使用一张RTX 3090显卡本地部署DeepSeek-R1模型
模型本地私有化部署
1、准备工作
Linux版本:Ubuntu 22.04.3 LTS
cuda版本:12.1
python版本:3.10.12
torch版本:2.5.1+cu121
博主偷了个懒,安装了ubuntu 22.04.03 LTS,因为该版本自带的python版本是3.10.12版本,刚好与cuda12版本对应。
提前从pytorch官网下载torch、torchaudio、torchvision依赖文件以下是对应具体地址:
https://download.pytorch.org/whl/torch
博主下载的是:torch-2.5.1+cu124-cp310-cp310-linux_x86_64.whl
2、环境搭建
安装前一定要确保服务器上已经安装了NVIDIA驱动,可以使用以下命令查看是否安装了NVIDIA驱动:
nvidia-smi
安装cuda驱动,可以先采用ubuntu-drivers devices命令查看推荐的NVIDIA驱动,recommended 表示 Ubuntu 推荐安装的版本(通常是最稳定的),
如果推荐的是12+版本,直接可以sudo ubuntu-drivers autoinstall自动安装推荐的cuda驱动,也可以指定版本安装cuda驱动sudo apt install nvidia-driver-560,也可以直接去NVIDIA官网下载.run文件进行安装,安装完成重启服务器后再次用nvidia-smi命令查看,如果显示cuda版本是12+,说明已经安装成功,一下是手动下载.run文件安装命令:
$ sudo apt update
$ sudo apt install -y software-properties-common
$ sudo add-apt-repository ppa:graphics-drivers/ppa
# 安装 CUDA 12.1
$ sudo sh cuda_12.1.0_520.61.05_linux.run
# 安装torch依赖,需要用国内加速,要不然安装的非常慢
$ pip install -i torch-2.5.1+cu124-cp310-cp310-linux_x86_64.whl torchaudio torchvision -i https://mirrors.aliyun.com/pypi/simple/
# 验证PyTorch 是否可以使用 GPU,输出True说明可以使用GPU
$ python -c "import torch; print(torch.cuda.is_available())"3、下载deepseek模型文件以及分词器
博主没那经济实力,只有一张RTX 3090,尽量将24G显存跑满,所以下载了DeepSeek-R1-Distill-Qwen-32B-GGUF量化模型
可以直接去hugging face官网或者是魔搭社区下载,博主具体下载的权重文件是DeepSeek-R1-Distill-Qwen-32B-Q4_K_M.gguf,分词器可以下载使用DeepSeek-R1-Distill-Qwen-32B蒸馏模型中的tokenizer_config.json,tokenizer.json两个文件。
4、搭建推理框架vLLM
博主为什么会选择vLLM,请看以下技术选型原因:
1、SGLang:大规模集群部署专家
2、Ollama:轻量级玩家最爱
3、vLLM:GPU推理性能王者
4、LLaMA.cpp:CPU部署救星
选择原因:要极致性能选vLLM,要简单易用选Ollama,要集群部署选SGLang,要CPU运行 → 选LLaMA.cpp
