DeepSeek + Dify 企业级大模型私有化部署指南
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。开始添加LLM模型,输入模型名称,类型,URL
一、为什么选择DeepSeek+Dify黄金组合?
1.1 企业级部署三大刚需解决方案:
1️⃣ 安全闭环:本地离线部署+数据物理隔离
2️⃣ 成本革命:16G显存即可运行7B模型
3️⃣ 敏捷开发:可视化工作流10分钟搭建AI应用
1.2 典型应用场景:
✔ 金融领域智能客服
✔ 医疗数据隐私分析
✔ 教育行业定制化教学
✔ 制造业知识库管理
二、部署环境准备指南
附Windows/Mac/Linux全平台配置方案
| 组件 | 最低配置 | 推荐配置 |
|---|---|---|
| GPU | NVIDIA T4 (可选) | RTX 4090 |
| 显存 | 16GB | 24GB |
| 内存 | 16GB DDR4 | 32GB DDR5 |
| 存储 | 50GB SSD | 1TB NVMe |
2.1 硬件配置说明
- 硬件配置清单
✅ 最低配置:
CPU:2核以上(推荐Intel Xeon系列)
内存:16GB DDR4
GPU:NVIDIA T4(可选)
存储:50GB SSD
✅ 推荐配置:
CPU:4核+(AMD EPYC系列)
显存:24GB(RTX 4090)
内存:32GB DDR5
网络:千兆内网
✅ 小编配置:
CPU: Intel® Xeon® CPU E5-2696 v4 @ 2.20GHz
显存:16GB(Tesla V100-PCIE-16GB) * 3
内存:256GB DDR4
网络:千兆内网
- 软件环境全攻略
📦 必装组件:
- • Docker 24.0+
- • Docker Compose 2.20+
- • Ollama 0.5.5+
- • Nvidia驱动535+(GPU加速需CUDA 12)
💻 多平台安装要点:
# Linux专项配置(Ubuntu示例)
sudo apt-get install -y nvidia-container-toolkit
