飞桨框架paddlepaddle3.0部署DeepSeek-R1-Distill系列模型实践(静态图部署)
第二次接触5天时间,paddlepaddle3.0静态图部署,docker、curl。
目录
一、一般流程
1、基本环境与资源准备
本次在无问芯穹 https://cloud.infini-ai.com/platform/ai 的云主机进行部署(自带docker勾选上,不用配、方便),funhpc、colab、autodl尝试了几遍发现都是容器跑的、安装docker报错,所以我才先才在funhpc动态图部署曲线一下。(另外物理的裸金属服务器也可docker拉环境部署)
飞桨框架paddlepaddle3.0部署DeepSeek-R1-Distill系列模型实践(动态图部署)-CSDN博客
1.1、环境准备
在 AIStudio 开发机上安装和使用 Jupyter Lab | 无问芯穹文档
#jupter转发设置
#开启 Web 应用预览
pip install jupyter
jupyter lab --no-browser --port=9999 --allow-root进入后参考(nvidia-container-toolkit安装的神中神,装了很多遍,没问题。包括中科大镜像 APT 源的安装)
nvidia-container-toolkit 国内镜像源安装_nvidia-container-toolkit.list-CSDN博客
拉取paddle官方镜像:
本次部署拉取:
docker pull ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddlenlp:llm-serving-cuda124-cudnn9-v2.2
大概二三十个G,云上系统盘不够或每次重启关机掉镜像的话得重新下载;
可以更改docker默认存储路径;
无问芯穹花钱买的盘 /datadisk。
其他镜像参考
docker pull ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddlenlp:llm-serving-cuda118-cudnn8-v2.21.2、模型资源下载
1.2.1、进入容器
官方环境镜像ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddlenlp:llm-serving-cuda124-cudnn9-v2.2 ;
传递-v /datadisk/kk12:/kk11将容器内的/kk11传递到主机的/datadisk/kk12中,防止关机就消失,
且容器默认存储路径在系统盘只有50个g,这个命令可以传递出至主机的永久存储盘。
docker run -it -v /datadisk/kk12:/kk11 ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddlenlp:llm-serving-cuda124-cudnn9-v2.2 /bin/bash1.2.2、下载静态图模型
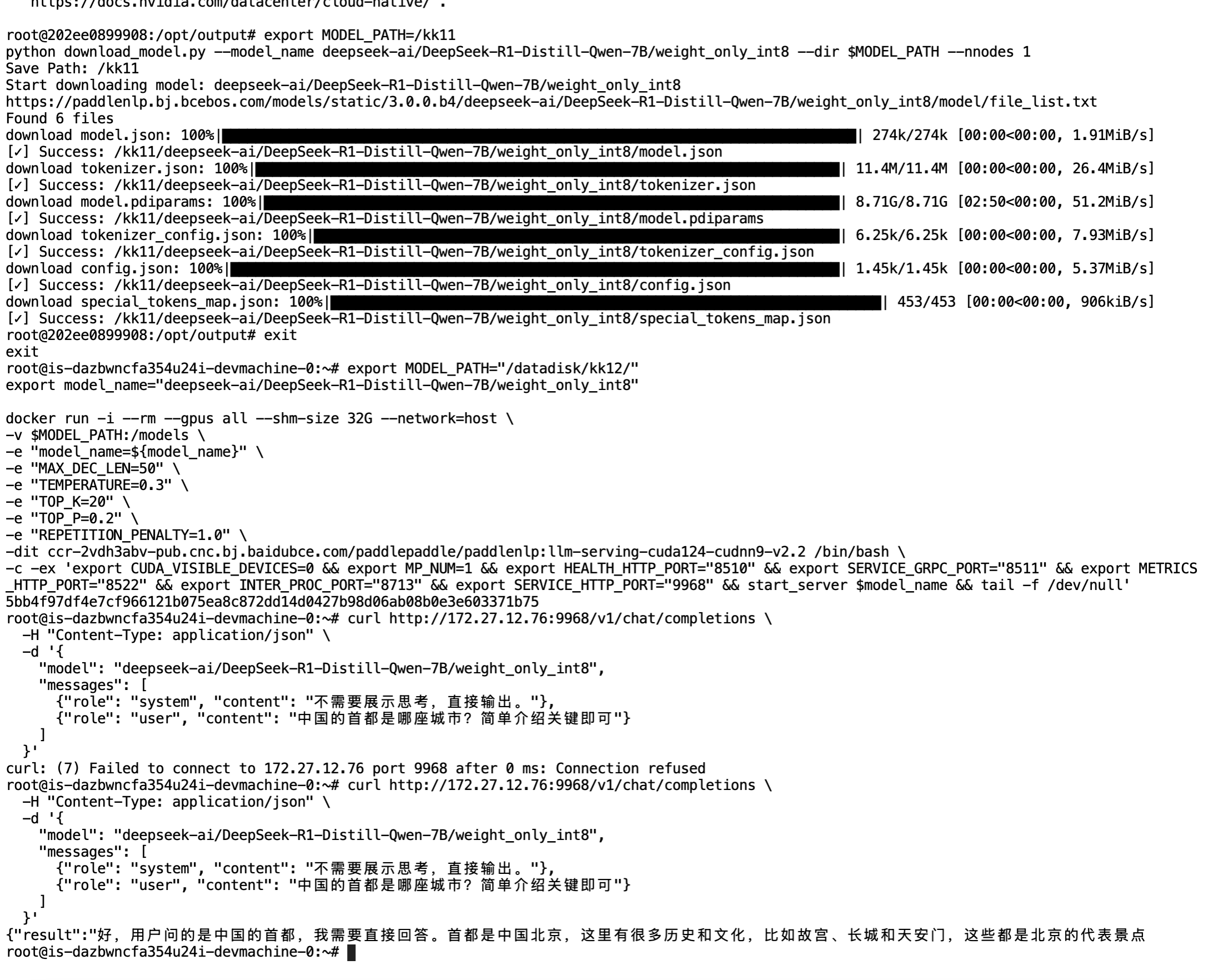
容器内的模型存储export MODEL_PATH=/kk11
export MODEL_PATH=/kk11
python download_model.py --model_name deepseek-ai/DeepSeek-R1-Distill-Qwen-7B/weight_only_int8 --dir $MODEL_PATH --nnodes 1其他模型参考:
DeepSeek — PaddleNLP 文档、https://github.com/PaddlePaddle/PaddleNLP/blob/develop/llm/server/docs/static_models.md
| deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B/weight_only_int8 |
| deepseek-ai/DeepSeek-R1-Distill-Qwen-7B/weight_only_int8 |
| deepseek-ai/DeepSeek-R1-Distill-Qwen-14B/weight_only_int8 |
| deepseek-ai/DeepSeek-R1-Distill-Qwen-32B/weight_only_int8 |
| deepseek-ai/DeepSeek-R1-Distill-Llama-8B/weight_only_int8 |
| deepseek-ai/DeepSeek-R1-Distill-Llama-70B/weight_only_int8 |
1.2.3、(可选)模型下载检查(镜像容器、主机外部传递)
#进入容器后
#容器内默认存储(官方代码)/modles
ls /kk11/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B/weight_only_int8/
