DeepSeek在计算机教育中的应用:实证案例研究
近年来,大型语言模型(LLMs)在计算机网络和安全领域的专业教育中展现了巨大的潜力。这些模型能够处理和表达复杂的概念,成为传统学习方法的有力补充。尽管初步研究表明LLMs在应用领域知识方面表现出色,但其在全面网络教育中的效能,尤其是涉及复杂技术概念和实际问题解决场景时,仍需通过标准化的专业基准进行系统评估。
近年来,大型语言模型(LLMs)在计算机网络和安全领域的专业教育中展现了巨大的潜力。这些模型能够处理和表达复杂的概念,成为传统学习方法的有力补充。尽管初步研究表明LLMs在应用领域知识方面表现出色,但其在全面网络教育中的效能,尤其是涉及复杂技术概念和实际问题解决场景时,仍需通过标准化的专业基准进行系统评估。
为评估DeepSeek-V3在计算机网络中的实际效果,本研究选取了两个权威测试数据集:最新的Cisco Certified Network Associate (CCNA)模拟题库和中国2022-2023年网络工程师认证考试的一部分。这两个考试涵盖了广泛的网络规划、安全和管理能力,将理论与实践问题相结合,提供了具有挑战性的题目以测试概念和应用知识。

图1:难度评估提示工程示意图,展示了用于评估试题难度的提示设计。
研究成果
本研究对DeepSeek-V3在计算机网络教育中的表现进行了系统评估,揭示了以下核心发现:
- 角色依赖性:实验表明,无论是否包含特定角色定义,模型均能保持一致的准确性和可靠性,体现了其捕捉上下文信息的能力。
- 跨语言性能:DeepSeek-V3在中文和英文问题上的表现略有差异,但统计上不显著。这表明模型在跨语言场景下具有较强的适应性。
- 问题类型表现:模型在低阶事实记忆任务上表现优异,但在高阶推理问题上存在明显局限,显示了其推理能力的提升空间。
- 主题表现:模型在安全性基础方面表现出高精度,但在网络工程师考试的不同主题上表现差异显著,特别是在IP连接性和网络访问等复杂内容上存在不足。
- 响应可重复性:当模型的回答高度一致时,其准确性显著提高,表明回答的一致性可以作为评估输出可靠性的指标。
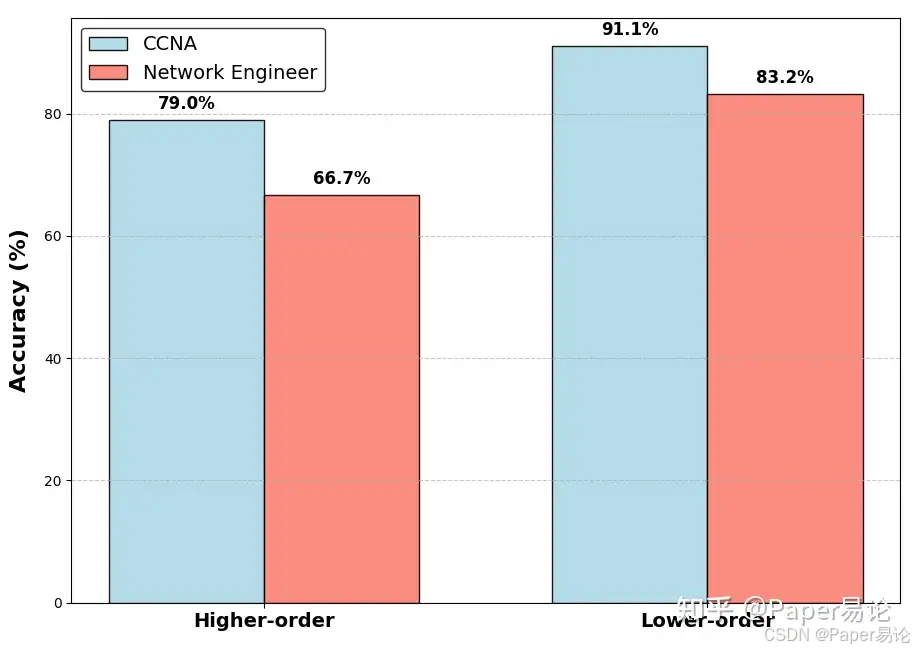
图4:高低阶问题准确率对比图,展示了模型在不同层次问题上的表现差异。
研究贡献
本研究对DeepSeek-V3在计算机网络教育中的应用进行了深入探讨,其主要贡献包括:
- 实证分析:提供了DeepSeek-V3在CCNA测试和网络工程师考试中的表现分析,揭示了其优势和局限性。
- 跨语言评估:验证了模型在中文和英文问题上的稳定表现,为其在多语言环境中的应用提供了依据。
- 问题类型分析:明确了模型在低阶和高阶问题上的表现差异,为未来模型优化指明了方向。
- 响应一致性评估:引入了响应可重复性作为评估模型可靠性的新指标,建立了其与准确性的强相关关系。

