【deepseek】 学cuda 基于WMMA的半精度矩阵乘法(HGEMM)
难点在于划分warp。涉及三次划分warp。全局内存到共享内存如何划分warp?利用TensorCor 即wmma 接口实现16*16 矩阵相乘时,如何划分warp?将计算结果,写回全局内存,怎样划分warp 实现并行?这三次划分warp 可以独立的划分。原因在于,三次操作间已经__syncthreads()同步过了。代码中, 后两次划分warp方式可以保持一致。笔者学习过程中,对数据搬用划分可以
难点在于划分warp。
涉及三次划分warp。 全局内存到共享内存如何划分warp? 利用TensorCor 即wmma 接口实现16*16 矩阵相乘时,如何划分warp? 将计算结果,写回全局内存,怎样划分warp 实现并行?
这三次划分warp 可以独立的划分。原因在于,三次操作间已经__syncthreads()同步过了。
代码中, 后两次划分warp方式可以保持一致。笔者学习过程中,对数据搬用划分可以方便理解。 刚开始以为实现矩阵相乘时计算时warp的划分要和搬运保持一致,理解了一会儿。 实际搬运数据所以warp 可以协作, 不必考虑16*16的TensorCore.
实现
#include <cuda_runtime.h>
#include <mma.h>
using namespace nvcuda;
template <
const int WMMA_M = 16, // WMMA矩阵乘法的M维度
const int WMMA_N = 16, // WMMA矩阵乘法的N维度
const int WMMA_K = 16, // WMMA矩阵乘法的K维度
const int WMMA_TILE_M = 4, // 每个线程块在M方向的WMMA分块数
const int WMMA_TILE_N = 2 // 每个线程块在N方向的WMMA分块数
>
__global__ void hgemm_wmma_m16n16k16_kernel(
half *A, half *B, half *C,
int M, int N, int K)
{
// 定义分块参数
constexpr int BM = WMMA_M * WMMA_TILE_M; // 线程块处理的M维度: 16*4=64
constexpr int BN = WMMA_N * WMMA_TILE_N; // 线程块处理的N维度: 16*2=32
constexpr int BK = WMMA_K; // 线程块处理的K维度: 16
// 定义共享内存(A: 64x16, B: 16x32)
__shared__ half s_a[BM][BK];
__shared__ half s_b[BK][BN];
// 线程索引计算
const int tid = threadIdx.y * blockDim.x + threadIdx.x;
const int warp_id = tid / 32; // 当前线程所在warp的ID(0~7)
const int lane_id = tid % 32; // 线程在warp内的lane ID(0~31)
const int warp_m = warp_id / 2; // warp在M方向的索引(0~3)
const int warp_n = warp_id % 2; // warp在N方向的索引(0~1)
// 定义WMMA Fragment
wmma::fragment<wmma::matrix_a, WMMA_M, WMMA_N, WMMA_K, half, wmma::row_major> A_frag;
wmma::fragment<wmma::matrix_b, WMMA_M, WMMA_N, WMMA_K, half, wmma::row_major> B_frag;
wmma::fragment<wmma::accumulator, WMMA_M, WMMA_N, WMMA_K, half> C_frag;
wmma::fill_fragment(C_frag, 0.0f); // 初始化C_frag为0
// 全局内存地址计算
const int by = blockIdx.y;
const int bx = blockIdx.x;
const int num_k_tiles = (K + BK - 1) / BK;
// 主循环:按K维度分块处理
for (int tile_k = 0; tile_k < num_k_tiles; ++tile_k) {
// 第1步:加载A和B到共享内存(每个线程加载多个元素)
// A的全局内存地址计算
int load_a_m = by * BM + tid / 4; // 每个线程处理4个元素(行方向)
int load_a_k = tile_k * BK + (tid % 4) * 4; // 每个线程处理4个连续元素(列方向)
if (load_a_m < M && load_a_k < K) {