sudo systemctl restart docker
# Windows特别提示
需启用WSL2并设置内存限制:
[wsl2]
memory=16GB
swap=0
三、部署核心组件(含路径/端口定制)
3.1 Ollama 配置
- Ollama深度配置
# 自定义安装路径(以/data为例)
mkdir -p /data/ollama && export OLLAMA_MODELS="/data/ollama/models"
# 启动服务指定端口(默认11434)
OLLAMA_HOST=0.0.0.0:11435 ollama serve &
# 模型下载加速技巧
export OLLAMA_MIRROR="https://mirror.example.com"
ollama run deepseek-r1:7b
# 国内镜像源配置(速度提升10倍+)
export OLLAMA_MIRROR=https://mirror.ghproxy.com/
ollama run deepseek-r1:7b
- 避坑版Ollama安装
# Windows特别版(解决路径含中文问题)
setx OLLAMA_MODELS "D:\ollama_models"
curl -L https://ollama.com/download/OllamaSetup_zh.exe -o ollama.exe
./ollama.exe
# 出现安全提示时选择"允许所有连接"
# Mac/Linux一键脚本(已处理权限问题)
curl -fsSL https://ollama.com/install.sh | sudo env PATH=$PATH sh
sudo systemctl enable ollama
- 组件连通性测试
# 验证Ollama服务
curl http://localhost:11434/api/tags
# 检查Dify容器
docker exec -it dify-api bash
ping host.docker.internal
3.2 Dify 部署方案
- Dify高级部署方案
