【Deepseek 学Cuda】double buffer 中涉及到全局内存到共享内存的搬运
asmvolatile::asmvolatile::asmvolatileasmvolatile学习double buffer 优化矩阵乘法, 看到了指令性的东西。
#include <cuda_runtime.h>
#include <mma.h>
using namespace nvcuda;
// 定义双缓冲异步加载的宏
#define CP_ASYNC_COMMIT_GROUP() asm volatile("cp.async.commit_group;\n" ::)
#define CP_ASYNC_WAIT_ALL() asm volatile("cp.async.wait_all;\n" ::)
#define CP_ASYNC_WAIT_GROUP(n) asm volatile("cp.async.wait_group %0;\n" ::"n"(n))
#define CP_ASYNC_CA(dst, src, bytes) asm volatile("cp.async.ca.shared.global.L2::128B [%0], [%1], %2;\n" ::"r"(dst), "l"(src), "n"(bytes))
学习double buffer 优化矩阵乘法, 看到了指令性的东西
// k = 0 is loading here, buffer 0
{
int load_gmem_a_k = load_smem_a_k; // global col of a
int load_gmem_a_addr = load_gmem_a_m * K + load_gmem_a_k;
int load_gmem_b_k = load_smem_b_k; // global row of b
int load_gmem_b_addr = load_gmem_b_k * N + load_gmem_b_n;
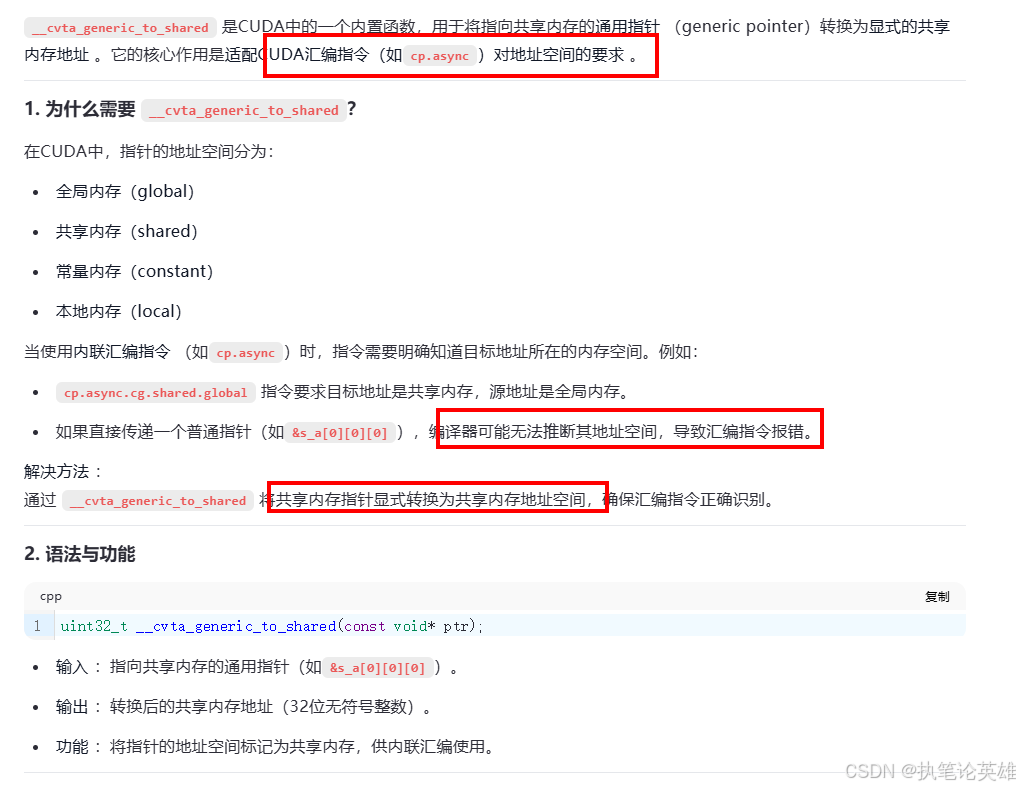
uint32_t load_smem_a_ptr = __cvta_generic_to_shared(
&s_a[0][load_smem_a_m][load_smem_a_k]);
CP_ASYNC_CG(load_smem_a_ptr, &A[load_gmem_a_addr], 16);
uint32_t load_smem_b_ptr = __cvta_generic_to_shared(
&s_b[0][load_smem_b_k][load_smem_b_n]);
CP_ASYNC_CG(load_smem_b_ptr, &B[load_gmem_b_addr], 16);
CP_ASYNC_COMMIT_GROUP();
CP_ASYNC_WAIT_GROUP(0);
}
__syncthreads();
1. 传统的 全局内存到共享内存是怎么搬用的
这里面涉及合并访问https://zhuanlan.zhihu.com/p/632244210
局内存到共享内存的搬运通常是通过线程块中的线程协作完成的。每个线程从全局内存读取数据,然后存入共享内存。这个过程可能涉及到缓存的使用,比如L1和L2。需要明确的是,数据从全局内存到寄存器,再到共享内存,因为共享内存只能由线程显式地读写。
