轻松认识RAG(三):手把手带你实现 博查API + LangChain + DeepSeek = RAG的项目实战
大家好啊,我是北极熊,之前我们聊到,在人工智能领域,RAG 技术正逐渐成为提升语言模型能力的重要手段。通过结合外部知识检索与生成模型,RAG 系统能够在回答问题时引用最新、最相关的信息,显著提高回答的准确性和时效性。那么这篇文章呢,我将会带大家详细介绍如何利用 LangChain 调用 DeepSeek 模型,结合博查的 Web Search API 和 Semantic Reranker API
目录
前言
大家好啊,我是北极熊,之前我们聊到,在人工智能领域,RAG 技术正逐渐成为提升语言模型能力的重要手段。通过结合外部知识检索与生成模型,RAG 系统能够在回答问题时引用最新、最相关的信息,显著提高回答的准确性和时效性。
那么这篇文章呢,我将会带大家详细介绍如何利用 LangChain 调用 DeepSeek 模型,结合博查的 Web Search API 和 Semantic Reranker API,构建一个完整的 RAG 系统。
一、 搭建 RAG 系统的前期准备
1.1 环境设置与依赖安装
使用以下命令安装必要的 Python 库:
pip install langchain json requests flask langchain_openai
1.2 获取博查API key
前往博查AI开放平台 → API Key管理 → 创建新Key(具体步骤可以参考文章【手把手教学】用Python玩转博查AI Web Search API!全网搜索一键搞定!)
1.3 获取DeepSeek Key
访问 DeepSeek 的官方网站,注册并生成您的 API 密钥。

二、搭建RAG全流程
2.1 RAG的召回阶段
博查的 Web Search API 提供了强大的语义搜索能力,能够根据用户的查询实时获取相关信息。我们使用博查的Web Search API 来实现RAG的召回部分。
在代码中,可以使用 requests 库调用博查的 Web Search API:
import requests
web_search_url = "https://api.bochaai.com/v1/web-search"
def web_search(query):
headers = {
'Authorization': f'Bearer {api_key}',
'Content-Type': 'application/json'
}
payload = json.dumps({
"query": query,
"count": 50,
"summary": True
})
response = requests.post(web_search_url, headers=headers, data=payload)
if response.status_code == 200:
return response.json().get('data', {})
else:
raise Exception(f"Web Search API Error: {response.text}")
2.2 RAG的精排阶段
检索到召回的结果可能包含噪声或相关性不高的信息,因此需要对结果进行重排序,以确保最相关的信息被优先考虑。我们使用博查的 Semantic Reranker API 可以帮助完成这一任务。
同样,可以使用 requests 库调用 Semantic Reranker API:
import requests
rerank_url = "https://api.bochaai.com/v1/rerank"
def semantic_rerank(query, documents):
headers = {
'Authorization': f'Bearer {api_key}',
'Content-Type': 'application/json'
}
payload = {
"model": "gte-rerank",
"query": query,
"documents": documents,
"top_n": 5,
"return_documents": True
}
response = requests.post(rerank_url, headers=headers, json=payload)
if response.status_code == 200:
return response.json()['data']['results']
else:
raise Exception(f"Rerank API Error: {response.text}")
2.3 RAG的生成阶段
我们使用Langchain来调用DeepSeek作为RAG的生成模型,接收来自搜索返回的答案并生成总结。
from langchain_openai import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.schema import StrOutputParser
class DeepSeekGenerator:
def __init__(self, api_key):
self.llm = ChatOpenAI(
model="deepseek-chat",
base_url="https://api.deepseek.com/v1", # DeepSeek API 地址
api_key= api_key # 你的 DeepSeek API Key
)
self.prompt_template = PromptTemplate(
template="""
基于以下上下文回答问题:
{context}
问题:{query}
答案:
""",
input_variables=["context", "query"]
)
def generate_answer(self, query, context):
prompt = self.prompt_template.format(query=query, context=context)
