最新版本就行,之所以选择lm studio主要是简单,其次:
- 应用内自带聊天界面:LM Studio提供了应用内聊天用户界面,用户可以选择已下载的模型进行对话聊天,并可以设置聊天参数,如GPU使用、聊天上下文长度等。
- 兼容OpenAI的本地服务器:用户可以通过启动本地HTTP服务器,模拟OpenAI API接口,非常方便的使用http调用本地部署的模型,比如WPS插件海鹦officeAi。
- 多模型推理聊天:允许同时加载多个模型,并行处理用户问题,提高聊天响应速度和多样性。
- 模型管理:提供模型下载、删除以及打开模型目录等功能,方便用户管理本地模型。
2.默认安装完成。
需要注意的是:默认安装后模型的路径是:C:\Users\用户名\.lmstudio\models\(此路径可以在程序中修改),但模型文件放置的结构要以下面的相同,才能正确识别:
C:\user\用户名\.lmstudi\models
├── my-models
│ ├── DeepSeek-R1-Distill-Qwen-7B-Q2_K
│ └── DeepSeek-R1-Distill-Qwen-7B-Q2_K.gguf
├── lmstudio-community
├── Qwen2-Math-1.5B-Instruct-GGUF
└── Qwen2-Math-1.5B-Instruct-Q4_K_M.gguf
- my_models是自己下载的模型路径(需要自己创建)
- lmstudio-community是软件下载模型存放路径
- 模型的选择一般是GGUF类型的模型,也就是.gguf文件,并存放在与文件名相同的文件夹中
例如:我下载了一个模型“DeepSeek-R1-Distill-Qwen-7B-Q2_K.gguf”,文件路径如下图所示