接下来,关于L1和L2的经过路径。当线程访问全局内存时,首先会检查L1缓存(如果启用的话),然后L2缓存,最后才是全局内存。数据加载到L2是全局的,所有SM共享,而L1是每个SM内部的。如果数据在L1命中,则不需要去L2或全局内存。但搬运到共享内存的过程中,数据是否经过这些缓存?需要确认,当使用LDG指令(缓存加载)时,数据会被缓存到L1和L2,而如果使用绕过缓存的加载,可能直接到L2或者不经过。不过,通常情况下,全局内存访问默认使用L2,是否经过L1取决于编译选项和架构。
搬运的粒度方面,全局内存的访问有合并访问的概念,理想的合并访问是32字节、64字节或128字节的粒度,具体取决于架构。例如,从Pascal开始,L1缓存行是128字节,而全局内存访问的合并粒度通常是32字节(对应线程束的访问模式)。当线程束请求连续的数据时,如果地址对齐,可以最小化事务数量。搬运到共享内存时,可能每个线程加载一个数据元素,然后同步,确保所有数据到达共享内存后再使用。
但用户的问题还涉及到数据从全局内存到共享内存的传输是否经过L1/L2。需要明确,当数据从全局内存加载到寄存器时,会经过L2和可能的L1,然后线程将数据从寄存器写入共享内存。所以,**共享内存的数据不会直接来自缓存,而是必须通过寄存器中转。**这一点很重要,因为共享内存的延迟较低,但需要显式管理
__global__ void kernel(float* global_data) {
__shared__ float shared_data[128];
int tid = threadIdx.x;
// Step 1: 全局内存 → 寄存器(通过L1/L2缓存)
float reg = global_data[tid];
// Step 2: 寄存器 → 共享内存
shared_data[tid] = reg;
__syncthreads();
// 后续使用共享内存数据...
}
1. 异步搬运 全局内存到共享内存是怎么搬用的
假如缓冲中没有数据, 怎么从全局内存搬到共享内存和缓冲的,以及缓冲的时机?结合cp.async.ca.shared.global指令进行分析,给出详细的过程
使用异步拷贝指令可以绕过这一步,直接从全局内存到共享内存
全局内存到共享内存的搬运通常需要线程显式地将数据从全局内存加载到寄存器,再存储到共享内存。但使用异步拷贝指令可以绕过这一步,直接从全局内存到共享内存,可能通过DMA(直接内存访问)进行。同时,数据在搬运过程中可能经过缓存,比如L1或L2,这取决于指令的修饰符和架构的设定。
例如,在NVIDIA的文档中,提到cp.async可以结合缓存修饰符,如.cg(cache global,L2缓存)和.ca(cache all,L1和L2)。例如,cp.async.ca.shared.global可能意味着在加载到共享内存的同时,将数据缓存到L1和L2,而.cg则只缓存到L2。
另一个关键点是异步拷贝的执行流程。异步拷贝操作由线程发起,但实际的数据传输由硬件在后台执行,不需要线程的进一步参与。线程可以继续执行其他指令,同时数据传输在后台进行。之后,需要通过cp.async.wait_all或类似的同步指令来确保数据传输完成,然后再访问共享内存中的数据。
那么,当缓存中没有数据时,整个流程可能是这样的:
-
线程发起
cp.async.ca.shared.global指令,指定源地址(全局内存)和目标地址(共享内存)。 -
内存系统检查L1缓存,发现未命中,继续检查L2缓存。
-
L2也未命中,因此从全局内存中获取所需数据。
-
数据被加载到L2缓存,然后到L1缓存(由于
.ca修饰符),同时数据也被写入共享内存。 -
数据传输完成后,共享内存中的数据可用,同时L1和L2缓存中也保存了该数据的副本,供后续访问使用。
不过,这里可能存在一个疑问:数据是同时加载到共享内存和L1缓存,还是先到缓存再复制到共享内存?或者说,共享内存的加载是否绕过了缓存?
