DeepSeek R1 & R2 技术原理详解,你不能不知道的DeepSeek干货!!
传闻 DeepSeek R2 今天上新,东大时区已过,难道是阿美时间?不必失望,笔者20多年职业生涯学到一个深刻道理是:所有的 rumor 都是真的。
前言
传闻 DeepSeek R2 今天上新,东大时区已过,难道是阿美时间?不必失望,笔者20多年职业生涯学到一个深刻道理是:所有的 rumor 都是真的。

DeepSeek不愧是国产之光,V3, R1系列模型以其卓越的性能和开源创新席卷全球。
相应技术文档分享了多项关键技术突破,为高效、可扩展的大模型训练与推理奠定了基础。
R1发布给行业带来的天翻地覆的震动波还在激荡,R2很快就可能接踵而至了。借此机会,笔者梳理一下DeepSeek R1&R2超越其他对手的核心秘方。
一、GRPO与软归纳偏好
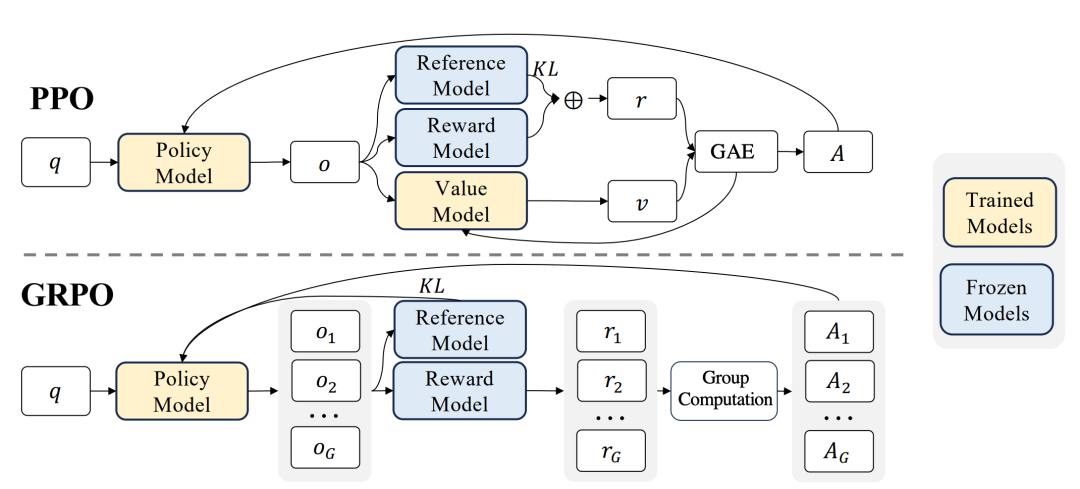
DeepSeekMath的组相对策略优化(GRPO)是R1成功的关键,核心思想是:
笔者看来,GRPO 的关键优势在于:策略模型可以在更大更灵活的假设输出空间中搜索解;组内相对奖励估计构成软性偏好,引导模型趋向更优解。 一个大的假设输出空间,加上对简单解的偏好,提供了一种可证明的非常有效的保障良好泛化性能的方案,即【文献1】中定义的软归纳偏好。
学者用软归纳偏好来解释,深度神经网络的异常泛化行为,包括良性过拟合、双下降现象以及过参数化的奇特效果。
软归纳偏好是解释这些异常泛化现象的关键统一原则:
