Deepseek联合清华公布推理的Scaling新论文R2详细解读
DeepSeek 提出了 DeepSeek-GRM-27B,它基于 Gemma-2-27B 用 SPCT 进行后训练。对于推理时间扩展,它通过多次采样来扩展计算使用量。通过并行采样,DeepSeek-GRM 可以生成不同的原则集和相应的批评,然后投票选出最终的奖励。通过更大规模的采样,DeepSeek-GRM 可以更准确地判断具有更高多样性的原则,并以更细的粒度输出奖励,从而解决挑战。

- 论文标题:Inference-Time Scaling for Generalist Reward Modeling
- 论文链接:https://arxiv.org/abs/2504.02495
研究背景
LLMs 发展迅速,强化学习(RL)用于其训练可提升性能,奖励建模(RM)是 RL 关键部分,能为 LLMs 生成奖励信号。但在通用领域获取高质量奖励信号困难,现有 RM 方法存在输入灵活性和推理时可扩展性问题,因此研究通用 RM 及有效推理时扩展方法很重要。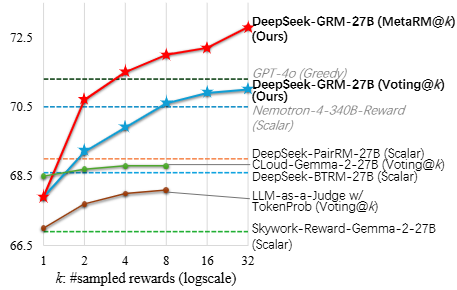
研究方法
- 采用逐点生成式奖励建模(GRM),统一不同响应格式评分,有输入灵活性和推理时扩展潜力。 提出 SPCT 方法,包括拒绝微调与基于规则的在线
RL 两个阶段。 - 拒绝微调让 GRM 适应多种输入,基于规则的在线 RL 优化原则和批评生成,使 GRM 能自适应生成原则和批评,提升奖励质量。
- 为实现推理时扩展,使用并行采样增加计算量,引入元 RM 指导投票,提升 DeepSeek-GRM 性能。
SPCT方法详解
1、将「原则」从理解转向生成
- 背景与挑战:在通用奖励建模中,合适的原则对生成高质量奖励很关键,但大规模生成有效原则颇具挑战。传统方式将原则视为预定义的固定规则或预处理步骤,难以适应多样化的任务和输入。
- 创新思路:SPCT 提出将「原则」从理解过程解耦,作为奖励生成的一部分。也就是说,不再把原则当作预先设定好的条件,而是让模型根据输入的查询和响应动态生成原则。
- 实现方式:通过函数
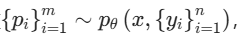
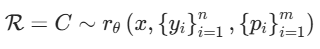
来实现,其中,Pθ是用于生成原则的函数,由参数θ表示,且与奖励生成函数rθ共享同一个模型架构。这样一来,原则能够基于输入动态生成,使奖励生成过程更具适应性。通过GRM进行后训练,还能进一步提升原则和对应点评内容的质量与细致程度,为推理时的可扩展性奠定基础。
2、基于规则的强化学习
- 方法构成:SPCT 结合拒绝式微调(Rejective Fine-Tuning)与基于规则的强化学习(rule-based
RL),其中拒绝式微调作为冷启动阶段。 - 拒绝式微调(冷启动):此阶段的核心是让 GRM 适应不同输入类型,以正确格式生成原则与点评内容。与以往混合使用不同格式 RM数据的方式不同,SPCT 采用点式GRM,在相同格式下灵活对任意数量的响应进行奖励生成。在数据构建上,除通用指令数据外,还从不同响应数量的 RM 数据中采样预训练 GRM的轨迹,对每个查询及响应执行(N_{RFT})次采样。若模型预测奖励与真实奖励不一致,或查询与响应在所有(N_{RFT})次采样中全部预测正确,则拒绝该轨迹。在实际操作中,预训练的GRM 在有限采样次数下难以生成正确奖励,因此引入提示式采样,将(max {l}{r{l}}_{l=1}^{n}) 作为提示附加到GRM 的提示语中,期望提高预测奖励与真实奖励的一致性 。不过,提示采样的轨迹在推理任务中有时会简化点评生成,这也凸显了在线强化学习对GRM 的必要性和潜在优势。
- 基于规则的 RL:使用基于规则的在线强化学习对 GRM 进一步微调,采用 GRPO 的原始设定和基于规则的结果奖励。在 rollout过程中,GRM 根据输入查询与响应生成原则与点评,提取预测奖励并通过准确性规则与真实奖励对比。与 DeepSeek-AI不同,这里不使用格式奖励,而是采用更高的 KL 惩罚系数,确保输出格式正确并避免严重偏差。通过奖励函数
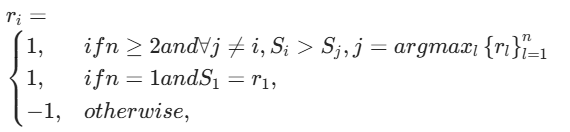
鼓励 GRM 通过在线优化生成的原则与点评内容,准确区分最优响应,提升推理阶段的可扩展性。这种奖励信号可无缝对接任何偏好数据集与标注的 LLM 响应 。
通过上述两个主要阶段,SPCT 能够让 GRM 自适应生成高质量原则和准确的点评内容,为大语言模型在不同领域生成更合理的奖励信号,显著提升奖励模型的质量和推理时的可扩展性,在多个综合 RM 基准测试中展现出优于现有方法和模型的性能 。
实验及结果
在多个 RM 基准测试中评估不同方法,DeepSeek-GRM-27B 在整体性能上优于基线方法,与强大的公共 RM 竞争性能相当;推理时扩展可进一步提升其性能。消融研究表明,SPCT 各组件对模型性能提升都很重要,元 RM 指导投票表现稳健。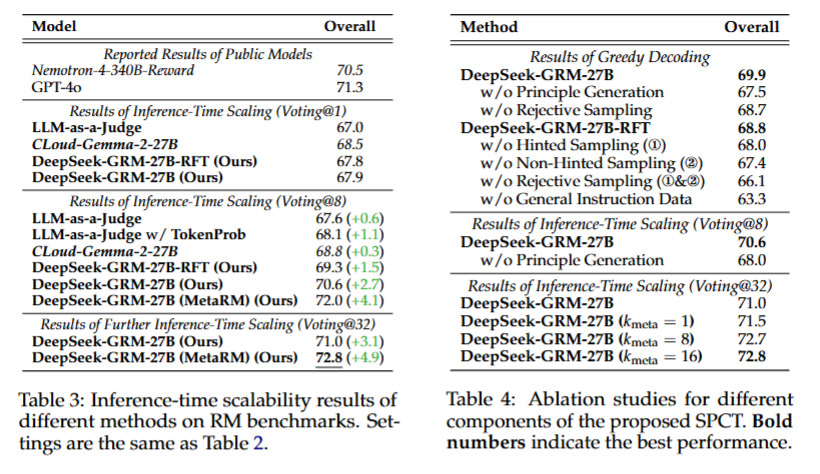
研究结果
SPCT 显著提升 GRM 奖励质量和推理时可扩展性,DeepSeek-GRM 在基准测试中表现出色。未来可将 GRM 集成到在线 RL 管道、探索与策略模型的推理时共扩展,或用于 LLM 离线评估等。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 19
19 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)