图5:DeepSeek-V3在不同主题上的表现图,展示了模型在各类主题中的精度差异。
实验过程数据
实验设计
本研究采用DeepSeek-V3官方API进行实验分析,模型基于混合专家(MoE)架构,总参数量达671亿,激活参数约37亿。预训练数据来自14.8万亿个标记化的多语言文本,涵盖网页文本、技术文档和学术出版物。
实验步骤
- 数据选择:从CCNA模拟题库和中国网络工程师考试题库中分别选取单选题和多选题,排除图像类问题后,最终得到122道中文考试题和199道CCNA考试题。
- 提示工程:设计标准化提示模板,确保模型输出格式统一,并要求模型对问题进行分类(低阶或高阶)。
- 数据收集:记录模型生成的答案、详细解释及问题分类,用于后续分析。
实验数据
| 项目 | CCNA Exam | Network Engineer Exam |
|---|---|---|
| 总题数 | 199 | 122 |
| 单选题准确率 | 87.4% | 82.0% |
| 多选题准确率 | 81.8% | - |
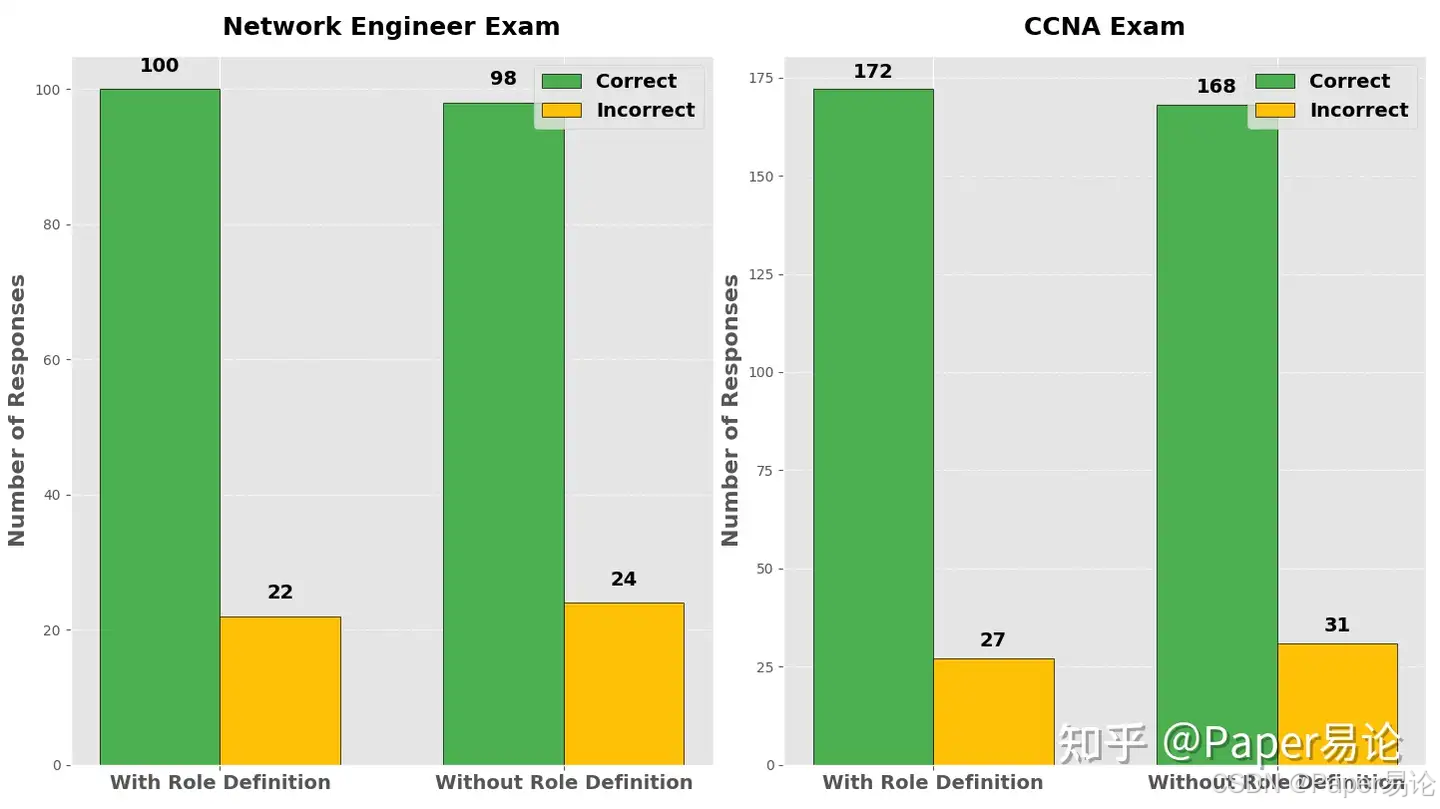
图3:提示设计对考试答案影响图,展示了有无角色定义条件下模型的表现差异。
结论
研究结果总结如下:
- DeepSeek-V3在低阶事实记忆任务中表现出色,但在高阶推理问题上存在局限。
- 模型在中文和英文问题上的表现一致,显示出良好的跨语言适应能力。
- 响应一致性与模型准确性呈强相关关系,可作为评估模型可靠性的有效指标。
对未来研究方向的展望:尽管DeepSeek-V3在网络教育中展现出显著价值,但其在处理多模态数据和复杂主题方面仍有待改进。未来的研究应进一步探索如何增强模型的推理能力和跨领域适应性,以更好地满足专业教育的需求。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 39
39 0
0- 0



 已为社区贡献79条内容
已为社区贡献79条内容

所有评论(0)