与其通过限制假设输出空间来避免过拟合,不如拥抱一个更大更灵活的假设解的搜索空间,同时通过某种机制对与数据一致的简单解赋予软性偏好。
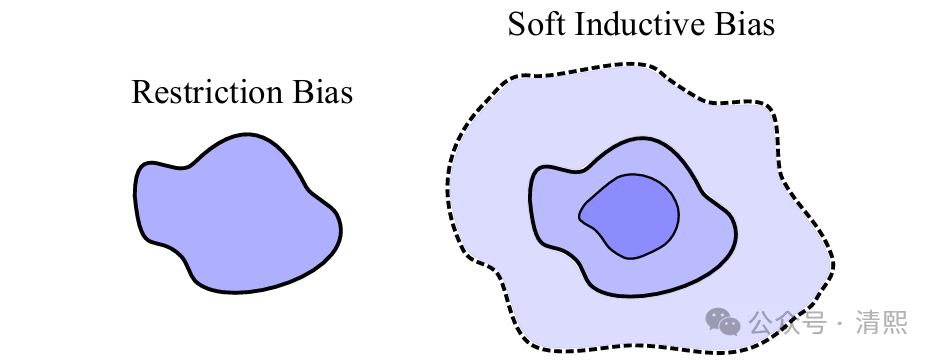
笔者认为GRPO 可以看作是软归纳偏好在强化学习领域的一种具体实现形式,能够很好解释scaling law和顿悟(grokking)等涌现泛化现象:
软归纳偏好被定义为对某些解的偏好,即使这些解对数据的拟合效果相同。下图展示了通过软归纳偏好实现良好泛化的过程。
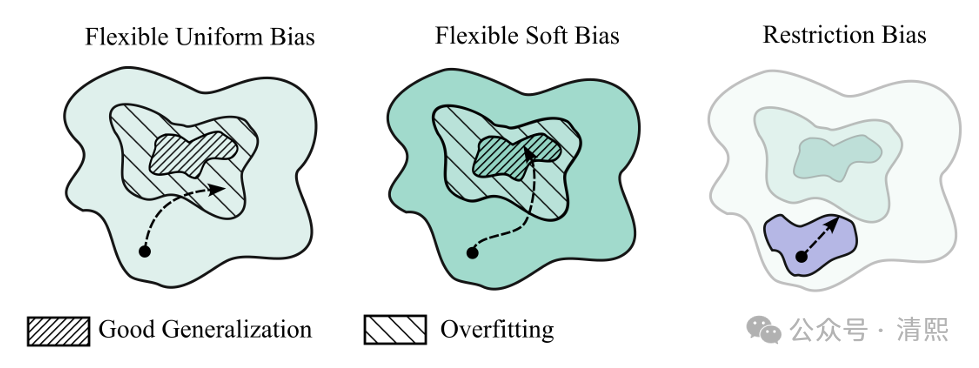
左图:一个大的假设空间,但对拟合数据效果相同的解没有偏好,因此训练通常会导向过拟合的解,泛化能力较差。
中图:软归纳偏好通过结合灵活的假设空间和对解的偏好(用不同深浅表示)来引导训练,从而实现良好的泛化。
右图:限制假设空间可以通过仅考虑具有某些理想属性的解来帮助防止过拟合,但限制表达能力,模型无法捕捉现实的细微差别,从而阻碍泛化。
残差路径先验(Residual Pathway Priors, RPP)研究表明,给定问题,软偏好对于等变性的效果通常与完美约束的模型一样好。
在仅接触少量数据后,软偏好会收敛到近乎完美的旋转等变性,因为模型被鼓励以对称性表示数据,并且即使数据量很小,它也可以精确地做到这一点。
此外,在数据仅包含近似对称性或完全没有对称性的情况下,软偏好RPP方法的表现显著优于具有硬对称性约束的模型。
等变性对称性提供了压缩数据的机制,而transformer具有一种软归纳偏好,倾向于压缩数据。训练后的vision transformer甚至比CNN更具平移等变性!