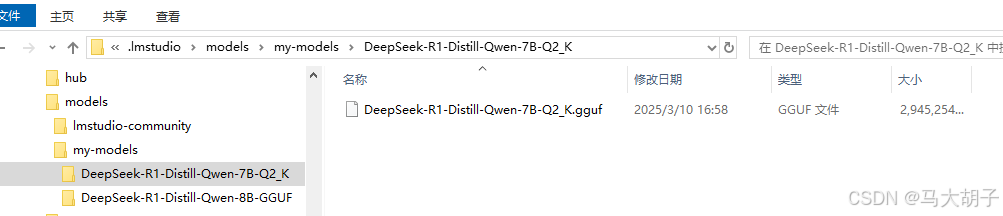
注意:文件与文件夹同名
3.启动LM Studio
默认安装完成后,即可像其他应用一样,双击桌面图标启动,界面如下:
LM Studio的使用界面很简单,这里就不多说了。
正常启动后,我们就可以选择需要的的模型加载。
4.模型的下载,有两种方式
第一种:直接下载LM Studio官方提供的模型使用
- 到官网查看,选择下载,然后存放到上述模型的文件夹里,地址:https://lmstudio.ai/models
- 或者在应用里打开应用设置(按"Ctrl+,") ,选择可加载的模型下载:
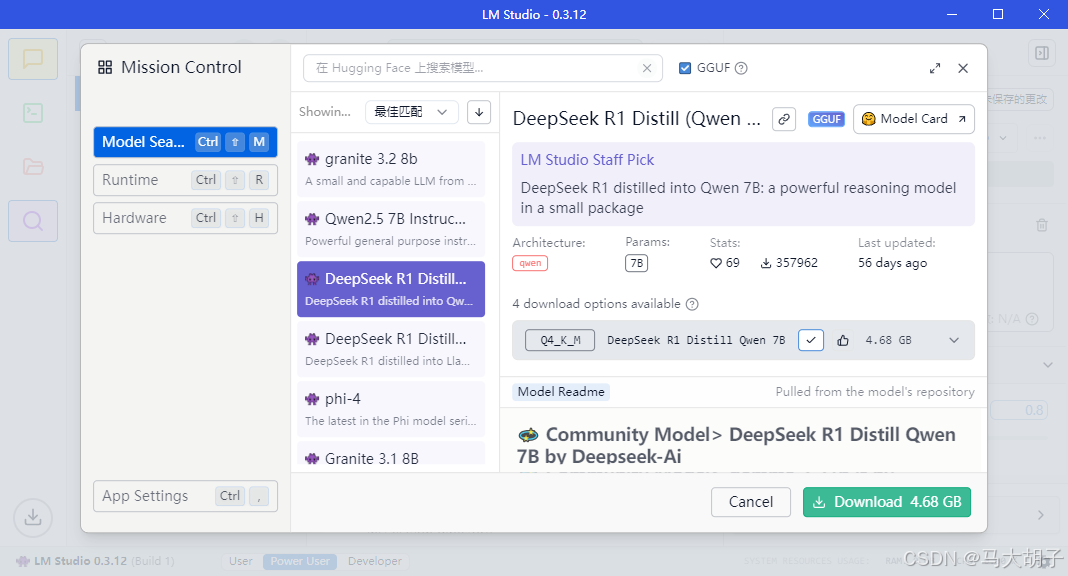
第二种:到其他站点下载GGUF模型,并按要求在正确路径的目录下存放模型文件
推荐站点:hf-mirror.com,根据需要搜索所需模型
- 搜索时一定要注意:模型名称(例如:DeepSeek-r1)和模型类型(GGUF)
- 不是很了解一些模型关键词或内容的,建议用第一种方法
5.加载模型
下载好模型,就可以点击最上方“选择加载的模型(或按Ctrl+L),选择模型加载: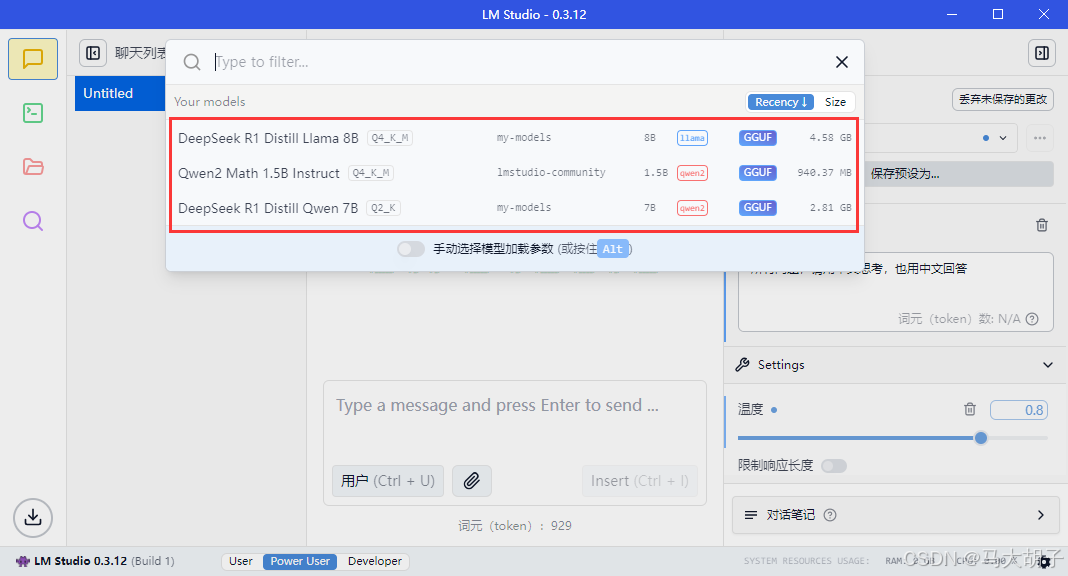
点击要加载的模型后,需要进行模型加载的参数调整,调整完点击加载模型。需要调整的参数有以下几个,其余参数随便(根据自己PC配置适当调整,过高则可能模型加载失败,过低则可能模型使用时速度较慢):
- 上下文长度:决定模型能够处理的最大文本长度,不易太大,默认4096即可,如果速度太慢则调低数值
- GPU卸载:一般参考GPU显存大小调整,可以先选择一个中值,根据实际的显存占用率和模型推理速度,适当增减
- CPU Thread pool Size:一般调到最大
