顶会收割机:多变量不规则时序预测!DeepSeek公司都在抢着发!
性能提升:在多个时间序列基准数据集上,TIME-LLM显著优于现有的专门预测模型。性能提升:在多个医疗和活动识别数据集上,RAINDROP在分类任务中平均提升了3.5%的AUROC和4.8%的AUPRC,尤其是在留出传感器的设置中表现更为突出。少样本和零样本学习:在少样本和零样本学习场景中,TIME-LLM表现出色,平均性能提升超过10%,展示了其在数据稀缺情况下的强大适应能力。跨样本学习:通过共
2025深度学习发论文&模型涨点之——多变量不规则时序预测
多变量不规则时序预测是一个复杂的问题,通常涉及使用机器学习或深度学习模型来处理时间序列数据,这些数据可能在时间上不均匀分布。
-
缺失值处理:对于不规则时序数据,首先需要处理缺失值。可以使用插值方法(如线性插值、样条插值等)来填充缺失值。
-
时间对齐:将不同变量的时间戳对齐到一个共同的时间网格上,以便于模型处理。
-
标准化:对数据进行标准化或归一化,以消除不同变量之间的量纲影响。
小编整理了一些多变量不规则时序预测【论文】合集,以下放出部分,全部论文PDF版皆可领取。
需要的同学
回复“多变量不规则时序预测”即可全部领取
论文精选
论文1:
Deep Learning for Multivariate Time Series Imputation: A Survey
多变量时间序列插补的深度学习方法综述
方法
-
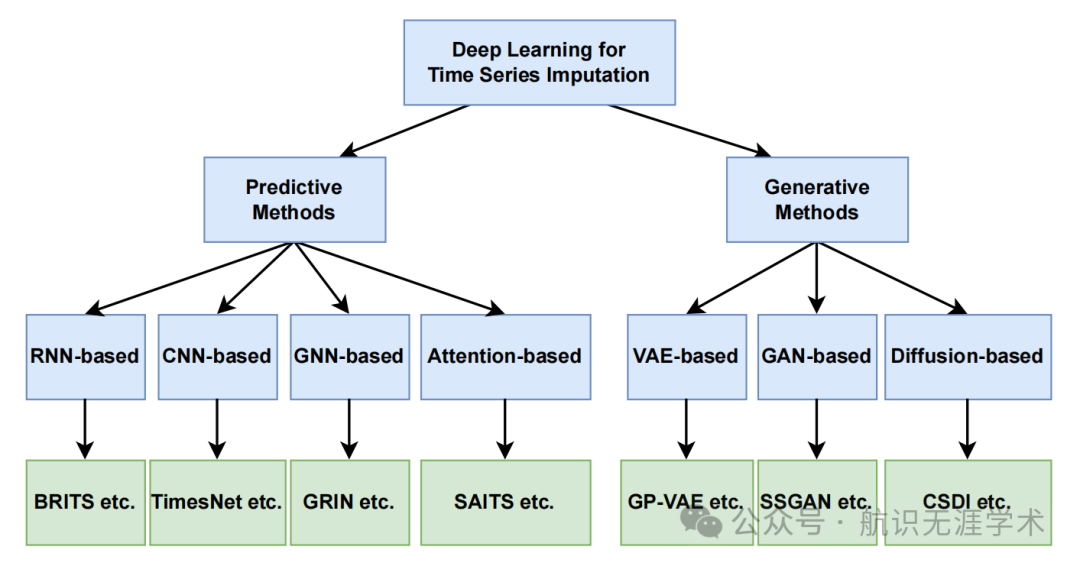
分类体系:提出了一个新的分类体系,从两个角度对深度学习方法进行分类:缺失数据的不确定性和神经网络架构。