应该会返回6个文件
config.json model.json model.pdiparams special_tokens_map.json tokenizer.json tokenizer_config.json
#主机
#terminal输入exit退出容器
#检查主机存储的传递文件
ls /datadisk/kk12/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B/weight_only_int8/
2、静态图部署与crul命令请求
2.1、创建一个专用容器
部署参考:
1、https://github.com/PaddlePaddle/PaddleNLP/issues/10157
参数参考:
2.1.1、退出镜像主容器
terminal输入
exit2.1.2、创建各个模型的专用容器
本次部署一般用的命令:
export MODEL_PATH="/datadisk/kk12/"
export model_name="deepseek-ai/DeepSeek-R1-Distill-Qwen-7B/weight_only_int8"
docker run -i --rm --gpus all --shm-size 32G --network=host \
-v $MODEL_PATH:/models \
-e "model_name=${model_name}" \
-e "MAX_DEC_LEN=50" \
-e "TOP_K=20" \
-e "TOP_P=0.2" \
-e "REPETITION_PENALTY=1.0" \
-dit ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddlenlp:llm-serving-cuda124-cudnn9-v2.2 /bin/bash \
-c -ex 'export CUDA_VISIBLE_DEVICES=0 && export MP_NUM=1 && export HEALTH_HTTP_PORT="8510" && export SERVICE_GRPC_PORT="8511" && export METRICS_HTTP_PORT="8522" && export INTER_PROC_PORT="8713" && export SERVICE_HTTP_PORT="9968" && start_server $model_name && tail -f /dev/null'注释版:
#注释版
export MODEL_PATH="/datadisk/kk12/" #主机传递的模型位置
export model_name="deepseek-ai/DeepSeek-R1-Distill-Llama-70B/weight_only_int8"
docker run -i --rm --gpus all --shm-size 32G --network=host \
-v $MODEL_PATH:/models #容器默认(官方代码)的模型与主机模型映射 \
-e "model_name=${model_name}" \
-e "MAX_DEC_LEN=50" #模型生成文本长度,有的模型过大会乱码(静态图) \
-e "TEMPERATURE=0.3" #文本随机性(木得用)钉了在0.95(底层代码修改) \
-e "TOP_K=20" #采样候选数量 \
-e "TOP_P=0.2 #数值越大随机性越大" \
-e "REPETITION_PENALTY=1.0 #1.0禁用随机惩罚,大于1.0惩罚重复,小于1.0鼓励重复" \
-dit ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddlenlp:llm-serving-cuda124-cudnn9-v2.2 /bin/bash \#官方镜像地址
-c -ex 'export CUDA_VISIBLE_DEVICES=0,1 && export MP_NUM=2 #GPU参数,2为两张卡
&& export BLOCK_BS=16 && export BLOCK_RATIO=0.5 && export BATCH_SIZE="64"
#多卡参数可调,优化推理性能/显存等
&& export HEALTH_HTTP_PORT="8510" && export SERVICE_GRPC_PORT="8511" && export METRICS_HTTP_PORT="8522" && export INTER_PROC_PORT="8713" && export SERVICE_HTTP_PORT="9968"
#export SERVICE_HTTP_PORT="9968" 后续curl命令会用
&& start_server $model_name && tail -f /dev/null'
#注意:float16精度下可能出现计算溢出,可以使用export FLAGS_blha_use_fp32_qk_sum=1 避免溢出
