大模型评测【行业应用篇】法律行业|律师资格考试,108个大模型应用实测横评!
法律行业-律师资格考试应用评测,评测结论:百度系大模型得分第一!腾讯系大模型包揽第2、第3名、第4名,DeepSeek排名第5名,前5名中hunyuan-large和DeepSeek-R1是唯二的开源模型。
继续评测,本期安排上了应用于法律行业的大模型能力评测,涉及律师资格考试的专业知识评测。同时,律师等领域不同类型、不同阶段、不同科目的评测,都在爆肝输出中,敬请期待。
一、评测结论:
百度系大模型得分第一!腾讯系大模型包揽第2、第3名、第4名,DeepSeek排名第5名,前5名中hunyuan-large和DeepSeek-R1是唯二的开源模型。
二、评测维度:
针对律师资格考试所涉及的专业知识,构建评测题集(累计3000+),进行评测。
各科目完整评测题集及结果详见:https://github.com/jeinlee1991/chinese-llm-benchmark
三、评测方法:
根据以上评测维度,输出3000+选择题,分别让各个大模型进行回答,根据结果进行打分,并统计每个大模型的答题准确率,输出综合得分和排名。每一个大模型评测的评测题集、评测得分、评测错题,均可见、可查询、可溯源!
我们的目标是:
通过评测为大家透视化呈现,各个大模型的能力边界,以支持大家高效使用!
*评测综合得分排名(图)|绿色(闭源),蓝色(开源)
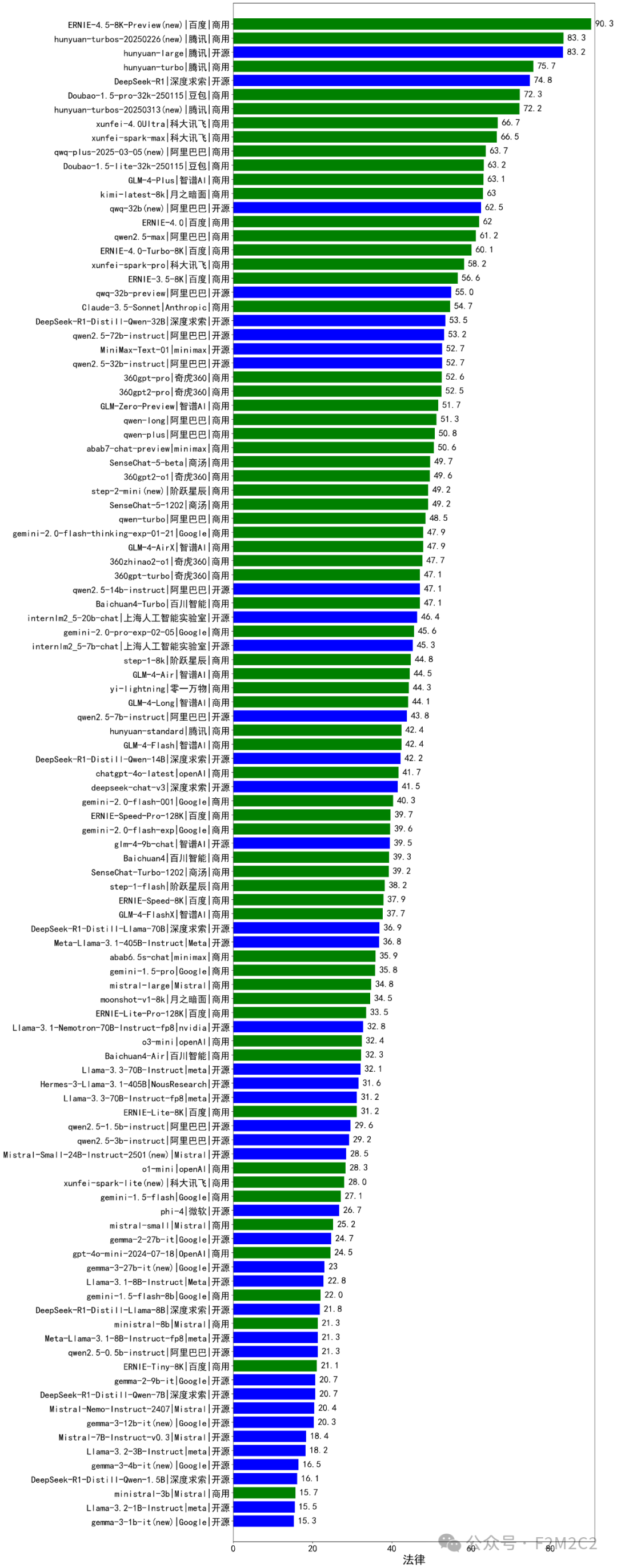
*实测大模型列表、得分和排名:

完整评测题集及结果详见:https://github.com/jeinlee1991/chinese-llm-benchmark
往期文章
教育行业|小学至高中3个阶段、9个学科、110个大模型应用实测!
Llama/Qwen/DeepSeek开源之争——CLiB开源大模型排行榜03.04
那些免费的大模型API效果到底好不好?——CLiB大模型排行榜
关于大模型评测EasyLLM
-
最全——全球最全大模型产品评测平台,已囊括203个大模型
-
最新——月更各个大模型各项能力指标评测,输出排行榜
-
最方便——无需注册/梯子,国内外各个大模型可一键评测
-
结果可见——所有大模型评测的方法、题集、过程、得分结果,可见可追溯!
-
错题本——百万级大模型错题本
大模型评测EasyLLM目前已囊括203个大模型,覆盖chatgpt、gpt-4o、o3-mini、谷歌gemini、Claude3.5、智谱GLM-Zero、文心一言、qwen-max、百川、讯飞星火、商汤senseChat、minimax等商用模型, 以及DeepSeek-R1、deepseek-v3、qwen2.5、llama3.3、phi-4、glm4、书生internLM2.5等开源大模型。不仅提供能力评分排行榜,也提供所有模型的原始输出结果!
完整评测题集及结果详见:https://github.com/jeinlee1991/chinese-llm-benchmark


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 13
13 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)