软归纳偏好(而非限制假设空间)是构建智能系统的关键处方,GRPO是个成功的实现,所以笔者说:GRPO 是DeepSeek魔法的源泉。
二、内存墙****与 I/O感知
为执行运算,GPU必须将数据从高层级的 DRAM 移动到低层级的计算核,因而GPU 的性能不仅受限于计算能力(TFLOPs),还受限于内存带宽(GB/s)。
现在大模型已经撞到了内存墙——随着计算能力的提升速度(×3/2年)远快于 DRAM 带宽的提升速度(×1.6/2年),算法越来越受限于带宽/传输成本。
此外,DRAM 已占系统总功耗的 46%,随着内存相对于计算效率的逐渐降低,考虑传输成本 I/O 感知 变得非常关键。大力出奇迹,还得当心很多白费蛮力。
这应该是DeepSeek AI工程团队做了大量的对英伟达芯片集群性能的极限优化与提升的更深层次的原因。可见于通信与混合精度的惊艳工作:
DualPipe通信优化,在前后向微批次内部和之间叠加计算和通信阶段,从而减少了流水线低效。
特别是,分发(将token路由到专家)和合并(聚合结果)操作通过定制的PTX(并行线程执行)指令与计算并行处理,绕过CUDA与NVIDIA GPU接口并优化其操作。

某种意义上说,DeepSeek 实际上是为 GPU 集群中的all对all通信创建了自己的 GPU 上的虚拟 DPU,用于执行各种与 SHARP 类似的操作。
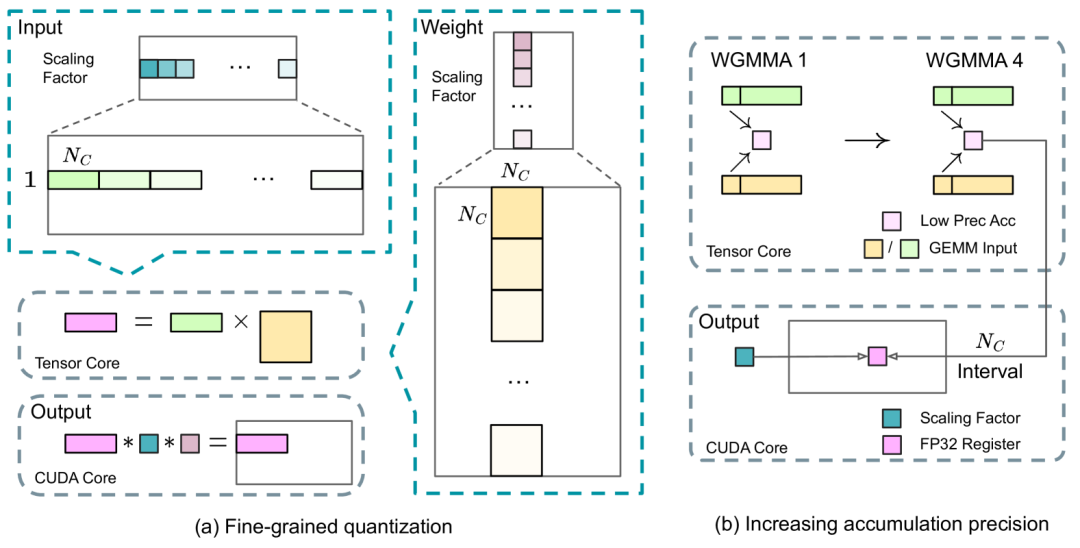
同时,DeepSeek使用FP8混合精度框架,实现更快的计算速度和更低的内存占用,同时不牺牲数值稳定性。
关键操作(如矩阵乘法)以FP8精度执行,而敏感组件(如嵌入层和归一化层)则保留更高精度(BF16或FP32)以确保准确性。
