DeepSeek联合清华,携强化学习(RL)与大语言模型(LLM)强势来袭!AI世界或将“改朝换代”?
就在刚刚,发布的最新论文正在 AI 领域逐渐升温!在人工智能领域,已然成为创新焦点,开启了充满无限可能的新征程。RL能够基于环境反馈不断优化决策,LLM则擅长对语言进行深度理解与精准生成,二者相辅相成,有望推动AI技术实现重大飞跃。当前,不过,在诸多领域获取LLM准确奖励信号仍是一大挑战,尤其是在难以验证的问题或缺乏人工规则的场景下。
就在刚刚,DeepSeek 发布的最新论文正在 AI 领域逐渐升温!
在人工智能领域,强化学习(RL)与大语言模型(LLM)的融合已然成为创新焦点,开启了充满无限可能的新征程。RL能够基于环境反馈不断优化决策,LLM则擅长对语言进行深度理解与精准生成,二者相辅相成,有望推动AI技术实现重大飞跃。
当前,RL在LLM后期训练中的应用已十分广泛。不过,在诸多领域获取LLM准确奖励信号仍是一大挑战,尤其是在难以验证的问题或缺乏人工规则的场景下。而DeepSeek与清华大学的研究人员另辟蹊径,在最新提交的论文中,探索奖励模型(RM)的多元方法时发现,逐点生成奖励模型(GRM)能够统一对单个、成对及多个响应的评分,以纯语言表示巧妙化解难题。
研究还表明,特定原则可引导GRM在合理标准内生成奖励,提升奖励质量,这也意味着,通过拓展高质量原则与精准批评的生成,RM的推理时间可扩展性有望实现突破。说不定,这一研究成果正是未来DeepSeek R2的雏形。
为助力大家深入探索这一前沿领域,我们精心挑选了一系列论文,涵盖多样创新视角与应用场景,希望能为各位的研究注入灵感,携手推动RL与LLM融合。
全部论文+开源代码需要的同学看文末!
【论文1】Inference-Time Scaling for Generalist Reward Modeling
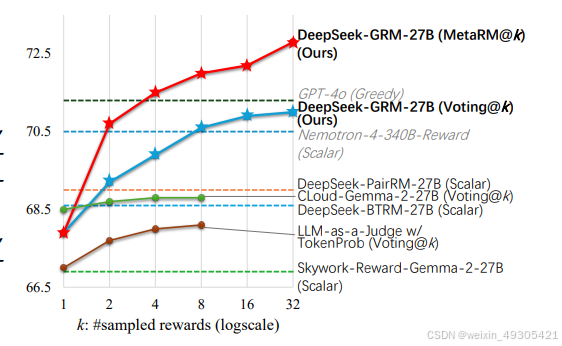
Inference-time scaling performance with different RMs on all tested RM bench-marks
1.研究方法
