天津大学 | 深度解读DeepSeek:原理与效应(附44页PDF下载)
DeepSeek 作为大模型领域的创新代表,展现了技术创新的巨大潜力。期待未来它能与更多创新成果一起,推动大模型技术迈向新高度。
前言
在人工智能大模型的激烈竞争中,DeepSeek 异军突起,凭借其独特的技术原理和显著的应用效应,成为行业焦点。
天津大学自然语言处理实验室的《深度解读DeepSeek:原理与效应》,为我们全面解读了 DeepSeek 的奥秘,下面就让我们深入探索。
1、大语言模型
发展脉络中的 DeepSeek 坐标
大语言模型的发展历经多个阶段,从早期理论探索到如今生成式 AI 蓬勃发展。
生成式 AI 借助 Attention 机制、Transformer 架构、Scaling Laws、RLHF 等技术不断进化,o1/R1 等模型也推动着复杂问题求解能力的提升。
DeepSeek V2 - V3/R1 系列模型在这一发展进程中,凭借创新技术脱颖而出,成为大语言模型发展的重要参与者。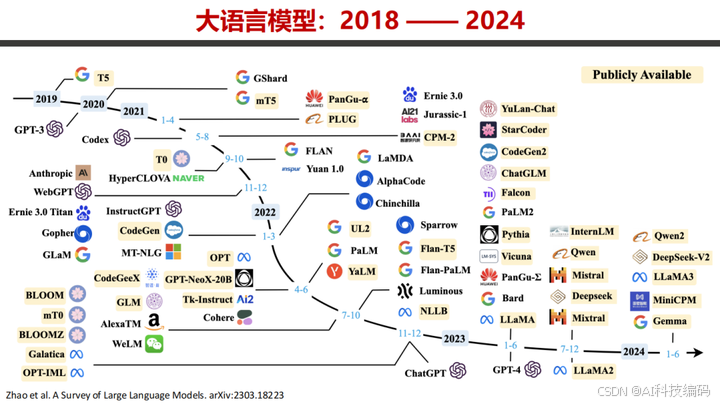
2、技术原理
DeepSeek 的创新引擎
V2 - V3:架构优化与性能提升
DeepSeek V2 通过 DeepSeekMoE 和 MLA 技术实现创新。
DeepSeekMoE 的稀疏激活设计减少计算量,细粒度专家及路由通信改造提升效率;MLA 降低 KV cache 占用空间。这些优化让 V2 在训练、存储和生成速度上表现出色。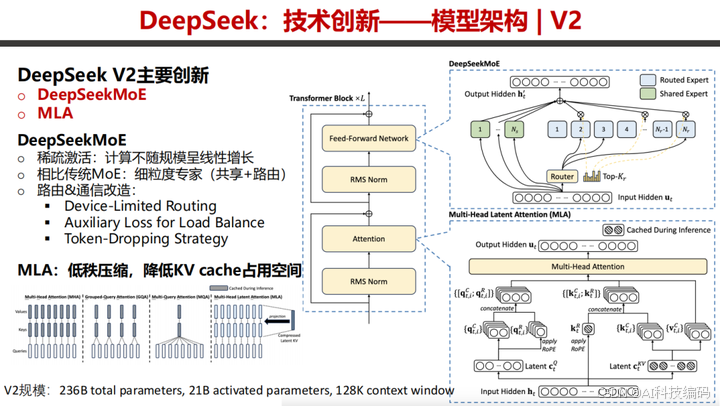
V3 进一步升级,引入 MTP 技术,一次可预测多个 token,同时优化基础设施,减少流水线气泡,实现高效通信,采用 FP8 训练和低精度存储。
V3 通过分布式训练优化显著降低算力消耗,达到强大性能,相比其他模型性价比优势明显。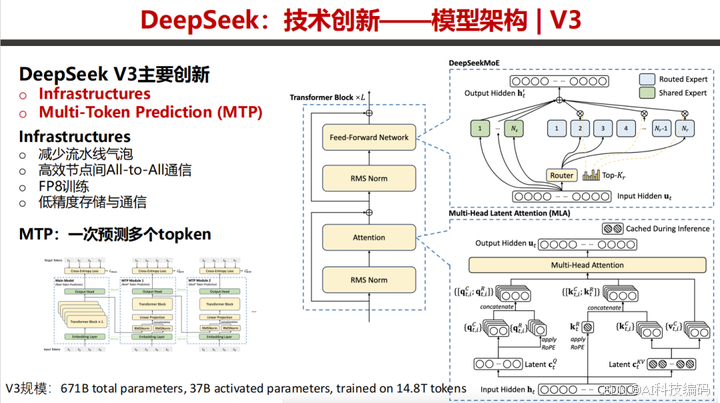
R1:推理模型的新突破
R1 的核心创新围绕推理能力。DeepSeek - R1 - Zero 通过大规模 RL 训练,发现 RL 训练的 Scaling Laws,训练中涌现多种能力。
不过,R1 - Zero 存在可读性差和语言混合的问题。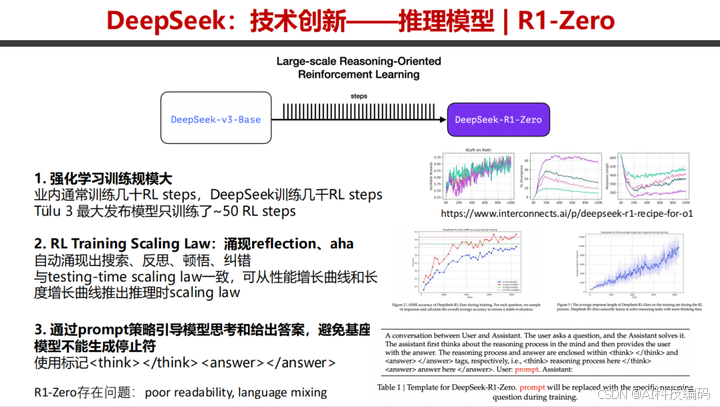
为此,R1 采用 4 步法训练框架,将推理与对齐结合。
强化学习训练框架使用 GRPO 算法,降低计算和存储开销,还采用多种奖励模型确保训练效果。