DeepSeek 独创了对正在处理的数据的尾数和指数进行微缩放,从而在不损害数据保真度的情况下,保持任何给定计算所需的精度水平和数值范围。
大家熟悉的FlashAttention也是一种 I/O-Aware的注意力机制,克服了内存墙问题。注意力机制是生成模型的核心,包括大语言模型和图像生成算法。
FlashAttention 通过融合注意力机制的步骤,在低层级内存上完成所有顺序计算,避免了不必要的中间数据传输。与标准的 PyTorch 实现相比,其吞吐量提高了 6 倍。
然而,当前生成 I/O 感知算法,以利用硬件特性的最佳技术,仍然是缓慢的手动推导,可能导致大量性能仍未被充分挖掘。
FlashAttention就是历经三年三次迭代才能充分利用 Hopper 硬件(NVIDIA, 2022)的特性。DeepSeek业界良心,开源了不少代码,方便大家抄作业。
系统化创新自动优化算法需要一种机制来理解算法的组合结构,并需要一个性能模型来比较执行同一操作的不同方式,难度很大,【文献2】非常值得期待:
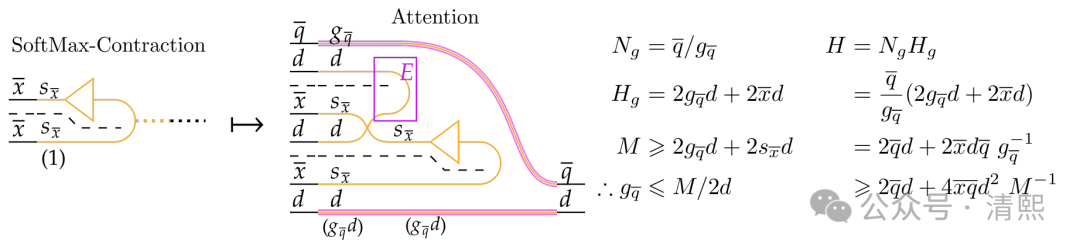
文献提出了基于神经电路图(Neural Circuit Diagrams)的深度学习算法表征方案,展示了任务在 GPU 层级结构中的分布及相关资源使用情况。
该方案结合了用于融合算法组合性质的定理,能够快速推导出 GPU 优化的矩阵乘法和注意力机制的高层次草图,并构建出相应性能模型。

三、代码与推理Scaling Law
代码是设计完善的符号语言,结构性强,长程关联,关系明确,可以看成特殊的思维链,是训练大模型推理能力的最佳语料。
利用微语言结构的概率分布为基底,张成语言空间,程序就是该语言空间的点线面体结构。大模型可以用自己构建的高维概率语言空间简单方便的学习代码。