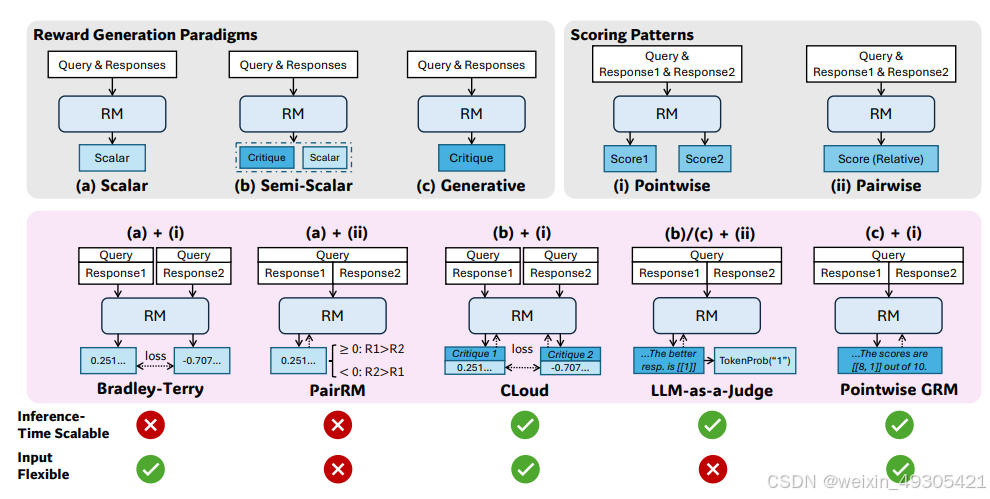
Different paradigms for reward generation, including (a) scalar, (b) semi-scalar, and (c) generative approaches, and different scoring patterns, including (i) pointwise and (ii) pairwise approaches
Deepseek的这篇论文采用逐点生成式奖励建模(GRM),通过基于规则的在线强化学习,提出 Self-Principled Critique Tuning(SPCT)方法。让 GRM 根据输入查询和响应自适应地生成原则和批判,进而优化奖励生成,还通过并行采样和元 RM 指导投票提升推理时的扩展性。
2.论文创新点
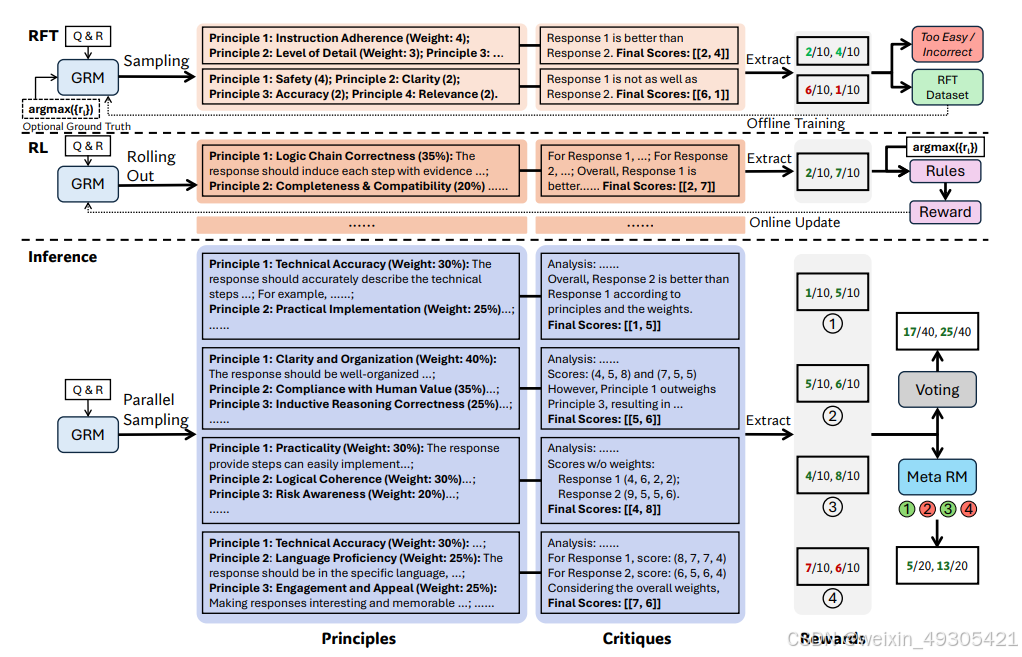
illustration of SPCT
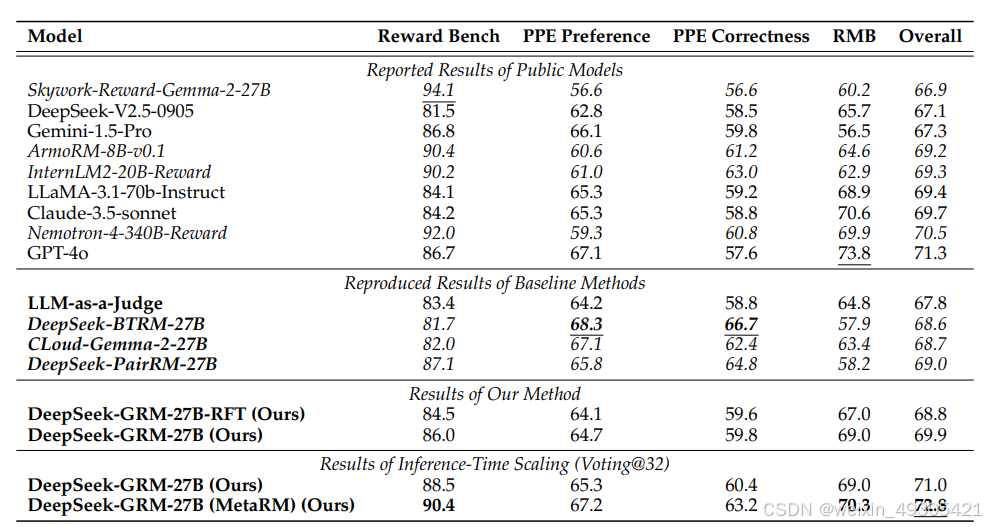
Overall results of different methods and models on RM benchmarks
-
新的学习方法:提出SPCT方法,增强通用奖励建模在推理时的可扩展性,使模型能自适应生成原则和批判,提升奖励质量,应用于GRM训练,得到DeepSeek-GRM模型。
-
高效推理扩展:利用并行采样扩展计算使用,引入元RM指导投票过程,提高推理时的扩展性和奖励信号质量,在多个RM基准测试中优于现有方法和模型。
-
性能优势:经实验验证,DeepSeek-GRM在推理时缩放性能出色,相比训练时缩放模型大小,能以更少的参数实现更好的性能,且具有输入灵活、领域泛化能力强等优点。
论文链接:https://arxiv.org/pdf/2504.02495
【论文2】DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
1.研究方法
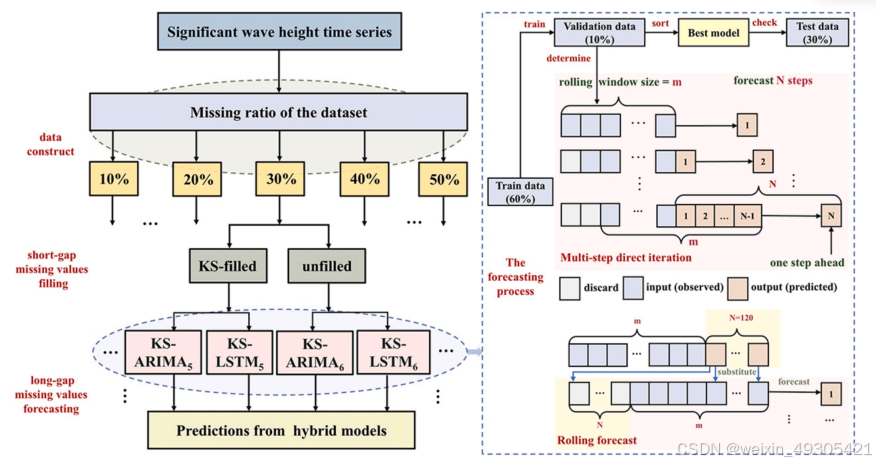