# 指定部署路径(原docker目录可自定义)
git clone https://github.com/langgenius/dify.git /opt/ai-platform/dify
cd /opt/ai-platform/dify/docker
# 小编自定义路径为 /data1/home/datascience/item/ai-platform/dify
# 关键配置文件修改(.env示例)
vim .env
---
# 端口绑定设置
HTTP_PORT=8080
WEBSOCKET_PORT=8081
# 数据持久化路径
DATA_DIR=/data1/home/datascience/item/ai-platform/dify_data
# 启动命令(后台运行)
docker compose up -d --build

dify路径位置
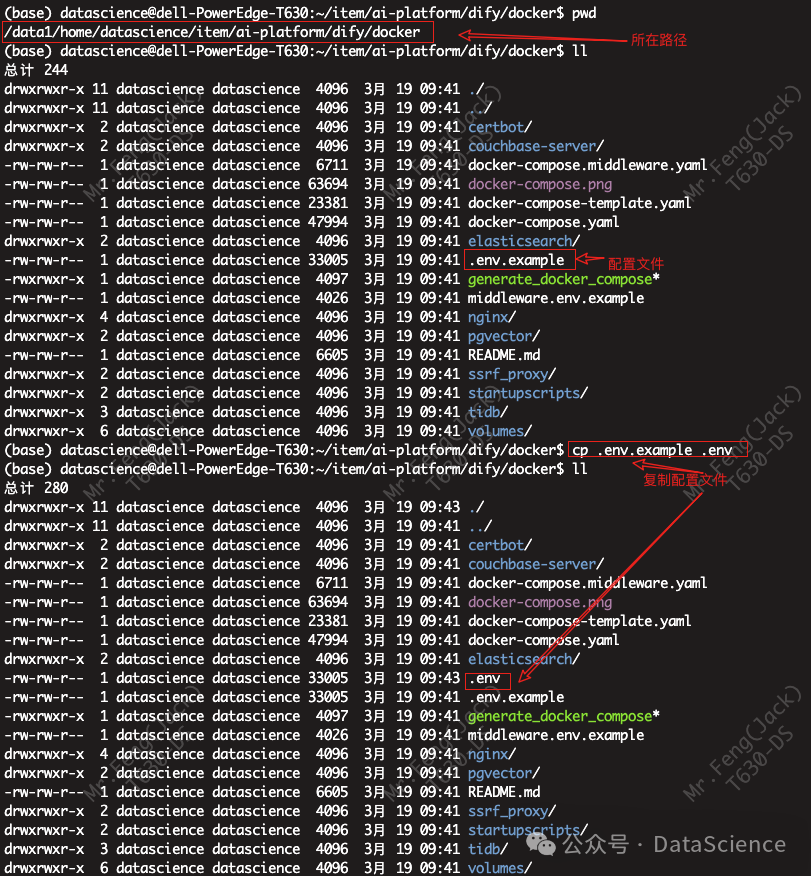
启动dify容器

在这个输出中,你应该可以看到包括 3 个业务服务 api / worker / web,以及 6 个基础组件 weaviate / db / redis / nginx / ssrf_proxy / sandbox 。

首先访问地址,进行初始化配置,记得替换为你的ip和端口,这里配置的第一个默认账号为超级管理员,切记注意保存。
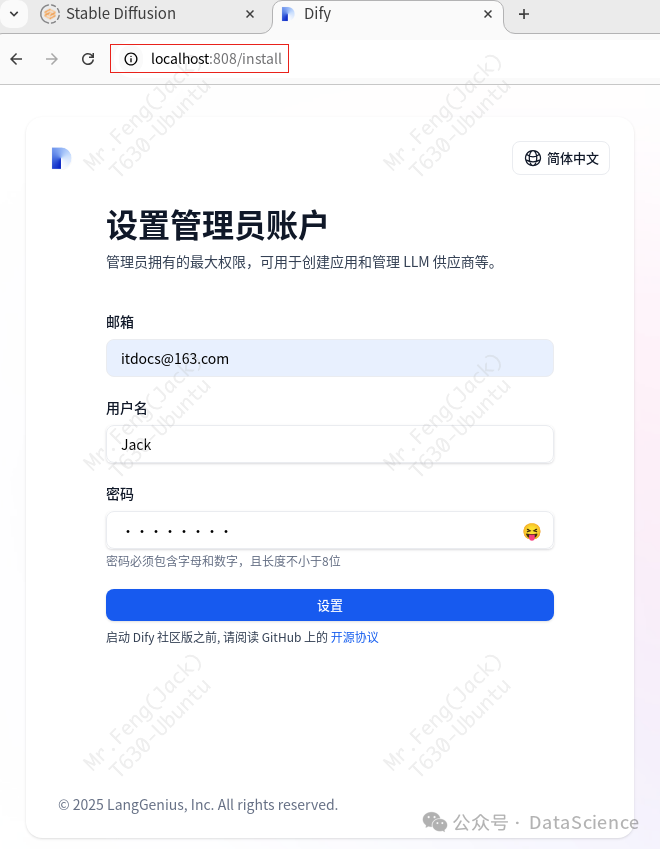
输入账号密码,登录dify,进入配置
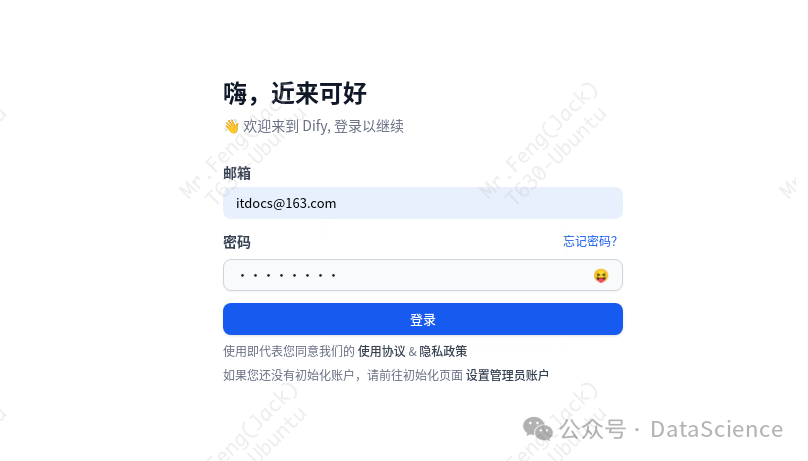
3.3 Dify平台深度集成指南
- 模型接入关键步骤
📍 路径:设置 > 模型供应商 > Ollama
🔧 配置参数详解:
Model Name:deepseek-r1:7b(需与Ollama模型名完全一致)
Base URL:
- 物理机部署:http://主机IP:11434
- Docker网络:http://host.docker.internal:11434
Temperature:0.7(对话类建议0-1)
Max Tokens:4096(7B模型实测上限)