读者都熟悉大模型的训练推理过程数理框架: 1、重整化从海量语料中提取出范畴,2、持续重整化驱动范畴解构重组结晶,3、生成过程于范畴中采样做变分推理。
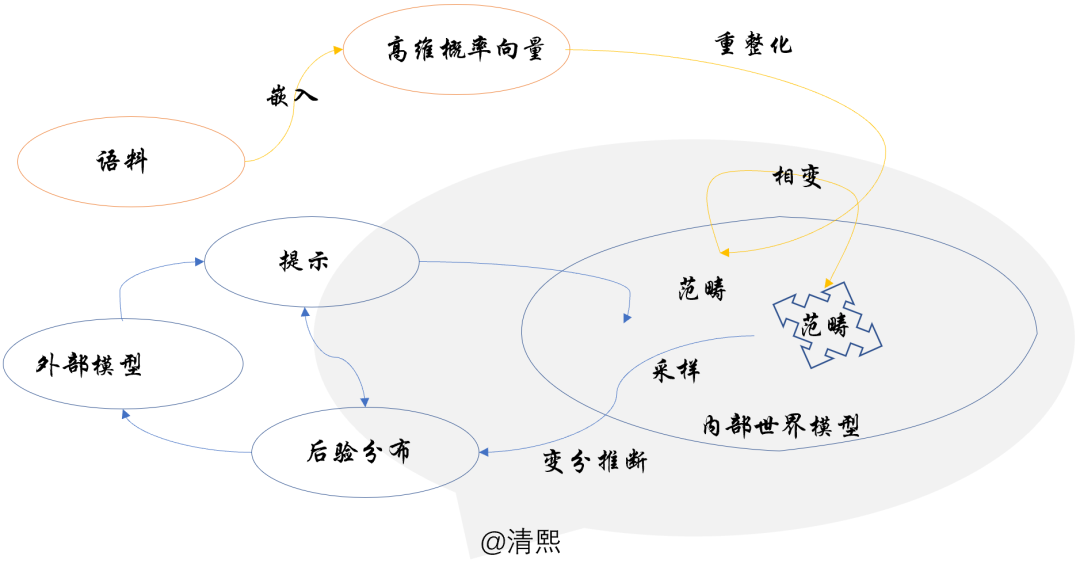
基于宏大的人类知识提取出来丰富范畴,形成众多领域的本体知识结构,这是大模型通过预训练已经构建的内部世界模型;
提高推理采样的机制,通过训练测试达成学习推理的scaling law,是大模型下一步努力提升的关键方向。
在已训练的LLM世界模型的基础上,进行专注推理策略的第二阶预训练,给LLM构建完整的“大脑皮层”,进而借助皮层指挥LLM推理生成。
“MoE = 推理采样策略” :MoE里的“专家”是一种拟人的形象化的说法,本质上是基于某种人类先验“知识”或“策略”的“跨范畴采样”:
“在外部感官输入下,大模型内部将限定在相应的高维语言概率空间的子空间内推理;推理是在子空间中采样,做类比时跨范畴采样”。
现有支撑激发LLM推理scaling law的技术:参数更新、输入修改和输出校准解决分布偏移并增强稳健性;重复采样、自我校正和树搜索等策略用来加强推理。
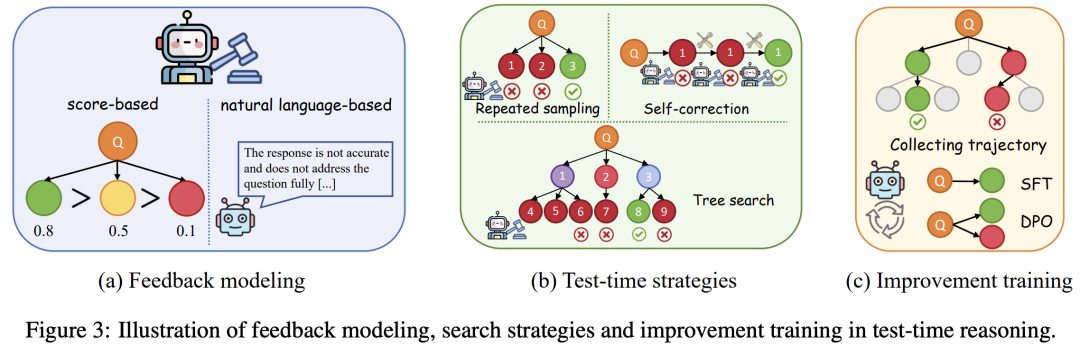
测试时计算模型更新,等于利用测试样本信息在推理阶段进一步微调了模型参数,使模型能够适应测试分布。
推理过程中进行重复采样同样可以显著提升复杂任务(如数学和编程)的性能【文献3】,即使是较小的模型也能通过增加采样获得显著性能提升。性能改进遵循指数幂律关系。
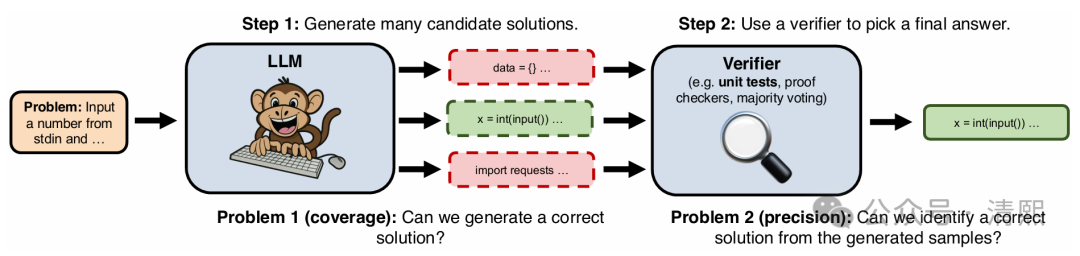