预测方法:包括基于循环神经网络(RNN)、卷积神经网络(CNN)、图神经网络(GNN)和注意力机制的预测方法。
生成方法:包括基于变分自编码器(VAE)、生成对抗网络(GAN)和扩散模型的生成方法。
创新点
-
分类体系:首次提出了一个综合的分类体系,涵盖了从预测到生成的各种深度学习方法,为研究者提供了一个清晰的框架来理解和比较不同的方法。
实验评估:通过广泛的实验验证了不同方法的有效性,并指出了未来研究的方向,为该领域的发展提供了重要的参考。
性能提升:在多个真实世界数据集上,深度学习方法显著优于传统方法。例如,在PhysioNet2012数据集上,深度学习方法在高缺失率(80%)的情况下,相比传统方法(如均值插补、中位数插补等)在下游任务(如分类)中提升了约5%的PR-AUC和1%的ROC-AUC。
论文2:
CROSSFORMER: TRANSFORMER UTILIZING CROSS-DIMENSION DEPENDENCY FOR MULTIVARIATE TIME SERIES FORECASTING
Crossformer:利用跨维度依赖的Transformer进行多变量时间序列预测
方法
-
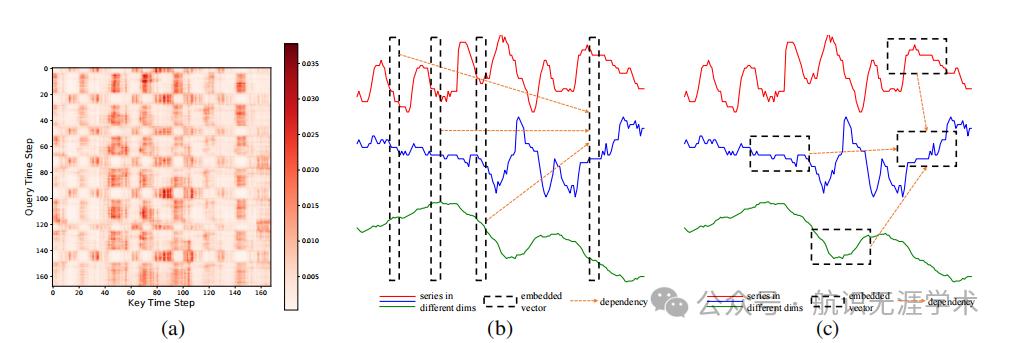
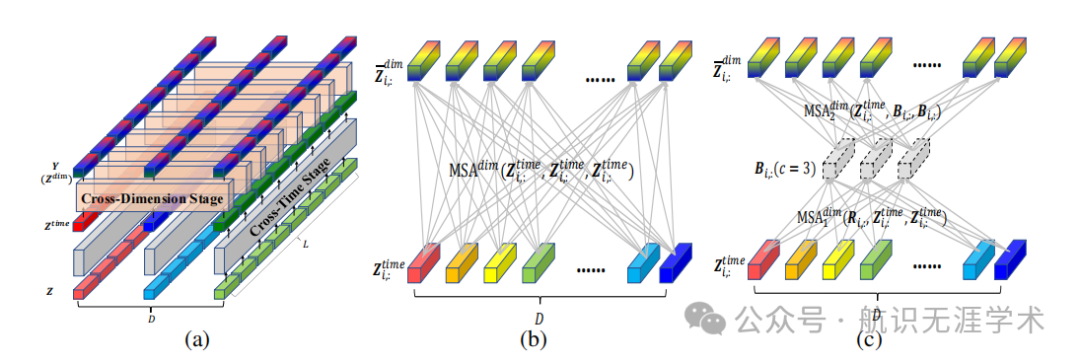
维度分段嵌入(DSW):将时间序列数据嵌入到二维向量数组中,保留时间和维度信息。
两阶段注意力(TSA):通过时间注意力和跨维度注意力分别捕捉时间依赖和维度依赖。
层次编码器-解码器(HED):利用不同尺度的信息进行最终预测,通过编码器和解码器的层次结构捕捉不同尺度的依赖关系。