会返回一行长的容器id,可以复制一个地方标注备用
#示例
35ff04b99f88911d96558bed3adc702d0d7e3ca965d7964509414518c63d9902.2、curl命令请求
2.2.1、查ip
ifconfigterminal输入后查看自己的地址,第二区域,替换下面172.27.12.199;
(云主机每关机重启/掉jupyter都会变)
2.2.2、curl请求
9968 SERVICE_HTTP_PORT="9968"是创建容器时定义的;
system为系统提示词,可以不用。
curl http://172.27.38.107:9968/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-7B/weight_only_int8",
"messages": [
{"role": "system", "content": "不需要展示思考,直接输出。"},
{"role": "user", "content": "中国的首都是哪座城市?简单介绍关键即可"}
]
}'(一般需要等创建容器后等待模型加载完毕才可请求成功,或者 sleep 一下)
利用查看显存实时占用可以推断模型是否load上。
watch -n 1 nvidia-smi 3、流程结果图
4、其他代码
4.1、log下载与保存
#回到主机
exit#35ff04b99f88911d96558bed3adc702d0d7e3ca965d7964509414518c63d9909为示例容器id
#7b测试log为文件名保存在根目录
docker cp 35ff04b99f88911d96558bed3adc702d0d7e3ca965d7964509414518c63d9909:/opt/output/log/. 7b测试log进入
cd 7b测试log打包压缩,右键下载
tar -czvf log_7B.tar.gz *4.2、重复流程注意事项
用docker stop,防止占用端口,进行下一个测试部署
docker stop 35ff04b99f88911d96558bed3adc702d0d7e3ca965d7964509414518c63d9909查看端口占用
netstat -tuln
4.3、docker指令与其他代码
docker pull #拉镜像
docker run #创建容器
exit #退出docker
docker cp <容器id>:容器内路径 . 主机路径 #复制文件到主机路径
docker stop #停止
docker ps #查看所有docker容器id等信息
docker info #info 其他docker指令包括权限等:
在开发机内使用 Docker | 无问芯穹文档无问芯穹官方文档 | 无问芯穹(Infinigence AI,简称![]() https://docs.infini-ai.com/ai-studio/dev-instance/docker-in-docker/
https://docs.infini-ai.com/ai-studio/dev-instance/docker-in-docker/
其他(防忘):
watch -n 1 nvidia-smi #显存实时占用(load模型检查)
df -h #查看硬盘占用(检查挂载)
netstat -tuln #查看端口占用
sudo apt install vnstat #安装 需要apt镜像
watch -n 1 vnstat -i eth0 -tr # 每秒刷新,显示实时速率
#apt镜像
curl -s -L https://mirrors.ustc.edu.cn/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://nvidia.github.io#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://mirrors.ustc.edu.cn#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
ls #列出当前目录文件
cd .. #进入上层文件
#vim
i #插入
:%s/^/#/ #vim里注释所有行
:%d #删掉所有行
:wq #保存退出
然后一般需要source ~/.bashrc
#但这两个都在无问芯穹上尝试失败:
sudo systemctl daemon-reload
sudo systemctl restart docker
#或者
sudo service docker restart
二、静态图部署分析(与动态图部署对比)
2.1、分析与对比
静态图部署统一参数(单卡A800 80G PCIE):
export MODEL_PATH="/datadisk/kk12/"
export model_name="deepseek-ai/DeepSeek-R1-Distill-Qwen-7B/weight_only_int8"