return self.llm.generate([prompt]).generations[0][0].text
好的,到现在为止,我们已经完成了整个RAG的流程。为了让大家看起来更好看呢,我们来一点小“魔法”。
三、完整项目代码
完整的项目架构如下所示:
rag-project/
├── app.py # Flask主程序
├── utils/
│ ├── api_client.py # 博查API封装
│ └── llm_handler.py # DeepSeek集成
└── templates/
└── index.html # 前端代码
3.1 后端代码部分
3.1.1 app.py
from flask import Flask, render_template, request, jsonify
from utils.api_client import BochaClient
from utils.llm_handler import DeepSeekGenerator
app = Flask(__name__)
BOCHA_API_KEY = "你的博查 API Key"
DEEPSEEK_API_KEY = "你的DeepSeek Key"
bocha_client = BochaClient(BOCHA_API_KEY)
deepseek = DeepSeekGenerator(DEEPSEEK_API_KEY)
@app.route('/', methods=['GET', 'POST'])
def index():
if request.method == 'POST':
query = request.form.get('query')
if not query:
return render_template('index.html', error="请输入搜索内容")
try:
# Step 1: 调用Web Search API
search_results = bocha_client.web_search(query)
if not search_results:
return render_template('index.html', error="未找到相关结果")
# Step 2: 提取文档并调用Semantic Reranker
documents = [doc['snippet'] for doc in search_results['webPages']['value']]
reranked_docs = bocha_client.semantic_rerank(query, documents)
# Step 3: 调用DeepSeek生成回答
context = "\n".join([doc['document']['text'] for doc in reranked_docs])
answer = deepseek.generate_answer(query, context)
return render_template('index.html',
query=query,
search_results=search_results,
reranked_docs=reranked_docs,
answer=answer)
except Exception as e:
return render_template('index.html', error=f"系统错误: {str(e)}")
return render_template('index.html')
if __name__ == '__main__':
app.run(debug=True)
3.1.2 博查代码封装 utils/api_client.py
import requests
import json
class BochaClient:
def __init__(self, api_key):
self.api_key = api_key
self.web_search_url = "https://api.bochaai.com/v1/web-search"
self.rerank_url = "https://api.bochaai.com/v1/rerank"
def web_search(self, query):
headers = {
'Authorization': f'Bearer {self.api_key}',
'Content-Type': 'application/json'
}
payload = json.dumps({
"query": query,
"count": 50,
"summary": True
})
response = requests.post(self.web_search_url, headers=headers, data=payload)
if response.status_code == 200:
return response.json().get('data', {})
else:
raise Exception(f"Web Search API Error: {response.text}")
def semantic_rerank(self, query, documents):
headers = {
'Authorization': f'Bearer {self.api_key}',
'Content-Type': 'application/json'
}
payload = {
"model": "gte-rerank",
"query": query,
"documents": documents,
"top_n": 5,
"return_documents": True
}
response = requests.post(self.rerank_url, headers=headers, json=payload)
if response.status_code == 200:
return response.json()['data']['results']
else:
raise Exception(f"Rerank API Error: {response.text}")