创新点
-
跨维度依赖建模:首次在Transformer架构中明确建模跨维度依赖,显著提升了多变量时间序列预测的性能。
性能提升:在六个真实世界数据集上,Crossformer在大多数设置中均优于现有最先进的模型。例如,在ETTh1数据集上,Crossformer在预测长度为96时的MSE相比其他Transformer模型降低了约20%。
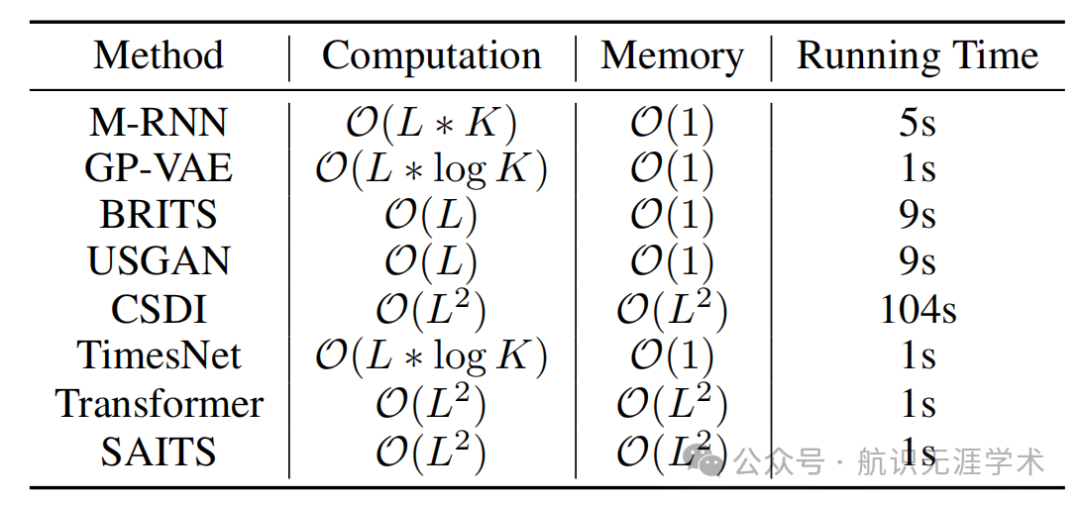
计算效率:通过优化的两阶段注意力机制和层次结构,Crossformer在计算效率上优于其他复杂模型,同时保持了高性能。
论文3:
GRAPH-GUIDED NETWORK FOR IRREGULARLY SAMPLED MULTIVARIATE TIME SERIES
用于不规则采样多变量时间序列的图引导网络
方法
-
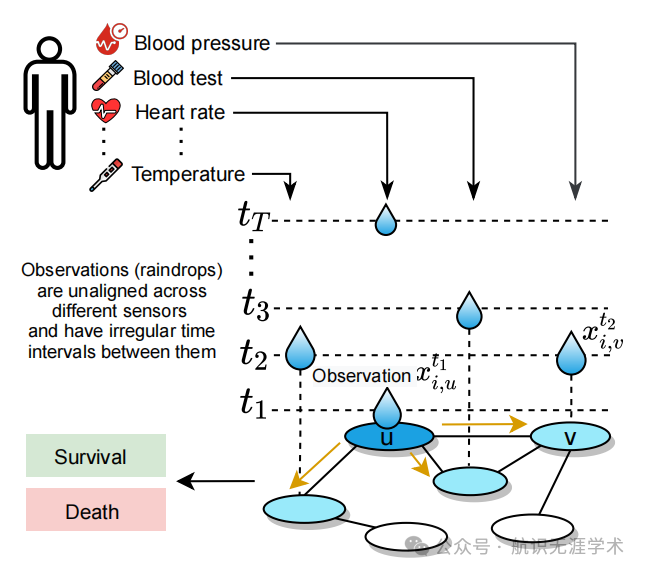
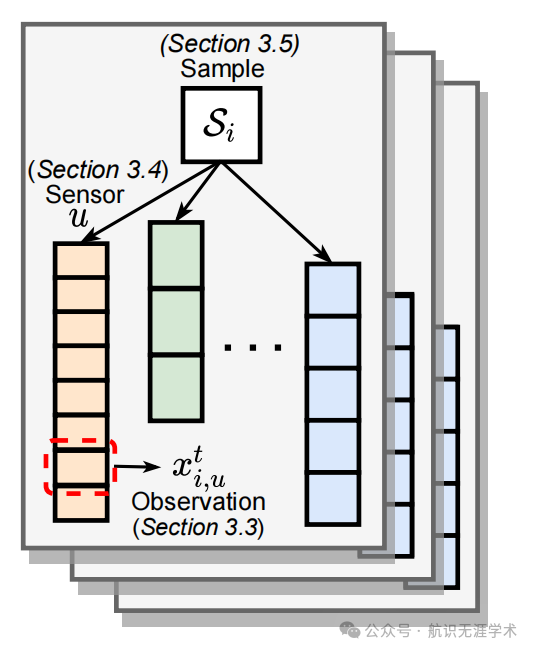
图神经网络(GNN):利用图神经网络学习时间序列中传感器之间的动态依赖关系。
消息传递机制:通过消息传递机制在传感器图中传播信息,处理不规则采样的时间序列。
层次化注意力机制:结合时间注意力和传感器级别的注意力,生成样本的固定长度嵌入。
创新点
-
图结构学习:首次提出利用图结构来建模不规则采样时间序列中的传感器依赖关系,显著提升了模型对不规则数据的处理能力。
性能提升:在多个医疗和活动识别数据集上,RAINDROP在分类任务中平均提升了3.5%的AUROC和4.8%的AUPRC,尤其是在留出传感器的设置中表现更为突出。