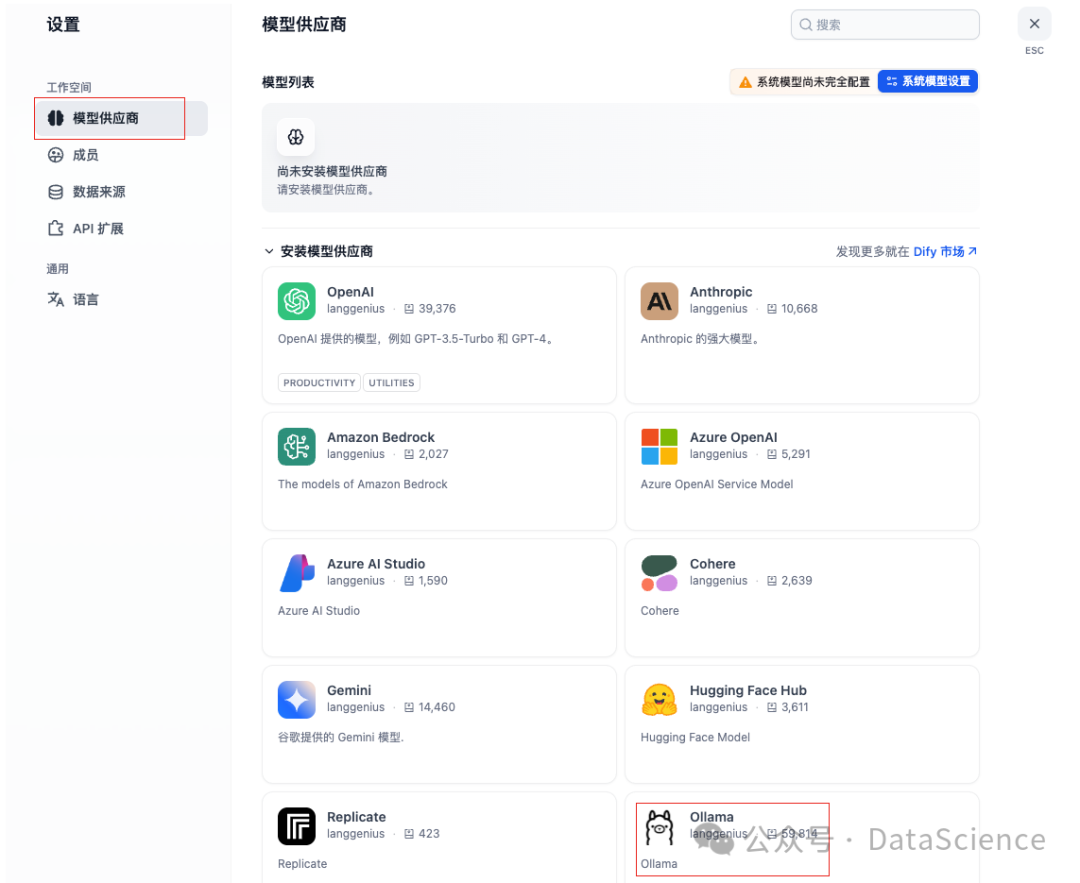
点击 ollama 选择安装
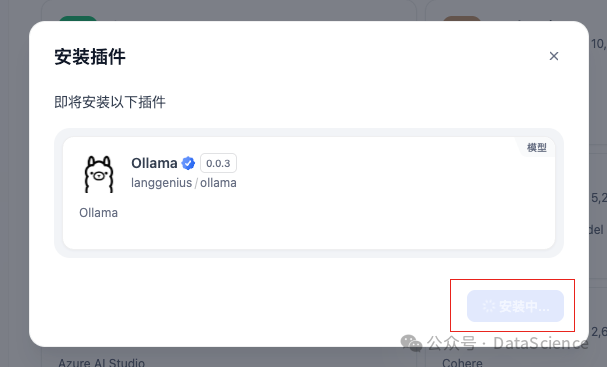
点击添加模型
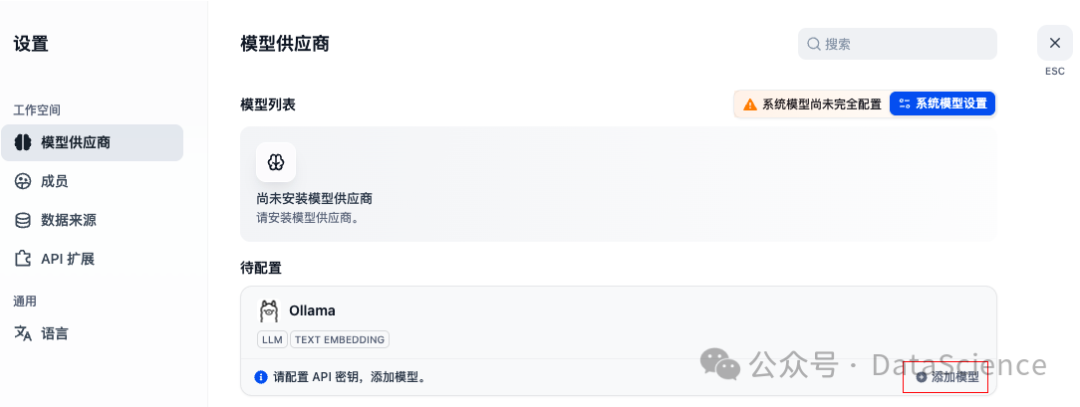
开始添加LLM模型,输入模型名称,类型,URL 为需要接入的模型server,例如本地部署的deepseek,当然你也可以接入其他api。例如deepseek官网,豆包,通义千问等。
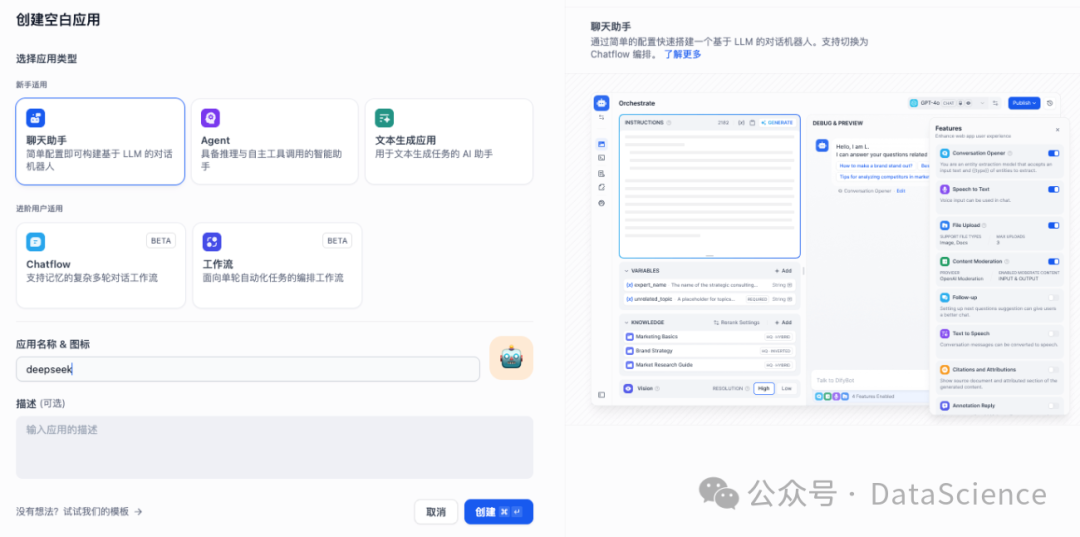
3.4 应用创建
创建空白应用,聊天助手,命名好你的应用名称
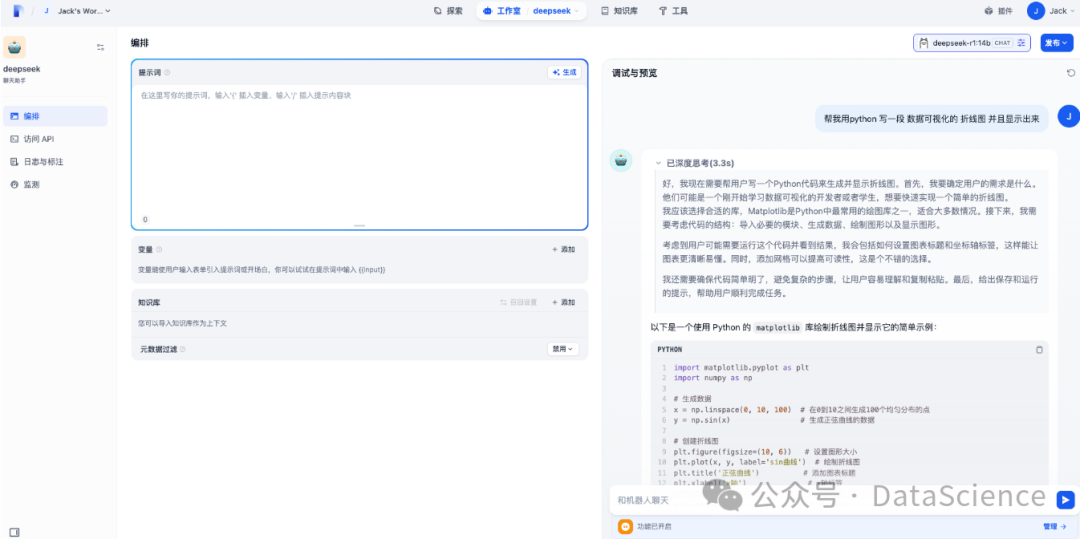
测试AI助手的使用,正常对话查看模型调用
3.5 企业级安全加固方案
🔒 传输加密:
# 反向代理配置示例(Nginx)
server {
listen 443 ssl;
server_name ai.example.com;
ssl_certificate /path/to/cert.pem;
ssl_certificate_key /path/to/key.pem;
location / {
proxy_pass http://localhost:8080;
proxy_set_header Host $host;
}
}
3.6 实战案例:10分钟构建智能客服系统
- 基础版Chatbot搭建
[创建应用] → [对话型] → 命名"DeepSeek客服助手"
↓
[模型选择] → Ollama → deepseek-r1:7b
↓
[提示词工程]:
"你是一名专业的客服助手,回答需符合以下要求:
1. 使用{{用户语言}}应答
2. 引用知识库:{{上传的PDF内容}}
3. 禁止透露模型身份"
3.7 避坑大全:高频问题解决方案
- 端口冲突终极处理
# 查看端口占用
lsof -i :11434
# 批量释放Dify资源
docker compose down --volumes --remove-orphans