性能对比:
推理速度:vLLM > SGLang > Ollama > LLaMA.cpp
易用程度:Ollama > LLaMA.cpp > vLLM > SGLang
硬件要求:vLLM(需GPU) > SGLang > Ollama > LLaMA.cpp
如果你只有6G、8G、12G显存,可以尝试一下用docker下载Ollama镜像运行模型,部署起来非常简单。
目前市面上关于如何用Ollama拉取Q4或Q8量化模型进行本地推理的教程已经层出不穷,Ollama 确实以简单易用俘获了一大批开发者,但如果你和我一样,追求的是生产环境的稳定高效,那么Ollama可能就不适合你了。
为什么我最终选择了vLLM?因为Ollama在高并发和推理速度上,相比vLLM 真的弱了不少,尤其是在吃 GPU 算力的场景下。生产环境 Real Talk:如果你是认认真真要搞生产部署 DeepSeek-R1,vLLM 这种专为生产设计的框架才是更稳的选择。RTX 3090 最佳拍档:单卡3090 想发挥最大威力?vLLM 的优化更到位!SGLang 那种大规模集群方案,个人而言用不上。
目前我遇到的企业基本都是采用vLLM部署deepseek-千问32B,deepseek-llama70B蒸馏模型,甚至deepseek-R1满血模型,因为vLLM可以用--tensor-parallel-size 2命令将模型并行分布在多张 GPU 上运行,因为博主只有一张显卡,没有尝试。
5、启动DeepSeek推理服务
$ python3 -m vllm.entrypoints.openai.api_server \
--served-model-name DeepSeek-R1-Distill-Qwen-32B-GGUF \
--model /home/models/DeepSeek-R1-Distill-Qwen-32B-GGUF/DeepSeek-R1-Distill-Qwen-32B-Q4_K_M.gguf \
--trust-remote-code \
--host 0.0.0.0 \
--port 6006 \
--max-model-len 2048 \
--dtype float16 \
--enable-prefix-caching \
--enforce-eager \
--max_num_seqs 1 \
--api-key "1234567890" \
--tokenizer /home/models/tokenizer以上命令退出后就停止了,建议采用后台方式启动,也可以提前把启动脚本给写好,在进行启动。以下是后台启动方式。
nohup python3 -m vllm.entrypoints.openai.api_server \
--served-model-name DeepSeek-R1-Distill-Qwen-32B-GGUF \
--model /home/shawang/models/DeepSeek-R1-Distill-Qwen-32B-GGUF/DeepSeek-R1-Distill-Qwen-32B-Q4_K_M.gguf \
--trust-remote-code \
--host 0.0.0.0 \
--port 6006 \
--max-model-len 2048 \
--dtype float16 \
--enable-prefix-caching \
--enforce-eager \
--max_num_seqs 1 \
--api-key "1234567890" \
--tokenizer /home/shawang/tokenizer \