如果出现加载失败,可以把GPU调到最低,不使用GPU加载模型,速度太慢,则降低上下文长度
至此,本地部署完成。
模型的使用
当加载模型成功后,既可以使用。LM Studio自带聊天窗口,不需要再去下载另外的工具。
例如: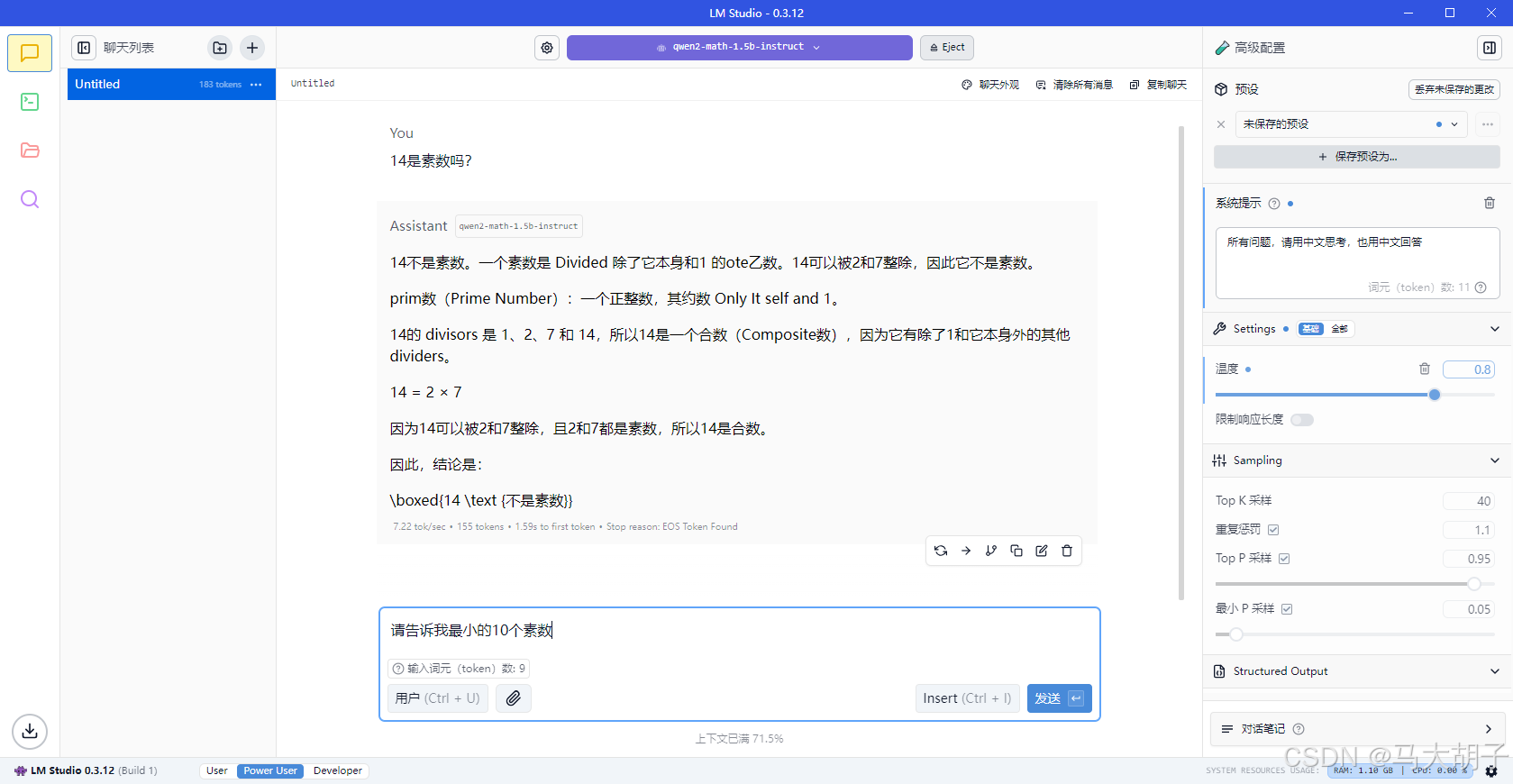
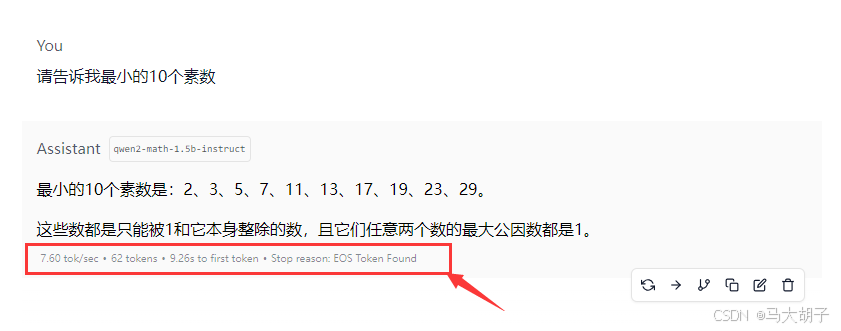
- 可以根据上图红线所示,对模型参数重新调整。
使用LM Studio的网络功能
1.开启网络服务器的功能
即把本地电脑用做服务器,并提供网络访问:提供http访问加载的模型。
- 点击软件最右侧“开发者”图标,进入开发者面板
- 打开:Status:Stopped后的开关,Settings可以调整简单的网络参数,比如端口号
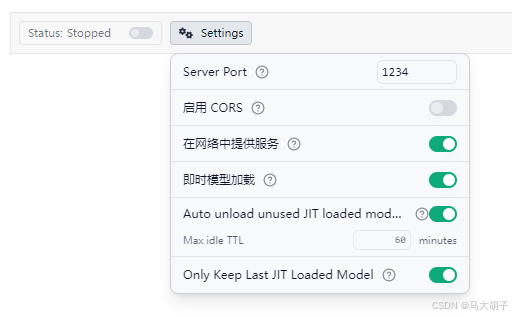
Status状态:有Stopped===>Running
- 按之前模型加载的方法,加载提供服务的模型
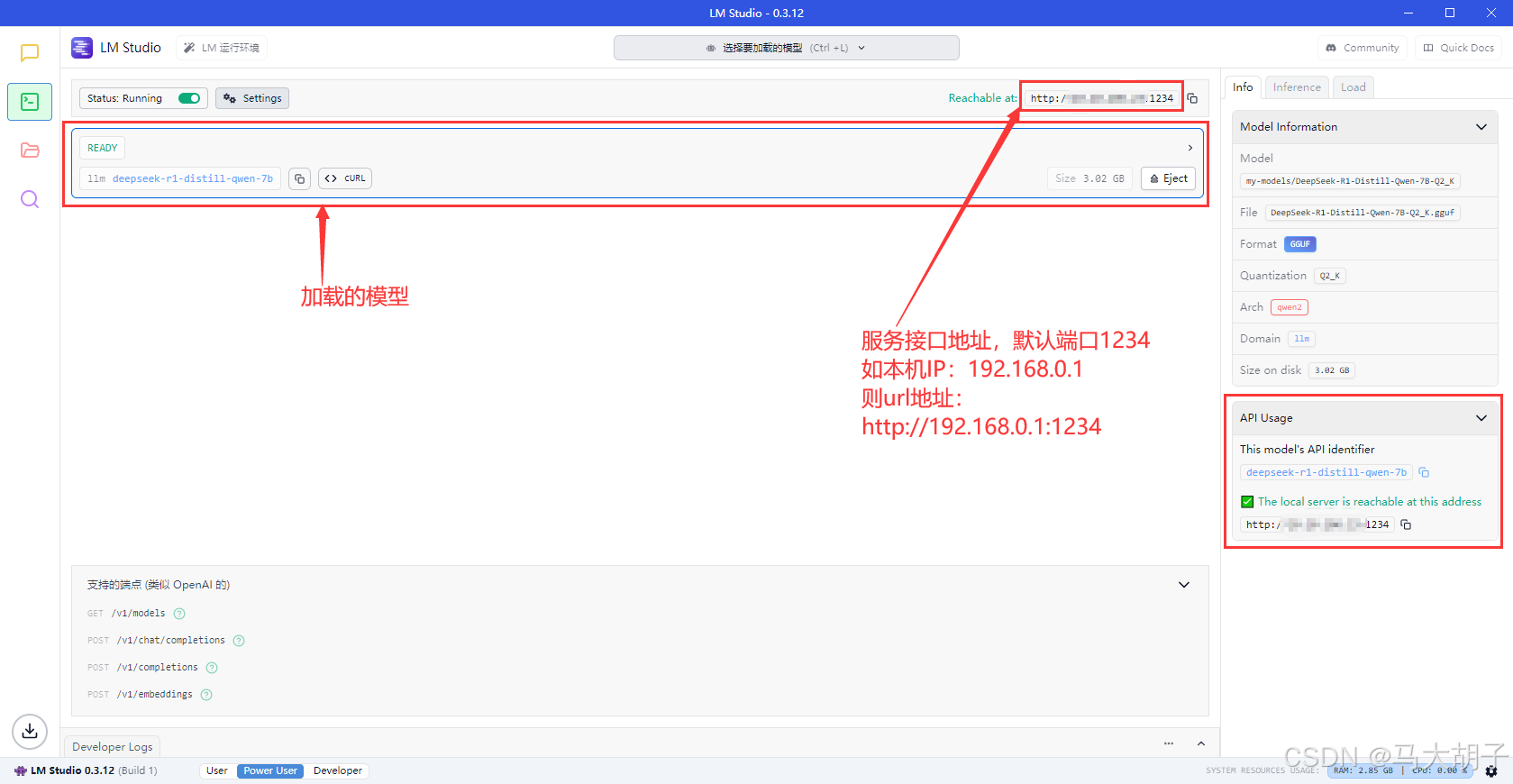
此时,你就已经开通了网络访问已加载模型的网络服务了。
正常启动服务后,Lm Studio会对本地1234端口监听,不需要自己预加载模型,使用客户端时会启动选择的模型自动加载。
当然,如果你在浏览器地址栏里直接输入:http://192.168.0.1:1234,你得到的是: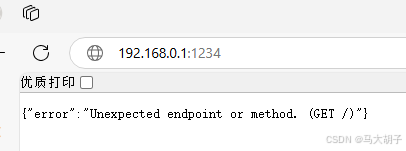
这是因为,这里的地址只是一个服务接口地址,而你又没有提供对应的访问方法,所以不能直接使用。
这里需要通过HTTP接口访问大规模模型服务的工具,推荐工具Chatbox,其他的还有LangChain、Cheerry Studio、AnythingLLM、Streamlit等。