关键的推理阶段增强技术可以结合使用:重复采样(生成多次尝试)、融合(综合多个响应)、批判与排序响应、验证输出(自动或手工),这些也是软归纳偏好方案。
目前看行业技术发展趋势是,推理与训练测试之间的界限正在变得模糊,推理结果也被反馈到训练测试过程中以提升模型能力。
未来的模型需要无缝的自我改进循环,以持续增强其能力,类似于人类通过持续互动和反馈学习,而非离散的训练阶段。软归纳偏好是很自然的方式。
四、不同层次/尺度语言处理
从语言到认知:LLM如何超越人类语言网络笔者总结:
通过对LLM训练过程中大脑对齐性的系统分析,揭示了形式语言能力 (语法) 与功能语言能力 (语义) 的不同发展轨迹。
未来的研究应进一步扩展对齐性评估的范围,探索LLM与其他认知网络的关系,并推动人工与生物语言处理的深度融合。
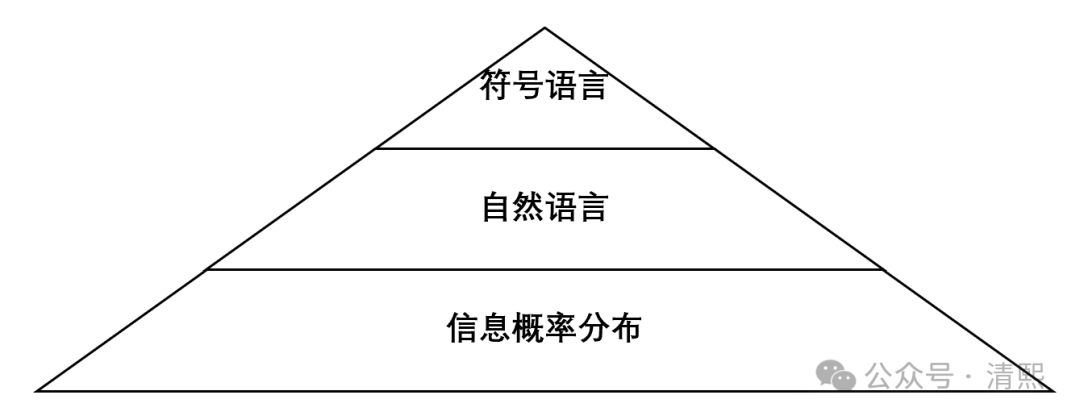
而做到深度融合,如笔者压缩即智能中探讨,需要从人类与大模型的语言体系中共通的三层结构分别入手:
自下而上,基础“信息概率分布”处理体系;自然语言如语音或词句文章;符号语言如代码、数学公式等。
Nature人类行为最新一项研究【文献4】,引入了一个统一的计算框架,将声学、语音和词汇层面的语言结构联系起来,以研究人类大脑在日常对话中的神经基础。
方法是:
- 使用皮层电图记录参与者在开放式现实生活对话中的语音产生和理解过程的神经信号;
- 从多模态语音文本模型(Whisper)中提取低层次的声学特征、中层次的语音特征以及上下文词汇嵌入。
- 开发了编码模型,将这些嵌入(embedding)线性映射到语音产生和理解过程中的大脑活动上。
Whisper模型捕捉到了在词汇发音前(语音产生)的语言到语音编码的时间序列,以及发音后(语音理解)的语音到语言编码的时间序列。