3.1.3 LLM代码封装部分 utils/llm_handler.py
from langchain_openai import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.schema import StrOutputParser
class DeepSeekGenerator:
def __init__(self, api_key):
self.llm = ChatOpenAI(
model="deepseek-chat",
base_url="https://api.deepseek.com/v1", # DeepSeek API 地址
api_key= api_key # 你的 DeepSeek API Key
)
self.prompt_template = PromptTemplate(
template="""
基于以下上下文回答问题:
{context}
问题:{query}
答案:
""",
input_variables=["context", "query"]
)
def generate_answer(self, query, context):
prompt = self.prompt_template.format(query=query, context=context)
return self.llm.generate([prompt]).generations[0][0].text
3.2 前端代码
templates/index.html
<!DOCTYPE html>
<html lang="zh">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>智能搜索系统 - RAG Demo</title>
<link href="https://cdn.bootcdn.net/ajax/libs/twitter-bootstrap/5.3.0/css/bootstrap.min.css" rel="stylesheet">
<link href="{{ url_for('static', filename='css/style.css') }}" rel="stylesheet">
</head>
<body>
<div class="container mt-5">
<h1 class="text-center mb-4">智能搜索系统</h1>
<!-- 搜索框 -->
<form method="POST">
<div class="input-group mb-4">
<input type="text" class="form-control" name="query"
placeholder="请输入您的问题,例如:阿里巴巴2024年ESG报告的重点"
value="{{ query if query else '' }}">
<button class="btn btn-primary" type="submit">搜索</button>
</div>
</form>
<!-- 错误提示 -->
{% if error %}
<div class="alert alert-danger">{{ error }}</div>
{% endif %}
<!-- 生成答案 -->
{% if answer %}
<div class="card mb-4">
<div class="card-header bg-primary text-white">
<h5 class="mb-0">AI生成答案</h5>
</div>
<div class="card-body">
<p class="lead">{{ answer }}</p>
</div>
</div>
{% endif %}
<!-- 重排序结果 -->
{% if reranked_docs %}
<div class="card mb-4">
<div class="card-header bg-success text-white">
<h5 class="mb-0">精选文档(语义重排序后)</h5>
</div>
<ul class="list-group list-group-flush">
{% for doc in reranked_docs %}
<li class="list-group-item">
<div class="text-muted small">相关度得分:{{ "%.2f"|format(doc.relevance_score) }}</div>
<p>{{ doc.document.text|truncate(200) }}</p>
</li>
{% endfor %}
</ul>
</div>
{% endif %}
</div>
<script src="https://cdn.bootcdn.net/ajax/libs/bootstrap/5.3.0/js/bootstrap.bundle.min.js"></script>
</body>
</html>
四、结果展示
在运行app.py之后,打开浏览器,转到http://127.0.0.1:5000:
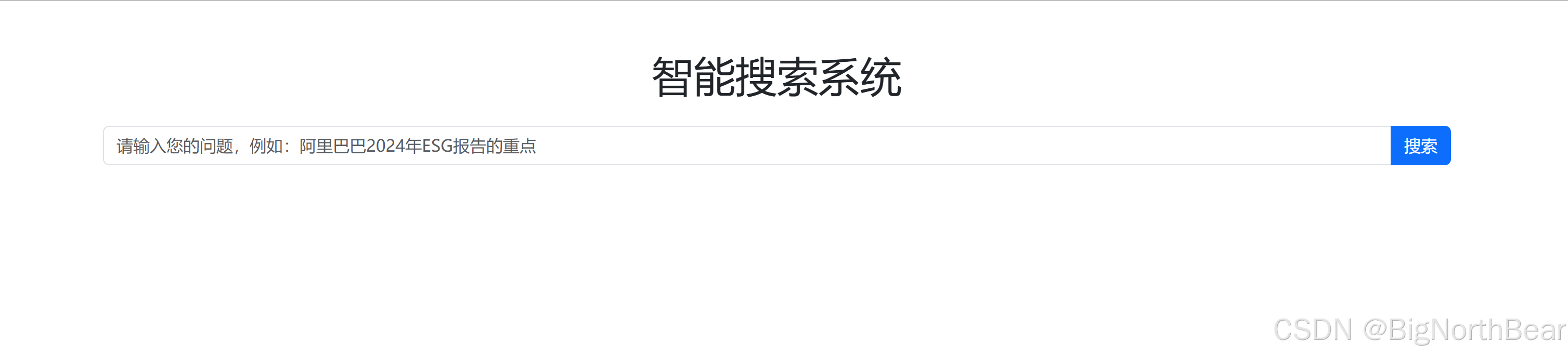
然后让我们试一下输入“哪吒2的票房到多少了?”

可以看到,他的回答是可以给出依据的,没有在胡编乱造,那我们直接去DeepSeek官网试一下。

总结
这篇文章呢,主要是带大家做一个实战,让大家从实战中了解RAG的各个流程是如何做的,从RAG的理论到实践,全面的认识RAG。大家可以自己动手实现一下,也可以在这个基础上继续改进!
🔗 系列文章推荐:
【你不知道的搜索进化史(一):从图书馆到AI搜索助手的演变】
【你不知道的搜索进化史(二):为什么有些问题,你在搜索引擎上永远找不到答案?】

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 17
17 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)