2.如果你想在WPS里使用你本地部署的模型,那么……
- 下载海鹦OfficeAI助手,并安装它,海鹦安全科技有限公司官网地址(https://www.haiyingsec.cn/)
安装完成后,你会发现在你的WPS工具栏处多了一个插件:
点击插件,找到它的设置对话框:
在大模型设置==>本地==>这些模型"lmstudio",并填入模型服务器地址:http://192.168.0.1 ,选择模型名,点击保存。就可以使用了。
右侧对话框会限制,加载使用的模型
关于各种量化版本标识符的对比
以下是常见量化标识符的对比表,涵盖参数位宽、分组策略、适用场景等关键信息:
量化标识符对比表
| 标识符 | 位数 | 分组块大小 | 混合精度 | 适用场景 | 精度 vs 体积 |
|---|---|---|---|---|---|
| Q2 | 2-bit | 32-64 | 否 | 极低显存设备,简单任务 | 体积最小,精度损失大 |
| Q2_K | 2-bit | 256 | 是 | 平衡压缩与精度,通用任务 | 体积稍大,精度优于 Q2 |
| Q3_K | 3-bit | 128-256 | 是 | 低显存 GPU,中等复杂度任务 | 体积适中,精度接近 Q4 |
| Q3_K_S | 3-bit | 64 | 是 | 快速推理,资源严格受限 | 精度略低于 Q3_K |
| Q3_K_M | 3-bit | 256 | 是 | 通用场景,平衡性能 | 精度优于 Q3_K_S |
| Q4_0 | 4-bit | 32 | 否 | 基础 4-bit 量化,快速推理 | 精度一般,体积中等 |
| Q4_K | 4-bit | 64-256 | 是 | 通用任务首选 | 精度高,体积略大 |