// 使用half4向量化加载(64位)
reinterpret_cast<float4*>(&s_a[load_a_m][load_a_k])[0] =
reinterpret_cast<float4*>(&A[load_a_m * K + load_a_k])[0];
}
// B的全局内存地址计算
int load_b_k = tile_k * BK + tid / 16; // 每个线程处理16行
int load_b_n = bx * BN + (tid % 16) * 2; // 每个线程处理2个元素(列方向)
if (load_b_k < K && load_b_n < N) {
// 使用half2向量化加载(32位)
reinterpret_cast<float2*>(&s_b[load_b_k][load_b_n])[0] =
reinterpret_cast<float2*>(&B[load_b_k * N + load_b_n])[0];
}
__syncthreads(); // 确保共享内存加载完成
// 第2步:加载共享内存数据到WMMA Fragment
// A_frag的起始地址:s_a[warp_m * 16][0]
wmma::load_matrix_sync(A_frag, &s_a[warp_m * WMMA_M][0], BK);
// B_frag的起始地址:s_b[0][warp_n * 16]
wmma::load_matrix_sync(B_frag, &s_b[0][warp_n * WMMA_N], BN);
// 第3步:执行WMMA矩阵乘加
wmma::mma_sync(C_frag, A_frag, B_frag, C_frag);
__syncthreads(); // 确保下一次循环的共享内存未被覆盖
}
// 第4步:将结果写回全局内存
// C的全局内存起始地址:C + (by*BM + warp_m*16) * N + bx*BN + warp_n*16
int store_c_m = by * BM + warp_m * WMMA_M;
int store_c_n = bx * BN + warp_n * WMMA_N;
if (store_c_m < M && store_c_n < N) {
wmma::store_matrix_sync(&C[store_c_m * N + store_c_n], C_frag, N, wmma::mem_row_major);
}
}
2 原理


在这里插入图片描述
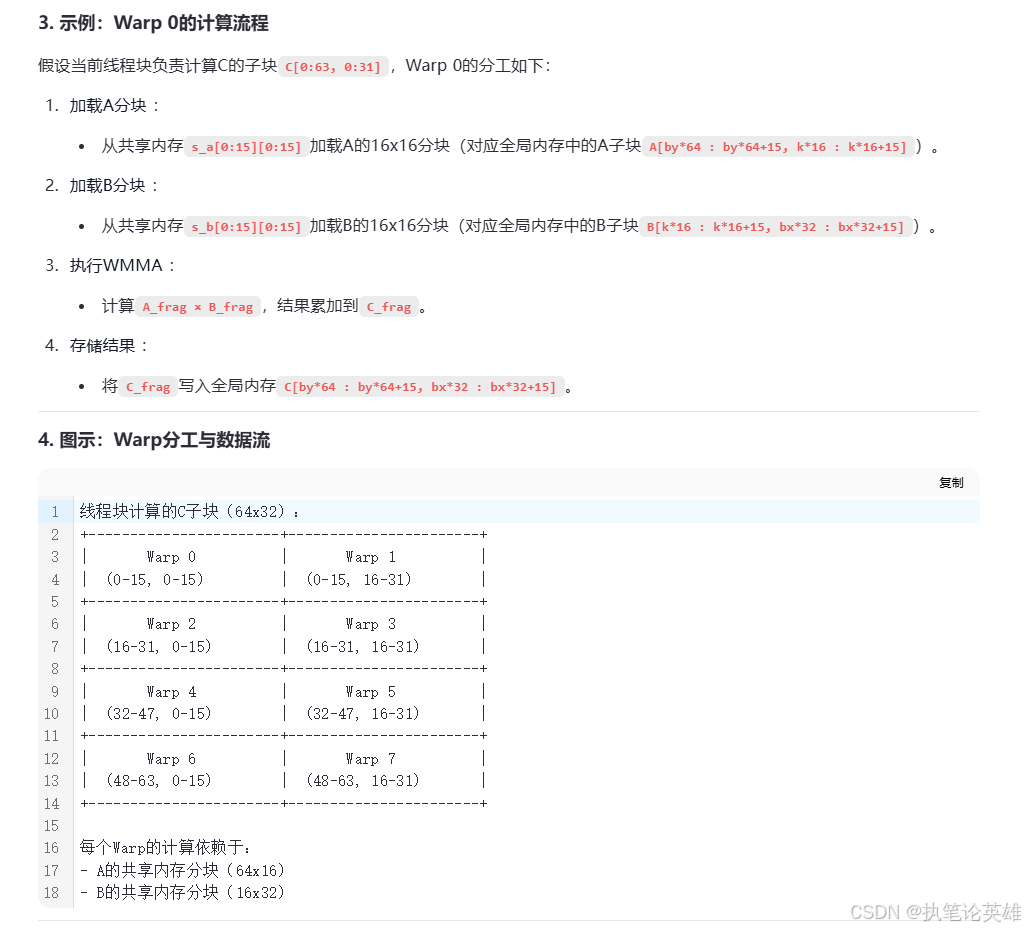

上面这句话指出 加载数据时是, 所有Warp协作(所以需要等同步后计算)但每个Warp独立计算自己的子块(warp间计算独立)
4 关键优化点 :
向量化加载 :通过LDST64BITS和LDST32BITS宏实现高效数据传输。
共享内存复用 :每个K分块的数据仅需加载一次,供所有warp重复使用。
Warp级并行 :每个warp独立处理子块,最大化计算资源利用率。
5. 向量化加载的好处
向量化加载(Vectorized Loading)是CUDA编程中优化内存访问的关键技术,其核心是通过单条指令加载多个连续数据元素 ,从而显著提升内存带宽利用率和减少线程执行差异。以下是其核心优势及代码中的具体体现:
- 减少内存事务数量
普通加载 :每个线程加载一个元素,导致大量独立的内存请求。
示例 :若每个线程加载1个half,256个线程需要256次内存事务。
向量化加载 :每个线程加载多个连续元素(如half4加载4个元素),大幅减少内存事务次数。
示例 :使用half4时,256个线程只需64次事务(每个事务加载4个元素)。 - 合并内存访问(Coalesced Access)
全局内存访问规则 :
CUDA要求线程束(Warp)的内存访问合并为连续地址的事务 ,否则会触发多次非合并访问,降低带宽效率。
向量化加载的天然合并 :
通过加载连续元素,确保线程束的内存请求自动合并为最少的事务。 - 提高共享内存效率
共享内存的Bank冲突问题 :
共享内存被划分为多个Bank,若多个线程访问同一Bank的不同地址,会导致序列化(Bank Conflict)。
向量化加载的对齐优势 :
通过向量化加载,数据在共享内存中按对齐方式存储,减少Bank Conflict概率。 - 减少线程执行差异(Warp Divergence)
普通加载的线程差异 :
若线程加载不同数量的元素,可能导致部分线程提前完成,而其他线程仍在执行(Warp Divergence)。
向量化加载的统一执行 :
所有线程执行相同数量的加载操作,减少分支差异,提升并行效率。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 4
4 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)