需要明确的是,共享内存和L1缓存是独立的。在之前的架构中,L1缓存和共享内存共享同一块物理内存,但在较新的架构中(如Ampere),它们可能是分开的。例如,在Ampere中,每个SM的L1缓存和共享内存是独立的,共享内存是软件管理的,
而L1是硬件管理的缓存。
因此,当使用cp.async.ca.shared.global指令时,数据从全局内存加载到共享内存,同时根据修饰符.ca,可能也会在L1缓存中缓存该数据。但共享内存本身并不在缓存层次结构中,而是独立的。因此,缓存的是全局内存的数据,而共享内存的数据是直接加载的,不经过缓存。
或者,可能的情况是,异步拷贝操作在将数据从全局内存传输到共享内存的同时,也触发了缓存的填充,即将该数据块也加载到L1和L2缓存,以便后续对全局内存的访问可以更快。
但这里可能存在混淆,因为共享内存的数据是显式管理的,而缓存是自动管理的。因此,当使用异步拷贝指令时,数据直接从全局内存到共享内存,而缓存可能不会被填充,除非有其他的访问触发了缓存。
或者,cp.async.ca中的.ca可能指示在拷贝的同时,将该数据也缓存到L1,以便后续对全局内存同一地址的访问可以更快。
这可能需要查阅具体的指令修饰符的含义。例如,.ca可能代表“cache at all levels”,即缓存到L1和L2,而.cg是“cache global”,即只缓存到L2。所以,当使用cp.async.ca.shared.global时,数据会被加载到共享内存,并且对应的全局内存地址的数据会被缓存到L1和L2。这样,后续对全局内存的访问可以利用缓存。
但异步拷贝到共享内存的数据本身是放在共享内存中的,而缓存中的是全局内存的数据。这可能是两个不同的副本。例如,共享内存中的是显式拷贝的一份,而缓存中保存的是全局内存的副本,供其他可能访问同一全局内存地址的线程使用。
查看用户提供的代码中的定义:
#define CP_ASYNC_CG(dst, src, bytes) asm volatile(“cp.async.cg.shared.global.L2::128B [%0], [%1], %2;\n” ::“r”(dst), “l”(src), “n”(bytes))
这里,CP_ASYNC_CG被定义为一个内联汇编指令,使用了cp.async.cg.shared.global.L2::128B这样的PTX指令。需要分解这个指令的各个部分。
cp.async.cg.shared.global.L2::128B 是PTX中的异步拷贝指令,其中:
- cp.async 表示异步拷贝操作。
- cg 是缓存操作的提示,可能指使用L2缓存的全局内存访问。
- shared.global 表示从全局内存到共享内存的拷贝。
- L2::128B 可能指定了L2缓存的传输粒度为128字节。
参数部分:
- [%0] 是目标地址(共享内存),由dst参数传入。
- [%1] 是源地址(全局内存),由src参数传入。
- %2 是传输的字节数,由bytes参数指定。
接下来,需要解释这个指令的作用。它异步地将全局内存中的数据拷贝到共享内存,使用L2缓存优化,并且可能以128字节的块进行传输。这种异步操作允许在数据传输的同时执行其他计算,从而隐藏内存延迟。
进一步,阅读https://zhuanlan.zhihu.com/p/685168850
为什么L2缓存的传输粒度为128字节, 但是用户传入的是16?

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 2
2 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)