| Q4_K_S | 4-bit | 64 | 是 | 显存紧张时的轻量级选择 | 精度略低于 Q4_K |
| Q4_K_M | 4-bit | 256 | 是 | 需高精度的复杂任务 | 精度接近原模型 |
| Q5_0 | 5-bit | 32 | 否 | 对精度敏感的低压缩需求 | 体积较大,精度较高 |
| Q5_K | 5-bit | 128-256 | 是 | 高精度要求,中等显存设备 | 精度接近无损,体积大 |
| Q5_K_S | 5-bit | 64 | 是 | 快速高精度推理 | 精度略低于 Q5_K |
| Q5_K_M | 5-bit | 256 | 是 | 最高精度需求(如学术研究) | 精度几乎无损 |
| Q8_0 | 8-bit | 32 | 否 | 无损量化,兼容性测试 | 体积大,精度与原模型一致 |
关键说明
- 位数:单个参数的存储位数,位数越高精度保留越好,但体积越大。
- 分组块大小:
- 块越小(如 64),计算效率越高,但误差可能累积。
- 块越大(如 256),统计分布更稳定,精度更高。
- 混合精度:
- 例如
Q2_K可能在块内对重要参数使用 4-bit,非关键参数用 2-bit。
- 例如
- 适用场景:
- 低显存设备:优先选
Q2_K、Q3_K_S。 - 通用任务:选
Q4_K_M或Q5_K_M。 - 无损推理:选
Q8_0(需足够显存)。
- 低显存设备:优先选
选择建议
- 资源极度紧张:
Q2_K>Q3_K_S。 - 平衡性能与精度:
Q4_K_M>Q5_K_S。 - 高精度要求:
Q5_K_M>Q8_0。 - 快速测试/原型:从
Q4_K_M开始,逐步向下压缩。
实际部署前建议用少量数据测试目标量化版本的输出质量! 🚀

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)