R1 还通过推理模型蒸馏,将大模型推理能力转移到小模型,效果优于小模型直接训练。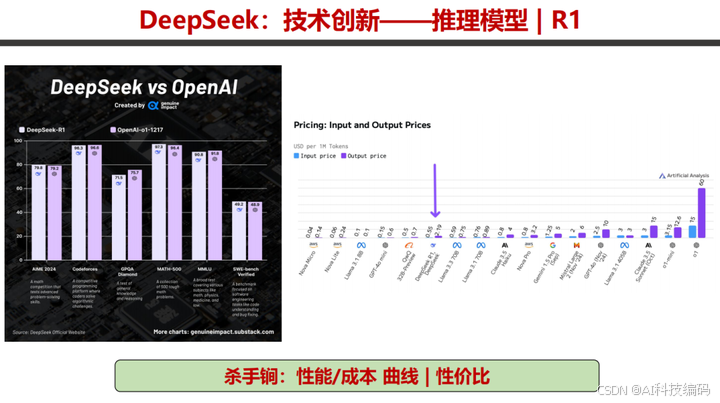
3、DeepSeek 效应
技术革新引发的行业变革
算力价格战的新变数
DeepSeek 凭借高性价比打破算力市场格局,其 V3 和 R1 在性能与成本对比中优势明显,突破了传统算力成本限制,推动行业在算力利用和成本控制方面创新。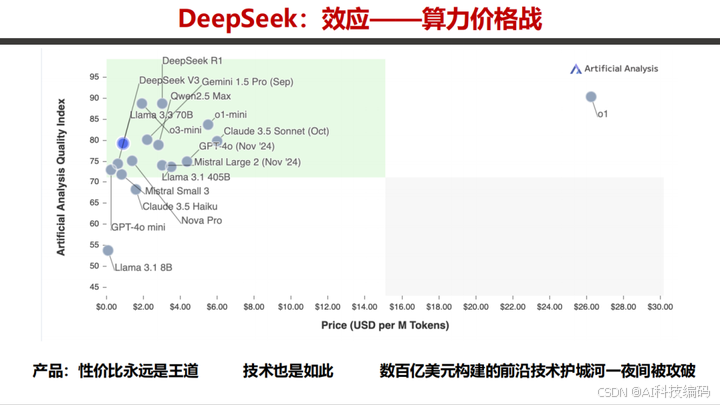
开源与闭源的新思考
DeepSeek R1 的开源是大模型发展的重要里程碑。
它打破了部分技术垄断,让更多人能接触和使用先进技术,推动技术共享与创新,为 AI 安全治理提供新思路,社区可共同参与模型改进和安全审查。
认知误区的颠覆
DeepSeek展示了中国在 AI 底层技术创新的实力。同时,它颠覆了大模型研发成本的传统观念,以相对低成本实现高性能,为更多参与者提供信心。
人才与创新的新契机
大语言模型发展依赖技术型和战略型人才。技术型人才突破创新,战略型人才指明方向。
4、未来展望
机遇与挑战并存
技术迭代的无限可能
未来 AGI/ASI 的实现或许还需 3 - 5 个重大突破。
DeepSeek 迭代速度快,R1 训练速度快,R2 有望很快发布。
R1 聚焦于数学、代码和逻辑推理,未来拓展更多领域的 RL 训练,将推动其向通用型模型发展,也为科研人员带来更多探索机会。
安全与发展的平衡难题
大模型发展中,安全问题日益重要。
DeepSeek R1 在提升推理能力时,安全性有所降低。不过,模型安全与推理能力并非对立,强大的推理能力可助力模型安全。
目前,DeepSeek R1 在危险目标和情景意识方面存在风险,未来需从技术创新、监管和评估等多方面入手,平衡安全与发展。
行业格局的重塑趋势
DeepSeek 已对大模型行业格局产生重大影响,未来这种影响还会持续。
随着技术进步,更多创新大模型将涌现,竞争愈发激烈。能在技术、成本、安全和人才培养等方面取得优势的参与者,将主导行业发展。
同时,国际合作也将成为大模型发展的关键趋势,各国共享技术经验,推动 AI 服务全人类。
结语
DeepSeek 作为大模型领域的创新代表,展现了技术创新的巨大潜力。期待未来它能与更多创新成果一起,推动大模型技术迈向新高度。
资料网盘自取:

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 38
38 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)