docker run -i --rm --gpus all --shm-size 32G --network=host \
-v $MODEL_PATH:/models \
-e "model_name=${model_name}" \
-e "MAX_DEC_LEN=50" \
-e "TEMPERATURE=0.3 #实际默认0.95" \
-e "TOP_K=20" \
-e "TOP_P=0.2" \
-e "REPETITION_PENALTY=1.0" \
-dit ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddlenlp:llm-serving-cuda124-cudnn9-v2.2 /bin/bash \
-c -ex 'export CUDA_VISIBLE_DEVICES=0 && export MP_NUM=1 && export HEALTH_HTTP_PORT="8510" && export SERVICE_GRPC_PORT="8511" && export METRICS_HTTP_PORT="8522" && export INTER_PROC_PORT="8713" && export SERVICE_HTTP_PORT="9968" && start_server $model_name && tail -f /dev/null'
curl http://172.27.38.107:9968/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B/weight_only_int8",
"messages": [
{"role": "system", "content": "不需要展示思考,直接输出。"},
{"role": "user", "content": "中国的首都是哪座城市?简单介绍关键即可"}
]
}'格式:DeepSeek-R1-Distill-****-**/weight_only_int8
| 参数名称 | Qwen1.5B | Qwen7B | Llama8B | Qwen14B | Qwen32B |
|---|---|---|---|---|---|
| GPU 显存占用 (MB) | 3808 | 10924 | 13268 | 22512 | \\\ |
| 推理服务启动时间 (秒) | 12.05 | 28.07 | 26.06 | 78.12 | \\\ |
| Token/s (不含<think>) | 84.63 | 57.25 | 46.87 | 25.83 | \\\ |
| 缓存任务成本时间 (秒) | 0.0031 | 0.0169 | 0.0148 | 0.0216 | \\\ |
个人主观:
1、与动态图对比,接近的参数静态图14B就会完全乱码(溢出?,下面issue),静态图参数趋向于简单降参(topp)才勉强行。
2、动态图部署流简单(云上部署),线下部署静态图部署熟练后简单(但明显感觉静态图部署的坑更多一些)。
动态图参数

静态图

动态图

2.2、issues
1、输出乱码:改配置参数,改promt加入system promt,手动动态转静态;
另外从log中发现-e "TEMPERATURE=0.95"但设置的是-e "TEMPERATURE=0.3,说明设置不起作用。要进入代码底层修改,这又麻烦的很;
注意:float16精度下可能出现计算溢出(SM80以下),可以使用export FLAGS_blha_use_fp32_qk_sum=1 避免溢出。32b没啥用该不出还是不出,14b没测,可能有所帮助。
-e "MAX_DEC_LEN=50" \
-e "TEMPERATURE=0.3" #无用 \
-e "TOP_K=20" \
-e "TOP_P=0.2" \
-e "REPETITION_PENALTY=1.0" \
export FLAGS_blha_use_fp32_qk_sum=1 "messages": [
{"role": "system", "content": "不需要展示思考,直接输出。"},
{"role": "user", "content": "中国的首都是哪座城市?简单介绍关键即可"}2、32b/70b静态图部署load不成,包括双卡也测了一遍,手动由动态图转静态图导出,没时间精力资源了。
三、其他
1、其他服务部署:OpenAI 请求、多机参数部署等参考DeepSeek — PaddleNLP 文档;
https://paddlenlp.readthedocs.io/zh/latest/llm/server/docs/deploy_usage_tutorial.html。
动态图/静态图区别参考:深度学习框架——动态图和静态图-CSDN博客
2、先租一些低价云主机测试,熟练后再加配置,但要注意docker pull的路径更改在永久存储路径。
3、paddlepaddle3.0动静态部署本人归档 链接:提取码:lbcP

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)