# 强制重建服务
docker compose up -d --force-recreate
- 模型加载异常排查
# 查看Ollama日志
journalctl -u ollama -f
# 验证模型完整性
ollama ls
ollama show deepseek-r1:7b --modelfile
- 性能优化参数(7B模型实测)
# docker-compose覆盖配置
services:
api:
environment:
- WORKER_COUNT=4
- MODEL_LOAD_TIMEOUT=600
deploy:
resources:
limits:
cpus: '2'
memory: 8G
我的DeepSeek部署资料已打包好(自取↓)
https://pan.quark.cn/s/7e0fa45596e4
但如果你想知道这个工具为什么能“听懂人话”、写出代码 甚至预测市场趋势——答案就藏在大模型技术里!
❗️为什么你必须了解大模型?
1️⃣ 薪资爆炸:应届大模型工程师年薪40万起步,懂“Prompt调教”的带货主播收入翻3倍
2️⃣ 行业重构:金融、医疗、教育正在被AI重塑,不用大模型的公司3年内必淘汰
3️⃣ 零门槛上车:90%的进阶技巧不需写代码!会说话就能指挥AI
(附深度求索BOSS招聘信息)
⚠️警惕:当同事用DeepSeek 3小时干完你3天的工作时,淘汰倒计时就开始了。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?老师啊,我自学没有方向怎么办?老师,这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!当然这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
👉大模型学习指南+路线汇总👈
我们这套资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 28
28 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)