> vllm.log 2>&1 &根据博主的经验,以下便是最佳设置,说明如下:
• served-model-name,指定模型的名称。
• model,DeepSeek模型权重文件的路径。
• max-model-len,模型上下文长度。如果未指定,将继承模型自身配置。将max_model_len设置为2048、4096或8196,以找到在没有错误的情况下工作的最大值。如果取值过大,你可能会遇到OOM错误。
• max_num_seqs,用于配置同时处理多少个请求;由于这将使内存使用量增加一倍,因此将其设置为1。
• trust-remote-code,加载HuggingFace自定义代码时必须启用。
• host和port,设置ip和端口。
• dtype,权重和激活参数的数据类型,用于控制计算精度,常用float16/bfloat16。
• enforce-eager,用于启用 eager 模式,加快推理速度。
• enable-prefix-caching,重复调用接口时缓存提示词内容,以加快推理速度。例如,如果你输入一个长文档并询问有关它的各种问题,启用该参数将提高性能。
• api-key,API访问秘钥,设置一个字符串即可。
• tokenizer,分词器存储目录。
• tensor-parallel-size,指定GPU数量,单卡不用设置此参数。
启动如果是以下情况,说明启动成功
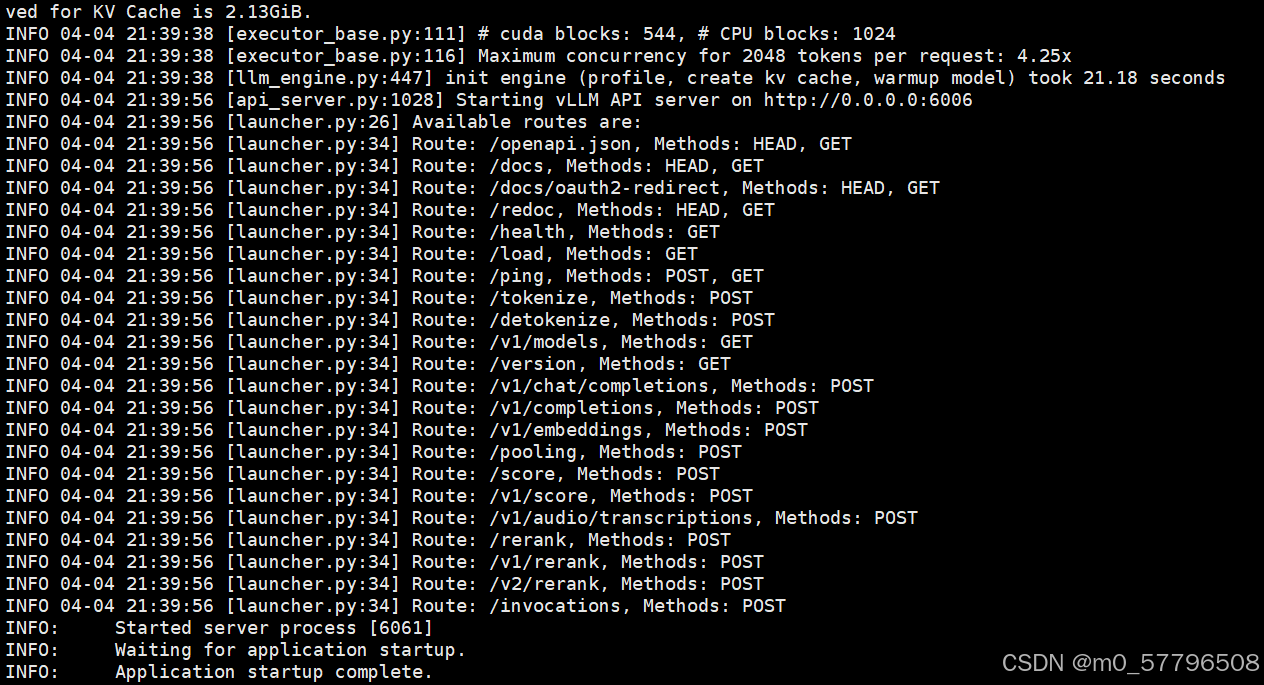
可以通过nvidia-smi查看显卡占用情况
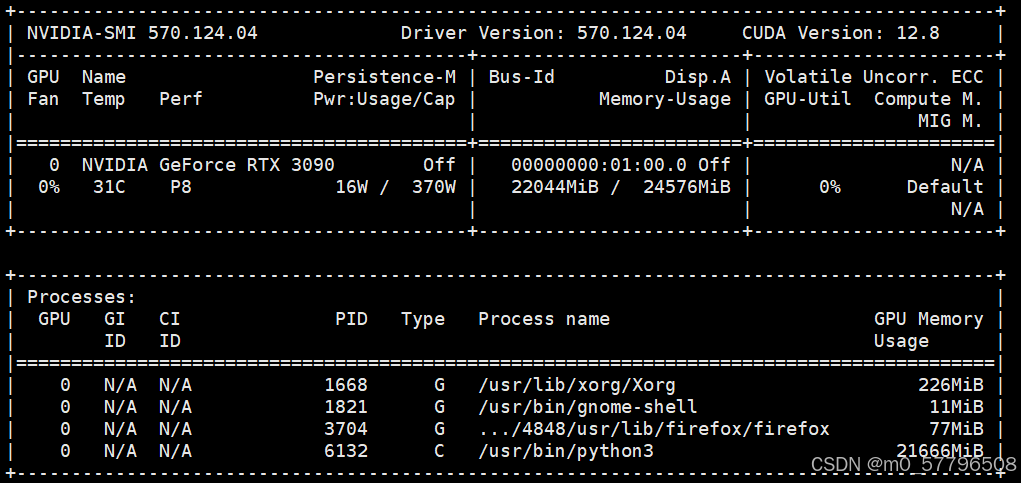
可以看到,加载DeepSeek后,24GB的显存已被占用22GB。
6、接口测试
通过浏览器访问http://127.0.0.1:6006/docs 查看vLLM支持的DeepSeek API接口
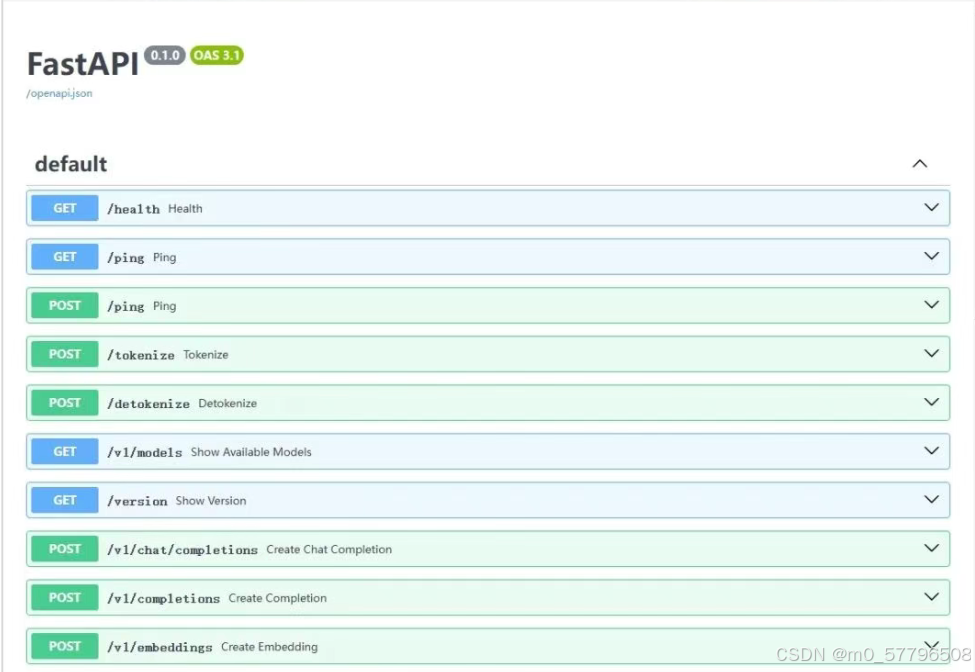
查看已加载的模型列表
curl http://localhost:6006/v1/models -H "Authorization: Bearer 1234567890"测试文本补全接口:
curl http://127.0.0.1:6006/v1/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer 1234567890" \
-d '{
"model": "DeepSeek-R1-Distill-Qwen-1.5B",
"prompt": "DeepSeek 是什么?",
"max_tokens": 100,
"temperature": 0.7
}'测试模型对话接口:
curl http://127.0.0.1:6006/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer 1234567890" \
-d '{
"model": "DeepSeek-R1-Distill-Qwen-1.5B",
"messages": [
{"role": "user", "content": "DeepSeek 是什么?"}
],
"max_tokens": 100,
"temperature": 0.7
}'以上的接口测试都能正常返回结果,至此通过vLLM部署运行Deepseek-千问32B量化模型已经成功了。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 45
45 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)