低资源消耗!用Ollama轻松本地部署运行DeepSeek-32B
前几天尝试了用vllm部署DeepSeek-32B模型,这次采用docker部署ollama,并运行DeepSeek-32B,废话不多说,直接上干货。
1、准备工作
Linux版本:Ubuntu 22.04.3 LTS
cuda版本:12.1
python版本:3.10.12
torch版本:2.3.1+cu121
docker版本:28.0.4
显卡:RTX 3090
模型权重文件:DeepSeek-R1-Distill-Qwen-32B-Q4_K_M.gguf,如果你只有12G显存建议下载使用DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf、DeepSeek-R1-Distill-Qwen-7B-Q4_K_M.gguf,如果你只有6G建议下载使用DeepSeek-R1-Distill-Qwen-1.5B-Q4_K_M.gguf
博主喜欢偷懒,安装了ubuntu 22.04.03 LTS,因为该版本自带的python版本是3.10.12版本,刚好与cuda12版本对应。
提前从官网下载torch-2.3.1+cu121-cp310-cp310-linux_x86_64.whl、torchaudio-2.3.1+cu121-cp310-cp310-linux_x86_64.whl、torchvision-0.18.1+cu121-cp310-cp310-linux_x86_64.whl
下载地址为:https://download.pytorch.org/whl/torch、https://download.pytorch.org/whl/torchaudio、https://download.pytorch.org/whl/torchvision
安装依赖包,指定用国内加速,要不然会下载很慢
pip install torch-2.3.1+cu121-cp310-cp310-linux_x86_64.whl torchaudio-2.3.1+cu121-cp310-cp310-linux_x86_64.whl torchvision-0.18.1+cu121-cp310-cp310-linux_x86_64.whl -i https://mirrors.aliyun.com/pypi/simple/模型权重文件可以直接去社区下载
2、环境搭建
安装nvidia驱动,可以使用autoinstall自动下载,也可以指定版本进行下载安装
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt update
ubuntu-drivers devices
sudo ubuntu-drivers autoinstall安装cuda-toolkit
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt-get update
sudo apt-get -y install cuda-toolkit-12-8配置环境变量
echo "export PATH=/usr/local/cuda-12.8/bin:$PATH" >> ~/.bashrc
echo "export LD_LIBRARY_PATH=/usr/local/cuda-12.8/lib64:$LD_LIBRARY_PATH" >> ~/.bashrc
source ~/.bashrcnvidia驱动和cuda-toolkit安装后,需要重启服务器,要不然驱动不生效
添加 NVIDIA Container Toolkit 仓库
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey \
| sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list \
| sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' \
| sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list更新包列表
sudo apt-get update安装 NVIDIA Container Toolkit 软件包
sudo apt-get install -y nvidia-container-toolkit配置Docker使用NVIDIA驱动程序,并重启docker
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker
#验证NVIDIA容器支持
sudo docker run --rm --gpus all nvidia/cuda:12.3.1-base-ubuntu22.04 nvidia-smi3、部署ollama
加载ollama推理镜像
sudo docker pull ollama/ollama:latest启动ollama容器
sudo docker run -d --gpus=all -v /home/models:/root/.ollama -p 11434:11434 --name ollama ollama/ollama:latest进入容器
sudo docker exec -it 404 /bin/bash#构建模型(方法1)
docker exec -it ollama ollama run qwen2构建deepseek-32b-gguf模型(方法2)
在容器使用Modelfile构建模型
cat > /root/.ollama/Modelfile <<EOF
FROM /root/.ollama/DeepSeek-R1-Distill-Qwen-32B-GGUF/DeepSeek-R1-Distill-Qwen-32B-Q4_K_M.gguf
PARAMETER num_ctx 2048
EOF
ollama create deepseek-32b-gguf -f /root/.ollama/Modelfile#验证模型是否加载成功
sudo docker exec -it ollama ollama list4、运行模型,并且测试
sudo docker exec -it ollama ollama run deepseek-32b-gguf运行模型之后,直接可以进行问答测试

查看显存占用,能看到GPU显存已被占21G
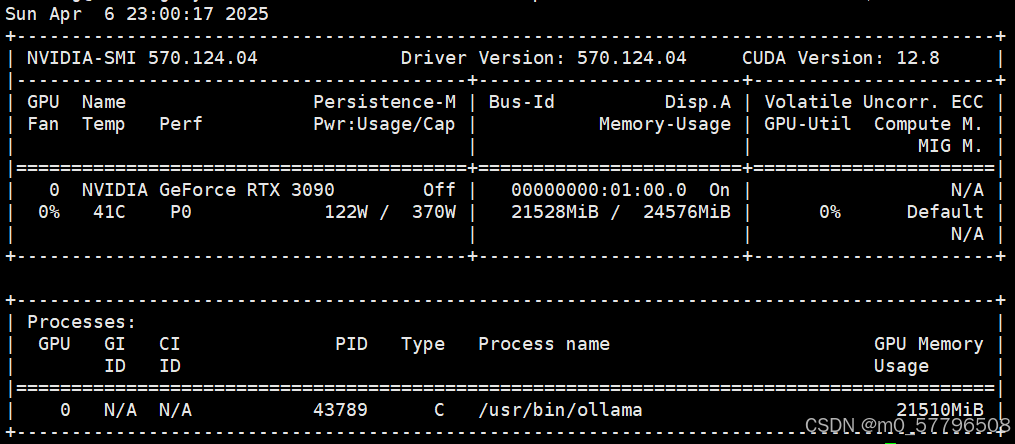
5、通过API调用测试
文本补全测试
curl http://localhost:11434/api/generate -d '{
"model": "deepseek-32b-gguf",
"prompt": "你好,你是谁?",
"stream": false,
"options": {
"temperature": 0.7,
"num_ctx": 2048
}
}'对话接口测试
curl http://localhost:11434/api/chat -d '{
"model": "deepseek-32b-gguf",
"messages": [
{ "role": "user", "content": "你是什么模型" }
],
"stream": false,
"options": {
"temperature": 0.6,
"num_ctx": 2048
}
}'兼容openai接口测试
curl http://localhost:11434/v1/chat/completions -d '{
"model": "deepseek-32b-gguf",
"messages": [
{"role": "user", "content": "你好"}
],
"max_tokens": 1024,
"temperature": 0.6
}'以上的接口测试都能正常返回结果,至此通过Ollama部署运行Deepseek-千问32B量化模型已经成功了,当然Ollama有web界面,如下图所示,具体操作步骤,博主就不演示了。


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)