KS-LSTM flow chart to fill in the missing values of SWH.
这篇论文提出 KS-LSTM 混合模型,用于填补有效波高数据中的短期和长期缺失值。先利用卡尔曼平滑(KS)方法填充短期间歇性缺失值,通过递归估计系统状态,结合当前和过去观测值生成连贯平滑的时间序列;再基于 KS 处理后的序列,运用长短期记忆网络(LSTM)预测长期连续缺失值,利用 LSTM 捕捉复杂非线性模式和长期依赖关系的能力,实现对长期缺失值的有效填充 。
2.论文创新点
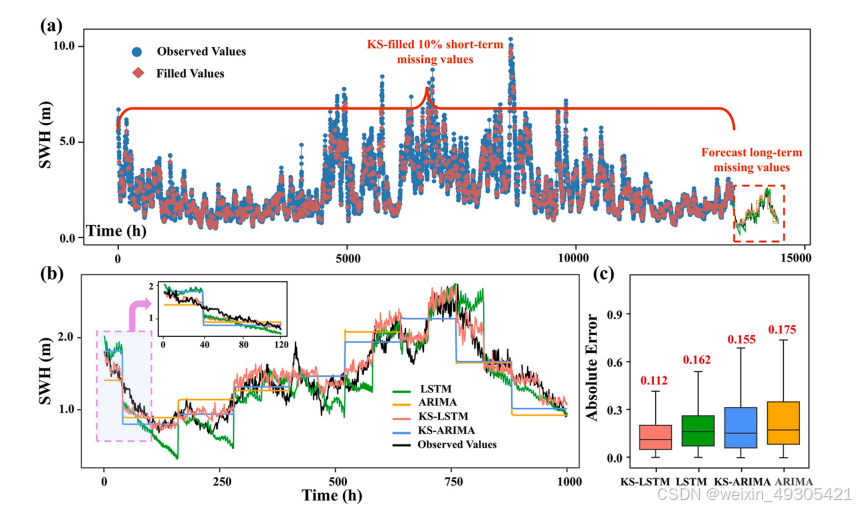
Filling plot for short- and long-term missing values:
-
混合模型设计:首次将KS与LSTM结合,针对有效波高数据缺失问题,发挥KS在短期缺失值填充的优势和LSTM处理长期依赖关系的能力,实现同时高效填补短、长期缺失值。
-
填补效果优势:在填充短期缺失值时,相比传统立方样条插值法,KS方法误差更低,如在10%和50%缺失率下,KS的RMSE明显低于立方样条插值法;在预测长期缺失值时,KS-LSTM相较于KS-ARIMA、LSTM和ARIMA,最大程度降低了预测误差,RMSE最大降低率分别达49.6%、59.4%和57.8%,展现出更强的泛化能力。
-
高适应性:KS-LSTM在不同缺失率(10%-50%)和不同类型数据条件下都表现稳定,在高缺失率场景下也能保持较低误差,如在浮标ID4数据缺失率达50%时,RMSE、MSE和MAE仍处于较低水平,适合处理复杂含缺失值的时间序列预测任务。
论文链接:https://arxiv.org/abs/2501.12948
关注下方《AI前沿速递》🚀🚀🚀
回复“C225”获取全部方案+开源代码
码字不易,欢迎大家点赞评论收藏

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 12
12 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)