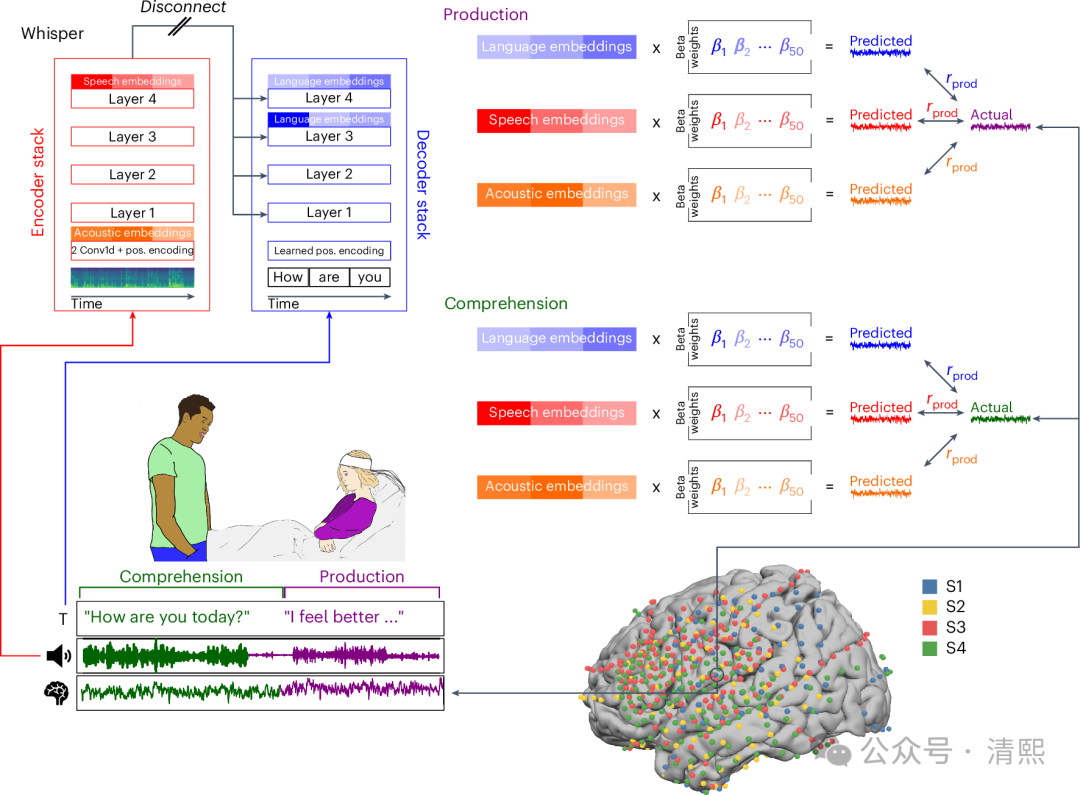
值得注意的是,该模型能够准确预测在未用于模型训练的长时间新对话中,语言处理层次结构中每个层级的神经活动。
模型内部的处理层次与大脑皮层中语音和语言处理的层次结构相一致,其中感觉和运动区域与模型的语音嵌入更匹配,而更高层次的语言区域则与模型的语言嵌入更匹配。
该模型学习到的嵌入在捕捉支持自然语音和语言的神经活动方面优于符号模型。
这些发现支持了一种范式转变:即采用统一的计算模型来捕捉现实世界对话中语音理解和产生的整个处理层次结构。

这也让DeepSeek R1 或 R2 这样的大模型,方便地,自下而上切换推理用的自然语言以致符号语言;或者自上而下地“编译”并执行符号定义的、或者自然语言描述的推理过程:
因为推理不过是在LLM构建的高维概率语言空间里,对信息概率分布采样做变分;
“切换” 是将这个过程映射到不同的上层自然语言,以及对应的语音,甚至进一步映射到某种符号语言 - 代码或数学公式;
“编译” 则是这一过程的逆过程,即将抽象的符号语言用自然语言描述,或者转换为对信息概率分布的处理过程。
AI 之间沟通可以在三个层次上自由切换,而人类则需要把上下两层都翻译成中间的自然语言才能有效沟通和交流,很多情形下会比AI低效。
我们共同期待一下 DeepSeek R2 吧!
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

DeepSeek全套安装部署资料

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 24
24 0
0- 0



 已为社区贡献112条内容
已为社区贡献112条内容

所有评论(0)