跨样本学习:通过共享参数和利用样本之间的相似性,RAINDROP能够更好地处理不同样本之间的关系,进一步提升了模型的泛化能力。
论文4:
TIME-LLM: TIME SERIES FORECASTING BY REPROGRAMMING LARGE LANGUAGE MODELS
通过重编程大型语言模型进行时间序列预测
方法
-
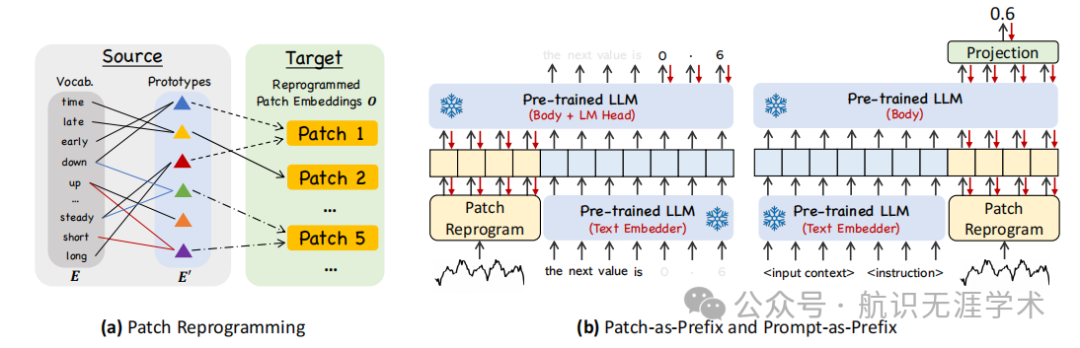
输入重编程:将时间序列数据重编程为文本原型表示,使其更适合语言模型处理。
提示作为前缀(PaP):通过在输入中添加自然语言提示,增强语言模型对时间序列任务的理解和推理能力。
输出投影:将语言模型的输出投影到时间序列预测的最终结果。
创新点
-
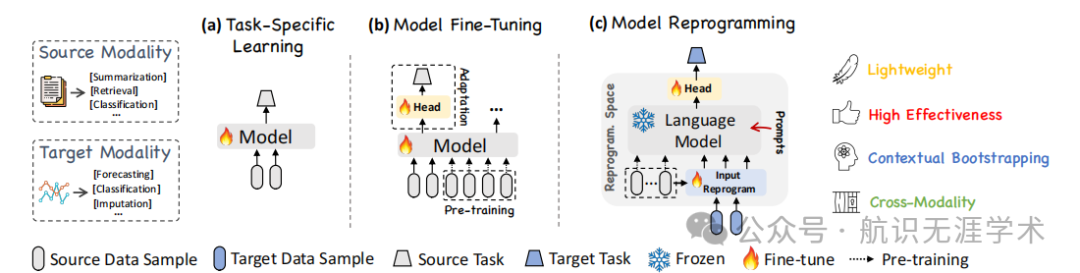
重编程框架:首次提出利用重编程框架将大型语言模型应用于时间序列预测,无需对预训练模型进行微调。
性能提升:在多个时间序列基准数据集上,TIME-LLM显著优于现有的专门预测模型。例如,在ETTh1数据集上,TIME-LLM在预测长度为96时的MSE相比其他Transformer模型降低了约14%。
少样本和零样本学习:在少样本和零样本学习场景中,TIME-LLM表现出色,平均性能提升超过10%,展示了其在数据稀缺情况下的强大适应能力。
小编整理了多变量不规则时序预测论文代码合集
需要的同学扫码添加我
回复“多变量不规则时序预测”即可全部领取

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)